混合迁移学习方法在医学图像检索中的应用
2015-06-05贾刚王宗义
贾刚,王宗义
(哈尔滨工程大学自动化学院,黑龙江哈尔滨150001)
在医学图像检索领域,医学图像的语义标注常常是利用已有的先验医学知识完成的。现有的研究也都是针对某一特定的身体部位或器官进行的,使用的医学知识也仅仅是与这一部位或器官相关的,这样建立起的语义映射机制具有极大的局限性。从一个实用性来看,更加希望能够最大效率地利用已有的知识和先验信息,克服这种只针对某一领域数据有效的局限性,要在有限的知识和先验信息中挖掘出更多的可以利用的信息,提高学习效率。因此,本文将迁移学习理论引入到医学图像的语义映射。
迁移学习源于20世纪90年代,是指在不同任务或领域知识间进行迁移和转化的能力。确切地说,迁移学习是指一种学习对另一种学习的影响,或一种学习的经验对完成其他任务的影响。迁移学习的概念提出后受到学者们的关注,并且有些研究成果已经应用到了实际问题中,如文本分类[1]、文本数据挖掘[2]和命名实体识别[3]等。
迁移学习可根据具体实现方法分为以下4类:实例迁移、特征迁移、参数迁移以及知识迁移[4]。本文主要涉及实例迁移和特征迁移2种。融合实例迁移和特征迁移学习各自的优点,提出一种混合迁移学习方法,具体地,将实例迁移引入到多任务稀疏特征学习方法中,并将其应用到医学图像检索和语义标注中。
1 迁移学习原理
1.1 实例迁移学习
实例迁移的研究重点是如何在源领域中实现数据的加权选择,把选出的优秀数据应用于目标任务的学习中。
将样本的特征x与其标签y之间的关系看作满足某种联合分布 P(x,y),设源领域数据分布为PS(X,Y),目标领域数据分布为PT(X,Y),则学习的任务就是利用领域中的 l个样本 z=(l个样本独立同分布)在一系列函数中找到一个能最优的估计出特征x与其标签y之间的关系函数,使得下式风险泛函最小[8]:
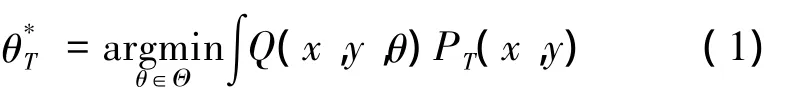
式中:Θ为函数集,θ*为学习到的最优模型,Q x,y,θ()为在函数为θ条件下造成的损失。从源数据中随机抽取样本,设其分布为PS'(X,Y),则目标领域的学习函数为

1.2 特征迁移学习
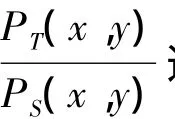
定义特征变换h:X→W,对观察样本的表示做出变换w=h(x)∈W,P(W,Y)是变换后数据分布情况。则,若 有 合 适 变 换 h*:X → W,使PS(W,Y)=PT(W,Y),这样便能够避免实例迁移中的估计问题[5]。
1.2.1 稀疏非负矩阵分解
稀疏特征学习是一种典型的特征迁移学习方法,但该稀疏性是不被控制的,而非负稀疏矩阵分解(sparse non-negative matrix factorization,SNMF)则可通过定义稀疏因子控制基矩阵或系数矩阵的稀疏性[6],充分表现局部表征整体的优势,其中特征矩阵W和系数矩阵H可以是同时稀疏的,也可以只有一个是稀疏的。
SNMF算法的目标函数为

使得 W,H ≥0,Ssparseness(wi)= Sw,Ssparseness(hi)= Sh,其中:且Sw为特征基矩阵W的稀疏因子,Sh为系数矩阵H的稀疏因子,n是样本x的维数[7]。

1.2.2 多任务学习下非负稀疏特征迁移学习

图1 2个数据源对应的子空间的结构示意图Fig.1 Schematic diagram of the subspace corresponding to the two data sources
在进行矩阵分解时,可利用划分后的3个子空间表示矩阵X1和X2:

数据源层次的分解利用W和H进行表示,而子空间层次的分解利用w、h表示。在非负性条件的约束下,对矩阵X1和X2标准化分解的累加错误[8]的最小值作为上述非负矩阵分解的目标函数:

式中:A*是A的共轭转置矩阵,σi是矩阵A的奇异值。添加稀疏性约束到系数矩阵H,则上面2个目标函数可表示为
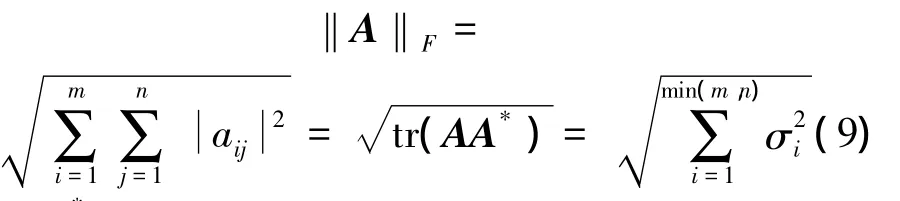


式中:参数ηi>0为可实现的压缩,正则化参数为βi(βi>0)。在以上2个公式中,η1和η2是进行压缩的参数,本文选择矩阵X1和X2中元素的最大值作为η1和η2的值。β1和β2是用来控制系数矩阵稀疏性的l1范数正则化参数,该参数主要作用是进行H矩阵近似的准确性和稀疏性之间的平衡。
式(10)、(11)是非负约束的最优化问题,可以利用投影梯度策略和乘法更新策略对这类优化问题进行求解。乘法更新策略能够在平衡快速收敛和自动选择梯度下降幅度间取得较好的效果[9]。
2 混合迁移学习方法
针对上节对2种迁移学习方法讨论,本节提出了一种混合迁移学习方法,以基于多任务稀疏非负特征学习为基础,同时引入实例迁移学习,这样既综合了实例迁移和特征迁移的优点,又充分考虑并利用了平衡迁移过程中分类器的适应性和推广性的特点。
2.1 混合迁移学习总体思想
将实例迁移引入多任务稀疏特征学习,其具体思想如下:
1)取XS和XT中具有相同标记的数据,建立特征空间子集X12,其中,XS为标记的源领域的训练数据集,XlT为少量的目标领域数据集的标注样本;
2)采用谱聚类的方法对特征空间子集X12中的样本数据进行聚类;
3)剔除聚类后孤立的样本数据,建立新的特征子空间;
4)采用多任务学习下稀疏非负矩阵的分解算法,实现迁移学习。
2.2 基于谱聚类的实例迁移学习
从1.2.2节的算法中可知矩阵X1和X2的共享基子空间w12在矩阵分解和迁移学习中起到了重要作用。但算法中w12的选取却并未经过任何筛选,只是直接采用了2个领域中具有相同标记的一些数据,容易受到噪声点的影响。
因此,本文将采用谱聚类算法筛选学习样本,以引入实例迁移学习[10]。利用数据集构建出一张图,将数据的划分转化为图的划分问题。利用图中的顶点表示样本点,边则反映出的是各样本点间的关系。一般地,谱聚类算法中用来衡量数据间关系的度量标准是数据间的相似性,依此可构建出包含聚类过程所需信息的邻接矩阵,完成对样本的最优划分,达到不同类样本间的相似性较低,而同类样本具有较高的相似性的效果。
谱聚类的具体运算过程如下:
1)本文采用欧式空间的距离进行相似性度量,构造数据点集的相似性矩阵;
2)计算Laplacian矩阵L=D-W;
3)求解矩阵L的特征向量和特征值;
4)利用多个特征向量确定低维空间,并将数据点映射到这个低维空间中;
5)在低维空间中实现划分数据点的划分,这样就完成实例迁移的引入。
2.3 多任务学习下稀疏特征学习目标函数的求解
针对1.2.2节的多任务学习下稀疏特征学习算法对目标函数进行求解。采用变量交替的更新办法进行逐一变量的迭代计算。首先进行各个待更新变量目标函数的推导,在保证其他变量不变的条件下,推导出Hi更新需要的目标函数:
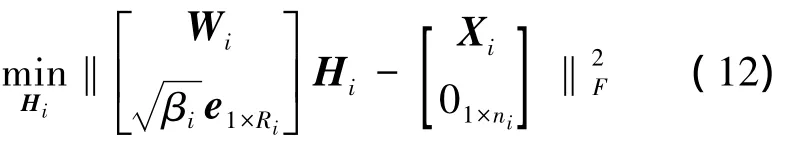

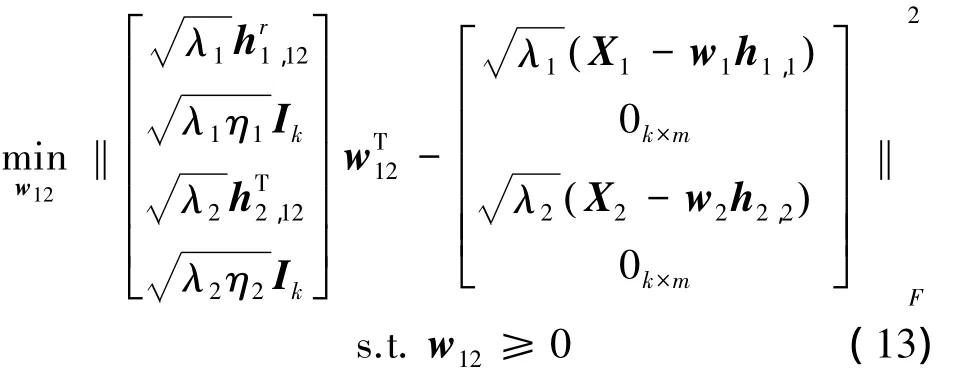
式中:k为共享子空间的维度。

由于乘法更新策略能够在平衡快速收敛和自动选择梯度下降幅度间取得较好的效果,本文采用交替的非负约束最小二乘法(alternating nonnegative constrained least squares,ANLS)[11]迭代进行目标函数式(10)、(11)的求解。利用ANLS进行迭代有2个关键点,即交替的处理和非负约束的最小二乘法。多任务学习下稀疏特征学习算法的具体过程如下:
1)输入2个不同数据源上构建的特征——标注矩阵 X1和 X2,参数 R1、R2、k、η1、η2、β1、β2和阈值ε以及最大循环迭代次数MAX;
3)对 w12、w1、w2、H1、H2进行随机初始化;
4)进行如下的迭代,直到收敛;
①根据式(12),运用NLS算法求解进行Hi更新,其中 i∈ 1,2{ };
②根据式(13),运用NLS算法求解进行w12更新;
③根据式(14),运用NLS算法求解进行wi更新,其中 i∈ 1,2{ };
5)输出结果,包括 w12、w1、w2、H1、H2等。
第 3 步采用了随机初始化参数 w12、w1、w2、H1、H2,为了减少随机初始化引起的不确定性,故后续采用多次实验的平均值作为实验结果。
第4步采用了ANLS进行Hi、w12、wi等量交替更新(i∈ 1,2{ })。此时,收敛条件有2个:1)通过设置阈值ε来判断,当连续多次矩阵的更新迭代不再发生变化时,认为算法达到了收敛;2)在算法中设置了最大迭代次数MAX用以限制算法的迭代次数。当收敛达到以上2个条件中的任意一个便停止迭代。
最后,在矩阵X1和X2的共享基子空间w12以及独立的基子空间w1和w2的基础上,通过不断地迭代更新共享基子空间w12这个桥梁,促使2个数据源相互迁移利用,实现2个数据源知识的迁移学习。
2.4 基于混合迁移方法的医学图像语义标注
根据本文提出混合迁移方法,给出应用于医学图像语义标注的方案。
输入:2个数据集上分别构建的矩阵X1和X2,2个数据集上的图片在标签特征空间上的表达T1和T2,待标记图片I;
输出:需要返回的语义T;
1)利用本文算法,对矩阵X1和X2进行分解得到

2)对输入的样例图片I,提取sift特征,并利用特征包(bag of features,Bof)方法[12],得到该图片在视觉单词特征空间V上的向量表达q;
3)利用NLS算法求解下式所示最优化问题,得到q在基矩阵W1上的映射h
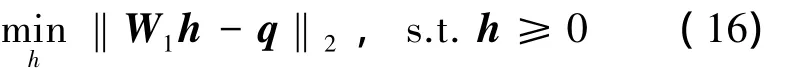
4)对于目标数据集的每一张图片,比如说第r张,其在基矩阵W1上的映射hr(即矩阵W1的第r个列向量),可按下式计算该图片与查询的相似度:
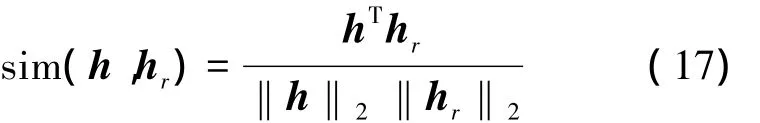
5)按相似度排序所有图片;
6)得到最相关的前u张图片组成图片集合U;
7)统计集合U中的语义标签,并按频率排序;
8)将出现频率较高的几个语义标签作为该幅图像的语义。
3 基于混合迁移学习的医学图像检索
利用2.4节中给出的流程进行医学图像语义标注并进行检索。本文将采用200幅肺部病变图像作为源领域数据D1,100幅具有胸膜病变的图像作为而目标领域数据D2,在此,可以通过D1数据集上的相关图片形成的70个有效的视觉单词V1,把它看做特征集合S1(此处特征空间即视觉单词的特征空间)。与此类似,利用D2数据集上的部分图片形成的70个视觉单词V2可以看成是特征集合S2。S1和S2的交集与并集为Sj和Su,Sj对应的基数为mj,Sμ对应的基数为mμ。易得到mμ=m1+m2-mj。此时,mj=20,进一步推出 mu=70+70-20=120,得到视觉单词的特征空间(维度为120)。以此,在后续的分析中使用Bof的方法在得到100幅图像的表达得到30幅图像的表达。采用2.4节的语义标注算法对图中未标注的70幅图像进行标注。表1给出了部分图像的语义标注结果。

表1 部分图像语义标注结果Table 1 Part of the image semantic annotation
本文以医生对图像的描述为判断语义标注是否准确为评价标准,统计所有图像标注的情况。本文的实验选取对图像标注的出现频率较高的4个关键词作为该幅图像的语义,首先统计每幅图像语义标注的正确率。具体统计如图2所示。
通过图2给出的单幅图像标注正确率的统计结果可以看出,不存在正确率为0%的图像,即不存在通过本算法进行标注的4个语义关键词都不正确的情况;正确率为25%(即标注出的4个语义关键词中只有一个为正确的)的图像中有11幅,占所有待标注图像的15.7%;正确率为50%的图像中有28幅,占所有待标注图像的40%;正确率为75%的图像中有15幅,占所有待标注图像的21.4%;正确率为100%的图像中有28幅。
统计原有的多任务学下稀疏非负矩阵的分解并采用本文的语义预测算法进行语义标注,同样采取4个语义关键词标注,统计这种算法的语义标记正确率,并与本文算法进行比较,得到统计图如图3。

图2 单幅图像标注正确率统计Fig.2 Statistical accuracy of single image annotation
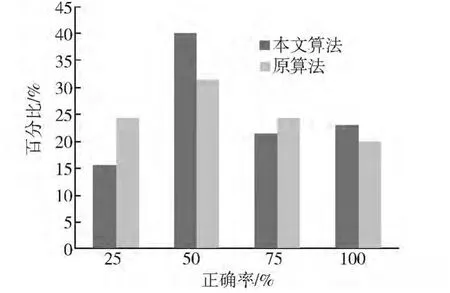
图3 2种算法不同正确率图像个数占图像总数百分比比较Fig.3 Comparison between percentages of images of different accuracies in total images within two algorithms
由图3可以看出,与原算法相比,本文提出的算法对大多数图像都有较好的标注能力,且标注的4个关键词也较为准确。其在图像标注正确率上有了一定的提高,尤其是降低了标注正确率较低(25%)的图像个数,使其在正确率为50%的情况下图像的数目较高,在正确率为75%和100%的情况下相较于原算法而言不分伯仲。故本文提出的算法能够有效提高图像语义标注的正确率。
4 结束语
分析了传统机器学习存在的不能够借鉴相似领域中知识,每次学习都是从零开始的问题,并针对这一问题,以医学图像语义标注为例,开展了研究。
通过对实例迁移和特征迁移进行分析发现,前者侧重于挑选源领域中与目标领域数据分布相似且对目标领域训练任务有帮助的那些数据。而后者通过挖掘隐含在数据间的相似特征从而搭建起领域间相互联系的桥梁,更好地实现领域间知识的迁移,因此本文综合了2种迁移学习的优点,使其互相补充,从而达到对医学图像语义准确标注的目的。
[1]GAO J,FAN W,JIANG J,et al.Knowledge transfer via multiple model local structure mapping[C]//Proceedings of the 14th ACM International Conference on Knowledge Discovery and Data Mining.LasVegas,USA,2008:283-291.
[2]ZHANG Y,YEUNG D Y.Transfer metric learning by learning task relationships[C]//Proceedings of the 16th ACM SIGKDD Conference on Knowledge Discovery and Data Mining.Washington DC,USA,2010:1199-1208.
[3]GOLDWASSER D,ROTH D.Active sample selection for named entity transliteration[C]//Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics.Columbus,USA,2008:53-56.
[4]吕静.基于实例的迁移算法研究[D].太原:山西财经大学,2013:7-8.
LYU Jing.Research of transfer learning algorithm based on instance[D].Taiyuan:Shanxi University of Finance & Economics,2013:7-8.
[5]覃姜维.迁移学习方法研究及其在跨领域数据分类中的应用[D].广州:华南理工大学,2011:5-20.
TAN Jiangwei.Research of transfer learning and its application in classifying cross-domain data[D].Guangzhou:South China University of Technology,2011:5-20.
[6]LEE D D,SEUNG H S.Learning the parts of objects by nonnegative matrix factorization[J].Nature,1999,401:788-791.
[7]宋金歌,杨景,陈平,等.一种非负矩阵分解的快速稀疏算法[J].云南民族大学学报:自然科学版,2011(20):262-266.
SONG Jinge,YANG Jing,CHEN Ping,et al.A fast and sparse algorithm for nonnegative matrix factorization[J].Journal of Yunnan University of Nationalities:Natural Sciences Edition,2011(20):262-266.
[8]GUPTA S,PHUNG D,ADAMS B.A matrix factorization framework for jointly analyzing multiple nonnegative data sources[C]//Procs of Text Mining Workshop,in conjuction with SIAM Int Conf on Data Mining.Arizona,USA,2011.
[9]马帅.基于稀疏非负矩阵分解的图像检索[D].杭州:浙江大学,2012:18-27.
MA Shuai.Image retrieval by joint nonnegative matrix factorization with sparse regularization[D].Hangzhou:Zhejiang University,2012:18-27.
[10]BENTHEM M H V,KEENAN M R.Fast algorithm for the solution of large-scal non-negativity-constrained least squares problems[J].Journal of Chemometrics,2004,18:441-450.
[11]KIM H,PARK H.Sparse non-negative matrix factorizations via alternating non-negativity-constrained least squares for microarray data analysis[J].Bioinfonnaties/Computer Applications in The Biosciences,2007,23:1495-1502.
[12]刘继晴.基于多特征融合的视频高层语义概念检测[D].北京:北京邮电大学,2011:25-27.
LIU Jiqing.High-level video senmantic concept detection based on multiple features[D].Beijing:Beijing University of Posts and Telecommunications,2011:25-27.
