基于动词依存集的领域概念聚类方法
2015-06-05刘里肖迎元
刘里,肖迎元
(1.天津理工大学计算机视觉与系统省部共建教育部重点实验室,天津300384;2.天津理工大学 天津市智能计算及软件新技术重点实验室,天津300384)
按照概念的相似性和差异性,将其划分为若干组,同组的尽量相似,不同组的尽量相异,这种对概念进行自动组织的方法称为概念聚类。概念聚类的过程就是根据各个概念的特征相似程度划分类簇的过程,在输入的概念集合中找到特征相似的概念,将其归为一个类簇。
目前,概念聚类在语义消歧[1-2]、主题抽取[3]、文本分类[4-5]、信息检索中得到了广泛的应用[6]。根据聚类所依据的特征,可以将概念聚类方法分为3类:基于语法特征的概念聚类、基于语义特征的概念聚类和基于语用特征的概念聚类[7]。
基于语法特征的概念聚类又称为基于语料库的概念聚类,这种方法一般是使用统计方法,从目标词的上下文中提取其语法特征,将语料库中语法特征相近的词进行聚类。选取何种和目标词构成相关关系的词作为特征维度,与被聚类的词的语言特点有关[8]。如汉语中,可以利用虚词作为特征维对实词进行描述[9],而日语中常选用动词-名词组合[10]。
基于语义特征的概念聚类通常基于某种语义知识库,如 WordNet、HowNet、同义词词林等,计算得出概念的相似度/相关度矩阵,然后使用K-Means[11]、KNN 或者层次聚类方法得到聚类结果。因为目前各种聚类方法比较成熟,如何进行概念的相关度/相似度的计算是目前研究的重点,常用的计算方法有 single linkagecomplete linkage 和 average linkage 等[12]。
基于语用特征的概念聚类针对某种具体的应用提取概念特征(语用特征),词与词之间的相似度不再局限于语义相似,而在于共同与某一特定对象的接近程度。利用搜索引擎的关键词推荐、搜索结果指向的网页资源[13]、文档分类信息[14]等资源对概念进行扩充后再进行聚类是常用的方法。这种方法产生的聚类结果接近于选取的辅助资源的分类。
这些概念聚类方法,都是在有较大规模、比较完善的辅助资源的基础上实现的,比如大规模的训练语料库、规范的语义知识库或者搜索引擎等。然而很多实际情况是,需要构建某个特定领域的领域本体,却只有小规模领域语料库支持,这种情况经常出现。如何利用有限的语料库进行概念聚类,值得深入研究。
在这种情况下,本文提出了一种新的方法——动词依存法。该方法使用领域专家辅助制定的动词依存集,根据概念对动词依存集的集合依存度将概念进行聚类。
1 动词依存法
1.1 理论依据
大量实验结果表明,在任何语种的自然语言中,出现在同一种句法结构中的词语是有限的,尤其是名词和动词的搭配,即能够搭配同类动词的名词非常有限。领域概念多为名词词性。据此,本文提出动词依存法进行概念聚类。动词依存法的基本思想是:存在动词依存集(verb dependency set,VDS),记为 VDS={v1,v2,...,vn},依存集中的元素vi可以和同类名词性概念搭配组成主谓结构或者动宾结构。换句话说,和相同动词依存集中的动词能够合理搭配的概念可以归为一类。

图1 示例文本Fig.1 Example text
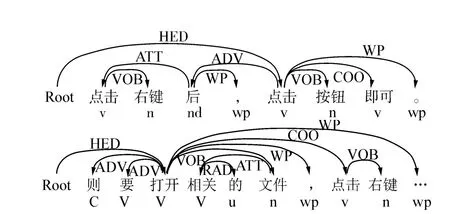
图2 示例文本的依存句法分析片段Fig.2 Dependency parse result of example text
例如,图1是一段示例文本,图2是这段文本对应的依存句法分析[15]片段(为了美观,采用分段截图,不影响关键内容的句法分析结果)。示例文本中的“右键”和“按钮”都是“菜单”类的概念,两者都和动词“点击”依存,形成动宾结构。而“文件”和“右键”不属于同一类概念,其依存的动词也各不相同。
1.2 相关定义
动词依存法的输入是领域候选概念集合、领域语料库和动词依存集 VDS={v1,v2,...,vn},输出是与每个动词依存集相对应的概念类簇CSi。本方法考虑动词和概念存在的2种句法结构组合:主语+谓语结构,动词+宾语结构。对句法结构的依存度量化指标参考并改进了互信息方法。定义1~4是动词依存法相关的参数。
定义1 主谓依存度(subject-predicate dependency,SPD)表示概念与动词以主谓结构出现时的依存程度。概念c与动词v的主谓依存度定义如下

在同一个语料库中,fsp(c,v)是概念c作为动词v的主语的频率,fs(c)是概念c作为任意动词的主语的总频率,f(v)是动词v的词频,Sn是语料库中句子的总数。
定义2 动宾依存度(verb-object dependency,VOD)表示概念与动词以动宾结构出现时的依存程度。概念c与动词v的动宾依存度定义如下

在同一个语料库中,fvo(s,v)是概念c作为动词v的宾语的频率,fo(c)是概念c作为任意动词的宾语的总频率。其余变量与式(1)一致。
定义3 动词依存度(verb dependency,VD)表示概念与动词在句法上的依存程度。本章只考虑主语+谓语结构,动词+宾语2种句法结构,概念c与动词v的动词依存度定义如下
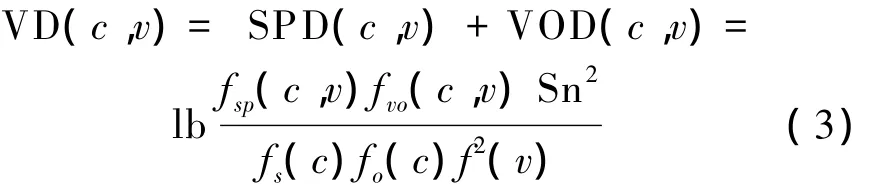
定义4 动词集合依存度(verb set dependency,VSD)表示概念与动词依存集中的所有动词在
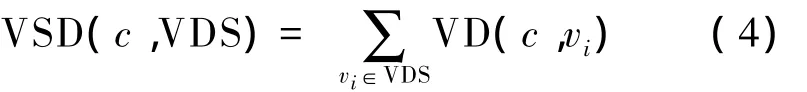
对 于 每 一 个 VDSi={vi,1,vi,2,...,vi,n},使用动词依存集方法可以在语料库中得到概念类簇CSi。CSi是由和VDSi的动词集合依存度大于阈值的概念集合,CSi={c|VSD(c,VDSi)>threshold}。
1.3 动词依存法的流程
动词依存集是在领域专家的参与下,针对领域语料库中的每一类概念选取的有依存关系的特征动词集。每一个动词依存集都对应着多个同一类别的领域概念。本文方法的流程如图3。句法上的依存度的总和。概念c与动词依存集VDS={v1,v2,...,vn}的动词集合依存度定义如下

图3 动词依存法的流程Fig.3 Process of verb dependency method
动词依存法的输入是动词依存集、领域候选概念集合和领域语料库,输出的是领域概念类簇。使用动词依存法对概念进行聚类的伪代码如下所示:


需要说明的是:1)动词依存法输入的领域候选概念集合采用经过筛选后的领域词典(领域词典应尽可能完善,覆盖领域语料库中的领域概念);2)依存句法分析采用哈尔滨工业大学的工具,为了提高准确率,对分析结果进行了人工辅助纠正;3)标准化处理是将语料库中的概念、动词分别替换为输入的标准化的概念集合中的概念、动词依存集中的动词。
2 对比实验及评价
2.1 实验方法与结果
为了评价算法的性能,选取某大型国企的多种大型计算机软硬件电子说明书作为实验语料。语料内容覆盖了计算机领域常用的说明语句,格式规范,包含10 375个句子。
根据实验语料库的分类关系,选取网络上计算机领域的词库,抽取其中的动词,并在领域专家的辅助下进行整理,制定了动词依存集。根据实验语料库的语言现象和实验的需要,设置每个依存集由6个动词组成。多次实验的结果表明,单个概念对动词的依存度为1.15时,概念与动词的依存关系符合人工的判定标准。利用动词依存法对概念进行聚类,设定当概念ck与动词依存集VDSi的动词集合依存度VSD(ck,VDSi)>6.5时,将ck归入VDSi对应的概念类簇CSi。在这个条件下,使用动词依存法聚类,共得到不重复的概念56个。表1列举了部分动词依存集和对应的概念类簇。
实验结果可见,动词依存法提取到的概念类簇符合人工聚类的结果,准确率较高。由于动词依存法计算的是概念与多个动词的依存度的总和,所以能够有效的排除某些概念归属于不同类簇的问题:例如“按钮”这个概念与动词“弹出”有较高依存度,但其与动词依存集VDS={显示,出现,弹出,生成,转换,变成}的集合依存度并不高,所以最终结果并不依存于这个集合。

表1 部分动词依存集和对应的概念类簇Table 1 Part of VDS and corresponding concept cluster
2.2 评价标准
利用概念重合率(concept coincide,CC)评价本文方法的聚类结果与人工结果中相同概念的比率。假定有n个动词依存集,每一个动词依存集VDSi用本文的方法对应着一个聚类得到的类簇CSi,与人工制定的结果CSi*进行比较。Cref定义为人工结果的总和,即Cref={CS1*,CS2*,..,CSn*}。概念召回率定义为本文聚类结果中每一个类簇与人工确定的类簇重合的概念数总和,占人工结果总概念数的比值如下

2.3 性能对比
将动词依存法得到的无重复概念总数与基于 LSI的方法[16]和基于搜索引擎的方法[17]进行对比,得到的概念重合率分别是:基于动词依存集的方法为 76.7%;基于 LSI的方法为 69.9%;基于搜索引擎的方法为65.8%。
实验结果表明,本文的动词依存法在概念重合率上效果较好,可以说明在特定领域,概念和动词数量有限的情况下,两者有较高的依存度。例如计算机软硬件说明语料,动词依存集就有着明显的领域特征,如VDS={填写,保存,编辑,打开,打印,输入}这个动词依存集搭配的名词只能是和“文字信息”相关的概念(比如“文件”、“文本”等)。
3 结束语
动词依存法根据同类领域概念与特定的领域动词共现这一特征,在领域专家辅助下制定动词依存集,将在主谓结构和动宾结构中与动词依存集共现的概念聚为一类。本方法一定程度上依赖人工,比如制定动词依存集,输入领域候选概念集合等。由于特定领域涉及的概念与动词比较有限,同时现阶段网络上又有各种领域词库可供利用,所以本文中的人工工作有较高的可行性。
由于动词依存法计算量相对较小,不需要前期的训练工作,应用较为方便,加上其依赖一定的人工,所以动词依存法是一种适用小规模领域语料库的聚类方法。
[1]TUFIŞ D,ION R,IDE N.Fine-grained word sense disambiguation based on parallel corpora,word alignment,word clustering and aligned wordnets[C]//Proceedings of the 20th International Conference on Computational Linguistics.Association for Computational Linguistics.Geneva,Switzerland,2004:1312.
[2]JIN P,SUN X,WU Y,et al.Word clustering for collocation-based word sense disambiguation[C]//Computational Linguistics and Intelligent Text Processing.Berlin:Springer,2007:267-274.
[3]陈炯,张永奎.一种基于词聚类的中文文本主题抽取方法[J].计算机应用,2005,25(4):754-756.
CHEN Jiong,ZHANG Yongkui.Novel Chinese text subject extraction method based on word clustering[J].Journal of Computer Applications,2005,25(4):754-756.
[4]CHEN W L,CHANG X Z,WANG H Z,et al.Automatic word clustering for text categorization using global information[C]//Information Retrieval Technology.Berlin:Springer,2005:1-11.
[5]DHILLON I S,MALLELA S,KUMAR R.Enhanced word clustering for hierarchical text classification[C]//Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.ACM.Edmonton,Canada,2002:191-200.
[6]MOMTAZI S,KLAKOW D.A word clustering approach for language model-based sentence retrieval in question answering systems[C]//Proceedings of the 18th ACM Conference on Information and Knowledge Management.ACM.Hong Kong,China,2009:1911-1914.
[7]郭怀恩,朱礼军,徐硕.词聚类技术研究综述[J].数字图书馆论坛,2010(5):15-19.
GUO Huaien,ZHU Lijun,XU Shuo.A survey on word clustering technique[J].Digital Library Forum,2010(5):15-19.
[8]闻扬,苑春法.基于搭配对的汉语形容词—名词聚类[J].中文信息学报,2000,14(6):45-50.
WEN Yang,YUAN Chunfa.Clustering of Chinese adjectives-nouns based on compositional pairs[J].Journal of Chinese Information Processing,2000,14(6):45-50.
[9]WANG B,WANG H.A comparative study on Chinese word clustering[C]//Computer Processing of Oriental Languages.Beyond the Orient:The Research Challenges Ahead.Berlin:Springer,2006:157-164.
[10]FARHAT A,ISABELLE J F,O'SHAUGHNESSY D.Clustering words for statistical language models based on contextual word similarity[C]//1996 IEEE International Conference on Acoustics,Speech,and Signal Processing.Atlanta,Georgia,1996:180-183.
[11]DUDA R O,HART P E,STORK D G.Pattern classification[M].2nd ed.Hoboken:John Wiley & Sons,2000.
[12]JAIN A K,DUBES R C.Algorithms for clustering data[M].Englewood Cliffs:Prentice hall,1988.
[13]MATSUO Y,SAKAKI T,UCHIYAMA K,et al.Graphbased word clustering using a web search engine[C]//Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing.Association for Computational Linguistics.Sydney,Australia,2006:542-550.
[14]BELLEGARDA J R,BUTZBERGER J W,CHOW Y L,et al.A novel word clustering algorithm based on latent semantic analysis[C]//Proceedings of the Acoustics,Speech,and Signal Processing,1996.IEEE,Atlanta,Georgia,1996:172-175.
[15]哈工大社会计算与信息检索研究中心.基于云计算技术的中文自然语言处理服务平台[EB/OL].(2014-02-11).http://www.ltp-cloud.com/demo/.
[16]HARRIS Z S.Mathematical structures of language[M].Florida:Krieger Pub Co,1968.
[17]TURNEY P D.Mining the Web for Synonyms:PMI-IR versus LSA on TOEFL[C]//Proceedings of the 12th European Conference on Machine Learning.arXiv preprint cs.Freiburg,Germany,2001:491-502.
