一种基于QBC的SVM主动学习算法
2015-06-05徐海龙别晓峰吴天爱
徐海龙,别晓峰,冯 卉,吴天爱
(空军工程大学防空反导学院,陕西西安710051)
一种基于QBC的SVM主动学习算法
徐海龙,别晓峰,冯 卉,吴天爱
(空军工程大学防空反导学院,陕西西安710051)
针对支持向量机(souport vector machine,SVM)训练学习过程中样本分布不均衡、难以获得大量带有类标注样本的问题,提出一种基于委员会投票选择(query by committee,QBC)的SVM主动学习算法QBC-ASVM,将改进的QBC主动学习方法与加权SVM方法有机地结合应用于SVM训练学习中,通过改进的QBC主动学习,主动选择那些对当前SVM分类器最有价值的样本进行标注,在SVM主动学习中应用改进的加权SVM,减少了样本分布不均衡对SVM主动学习性能的影响,实验结果表明在保证不影响分类精度的情况下,所提出的算法需要标记的样本数量大大少于随机采样法需要标记的样本数量,降低了学习的样本标记代价,提高了SVM泛化性能而且训练速度同样有所提高。
主动学习;支持向量机;委员会投票选择算法;分类
0 引 言
经典的支持向量机(support vector machine,SVM)训练算法都是基于大量带有类标记样本的监督学习方法,而在很多的实际应用中,对样本集进行类别标记存在着代价昂贵、枯燥乏味或是异常困难等问题,而获取未被标注的样本则相对容易,同时大量未标注样本含有丰富的有助于学习器的信息,如有效地利用未标注样本无疑将在一定程度上提高学习算法的性能[1]。
面对上述这种情况,传统的监督学习方法,即被动学习要构建分类正确率满足要求的分类器将是十分困难的。对此,机器学习领域中的主动学习(active learning,AL)可以有效解决SVM训练过程中的这一类问题[1-5],在学习过程中,学习机器可以根据学习进程主动选择对分类器性能最有利的样本作为候选样本,若候选样本是未标记的样本,则将候选样本提交领域专家进行类别标记,然后将这些样本加入到已有的训练样本集中,加入的新样本将能够最大程度地提高SVM对未标记样本软分类的准确性,这样在训练样本集较小的情况下以尽可能少的标记样本训练获得分类正确率较高的SVM分类器,从而降低构建高性能SVM分类器的代价。
根据在主动学习进程中选择“最有利”样本策略或方法的不同,不同样本选择策略对应不同的主动学习算法,如文献[4]提出的误差减少的抽样即期望错误率缩减方法,该方法选择这些能使当前分类器对测试样本集分类误差最小的样本作为“最有利”或“最富有信息”的样本,虽然这种方法分类准确率高,但是选择了过多的冗余样本,而且在每次选择样本之前都必须搜索整个样本空间,才能确定选择哪些样本作为候选标记样本,因而存在着训练学习时间长、计算复杂度高等问题。文献[6]提出的不确定性抽样(uncertainty based sampling,UBS)样本选择方法,即不确定度缩减方法,其选择当前分类器最不能确定其分类的样本作为候选标记样本,但此方法易于选择这些“奇异点样本”——这些样本具有较高的分类不确定性,而将这些“奇异点样本”加入训练样本集会使得分类器的分类误差加大从而产生误差传播问题。文献[7- 8]提出了基于委员会投票的样本选择方法(query by committee,QBC),这种方法根据已标记样本集训练两个或多个分类器组成“委员会”,利用委员会中各个“委员”对未标记样本进行标记投票,然后选择投票结果最不一致的样本作为候选标记样本,但此方法同样可能选择奇异点,对此,文献[9- 10]也对QBC做了相应的改进,如文献[10]中采用了改进的QBC和代价敏感支持向量机(cost-sensitive SVM,CS-SVM),减少了样本的标记代价,对样本分布不均衡中不同类的样本赋予不同的误分代价。
针对上述主动学习存在的这些问题,受文献[2,10]启发,提出基于改进的加权SVM和改进的QBC主动SVM(QBC based-active SVM,QBC-ASVM)训练算法,减少样本分布不均衡对SVM主动学习性能的影响,抑制由于将“不确定性”样本加入训练样本集而产生的误差传播问题以及选择过多冗余样本,以尽可能少的标记样本获得较高的SVM分类准确率。
1 改进的加权SVM
在SVM主动学习的初始阶段,存在标记样本少且样本分布不均匀等问题,如使用标准的SVM,SVM训练学习中产生的最优分界面将向间隔区域中样本较少的类别方向偏移,这种偏差行为将导致SVM动学习中可能采样到重复的、相似的、无意义以及孤立的样本。为此SVM主动学习算法中训练初始SVM分类器时,使用如下一种改进的加权SVM[11],对不同类别或不同样本采用不同的权重系数,以提高分类性能。其原始最优化问题为:

式中,si表示对不同样本的权重;λi为类yi的权重,其余参数同SVM广义最优分类超平面目标函数。
随着SVM主动学习的进程,为了能反映主动学习选择的未标记样本对SVM训练的贡献,减少样本分布不均衡对SVM学习性能的影响,受Co-EM SVM算法[2,10]启发,在SVM主动学习算法循环递推学习中的基分类器采用如下一种改进的加权SVM,其原始最优化问题可以描述为

式中,si,表示对不同样本的权重;λi为类的权重;Cs表示主动学习所选择的未标记样本对分类器训练的贡献;为领域专家对样本的标记,其余参数与式(1)及Co-EM SVM算法[2]同。
式(2)给出的改进的加权SVM的对偶问题为

式(3)中,加权SVM的权重系数的确定可以采取如下方法:
首先,在SVM主动学习训练的初始阶段,令正负类样本的类别权重参数λi与初始训练集中的正负类样本数成反比,同时每个样本的权重参数si都取相同的值,即si=1/n,在此基础上构造初始的分类器;

式中,f(x)为SVM分类判别函数选择距离超平面最近的m个样本,即最有可能成为支持向量的样本作为SVM训练的增量样本,对标记后将其加入到训练样本集中,在新的训练样本集中。使用分类器寻找此时位于分类间隔中的正负类样本,然后令分类间隔中的样本的权重参数大于分类间隔外的样本的权重参数,并令正负类样本的类别权重参数与分类间隔中的正负类样本数成反比,然后进行SVM主动学习进程,并训练。
式(3)中,参数Cs的初始值可以设置一个很小的数,在每次SVM训练学习迭代中让其加倍,直到达到1;其余参数可以采用类似文献[2]中方法进行确定。
2 SVM主动学习中概率度量和差异性度量方法
在SVM主动学习算法中,需要对样本的类标记输出度量其标记置信度,而经典SVM的决策函数是“硬输出”,对SVM概率输出的研究,学者们也做了相关的研究。为了简化计算同时又不影响度量效果,对算法中需要样本类标记的概率值度量置信度的问题,根据文献[12]中的分析讨论,可用式(4)即样本与最优分类面之间距离的远近作为样本属于不同类别的概率度量,受文献[13- 14]中方法的启发,算法中采用式(5)来度量样本的类标记置信度。

式中,|f(xi)|/‖ω‖的意义同式(4),则根据式(4)易知0.5≤conf(xi)≤1,其值随f(xi)的变化如图1所示。从图1可以看出,conf(xi)越接近于0.5,表示样本xi的标记最不确定,所包含的信息越大,其相应的类标记置信度也较低;同时conf(xi)越接近于1,表示样本xi属于正类或负类的标记很确定,也即属于某类的置信度较高。
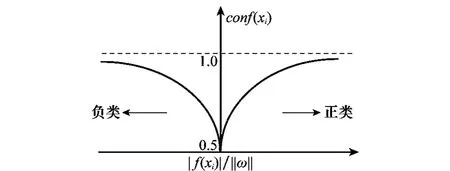
图1 置信度随样本距超平面距离变化趋势图
在SVM主动学习中,为了减少重复样本或相似度高的样本的选择,为此在角度多样性主动学习算法的基础上[15],使用式(6)给出的一种基于余弦函数度量候选样本xi与当前已标注样本L的差异性:

式中,n表示样本集L的样本数;dcos(xi,xj)为样本xi与xj的相似性,使用式(7)来度量。

式中,Φ(xi)和Φ(xj)分别为样本xi与xj经过非线性映射Φ,映射到某一特征空间H后对应的坐标,K(·,·)是SVM核函数。
在SVM主动学习中,为了综合考虑用式(4)距离度量候选样本到分类超平面“不确定性”以及所选样本与已标记样本的多样性,将式(6)修正为:
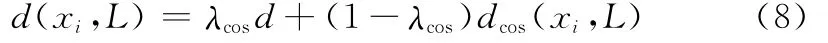
式中,d为式(4)的样本xi到分类超平面的距离;λcos为平衡因子(如均衡考虑可取0.5),即平衡样本到分类超平面的距离和训练样本集的多样性,以选择距离分类超平面最近并且与当前训练集中的样本具有最大差异性的“富有代表性”的样本来训练SVM分类器。
3 改进的QBC主动学习算法
QBC主动学习方法将训练的两个或多个分类器组成一个“委员会”,利用委员会中各个“委员”对未标记样本进行标记投票,然后选择投票结果“最不一致”的样本作为候选样本进行类别标记。根据度量投票结果“最不一致”方法的不同,当前主要有两种QBC方法:一种是由McCallum和Nigam[16]提出的采用相对熵(Kullback-Leibler divergence,KL-d)度量投票结果差异的方法,另一种是Argamon-Engelson和Dagan[17]提出的采用投票熵(vote entropy,VE)度量投票的不一致性的方法。
这两种QBC主动学习方法中,若采用相对熵来度量各个委员对某样本类标记投票“最不一致”,则相对熵值越大,说明委员会中成员对此样本的类标记投票结果差异就越大。但是采用这种度量法会漏选一些委员会成员类投票不一致的样本,这些样本正是基于QBC主动学习方法所要选择的样本;而如采用投票熵度量投票的不一致性,投票熵值越大,委员会成员的投票差异越大,虽然选择了投票不一致的样本,但是这种方法没有考虑各个委员对样本的类条件概率值——Pj(C|xi),这同样会导致漏选一些有助于学习器训练,即“最有利”或“最富有信息”的样本。表1和表2分别为3个SVM基分类器h1、h2以及h3组成的委员会,在实验中对3个样本x1、x2、x3基于两类问题(c1与c2)采用这两种度量方法的结果。

表1 QBC委员会分对样本的类投票结果

表2 3个样本的类投票熵和相对熵
从表2可以看出,样本x1与x2的相对熵值相当,如按相对熵法度量则两个样本将被选择为候选样本,而样本x1的投票熵为0即投票一致,这样以投票熵度量法则样本则将被漏选;同时对样本x3来说如以投票熵度量投票不一致性将被选择为候选样本,而如以相对熵度量则可能被漏选;由此可见,委员会成员中存在对样本x1与x3分类不确定性相当高的成员,而根据主动学习原理及思想,被分类器分类不确定的样本所含的信息量是丰富的[1,12],对其的标记将有利于分类器的训练,应当被选择为候选样本。对于QBC主动学习方法存在的这种问题,文献[9]中也做了相关讨论,并采用投票熵与相对熵互补法来解决此类问题。然而QBC算法在实际应用中易受样本分布不均匀的影响,如某些孤立样本点,其具有较高的分类不确定性将容易被选择为候选样本,而这些样本点的加入将极大影响分类器的性能,造成误差的传播,影响主动学习的性能。
为此,针对QBC方法存在的以上问题,结合第1节和第2节讨论的一些方法,在基于QBC的SVM主动学习算法中,给出以下的改进:
(1)QBC委员会由3个SVM分类器h1、h2、h3组成,同时在主动学习的初始阶段QBC各委员使用式(1)来训练学习确立,随着学习的进程各委员使用第1节给出的改进加权SVM来训练各个委员,以使QBC迭代训练的初始分类器具有较强鲁棒性,减少误差传播的影响。

(3)在通过QBC方法选择候选样本时,采用如下方法:
①首先根据式(9)计算样本xi的投票熵VE:

式中,V(ck,xi)为委员会成员对样本xi属于类别ck的投票数目。
②然后选择投票熵VE较大或大于某阈值VEth的样本,即投票最不一致的样本;而对VE小于某个阈值VEth或等于0的样本,即投票一致的样本,则计算根据式(10)计算其相对熵KL-d(xi):

式中,K是委员会中成员的数目;C是样本xi所有可能的类别集合C={ck},而Pavg(C|xi)是所有委员会中成员相对样本xi的类条件概率的平均值即

D[·‖·]是两个条件概率分布的信息度量,如对P1(C)、P2(C)则有
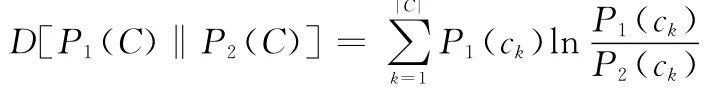
③根据式(8)计算样本xi的相似度dcos(xi,L),若其相对熵KL-d(xi)大于给定的阈值KL-dth并且dcos(xi,L)小于某个阈值Qdth,即其投票最不一致且训练样本集中不存在这些样本或较少,则将其加入候选样本集,以避免单独使用投票熵或相对熵方法造成信息量丰富样本的漏选,同时丰富训练样本集,使训练样本集保持多样化,减少孤立样本点被选择为候选样本的概率,加快主动学习迭代进程。
4 QBC-ASVM算法描述
Qth表示进行QBC主动学习的类标记置信度阈值;
Qdth表示主动学习中候选样本与训练样本集中对应类的样本相似度阈值;
VEth表示投票熵阈值;
KL-dth表示相对熵阈值;
4.2 算法过程
输入已标记样本集L(至少正负样本各一个),未标记样本集U,每次采样的样本数m,SVM训练算法Learn、IncLearn,阈值Tth、Qth、Tdth、Qdth、VEth、KL-dth,终止条件Sstop。
输出分类器fsvm,预标记样本。
初始化初始的训练样本集记为=L,对样本集进行BootstrapSample采样3次,记每次的样本集为Si,根据式(1)给出的加权SVM训练3个初始SVM分类器:=Learn(Si),并令初始集成分类器为
步骤1当进行第t(t=1,2,…)次训练时,判断SVM分类器是否达到终止条件Sstop,若满足则输出fsvm=结束训练,否则转到步骤2。
步骤2判断U是否为空,若是,输出fsvm=结束训练;否则,先对未标记样本用集成分类器进行预标记,然后据式(5)选择m个类标记置信度小于阈值,即当前分类器相对不确定的样本,并记为。
步骤3令第t次QBC主动学习选择的待标记样本集为空集,由、组成QBC委员会,对UQ中每个样本xi,根据式(9)计算样本xi的投票熵VE(xi)。
步骤4判断VE(xi)是否大于VEth,如果大于则更新待标记样本集X=X∪xi;如果VE(xi)小于VEth或者VE(xi)等于零,则根据式(8)计算样本xi与当前已标记样本L的相似度dcos(xi,L),根据式(10)计算样本xi的相对熵KL-d(xi),如果KL-d(xi)大于阈值KL-dth并且dcos(xi,L)小于相似度阈值Qdth,则更新待标记样本集X=X∪xi。
步骤5由领域专家Euser对中每个样本进行正确标记,记标记后的集合为。
步骤6在标记样本集及增量样本集上进行SVM增量训练=incLearn)(i=1,2,3),增量训练后将已标记样本集从未标记样本集U删除U=U-,将标记后的样本加入标记样本集
步骤7令i分别等于1、2以及3,估计的训练误差εi=MeasureError(),采用AdaBoost中的方法计算权重

根据SVM主动学习理论及QBC-ASVM算法描述可知,影响SVM主动学习性能的因素除了关键的候选标记样本选择策略外,还受其他的因素影响,如主动学习算法的终止条件Sstop,即SVM主动学习中需要估计什么时候SVM能到达最好的性能水平,以便停止标记样本并终止主动学习进程,避免花费大量的样本选择及标记代价而取的较小的性能提高,为此在QBC-ASVM算法中采用如下终止策略:
(1)在QBC-ASVM主动学习过程中对第t次选择候选标记样本时,在专家对其进行标记的同时,使用前次SVM分类器计算其分类正确率并记为ηk-1;
(2)统计QBC-ASVM主动学习第t次选择的最不确定性样本数记为Sk;
(3)当ηk达到学习器要求的某个阈值时并且其性能曲线呈现“rise-peak-flat”,即随着SVM主动学习进程,ηk在达到某个值后在一段时间里(可以SVM主动学习连续几次采样为判断)并没有明显的提升(实际应用中可以ηk的变化率作为判断)并且Sk呈现减少的趋势,则终止SVM主动学习。
5 实验结果及分析
为验证算法的正确性和有效性,通过实验比较了QBCASVM、随机采样Random、Active_Training、Active(VE)、Active(KL-d)算法的分类性能,其中Active(VE)、Active(KL-d)为QBC-ASVM算法中除步骤4分别仅采用投票熵、相对熵法度量法,Active_Training算法为未使用第1节给出的改进加权SVM,其余算法步骤同QBC-ASVM算法;实验中的数据使用UCI数据库中的breast-cancer-wisconsin、ionosphere、house-votes-84、hepatitis、credit-approval以及glass数据集。
在算法实验中,BootstrapSample采样随机地选择2%的样本作为SVM训练的初始样本,其余98%的样本去掉类别标记作为候选的未标记样本集。算法中SVM核函数采用高斯核函数,参数值为2;每次采样数m初始值设为8,对其调整按照随着分类器性能达到预定指标进行减1,以减少每次样本采样数。为保证主动学习选择“最不确定性”的样本,同时不漏选“富有信息”的样本,取阈值Qth=0.6、VEth=0.55、KL-dth=0.045,同样,为了避免选择重复类似的样本,保证选择的样本具有代表性,取阈值Qdth<0.5较为合适,算法中取Qdth=0.45。
为了说明问题,对每个数据集上的实验重复5次然后取其平均值,表3给出各算法在标准数据集上的分类正确率性能比较,其中std为实验中相应数值结果的标准差,底纹加黑数值为标记样本个数。其余算法对应的样本数为选择的候选样本并经领域专家进行标记。
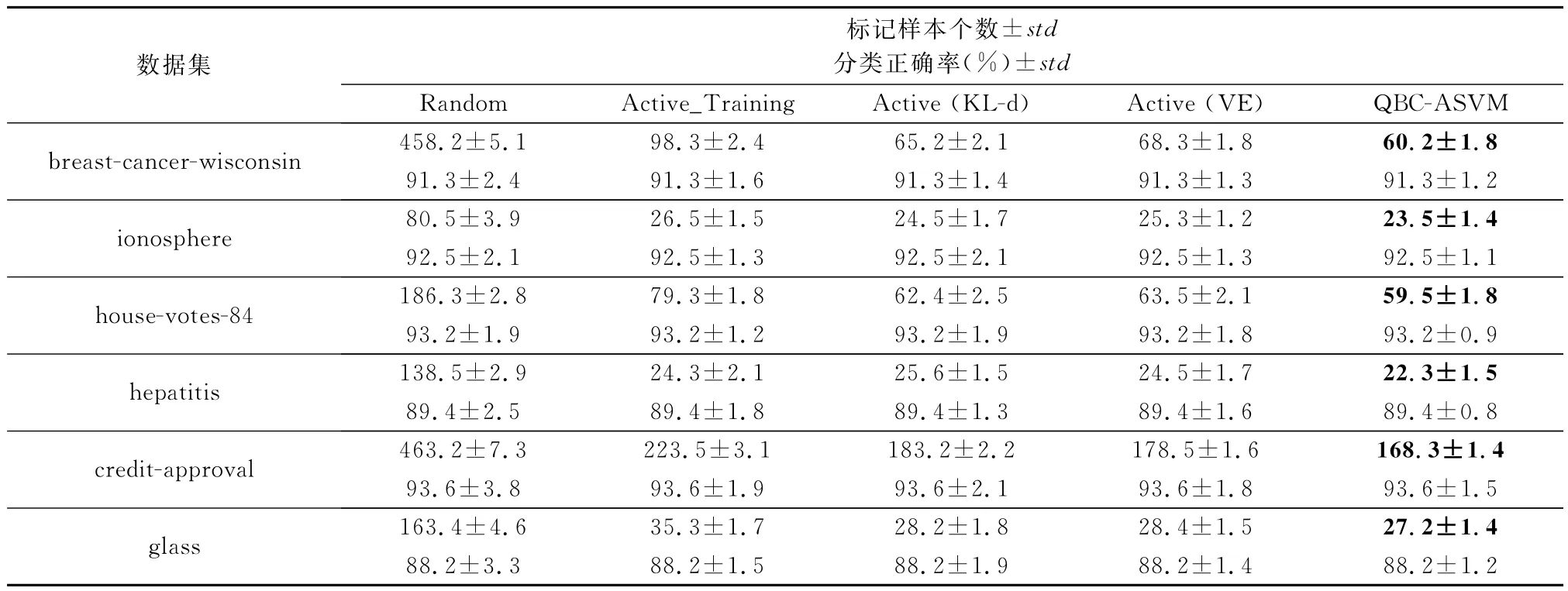
表3 各算法标记样本数与分类正确率性能比较
由表3以及图2和图3给出的各算法在数据集breast-cancer-wisconsin、hepatitis上的性能变化趋势图可以看出,QBC-ASVM、Active_Training、Active(VE)以及Active(KL-d)4种算法相比随机采样算法Random,在学习训练获得相同的SVM分类正确率时,其使用的标记样本数都明显少于后者,这种现象尤其在训练学习的初始阶段更明显;同时对QBC-ASVM算法来说,在达到相同的分类正确率时相比仅采用投票熵或相对熵度量的方法Active(VE)或Active(KL-d),后两者分别需要多标记7.6%、7.8%的样本;同时可以看出,在训练达到相同的分类正确率时,相比Active_Training算法,采用第1节给出的改进的加权SVM的QBC-ASVM、Active(VE)以及Active(KL-d)算法所标记的样本少于Active_Training算法,尤其在训练的初始阶段Active_Training算法呈现时高时低现象,即相比其他3种算法,标记了更多的样本,而分类正确率提高不明显,这说明了Active_Training算法在算法的初始阶段,由于样本分布不均衡,可能采样到孤立点导致分类正确率变化。
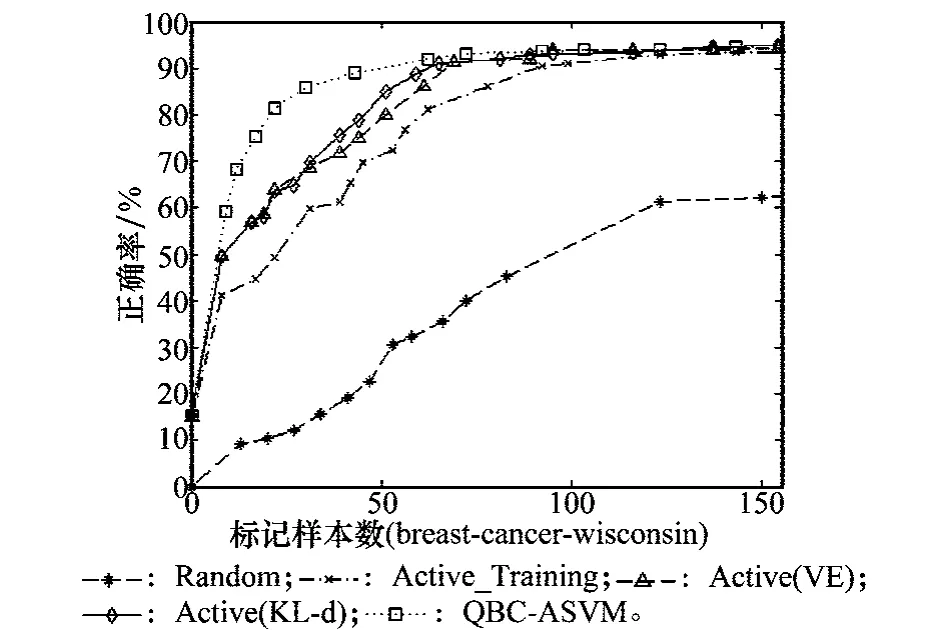
图2 各算法在数据集breast-cancer-wisconsin上的实验比较

图3 各算法在数据集hepatitis上的实验比较
从图2和图3可以看出来,QBC-ASVM算法在标记大概60个样本、Active(VE)以及Active(KL-d)算法在标记90多个样本时,其分类正确率都已达90%多,随着学习的进程,各算法的性能曲线都趋于“平稳”,这个时候应该根据第4节中给出的终止主动学习策略终止主动学习进程,避免花费大量的样本选择及标记代价而取的较小的性能提高。
6 结 论
本文在研究分析传统SVM训练算法存在的局限性——即传统的SVM训练方法都是基于大量带有类标记样本的监督学习以及现有主动学习在SVM训练中所存在的一些问题的基础上,针对大量标记样本难以获得或标注代价高,学习中样本分布不平衡等问题,提出了改进的QBC主动学习方法,将其应用于SVM训练学习过程中,通过实验验证了算法的有效性和可行性,这种方法可以有效减小主动学习算法的采样次数,降低标注代价。
[1]Long J,Yin J P,Zhu E,et al.A committee-based mis-classification sampling algorithm in active learning[J].Computer Engineering&Science,2008,30(4):69- 72.(龙军,殷建平,祝恩等.主动学习中一种基于委员会的错误分类采样算法[J].计算机工程与科学,2008,30(4):69- 72.)
[2]Zhao W Z,Ma H F,Li Z Q,et al.Efficient active leaning for semi-supervised document clustering[J].Journal of Software,2012,23(6):1486- 1499.(赵卫中,马慧芳,李志清,等.一种结合主动学习的半监督文档聚类算法[J].软件学报,2012,23(6):1486- 1499.)
[3]Xu J,Shi P F.Active learing with labled and un Labeled samples for content-based image retrieval[J].Journal of Shanghai Jiaotong University,2004,38(12):2068- 2072.(徐杰,施鹏飞.图像检索中基于标记与未标记样本的主动学习算法[J].上海交通大学学报,2004,38(12):2068- 2072.)
[4]Cohn D A,Ghahramani Z,Jordan M I.Active learning with statistical models[J].Journal of Artificial Intelligence Research,1996,4:129- 145.
[5]Roy N,McCallum A K.Toward optimal active learning through sampling estimation of error reduction[C]∥Proc.of the 18th International Conference on Machine Learning,2001:441- 448.
[6]Lewis D D,Gale W.A sequential algorithm for training text classifiers[C]∥Proc.of the 17th Annual International ACM-SIGIR Conference on Research and Development in Information Retrieval,1994:3- 12.
[7]Seung H S,Opper M,Sompolinsky H.Query by committee.[C]∥Proc.of the 15th Annual ACM Workshop on Computational Learning Theory,1992:287- 294.
[8]Freund Y,Seung H S,Samir E,et al.Selective sampling using the query by committee algorithm[J].Machine Learning,1997,28(2/3):133- 168.
[9]Zhao Y,Mu Z C,Dong J,et.al.A credit risk evaluation model for telecom clients based on query-by-comtitee mehtod of active learning[J].Journal of University of Science and Technology Beijing,2007,29(4):442- 445.(赵悦,穆志纯,董洁,等.基于QBC主动学习方法建立电信客户信用风险等级评估模型[J].北京科技大学学报,2007,29(4):442- 445.)
[10]Tang M Z,Yang C H,Gui W H.Fault detection based on modified QBC and CS-SVM[J].Control and Decision,2012,27(10):1489-1493.(唐明珠,阳春华,桂卫华.基于改进的QBC和CS-SVM的故障检测[J].控制与决策,2012,27(10):1489- 1493.)
[11]Lin C F,Wang S D.Fuzzy support vector machine[J].IEEE Trans.on Neural Networks,2001,13(2):464- 471.
[12]Xu H L,Wang X D,Liao Y,et al.Incremental training algorithm of SVM based on active learning[J].Control and Decision,2010,25(2):282- 286.(徐海龙,王晓丹,廖勇,等.一种基于主动学习的SVM增量训练算法[J].控制与决策,2010,25(2):282- 286.)
[13]Hu Z P.An active learning strategy of SVM via optimal selection of labeled data[J].Signal Processing,2008,24(1):105- 107.(胡正平.基于最佳样本标记的主动支持向量机学习策略[J].信号处理,2008,24(1):105- 107.)
[14]Zhang X,Xiao X L,Xu G Y.Probabilistic outputs for support vector machines based on the maximum entropy estimation[J].Control and Decision,2006,21(7):767- 770.(张翔,肖小玲,徐光祐.基于最大熵估计的支持向量机概率建模[J].控制与决策,2006,21(7):767- 770.)
[15]Panda N,Goh K S,Chang E Y.Active learning in very large databases[J].Multimedia Tools and Applications Archive,2006,31(3):249- 267.
[16]McCallum A K,Nigam K.Employing EM and pool-based active learning for text classification[C]∥Proc.of the 15th International Conference on Machine Learning,1998:350- 358.
[17]Argamon-Engelson S,Dagan I.Committee-based sample selection for probabilistic classifiers[J].Journal of Artificial Intelligence Research,1999,11:335- 360.
Active learning algorithm for SVM based on QBC
XU Hai-long,BIE Xiao-feng,FENG Hui,WU Tian-ai
(College of Air and Missile Defense,Air Force Engineering University,Xi’an 710051,China)
To the problem that large-scale labeled samples is not easy to acquire and the class-unbalanced dataset in the course of souport vector machine(SVM)training,an active learning algorithm based on query by committee(QBC)for SVM(QBC-ASVM)is proposed,which efficiently combines the improved QBC active learning and the weighted SVM.In this method,QBC active learning is used to select the samples which are the most valuable to the current SVM classifier,and the weighted SVM is used to reduce the impact of the unbalanced data set on SVMs active learning.The experimental results show that the proposed approach can considerably reduce the labeled samples and costs compared with the passive SVM,and at the same time,it can ensure that the accurate classification performance is kept as the passive SVM,and the proposed method improves generalization performance and also expedites the SVM training.
active learning;support vector machine(SVM);query by committee(QBC);classification
TP 181
A
10.3969/j.issn.1001-506X.2015.12.31
徐海龙(1981- ),男,讲师,博士,主要研究方向为模式识别、支持向量机、目标分配。
E-mail:xhl_81329@163.com
别晓峰(1979- ),男,讲师,博士,主要研究方向为目标分配、作战评估与仿真。
E-mail:58719591@qq.com
冯 卉(1982- ),女,讲师,硕士,主要研究方向为目标识别、目标分配、作战评估与仿真。
E-mail:fenghui_yy@126.com
吴天爱(197-7- ),女,讲师,博士研究生,主要研究方向为目标识别、目标跟踪。
E-mail:wuyh7277@163.com
1001-506X(2015)12-2865-07
2014- 12- 10;
2015- 04- 12;网络优先出版日期:2015- 07- 06。
网络优先出版地址:http://www.cnki.net/kcms/detail/11.2422.TN.20150706.1606.008.html
国家自然科学基金(61273275)资助课题
