基于改进Hadoop的受限玻尔兹曼机云计算实现
2015-06-01张立民范晓磊孙永威海军航空工程学院基础实验部山东烟台2600海军航空工程学院信息融合研究所山东烟台2600第二炮兵工程大学士官职业技术教育学院山东青州26500中国人民解放军960部队广东湛江5206
刘 凯,张立民,范晓磊,孙永威(.海军航空工程学院基础实验部,山东烟台2600;2.海军航空工程学院信息融合研究所,山东烟台2600;.第二炮兵工程大学士官职业技术教育学院,山东青州26500;.中国人民解放军960部队,广东湛江5206)
基于改进Hadoop的受限玻尔兹曼机云计算实现
刘 凯1,张立民2,∗,范晓磊3,孙永威4
(1.海军航空工程学院基础实验部,山东烟台264001;2.海军航空工程学院信息融合研究所,山东烟台264001;3.第二炮兵工程大学士官职业技术教育学院,山东青州261500;4.中国人民解放军91640部队,广东湛江524064)
摘 要:针对受限玻尔兹曼机(RBM)面对大数据时存在模型训练缓慢的问题,设计了基于Hadoop的RBM云计算实现方法。针对RBM训练方法,改进了Hadoop任务消息通信机制以适应模型迭代周期短的特点;设计了MapReduce框架,包括Map端实现吉布斯采样,Reduce端完成参数更新;依据Hadoop任务组合方式,将RBM的训练应用于深度玻尔兹曼机(DBM)中。通过手写数字识别实验证明,该计算方法在大规模数据条件下能够有效加速RBM训练,且适应于深度学习模型的学习。
关键词:云平台;受限玻尔兹曼机;Hadoop;并行编程
0 引言
基于能量模型的受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)[1]以其简单的人工神经网络形式和快速的学习算法,已经广泛应用于数据降维[2]、语音识别[3]、3D物体识别[4]、图像转换[5]以及高维时间序列建模[6]等机器学习问题,并形成了新的领域———深度学习[7]。
随着大数据时代的到来,如何解决海量数据带来的模型训练时间过长等问题成为了机器学习领域的研究热点。一般而言,解决这一问题的主要措施为模型训练的云计算化,以实现大规模数据的批处理[8]。
作为目前广泛应用的云计算平台,Hadoop具有计算效率高、稳定性好和开源等优点。近年来,为更好地提高平台执行效率,研究人员进行了多种优化措施。文献[9]针对Hadoop中资源共享问题,设计了公平调度算法;文献[10]通过延迟任务调度,增强了Hadoop运行时的数据迁移能力;文献[11]提出在分布式内存中增加保存map任务中间数据;文献[12]通过预测作业结束时间以加速任务的执行;文献[13]通过最小数据迁移量实现了Hadoop参数的自动优化;文献[14]平衡网络和磁盘带宽需求,以减小系统瓶颈的出现。虽然这些方法能够有效改善Hadoop系统性能,但对于机器学习模型训练等短任务的改善有限,因此深入优化Hadoop任务执行机制,调整作业执行流程可显著提高短作业执行效率。
文献[15]提出了基于Hadoop的RBM云计算方案,但缺陷在于仅将RBM的训练分为若干子任务,MapReduce机制优势难以发挥;且不适合于以RBM为底的深度学习模型训练的推广。本文以RBM训练在Hadoop平台下的实现作为研究内容,针对以往研究缺陷,通过两种措施,实现RBM的并行计算,即改进Hadoop任务消息模式以提高短任务执行效率和设计吉布斯采样的MapReduce框架,最后将其应用于深度玻尔兹曼机(Deep Boltz⁃mann Machine,DBM)训练中。实验表明,基于Hadoop的RBM云计算应用,解决了模型训练效率问题,且能有效提高深度模型的学习速度。
1 受限玻尔兹曼机及Hadoop平台
1.1受限玻尔兹曼机
受限玻尔兹曼机是在玻尔兹曼机(Boltzmann Machine,BM)的基础上,通过限制BM中层内单元连接,使得在给定同单元状态下临近层单元激活概率条件独立,其结构如图1所示。作为无向图模型,RBM中的可见单元层V,表示观测数据;隐单元层H,表现为特征检测器,其结构如图1所示。

图1 RBM单元连接图Fig.1 RBM unit connection diagram
以包含N个二值可见单元和M个二值隐单元的RBM为例,vi表示第i个可见单元的状态,hj为第j个隐单元状态。给定状态(v,h),模型的能量定义为
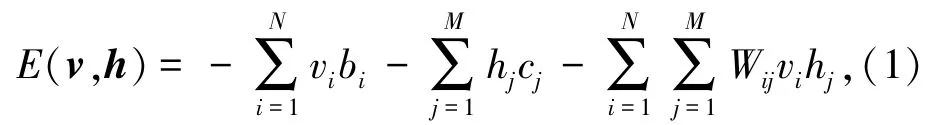
其中,Wij表示可视单元i与隐单元j之间的连接权值,bi表示可视单元i的偏置,cj表示隐单元j的偏置。
鉴于RBM层间单元无连接,故所有单元的激活状态都是条件独立的。隐单元和可见单元的后验激活概率,如式(2)、(3)所示:

其中,σ(x)=1/(1+exp(-x))。
针对RBM的训练,Hinton于2002年提出了对比散度(Contrastive Divergence,CD)算法。即首先通过执行吉布斯块采样(block Gibbs Sam⁃pling)———分别以各个训练数据作为初始状态,进行k次状态转移;然后将转移后的数据作为样本对Negative Phase估算均值实现参数更新。Hinton通过实验证明,在实际应用中,甚至只需要一次状态转移就能保证良好的学习效果。由此,在给定训练数据v(n)下,W.j的迭代如式(4)所示:

1.2Hadoop平台
Hadoop是一个开源的云计算平台,主要部分为Common、HDFS和MapReduce[16]。Common向其他子项目提供所需要的常用工具,HDFS为Ha⁃doop的文件系统,实现对分布式存储的底层支持,MapReduce是Google MapReduce的开源实现,主要用于任务并行化和程序支持。
作为Hadoop平台中任务分布处理的核心,MapReduce框架,相比于其他并行编程框架,具有负载平衡、扩展性良好以及高容错率等优势,成为了当前最有效的大数据处理解决方案之一。Ma⁃pReduce包含一个主节点(JobTracker)以及众多从节点(TaskTaracker)。JobTracker是Hadoop的核心节点,主要负责调度、管理作业(job)中的任务(task),TaskTracker作为任务节点,负责执行Job⁃Tracker分发过来的任务。
2 受限玻尔兹曼机的并行设计
2.1MapReduce设计
RBM训练MapReduce并行化的基本思路是,对RBM训练的参数迭代启动MapReduce计算过程,期间完成CD算法中Positive Phase和Negative Phase的计算,以及参数的更新。以更新RBM连接权值W为例,图2描述了RBM训练Map⁃Reduce并行化的实现方法。
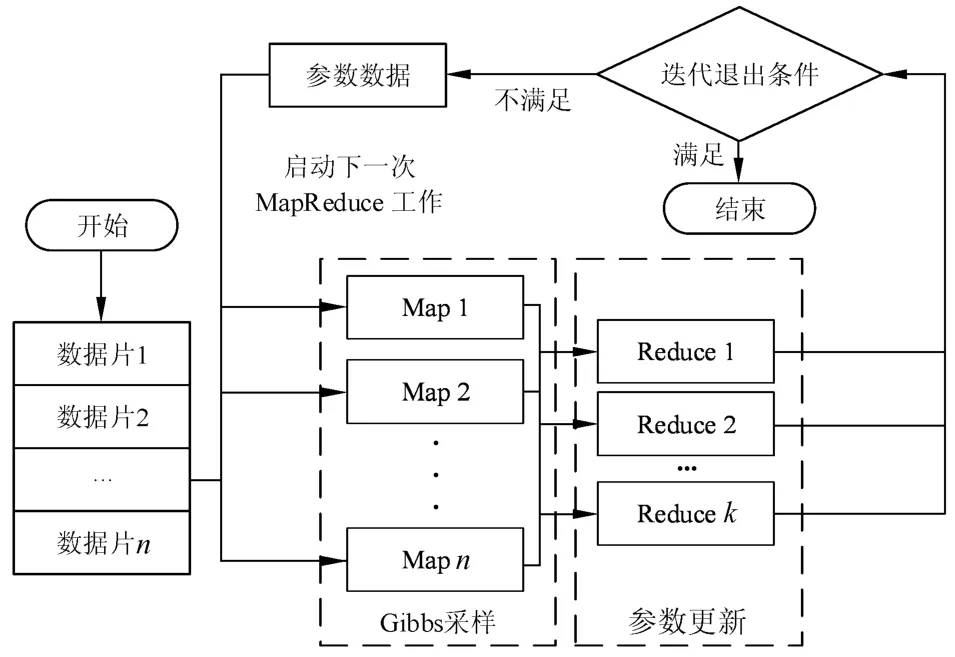
图2 RBM训练MapReduce并行化Fig.2 MapReduce parallelize for RBM training
为适合MapReduce计算模型对数据分片的要求,需要对待处理的训练数据进行规范化:在Ma⁃pReduce初始化阶段时,将原始训练数据转换为统一定义的格式,并按照行形式进行存储,从而保证数据在按行分片时行数据间没有相关性。MapRe⁃duce分片过程是由Hadoop环境实现,不需要编写代码。
1)数据规范
鉴于MapReduce在初始阶段的数据分片要求,将RBM训练集中的样本转换为行形式。所有训练数据总的数据格式为X#vector,Map函数输入要求的键值对<key,value>形式为<X,vector>,其中X为训练样本序号,vector表示训练样本向量。
2)Map函数设计
Map函数的任务是完成CD算法中的吉布斯采样,输入为训练样本和上一轮迭代(或初始随机)的RBM参数,输入数据<key,value>对的形式为<X,vector>。每个Map函数均读入RBM参数数据,Map函数对输入的训练样本执行吉布斯采样,并输出参数的更新值。依据RBM参数向量的不同,输出中间结构<key,value>键值对分为3类。
a)连接权值W:将维度大小为M×N(可见单元维度×隐单元维度)的W更新值ΔW映射成M× N个<key,value>,ΔW中第i行第j列元素对应的<key,value>对中key值为i#j,value值为ΔWij;
b)可见单元偏置b:Map函数将Δb映射为1×M个<key,value>,Δbi对应的<key,value>对中key值为i#,value值为Δbi;
c)隐单元偏置c:类似与b的映射关系,Δc映射为1×N个<key,value>,Δcj对应的<key,value>对中key值为#j,value值为Δcj。
综上所述,以训练样本<key,value>为例,Map函数的执行流程如下所示:
①依据key值判断信息类别,若为图像,选择卷积运算符,否则为点积;
②计算隐单元层激活概率;
③计算权重更新参数1(Positive Phase);
④更新隐单元层状态;
⑤计算可见单元层激活概率;
⑥更新可见单元层状态;
⑦计算隐单元层激活概率;
⑧计算权重更新参数2(Negative Phase);
⑨映射RBM参数矩阵,生成新的<key’,value’>;
⑩输出键值对<key’,value’>,key’为RBM参数矩阵元素索引,value’为对应的元素值。
3)Reduce函数设计
Reduce函数的任务是计算Map函数输出的ΔW、Δb和Δc对RBM参数的更新值,并将其输出至HDFS以供下一轮MapReduce Job使用。Reduce函数完成的工作是将对应的矩阵元素存入数组并累加求和,得到RBM参数的更新值,输出结果<key,value>对的形式类似于Map函数,也是RBM3种参数向量的元素键值对表达形式。
综上所述,以相同的键值key为例,Reduce函数的执行流程如下所示:
①根据key值定义新的<key’,value’>,初始化count=0,用于记录valueList中的元素个数;
②赋值key’=key;
③从valueList中取出一条数据,把其中的value与value’相加并更新value’;把其中的value数量与count相加并更新count值;
④重复执行步骤3,直至valueList为空;
⑤赋值value’=value’/count;
⑥输出键值对<key’,value’>,key’为RBM参数矩阵元素索引,value’为对应的元素值。
Reduce函数执行完以后,需要判断当前状态是否满足CD算法的迭代退出条件。CD算法一般设置2种迭代退出条件:1)迭代次数是否超过某个阈值;2)RBM参数的更新矩阵范数(一般为一阶或二阶范数)是否小于设定的阈值。如果满足条件,则算法结束,输出RBM参数;反之,将当前更新值叠加至RBM参数。
综上所述,方位向间歇采样散射波干扰可有效破坏自动相位搜索过程,不仅干扰信号无法被对消,所估相位还会使场景区域中大量真实点目标的回波被抑制或被增强,从而使得场景成像中出现类似噪声的杂乱明暗斑点.
2.2任务消息模式改进
从RBM训练的MapReduce设计可以看出,Map函数执行的是迭代次数较少的吉布斯块采样,且Reduce函数也仅需完成参数更新的加减运算。因此,对Hadoop进行优化也能够有效提高RBM训练效率,同时缩短平台运行时间。
通过对MapReduce框架机理分析发现,Hadoop任务是由TaskTracker向JobTracker发送基于周期性心跳报之后才会被传递的,因此作业的处理需要间隔一个心跳报周期。文献[17]通过改变任务消息模式,将“拉”模式改为“推送”模式,并将任务消息从心跳通信机制中分离出来,从而减少任务处理周期。但这种方法存在的问题为过多的消息通信增加了网络开销,会导致通信延时。
因此,本文对文献[17]设计的任务消息模式进一步优化,提出了改进措施:调整心跳报的发送条件改为两种,一是周期性中断;二是任务模式改变,这样既可以缩短任务分配时间,又能够避免单独增加任务消息的网络负担。综上,优化后的心跳报transmitHeartBeat()函数逻辑关系如图3所示。

图3 心跳报发送逻辑关系Fig.3 Logical relationship of heartbeat packets
2.3深度玻尔兹曼机训练实现
深度学习是一种通过建立类似于人脑信息处理机制进行分析学习的感知器结构,以形成抽象高层表示属性或特征,其特点在于具有多个隐藏层。
深度玻尔兹曼机和深度信念网络(Deep Belief Net,DBN)是两种常见的深度学习模型,两种结构均是由多层RBM叠加而形成的。本文以3层DBM为例,将RBM的Hadoop云计算实现应用于DBM的训练中,并把DBM的训练分为3个子过程,如下所示:
1)低层RBM训练子过程;
3)DBM的平均场估计子过程。
根据Hadoop框架特点,将DBM训练的每个子过程作为一个子任务,分别定义为Job_First、Job_Second和Job_MeanField。鉴于每个任务都是依据上一个任务的计算结果进行,因此需要向其添加依赖关系属性。
综上所述,DBM子任务属性定义和启动代码如下所示:

3 实验结果及分析
3.1集群环境
为了验证提出的DBM的Hadoop云计算加速性能,搭建了以下集群环境:1个Master节点、3个Slave节点,JDK版本1.6.27,Hadoop版本0.20.2,网络环境为100 M局域网,其中每个节点CPU型号均为Core i5。在本集群中,根据HDFS和Ma⁃pReduce框架要求,将Master主机部署为NameNode和JobTracker,Slave1~3。图4显示的是Hadoop集群中4个节点的状态信息。
3.2MNIST实验
实验对象:选用由Yann LeCun等人收集的手写数字图像库MNIST数据集[18]。该数据集包含了0到9的10个手写数字图像。鉴于MNIST数据集包含了70 000幅大小为28×28的数字图像,为了有效测试Hadoop云计算在不同规模数据集下的计算性能,将该数据集图像进行自拷贝以扩大数据规模。
实验设置:为了分析基于Hadoop的RBM训练效率与传统单CPU的串行运算差异,设计2种实验环境,分别为:1)采用单CPU执行环境;2)多CPU环境,即采用Hadoop平台。与此同时,设置3个实验对RBM的云计算设计进行验证。
1)实验1
实验1用于比较两种不同计算平台下的RBM训练效率。实验设置RBM中可见单元个数为784,隐单元个数为500,学习速率η=0.01,循环次数不超过2 000。经过实验,在不同规模图像集下完成上述RBM训练所消耗的时间(单位为s)对比如图5所示。

图4 Hadoop集群4个节点状态信息Fig.4 Information of four nodes in Hadoop cluster
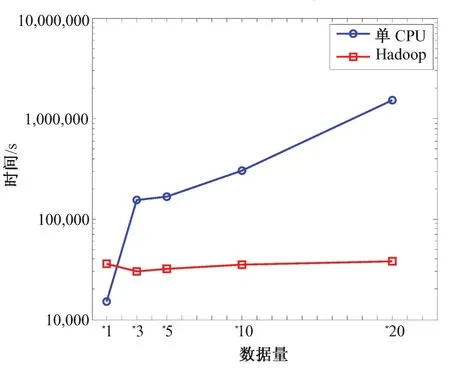
图5 RBM训练执行时间对比Fig.5 Comparison of RBM training execution time
从图5可以看出,当训练数据量较小时,采用Hadoop的训练时间略长于单CPU环境,原因在于Hadoop平台节点之间的启动和交互需要花费大量时间,降低了Hadoop的运行效率;数据量较大时,单CPU环境的DBM训练时间随着数据量的变大而急剧增大,但基于Hadoop的计算环境所耗费的时间没有太大变化,这表明Hadoop平台在处理海量数据时能够有效提高计算效率。鉴于实验环境和实验目的,数据集规模最高没有超过20次拷贝,但从现阶段的对比实验可以看出Hadoop平台在对RBM训练时处理大量数据时具有的优势和性能特点。
2)实验2
实验2用于比较Hadoop任务消息模式的改进效果。实验选用MNIST集合的10次拷贝作为训练数据;设置RBM中可见单元个数为784,隐单元个数为500,学习速率η=0.01,循环次数不超过2 000;选用3种不同任务消息模式作为对比条件,分别为传统Hadoop模式、心跳与任务分离模式[9]和本文设计的心跳报发送条件选择模式。实验选用对比指标为定义如式(5)所示的加速比S,且结果如图6所示:

其中,TCPU表示单CPU运行时间,THadoop表示Hadoop集群下的运行时间。

图6 不同任务消息处理模式下的RBM加速比Fig.6 RBM speedup ratio under different tasks messaging mode
从图6可以看出,经过与以往Hadoop任务消息处理模式的对比,新模式的RBM训练加速比有所增加。这表明通过增加心跳报发送条件的选择,提高了Hadoop云平台任务运行效率,证明了Hadoop改进的有效性。
3)实验3
实验3用于验证DBM训练的云计算效率。为达到实验目的,选用文献[1]设计的DBM模型结构,同时采用优化后的Hadoop任务消息发送模式,进行训练时间对比,其结果如表1所示。
从表中可以看出,基于Hadoop的DBM训练时间最短,单CPU环境较差;同时平均场估计耗时最长,但是Hadoop平台对该部分的加速比最大,体现了Hadoop平台对DBM训练时长的优化。
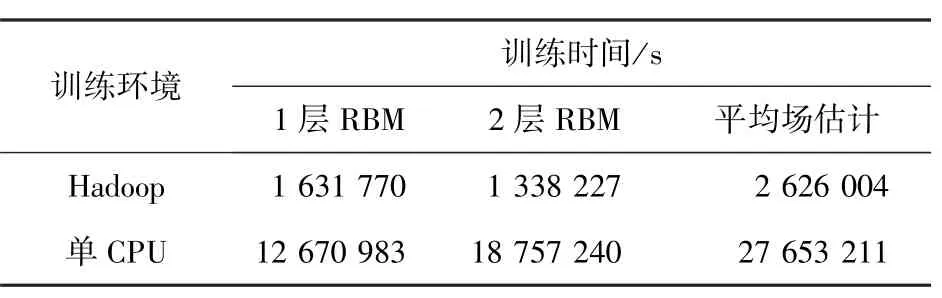
表1 DBM各项训练时间对比Tab.1 Comparison of DBM training execution time
4 结束语
本文采用基于改进Hadoop的RBM训练方法,实现了在云平台环境下RBM的加速训练。相对于单CPU环境下的RBM训练,该方法能够更好地处理大规模数据,促进了RBM模型在未来大数据环境下的实用;改进后的Hadoop任务消息发送模式,通过增加对平台周期性中断和任务模式判断的选择,缩短了Hadoop心跳报通信时间,提高了平台运行效率;与此同时,在此基础上设计了DBM训练的云计算实现,对于其他以RBM为基础的深度学习模型在云计算平台上的应用,具有较好的指导作用。
参考文献
[1]Salakhutdinov R Hinton G E.Deep boltzmann machines C //Proceedings of the 12th conference on Artificial Intelligence and Statistics Clearwater FL USA 2009 448⁃455.
[2]Zhang Y Salakhutdinov R Chang H A et al.Resource configurable spoken query detection using deep Boltzmann machines C //Proceedings of 2012 conference on Acoustics Speech and Signal Processing Kyoto Japan 2012 5161⁃5164.
[3]Ryan D P Daley B J Wong K et al.Prediction of ICU in⁃hospital mortality using a deep Boltzmann machine and dropout neural net C //Proceedings of 2013 conference on Biomedical Sciences and Engineering Oak Ridge TN USA 2013 211⁃216.
[4]Srivastava N Salakhutdinov R R Hinton G E.Modeling documents with deep boltzmann machines C //Proceedings of the 29th con⁃ference on Uncertainty in Artificial Intelligence Bellevue WA USA 2013 222⁃227.
[5]Eslami S M A Heess N Williams C K I et al.The shape boltzmann machine a strong model of object shape J .International Journal of Computer Vision 2014 107 2 155⁃176.
[6]Hinton G E.A practical guide to training restricted Boltzmann ma⁃chines R .Toronto Machine Learning Group University of Toronto 2010 129⁃136.
[7]Wang C Blei D M.Variational inference in nonconjugate models J .The Journal of Machine Learning Research 2013 14 1 1005⁃1031.
[8]余靖 刘盼盼.MapReduce框架下k⁃支配轮廓查询算法 J .燕山大学学报 2014 38 6 532⁃537.
[9]Apache Software Foundation.Apache Hadoop fair scheduler EB/OL . 2013⁃11⁃20 .http //hadoop.apche.org/common/docs/fair_scheduler.html.
[10]Zaharia M Borthakur D Sarma J et al.Delay scheduling a simple technique for achieving locality and fairness in cluster scheduling C //Proceedings of the 5th European conference on Computer systems Paris France 2010 265⁃278.
[11]Zhang S Han J Liu Z et al.Accelerating MapReduce with distrib⁃uted memory cache C //Proceedings of the 21th conference on Parallel andDistributedSystems.Piscataway Shenzhen Guangdong China 2009 472⁃478.
[12]Morton K Friesen A Balazinska M et al.Estimating the progress of MapReduce pipelines C //Proceedings of the 26th conference on Data Engineering Long Beach CA USA 2010 681⁃684.
[13]Tang X Wang L Geng Z et al.A Reduce Task Scheduler for Ma⁃pReduce with Minimum Transmission Cost Based on Sampling Evaluation J .International Journal of Database Theory and Ap⁃plication 2015 8 1 1⁃10.
[14]郭超 刘波 林伟伟 等.基于Impala的大数据查询分析计算性能研究 J .计算机应用研究 2015 32 5 1330⁃1334.
[15]郑志蕴 李步源 李伦 等.基于云计算的受限玻尔兹曼机推荐算法研究 J .计算机科学 2013 40 12 256⁃263.
[16]鲁伟明 杜晨阳 魏宝刚 等.基于MapReduce的分布式近邻传播聚类算法 J .计算机研究与发展 2012 49 8 1762⁃1772.
[17]顾荣 严金双 杨晓亮 等.Hadoop MapReduce短作业执行性能优化 J .计算机研究与发展 2014 51 6 1270⁃1280.
[18]LeCun Y Bottou L Bengio Y et al.Gradient⁃based learning applied to document recognition J .Proceedings of the IEEE 1998 86 11 2278⁃2324.
Realization of RBM cloud computing based on improved Hadoop
LIU Kai1ZHANG Li⁃min2FAN Xiao⁃lei3SUN Yong⁃wei4
1.Department of Basic Experiment Naval Aeronautical and Astronautical University Yantai Shandong 264001 China
2.Research Institute of Information Fusion Naval Aeronautical and Astronautical University Yantai Shandong 264001 China
3.Noncommissioned Officers Vocational and Technical Education College The Second Artillery Engineering University Qingzhou Shandong 262500 China 4.No.91640 Troops of PLA Zhanjiang Guangdong 524064 China
AbstractTo resolve the slow training of Restricted Boltzmann Machine for handling large data the realization of RBM training based on cloud platform Hadoop is designed.In view of the training method of RBM Hadoop tasks message mechanism was improved to suit RBM′s short iteration cycle MapReduce framework was designed including Map function implemented Gibbs sampling and Reduce function completed parameter update based on Hadoop task combinations RBM′s cloud training was used in Deep Boltz⁃mann Machine′s training.The handwritten numeral recognition experiments show that this cloud training method can accelerate RBM training effective under large⁃scale data condition and work well in deep learning model training.
Key wordscloud platform restricted Boltzmann machine Hadoop parallel programming
作者简介:刘凯(1986⁃),男,山东潍坊人,博士研究生,主要研究方向为文本信息检索、人工智能、数据库技术;∗通信作者:张立民(1966⁃),男,辽宁开原人,博士,教授,主要研究方向为计算机图形学、人工智能、军用仿真技术等,Email:iamzlm@163.com。
基金项目:国家自然科学基金资助项目(61032001)
收稿日期:2015⁃01⁃09
文章编号:1007⁃791X(2015)02⁃0145⁃07
DOI:10.3969/J.ISSN.1007-791X.2015.02.008
文献标识码:A
中图分类号:TP391.4
