融合词项关联关系的半监督微博聚类算法
2015-06-09马慧芳贾美惠子张志昌
马慧芳,贾美惠子,袁 媛,张志昌
(西北师范大学计算机科学与工程学院,兰州730070)
融合词项关联关系的半监督微博聚类算法
马慧芳,贾美惠子,袁 媛,张志昌
(西北师范大学计算机科学与工程学院,兰州730070)
针对微博文本内容短、稀疏、高维等特点,提出一种改进的半监督微博聚类算法。该算法利用词项间的关系丰富文本特征,通过定义词项文档间关联关系和词项文档内关联关系揭示词项间语义的关联程度,并由此自动生成有标记的数据来指导聚类过程。对词项先验信息进行成对约束编码,构建基于词项间成对约束的三重非负矩阵分解模型来实现微博的半监督聚类。实验结果表明,该算法可以减少繁琐的人工标记过程,并能高效地进行微博聚类。
微博;词项关联关系;成对约束;半监督聚类;非负矩阵分解
1 概述
随着Web2.0技术、无线网络技术和移动通信4G技术的发展,微博社交网络平台应运而生。作为一种新型的社交媒体,其海量的数据和主题多变的特点使得用户难以找到感兴趣的微博。直观想法是将微博聚类至不同主题下方便用户浏览与查询。针对文本聚类的研究核心内容包括文本表示和聚类模型两部分。长期以来文本表示的经典模型是向量空间模型(Vector Space Model,VSM)、通过词袋模型(Bag of Words,BOW)和信息检索中的词权重经典计算方法 TF-IDF(Term Frequency-Inversed Document Frequency)对文本进行向量化表示[1]。然后基于特征词项计算文本间相似度完成聚类。由于词空间具有高维、稀疏、多变和相关等特点,使得文本聚类存在各种各样的问题和困难。与传统文本不同,微博信息往往不遵循语法规则且内容过短,仅包含140个字,无法提供足够的词语共现与共享语义信息来进行相似度计算。此外,现实中很难得到有标签的样本信息,对大量微博进行手动加标件费时费力。
研究人员已在微博的聚类方面开展了相关工作,并取得了一定进展。主流的研究方法多采用面向长文本的挖掘方法来分类微博。代表性的工作包括基于主题模型的方法[2-3],也有一些研究人员探索传统的监督学习方法来实现为微博聚类[4-5]。然而微博的稀疏性和用词不规范严重影响了这些方法的性能。此外,从微博中获取带类标的数据仍需借助于人工,这在现实应用中几乎不可能。
针对微博长度短、内容稀疏的特点,本文提出一种融合词项关联关系的半监督非负矩阵分解聚类算法。通过挖掘微博内部的词语信息丰富微博的文本特征,自动生成具有特定类别词项标注信息来辅助预测大量未标注微博数据,并从中挖掘出微博潜在主题和语义信息。具体地,以正交三重非负矩阵分解算法(Orthogonal Nonnegative Matrix Tri-Factoriz-ation, OTri-NMF)[6]为基础,从词项关联关系出发,通过定义文档内关系与文档间关系获取词项关系,并设计合理的先验信息编码表示方法和迭代算法构建半监督三重非负矩阵分解算法来实现微博聚类。
2 先验信息
短文本应用场景下随着文档规模的不断上升词项规模增速缓慢,基本趋于一个稳定值。此外相应的词项中约95%词在大多数文档中的出现次数都等于1,即绝大数词项的tf值与idf值相等[7]。现有方法大多将文本向量每维视为彼此独立不相关的信息进行处理。即将每维特征词项的距离差值对文本整体相似度的贡献简单等同,不考虑不同特征分量间可能存在着的关联关系。事实上,特征词项分量间关联性直接影响着文本相似度的计算结果。利用词项间的关联关系代替词与文档间的关系可以有效地降低短文本表示矩阵的维度并丰富短文本的词项语义信息。
2.1 词项关联关系
先验信息生成的基础是基于词项的共现关系。显然,同一微博中共现的词项具有语义上的联系,而不同微博中出现的词项若通过某个或某些特定词项在其他微博中共现也具有一定的语义关联。如图1所示。其中,d1和d2分别表示2篇微博,黑色圆点表示两篇文档中共有的词项,实线圈内表示关联词关系的2种模式。左图表示词项在同一篇文档中的关联关系;右图则表示词项文档间关联关系。
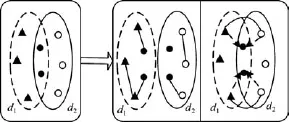
图1 关联词类型
考虑词项ti的分布情况可由该词项与上下文中的其它词项共现向量ti(w11,w12,…,wij)来表示,wij表示词ti和tj的互信息(Positive Point Mutual Information,PPMI)。作为信息论知识在统计学中的一种应用,互信息可用于度量2个统计量之间的相互关联程度。利用词分布上下文语义相关性思想来构建词项关联关系具体思想如下:
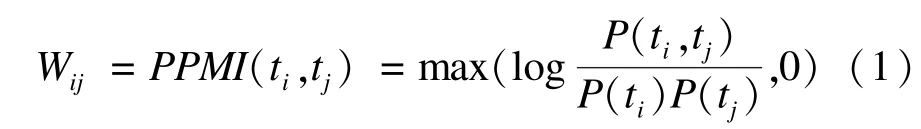
其中,P(ti,tj)和P(ti)的计算公式如下:
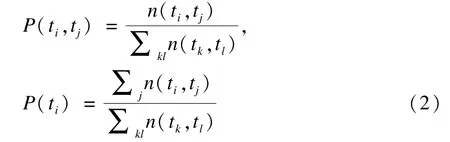
其中,n(ti,ti)表示ti和tj共同出现的次数。由此,可将数据集中的每一个词项表示为该词项的互信息向量。
2.1.1 文档内关联关系
若2个词语在同一篇文档中的共现,则这2个词语具有文档内关联关系。如图1所示,词ti和tk在d1中共现,tj和tk在d2中共现,则词ti,tk和词tj,tk分别在文档d1和d2中具有文档内直接关联关系。采用经典余弦相似度计算公式如下:

2.1.2 文档间关联关系
若2篇文档d1和d2中的词与d1和d2共有词共现,则这2个词具有文档间关联关系,如图1所示,给定词ti和tj,至少存在一个词tk,使得词ti与tj共现,那么称ti和tj是具有文档间关联关系的。其中词tk称为ti和tj的链接词。计算词ti和tj通过词tk的文档间关联关系公式如下:
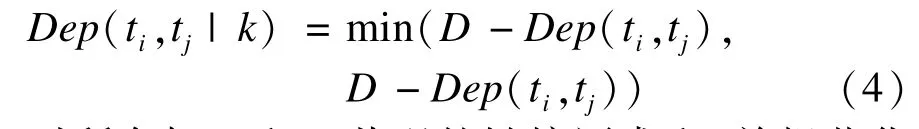
对所有与ti和tj共现的链接词求和,并规范化至[0,1]之间如下:
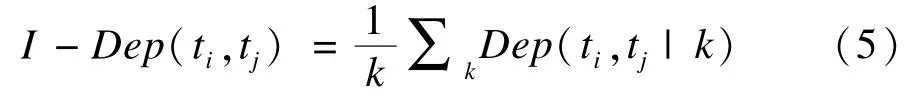
上述公式表明2个词的共有链接词越多,表明这2个词关系越密切,其文档间关联关系越大。与文档内关联关系相比,文档间关联关系考虑了所有与其具有相似关系的链接词出现的文档,语义覆盖面更为宽泛。
至此,文档内与文档间词语的关联关系充分挖掘出词语间全部的关联关系。利用如下公式计算词项间关联词关系:
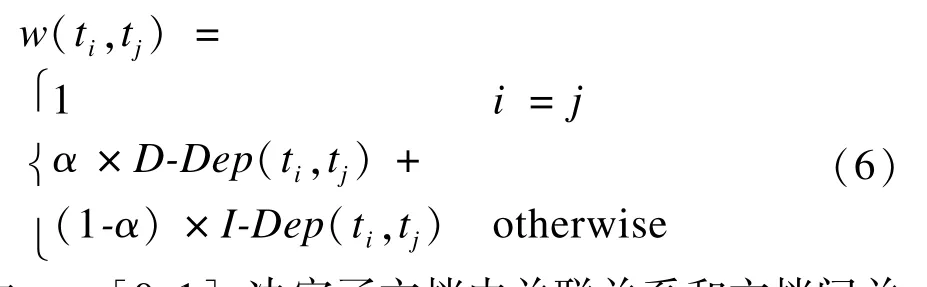
其中,α∈[0,1],决定了文档内关联关系和文档间关系所占比例。由上述方法得到的关联词关系不仅包含了共现词语的互信息,而且包含了非共现词语的文档间关联关系因此具有更为丰富的的语义信息。
2.2 先验信息的编码
针对本文中聚类的具体应用,must-1ink约束定义2个词项必在同一类;cannot-1ink约束则限定2个词项必不在同一聚类中。设定阈值,当计算得到的词项关联关系大于给定阈值则定义其必在同一类中,而小于特定阈值则必不在同一类中。考虑到must-1ink限制具备典型的传递关系,通过计算传递闭包将词项层面上的限制进行传播。词项的成对约束需要通过以下的方式对约束信息编码。
假定词项(wik,wjk)属于同一类,must-link约束集合As表征所有必须在同一类的词对,记为:
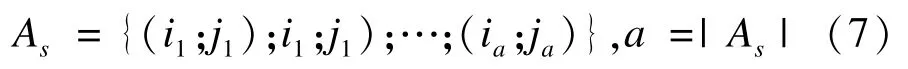
类似地,cannot-link约束集合Bs记为:
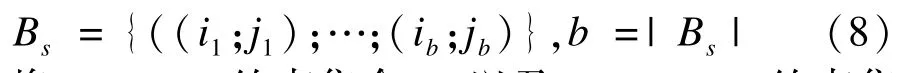
将must-link约束集合As以及cannot-link约束集合Bs集成到优化目标函数中的可行方案是将must-link约束集合As编码为对角线元素均为1的对称矩阵A,类似的,cannot-link约束集合Bs则编码为矩阵B。
将约束看作在矩阵F上词项属于各类的后验概率。那么一个must-link约束对(i1;j1)意味着对某个类别hi1hj1k>0,也即需要极大化,将must-link约束表示为:
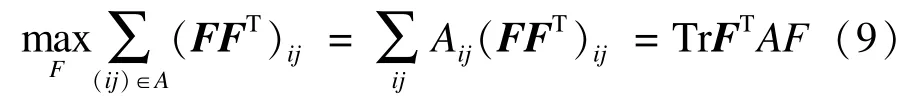
类似的处理可应用于cannot-link约束对(i2;j2)的处理。对不同类别k,h21khj2k=0。换言之,需要极小化。因此将cannot-link约束表示为:
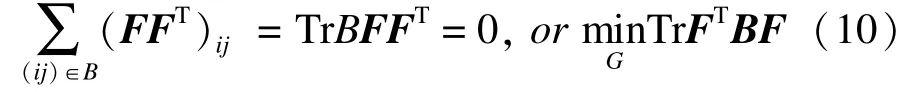
3 算法描述
经典的非负矩阵分解算法[8]仅要求所分解的因子矩阵非负。本文的应用背景中对分解的因子矩阵考虑更多的约束来得到强化分解的结果。一是要求分解结果正交来获得唯一的聚类结果;二是要求增添词项向量矩阵的成对约束信息。最终将融合词项关联关系的半监督微博聚类问题可转化为约束优化求解问题,目标函数定义为:
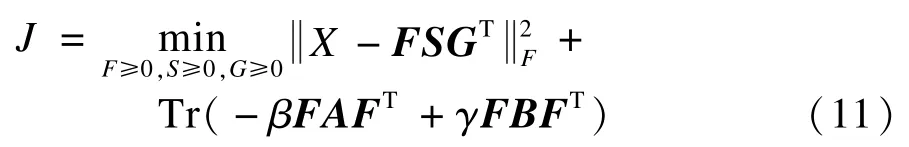
从优化的角度看,式(11)表示了一个典型的优化问题,其中β,γ均为正数,用于表示用户先验信息的强度,参数值越大则表示先验知识越重要。A,B表示词项间成对约束的先验信息。此处求F,S仅是为了辅助求G,求G是进行学习的根本目的。
如上所述,NMF的解不具有唯一性,为避免歧义,对目标函数定义正交约束:

对式(11)的优化可以用以下迭代过程来求解[9]:
为计算S,优化方程式(11),相当于优化:

得到更新F的函数如下:
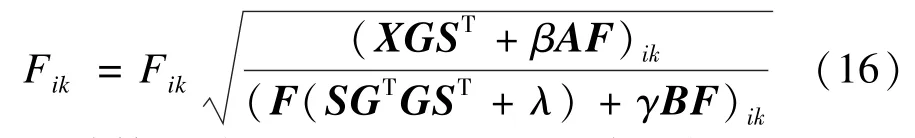
为计算G,优化方程式(11),相当于优化:
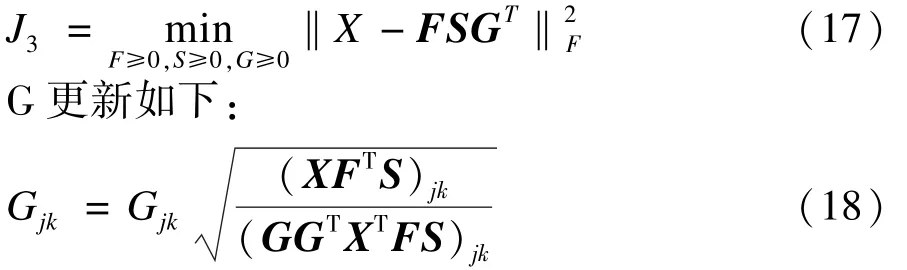
文献[6]已证明了该算法的收敛性和正确性。
半监督微博聚类算法:
输入 词项类别数目k1,微博类别数目k2,词_微博矩阵X∈RM×N,约束矩阵A,B
输出 F∈RM×K1,S∈RM×K1,G∈RK2×N

第2步
循环:
固定S,G,应用式(16)更新F;
固定F,G,应用式(14)更新S;
固定F,S,应用式(18)更新G。
4 实验性能与分析
4.1 数据描述
本文实验数据来源于微博平台Twitter[10]与新浪微博。实验采集了2013年10月15日-2013年12月15日大量的微博数据,通过Google趋势查找2013年的“热词”得到不同的类别。对实验数据进行预处理,首先去除微博文本中的链接、转发标志、@用户名和表情符号、简繁转换等噪音信息之后,对其进行分词,去除停用词、高频词和低频词,得实验数据集合。其中,分词采用 python开源分词系统stammer,停用词表采用新浪提供的1 028个停用词。最后去除所有在少于10篇文档中出现过的低频词项,得最终表1所示的实验数据集合。

表1 实验数据统计信息
此外,实验中的词项和微博的主题数目取值是按照实验者经验来进行主观选取的经验值,实验中将主题数目多次设定为不同值,得到在不同主题数目的情况下实验结果的对比。
4.2 实验结果与分析
为了验证本文方法的有效性,设计了2个实验: (1)将本文方法与其他经典算法进行比较;(2)分析成对约束对算法的影响。比较算法选择K-means、IT-Co-clustering、TNMF-E以及 TNMF-I为基线方法。其中,K-means算法是最经典的聚类算法之一; IT-Co-clustering[11]是经典的联合聚类算法TNMF-E以及TNMF-I分别代表采用欧式距离和KL散度的三重非负矩阵分解算法。
4.2.1 聚类整体性能和比较
采用纯度(Purity)、归一化互信息(Normalized Mutual Information,NMI)和可调节约当指数 ARI (Adjusted Rand Index)[12]作为评价聚类结果的指标。其中,纯度用来刻画整个聚类结果相对于手工分类结果的准确程度。NMI是外部评价标准,用来评价在一个数据集上的聚类结果与该数据集的真实划分的相似程度。ARI则是用来刻画一对方法的准确度。
本文方法与K-means,IT-Co-clustering,TNMF-E以及TNMF-I方法分别进行对比,结果如图2所示。
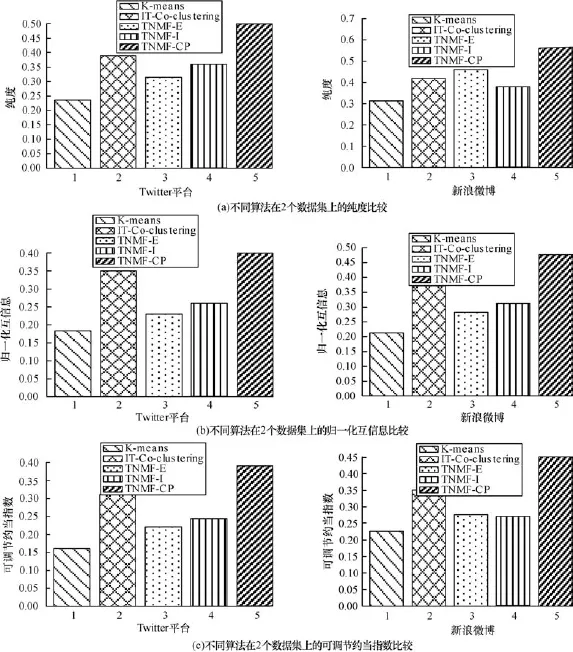
图2 不同算法在2个数据集上的聚类性能比较
由图2可以看出,本文方法在纯度、NMI和ARI指标上均优于其他4种方法。K-means仅从字面信息考虑,忽略了词项间隐含的关系,导致所得到的词微博矩阵非常稀疏,文档向量并不能很好地刻画所属的原始文档信息,所以算法性能最差。TNMF-E以及TNMF-I算法中三重非负矩阵分解的机制允许设置不同个数的特征词项与微博类别,这与现实中实际应用一致。IT-Co-clustering应用了联合聚类的思想算法性能好于其他3种。但是仍然没有考虑词项间的关系。本文方法不仅加入了词语的互信息,而且从词语的文档间关系入手,生成的约束充分挖掘了词项之间的关联关系,克服了文本表示中没有考虑词项与上下文关系而导致的聚类结果不准确的问题,还大大降低了原始数据高维稀疏及传统词频与逆文档频率对这类短文本区别能力差的难题。因而本文提出的算法总是优于其他的几种无监督聚类方法。
4.2.2 先验信息对聚类的影响
为了进一步分析先验信息对聚类效果的影响,本节展示调节文档内和文档间词项关系的因子变化对于聚类性能影响。该因子决定了文档内关联关系和文档间关系在先验信息生成中所占比例。取值越大表示关联词关系的共现词语的互信息更为重要,反之则表示非共现词语的文档间关联关系更加重要。图3给出了在Twitter数据集上相应的实验结果。
图3 关联关系比重α对聚类算法性能的影响
从图3中可以看出,当α的值从0~1逐渐增大时,本文算法的在纯度、NMI和ARI指标上呈现出先增后减再增的变化,通常参数值在中间值时算法的性能达到最好,即词语间互信息和词语的文档间关系的地位同等重要,此时既包含了同一篇文档中词语间的关系,又包含了不同文档中词语间的关系。
当α=1,即只考虑词语的文档间关系时算法的性能优于α=0,即只考虑词语间互信息,这是因为微博的词汇量有限,如果仅从词语在同一篇微博中的关系出发挖掘信息无法充分挖掘词语间蕴含的信息,反之在词语通过关联词产生的文档间关系中,由于可能发生的关联词数量较多,使得产生的词语的微博间关系数量超过了词语的互信息,因此词语的微博间关系更加能够挖掘出词语间的关系,所以仅考虑文档间关系时算法的性能略优于仅考虑词语互信息。
5 结束语
对海量用户感兴趣的微博进行聚类是值得研究的问题。针对现实应用中往往存在大量无标记数据和少量有标记数据,本文提出一种结合词项上下位词的信息词项关联关系的半监督非负矩阵分解的聚类算法。该算法克服了微博短文本的高维稀疏问题,通过自动获得微博特征词级的约束信息来有效支持微博聚类。然而本文特征项的提取仅从微博内容出发,下一步研究将考虑微博用户间关系、标签信息等来进一步改进微博聚类算法。
[1]Salton G,Wong A,Yang C S.A Vector Space Model for Automatic Indexing[J].Communications of the ACM, 1975,18(11):613-620.
[2]Zhao W X,Jiang J,Wen J,et al.Comparing Twitter and Traditional Media Using Topic Models[C]//Proceedings of European Conference on Information Retrieval Research.Berlin,Germany:Springer,2011:545-556.
[3]Yan X H,Guo J F,Liu S H,et al.Clustering Short Text Using Ncut-weighted Non-negative Matrix Factorization[C]//Proceedings of the 21st ACM International Conference on Information and Knowledge Management.Maui,USA:ACM Press,2012:216-222.
[4]Ramage D,Dumais S T,Liebling D J.Charaterizing Microblog with Topic Models[C]//Proceedings of International AAAI Conference on Weblogs and Social Media.Washington D.C.,USA:IEEE Press,2010:234-245.
[5]Chen Y,Li Z J,Nie L Q,et al.A Semi-supervised Bayesian Network Model for Microblog Topic Classification[C]//Proceedings of 24th International Conference on Computational Linguistic.Washington D.C.,USA: IEEE Press,2012:561-576.
[6]马慧芳,王 博.基于非负矩阵分解的双重约束文本聚类算法[J].计算机工程,2011,37(24):161-163.
[7]Yan X H,Guo J F,Liu S H,et al.Learning Topics in Short Texts by Non-negative Matrix Factorization on Term Correlation Matrix[C]//Proceedings of the SIAM InternationalConference on Data Mining.Austin, USA:[s.n.],2013:145-154.
[8]Lee D D,Seung H S.Learning the Parts of Objects by Non-negative Matrix Factorization[J].Nature,1999, 401(6755):788-791.
[9]Li T,Ding C,Zhang Y.Knowledge Transformation from Word Space to Document Space[C]//Proceedings of the 31stACM SIGIR Conf.on Research and Development in Information Retrieval.New York,USA: ACM Press,2008:187-194.
[10]马慧芳,王 博.基于增量主题模型的微博在线事件分析[J].计算机工程,2013,39(24):161-163.
[11]Zhao Y,Karypis G.Criterion Functions for Document Clustering,CSD:01-40[R].University of Minnesota,2001.
[12]Dhillon I S,Mallela S,Modha D S.Information-theoretic Co-clustering[C]//Proceedings of the 9th International ACM SIGKDD Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2003:89-98.
编辑 索书志
Semi-supervised Microblog Clustering Algorithm Fused with Term Correlation Relationship
MA Huifang,JIA Meihuizi,YUAN Yuan,ZHANG Zhichang
(College of Computer Science and Engineering,Northwest Normal University,Lanzhou 730070,China)
A novel semi-supervised learning algorithm fully exploring the inner semantic information to compensate for the limited message length is presented.The key idea is to explore term correlation data,which well captures the semantic information for term weighting and provides greater context for short texts.Direct and indirect dependency weights between terms are defined to reveal the semantic correlation between terms.Must-link and cannot-link are encoded as constraints for terms.This paper formulates microblog clustering problem as a semi-supervised non-negative matrix factorization co-clustering framework,which takes advantage of knowledge of features as pair-wise constraints.Extensive experiments are conducted on two real-world microblog datasets.Experimental results show that the effectiveness of the proposed algorithm.It not only greatly reduces the labor-intensive labeling process,but also deeply exploits the hidden information from microblog itself.
microblog;term correlation relationship;pair-wise constraints;semi-supervised clustering;non-negative matrix factorization
1000-3428(2015)05-0202-05
A
TP18
10.3969/j.issn.1000-3428.2015.05.037
国家自然科学基金资助项目(61163039,61363058);甘肃省教育厅基金资助项目(2013A-016)。
马慧芳(1981-),女,副教授、博士,主研方向:人工智能,数据挖掘,机器学习;贾美惠子、袁 媛,硕士研究生;张志昌,副教授、博士。
2014-06-03
2014-07-06E-mail:mahuifang@yeah.net
中文引用格式:马慧芳,贾美惠子,袁 媛,等.融合词项关联关系的半监督微博聚类算法[J].计算机工程,2015, 41(5):202-206,212.
英文引用格式:Ma Huifang,Jia Meihuizi,Yuan Yuan,et al.Semi-supervised Microblog Clustering Algorithm Fused with Term Correlation Relationship[J].Computer Engineering,2015,41(5):202-206,212.
