基于复旦大学ERU数据的学科交叉程度与研究热点分析
2015-05-25张春梅张计龙殷沈琴汪东伟郭耀东
张春梅 张计龙 殷沈琴 汪东伟 郭耀东
(复旦大学图书馆,上海200433)
·信息资源开发与利用·
基于复旦大学ERU数据的学科交叉程度与研究热点分析
张春梅 张计龙 殷沈琴 汪东伟 郭耀东
(复旦大学图书馆,上海200433)
本文利用复旦大学ERU数据采集平台,从底层网络数据中获取用户访问图书馆电子资源时检索行为的动态数据,运用Session ID关系、因子分析和聚类分析等方法,分析我国高校学术研究的学科交叉程度及研究热点。结果表明,学科交叉研究采用动态数据源进行分析,可以拓展学科交叉研究的深度和宽度,弥补以往研究中仅针对静态数据分析研究的不足,促进学术研究和科学创新上获得新的生长点。
学科交叉;动态数据;Session ID;因子分析;聚类分析
当前学科交叉研究已成为科学技术发展的一个重要趋势。自20世纪初学科交叉研究的萌芽在美国出现后,人们便开始认识到学科交叉产生的新兴学科,因为其能够打破传统学科研究束缚,为学科发展创造新的生长点,为科技进步提供新动力的特点,引起世界各国的广泛关注。学科交叉借助其研究领域的独特优势在新技术开发、新兴产业应用研究等领域产生极大的影响力,其科学技术创新的能力也被置于极其重要的地位。
发现学科研究的交叉点,无异于找到学科研究的新起点,许多科研人员、学者都希望获得本学科与其他学科的交叉点、学科研究新的增长点和研究热点的信息,那么如何从海量文献数据中发现这样的信息,为科学发展、研究创新提供动力呢?从目前已有的文献可以看出几种研究思路:第一种是以期刊引文关系为基础研究学科交叉关系[2-4];第二种是通过关联规则挖掘、文本挖掘等现代数据挖掘技术手段研究学科间的相关性和交叉知识[5-6];第三种是以期刊关键词为基础研究学科交叉的热点[7];第四种是以不同的研究对象为基础,从不同的视角研究学科之间的交叉关系[8-10]。以上文献多以静态数据为基础切入不同的分析角度探讨学科之间的交叉关系,但是对学科交叉的程度以及研究热点缺少量化分析。
本文将以复旦大学ERU数据采集平台所获得的用户使用电子文献行为的动态数据为基础进行数据分析。ERU全称为“图书馆电子资源使用统计分析软件”,一般部署在高校核心网络交换机的镜像口,从旁路出发,基于网络底层采集用户信息行为的数据,ERU软件可以对图书馆实现电子资源知识库定制管理,对图书馆所使用的数据库和数据库中的文献内容进行用户使用行为的数据采集,并以此为基础实现电子资源使用情况的多维统计和用户访问行为的统计分析。通过ERU数据采集平台获取的动态数据,实现挖掘学科之间可能存在的交叉关系,为更好地揭示学科交叉关系提供一种新思路,不仅通过网络用户使用电子文献资源的行为研究探讨学科之间的交叉程度,而且深入挖掘数据的潜在关系对学科交叉的研究热点也进行分析,为师生、学者和科研人员的研究提供数据参考,帮助其找到学科研究上新的创新点和突破口。
1 研究方法
学科交叉程度的研究分析运用Session ID关系,通过将Session ID中出现的文献之间的关系转换为学科之间的关系。以此建立起学科之间交叉关系的基础,以学科之间交叉出现的频次作为学科交叉关系程度的反映。学科交叉热点的研究分析则是利用因子分析,将学科交叉出现的高频关键词提取出具有代表性的因子,以这些因子为类,分析得出学科交叉的热点区域,再结合聚类分析,将结果进行比较,获得较为满意的学科交叉研究热点的分析结果。
1.1 Session ID关系运用分析
本文学科之间的交叉关系是建立在Session ID关系的基础之上获得的。在Web中Session是指用户在浏览某个网站时,从进入网站到浏览器关闭所经过的一段时间,也就是用户浏览这个网站所花费的时间。Session在用户第一次访问服务器的时候自动创建,其生成后,只要用户继续访问,服务器就会更新Session的最后访问时间,并维护该Session。服务器会把长时间没有活动的Session从服务器内存中清除,此时Session便失效。服务器会分配Session ID给不同的用户,每个Session ID都是惟一的。文中设Session ID为一个分析对象,在这个分析对象中,所有出现的文献被认为是存在关联关系的,它们之间的关联关系将作为学科之间建立交叉关系的基础。
(1)明确一个Session ID中包含的每篇文献的学科分类。文献学科分类确定好之后,Session ID中出现的文献之间的关系转换为学科之间的关系。
(2)再以Session ID为基础,交叉运算每一个Session ID当中存在的两学科、三学科甚至多学科之间的相互交叉关系。假设一个Session ID当中有若干篇文献,每篇文献都有学科归属。文献1学科分类为A,文献2学科分类为C,文献3学科分类既属于学科A又属于学科B,此时认为A和B学科之间存在交叉关系,A和C学科,B和C学科,A、B和C学科之间都存在学科交叉关系。在同一篇文献中出现的交叉关系定义为内在关系,同一个Session ID中出现的交叉关系定义为外在关系。学科之间每出现1次交叉计算1次出现频次,以学科之间交叉出现的频次作为学科交叉关系程度的反映。
(3)学科交叉的研究的热点分析,也同样引入Session ID关系影响因素,扩大文献中出现的关键词关联关系,同一个Session ID的用户使用文献的学科关键词,关键词的共现频次不仅需要计算在同一篇文献中两两共现的次数,而且还要计算同一个Session ID中关键词的两两共现次数。同一篇文献中出现的关键词的共现关系定义为内在关系,同一Session ID出现的关键词的共现关系定义为外在关系。
1.2 因子分析
因子分析最早是由英国心理学家斯皮尔曼提出的,是一种从变量群中提取共性因子的数据简化统计技术。因子分析通过研究众多变量间的内部依赖关系,探求观测数据中的基本结构,找出变量中隐藏的具有代表性的因子,将相同本质的变量归入一个因子中,减少变量的数目,同时检验变量间的假设关系,用假想的变量能够反映出原来众多变量的主要信息[11]。换句话说,因子分析是寻找潜在的、起支配作用因子的方法。通过因子分析,将学科交叉出现的高频关键词提取出具有代表性的因子,以这些因子为类,分析得出学科交叉的热点区域。
2.3 聚类分析
聚类分析又称群分析,起源于分类学,是一种探索性分析方法,能够分析事物的内在特点和规律,并根据相似性原则对事物进行分组,是数据挖掘中常用的一种技术。它特别适用于没有先验知识的分类。如果没有这些事先的经验或一些标准,分类便会显得随意和主观,这时只要设定比较完善的分类变量,就可以通过聚类分析法得到较为科学合理的类别[12]。学科之间交叉后会产生怎样的知识分类,事先是无法得知的,通过聚类分析,可以分类得出,这样就可以与因子分析的结果进行比较,获得较为满意的学科交叉研究热点的分析结果[13]。
2 数据采集与分析
本文以复旦大学ERU数据采集平台所获得的用户使用电子文献行为的动态数据为基础,从底层网络数据中获取用户对学校订购的所有中文数据库的检索、浏览、下载等信息行为的日志数据,及对应数据库文献信息,如关键字、作者、引用、发表时间等数据。数据采集时间为2013年8月到2014年2月的有效数据共241 464条,有48 000多个Session ID,平均每个Session ID有5条左右记录。
2.1 学科交叉程度分析
在数据分析中学科分类采用的是《中国图书馆分类法》,以此为基础揭示学科之间的交叉情况。将采集到的有效数据与Session ID结合,按照上文介绍的运算规则分析,并且对于同一篇文献中学科交叉频次,赋值为0.6,同一Session ID出现的学科交叉频次,赋值为0.4,获得的学科交叉程度结果如下(见表1):
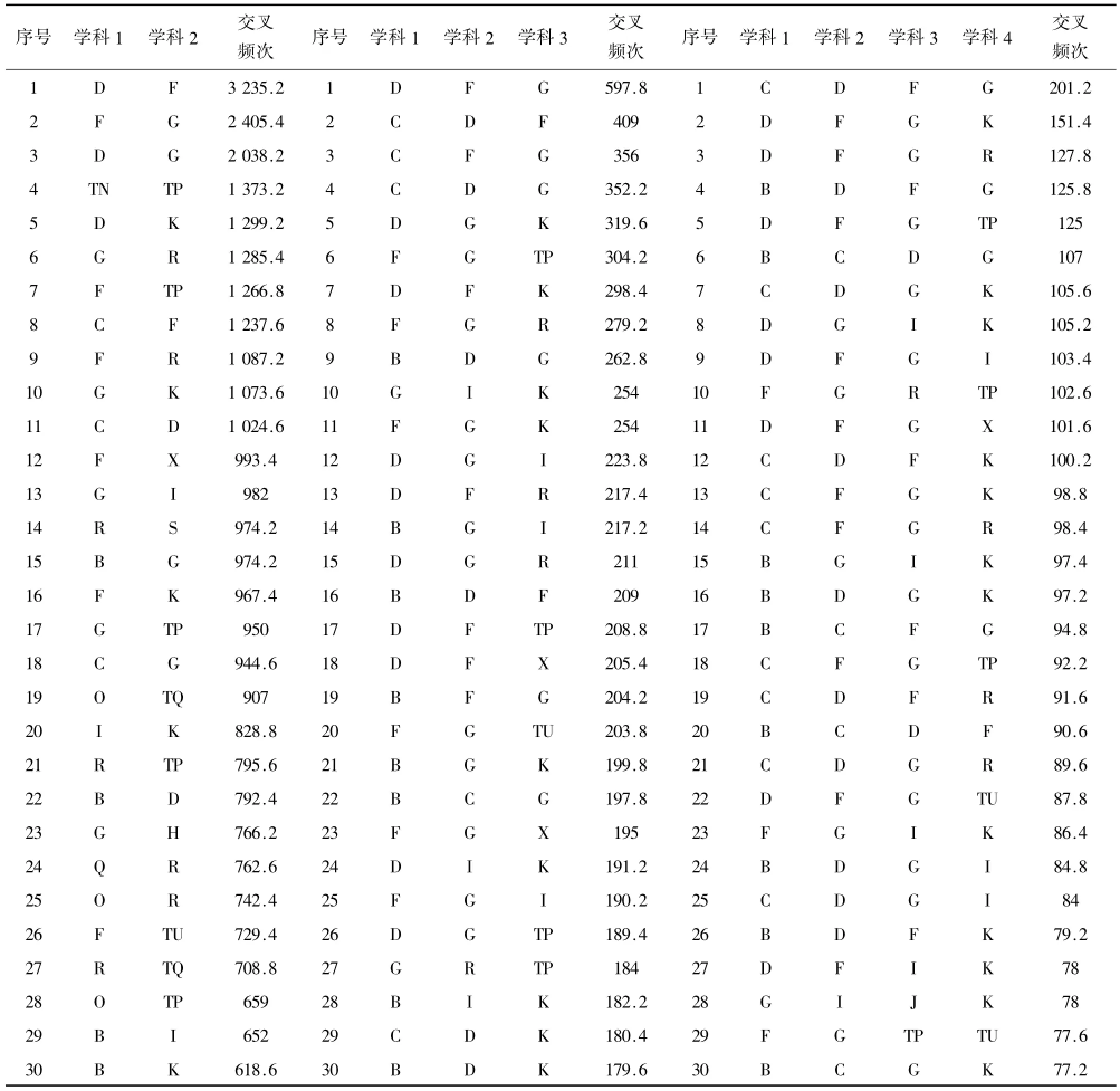
表1 学科交叉频次表(部分)
如表1所示,通过Session ID关系分析动态数据获得相关学科交叉的频次数据,它反映出复旦大学师生、科研人员和学者在相关研究中学科之间的相互交叉关系。首先,两学科交叉排序前3位的为:D(政治、法律)和F(经济);F和G(文化、科学、教育、体育);D和G。三学科交叉排名前3位的为:D、F(经济)和G;C(社会科学总论)、D和F;C、F和G;四学科交叉排名前3位的为:C、D、F和G;D、F、G和K(历史、地理);D、F、G和R(医药、卫生)。政治经济学科交叉融合本身已经较为成熟了,通过此次的数据说明它们的交叉融合程度是很高的。第二,学科交叉中的活跃学科:C、D、F、G、K,都属于传统的社会人文科学,这与复旦大学属于综合性大学,学科设置偏重社会人文科学相符,这些学科大多为其他学科提供理论指导,较易与其他学科发生交叉。第三,在所有学科交叉中没有出现E(军事)、J(艺术)、P(天文、地球)、U(交通运输)、V(航空、航天)等学科分类,这也是与复旦大学学科设置较为相符。第四,体现出学科交叉的发生,既存在于学科的内部,也存在于学科之间,甚至是存在于学科“界”之间。第五,两学科以上的学科交叉的发生,都是以两学科为基础,不断融入新的学科知识。
2.2 学科交叉热点分析
2.2.1 学科交叉高频词统计
根据以上分析得到的学科之间交叉情况的数据,本文将以排名首位的D和F为例,分析学科交叉的热点。首先利用Bibexcel软件对从ERU采集的相关学科交叉数据进行关键词词频统计(见表2),然后挑选高频关键词,形成相关共词矩阵(见表3)。手动将关键词中无意义的或与其他关键词联系少的关键词剔除,生成高频关键词共词矩阵。共词矩阵中关键词的共现次数不仅计算在同一篇文献中共现的次数,而且还要计算同一Session ID中不同文献关键词的共现次数。对于同一篇文献中关键词的共现次数,赋值为1;同一Session ID出现的关键词的共现次数,赋值也为1。
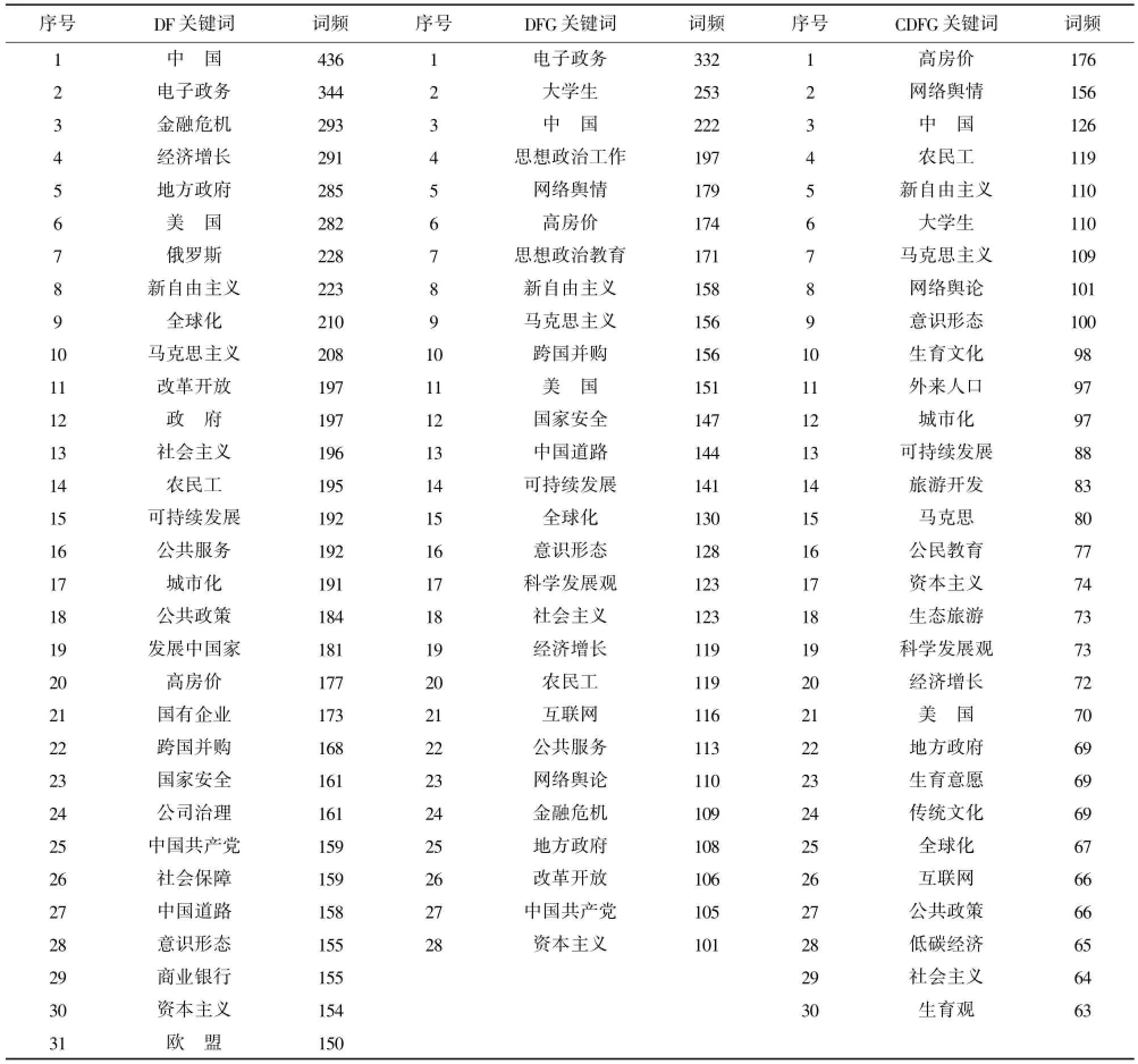
表2 高频关键词分布表(降序)
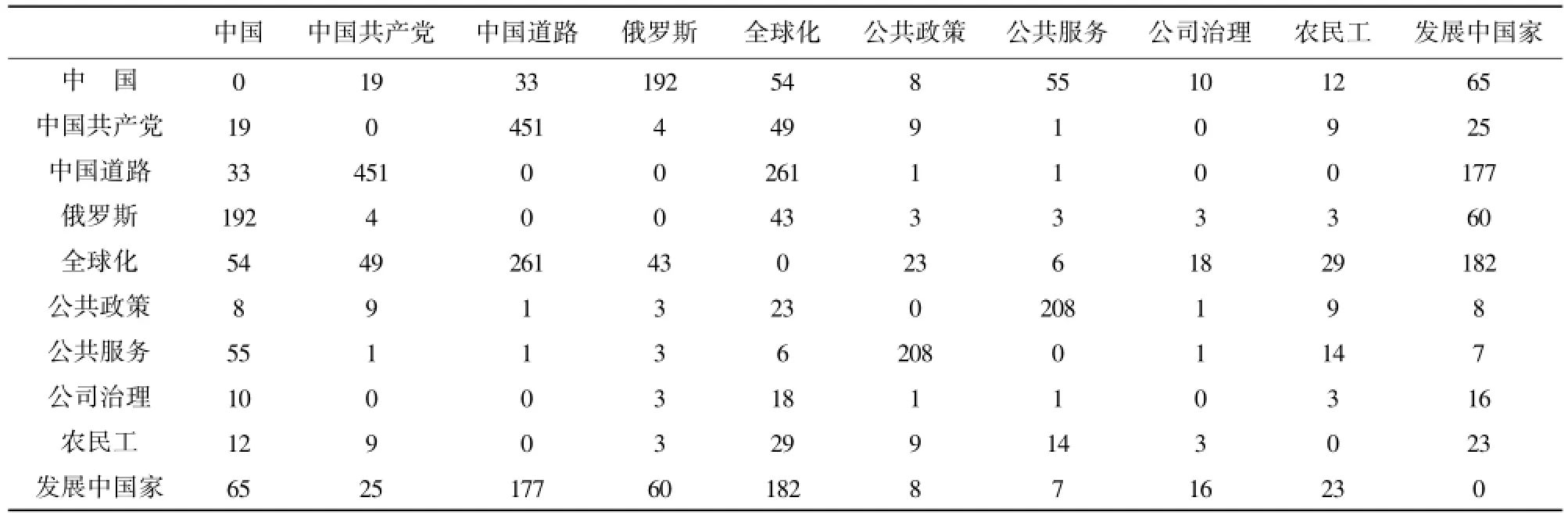
表3 DF 共词矩阵(部分)
2.2.2 学科交叉热点分析
本文在学科交叉热点分析中,以SPSS软件作为统计分析的工具进行因子分析和聚类分析。因子分析中,考虑到所建矩阵包含有内在共词关系和外在共词关系的因素,而且邱均平老师已在其文章中验证可以将原始矩阵直接作为输入矩阵,事先不需要任何转化[14]。另外,SPSS软件为了消除不同变量间量纲和数量级对结果的影响,在该过程中默认自动进行标准化处理,不再对这些变量提前进行标准化处理,因此本研究的矩阵均未进行转化。在此基础上,利用主成份法、相关性矩阵与旋转——最大方差法进行因子分析。聚类分析中,共词矩阵也未作转化,运用系统聚类、相似性矩阵、组间连接和余弦方法进行聚类分析。
(1)学科交叉热点因子分析
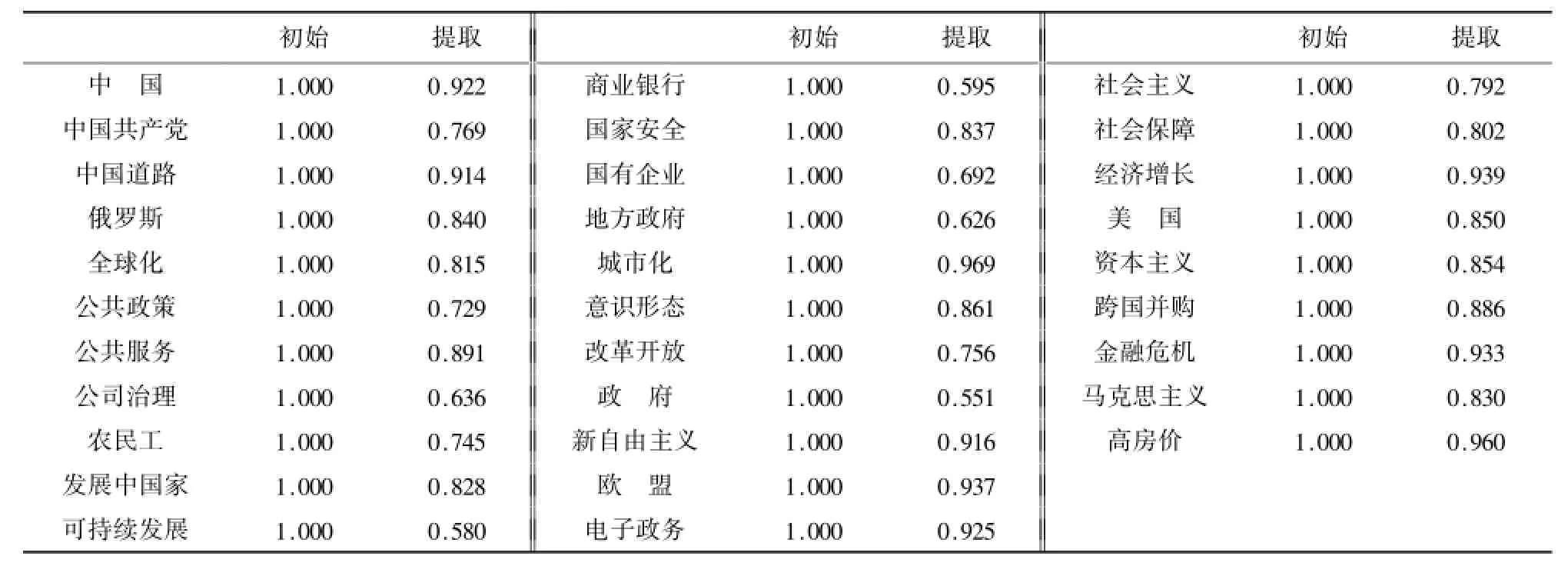
表4 DF公因子方差
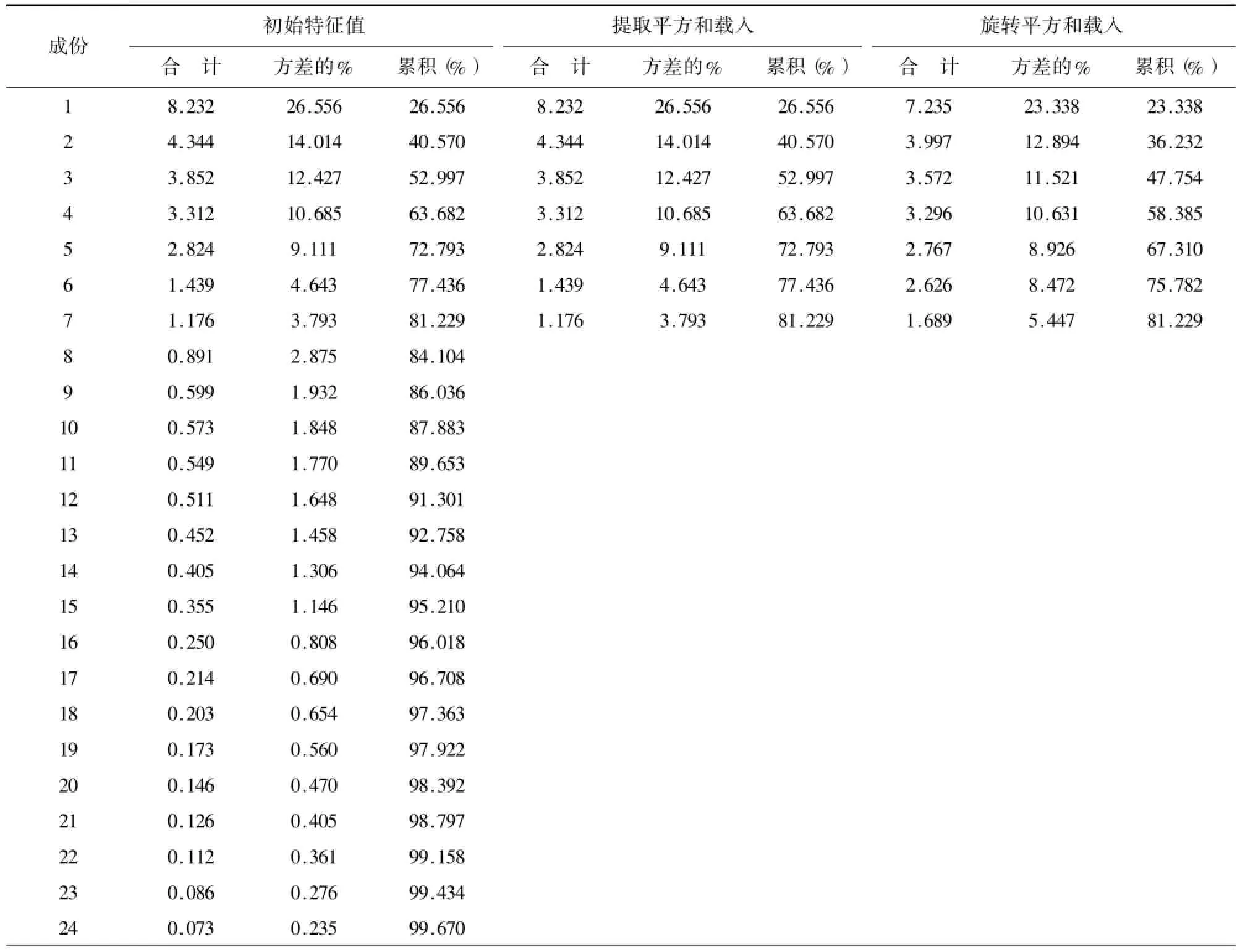
表5 DF 解释的总方差
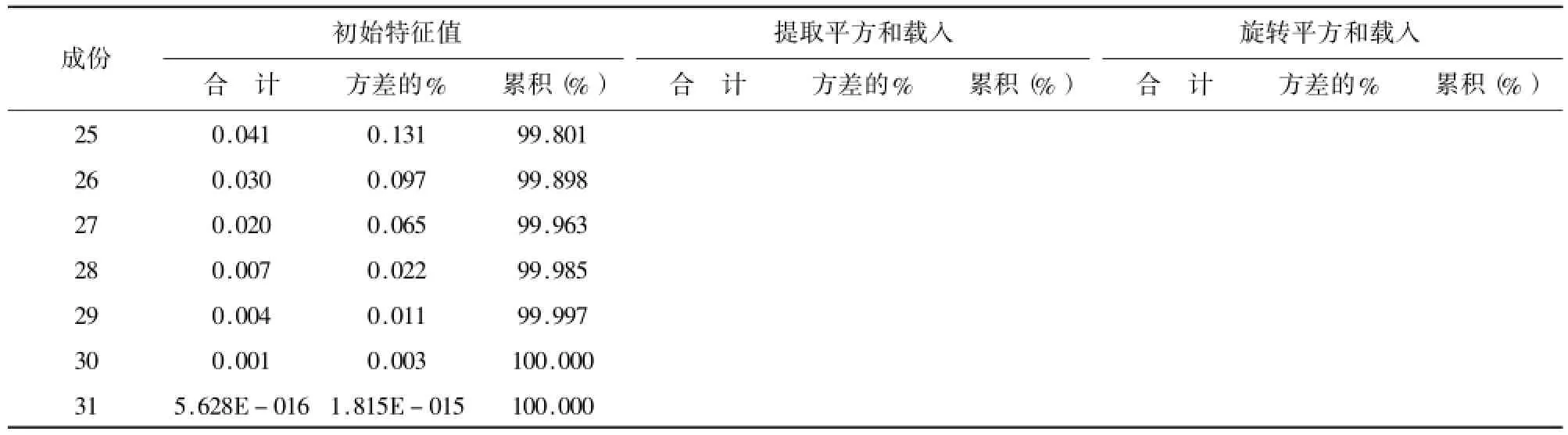
表5 (续)
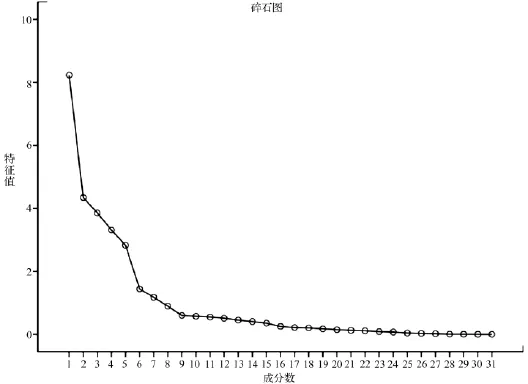
图1DF因子分析碎石图
表4显示,提取因子后公因子方差的值均很高,表明提取的因子能很好地描述这31个关键词。表5因子分析方差分解表(解释的总方差)表明,前7个因子特征值大于1,这7个因子能够解释31个指标的81.229%,而仅前3个因子的信息解释量就达52.997%。图1DF因子分析碎石图也表明,从第8个因子开始,特征值差异减小。综合以上结果,提取前7个因子。

表6 DF 旋转成份矩阵
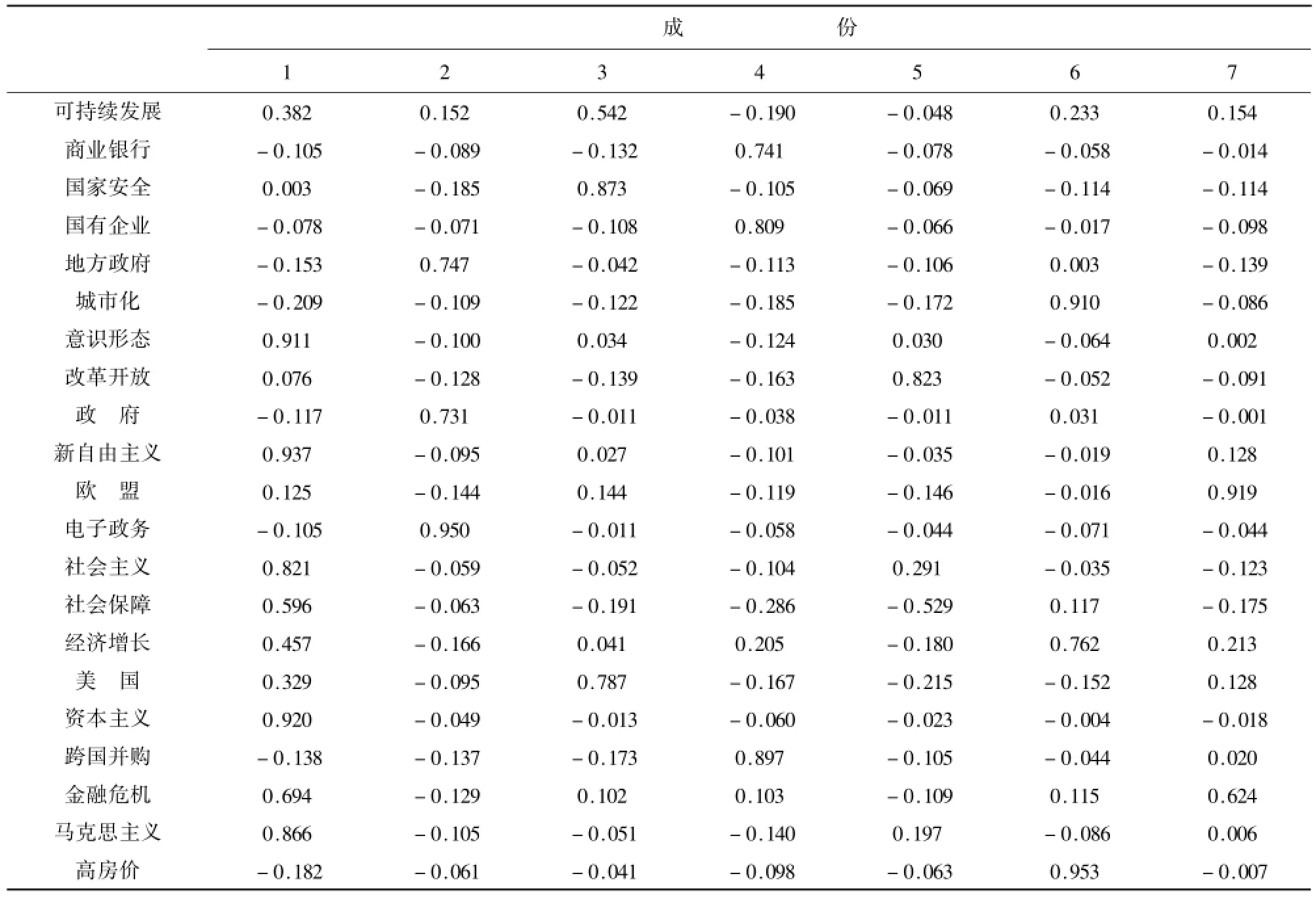
表6 (续)
由表6因子分析旋转成份矩阵可以看出,经旋转后,因子便于命名和解释。为便于识别,将因子负载绝对值大于0.5的关键词制作成如表7。
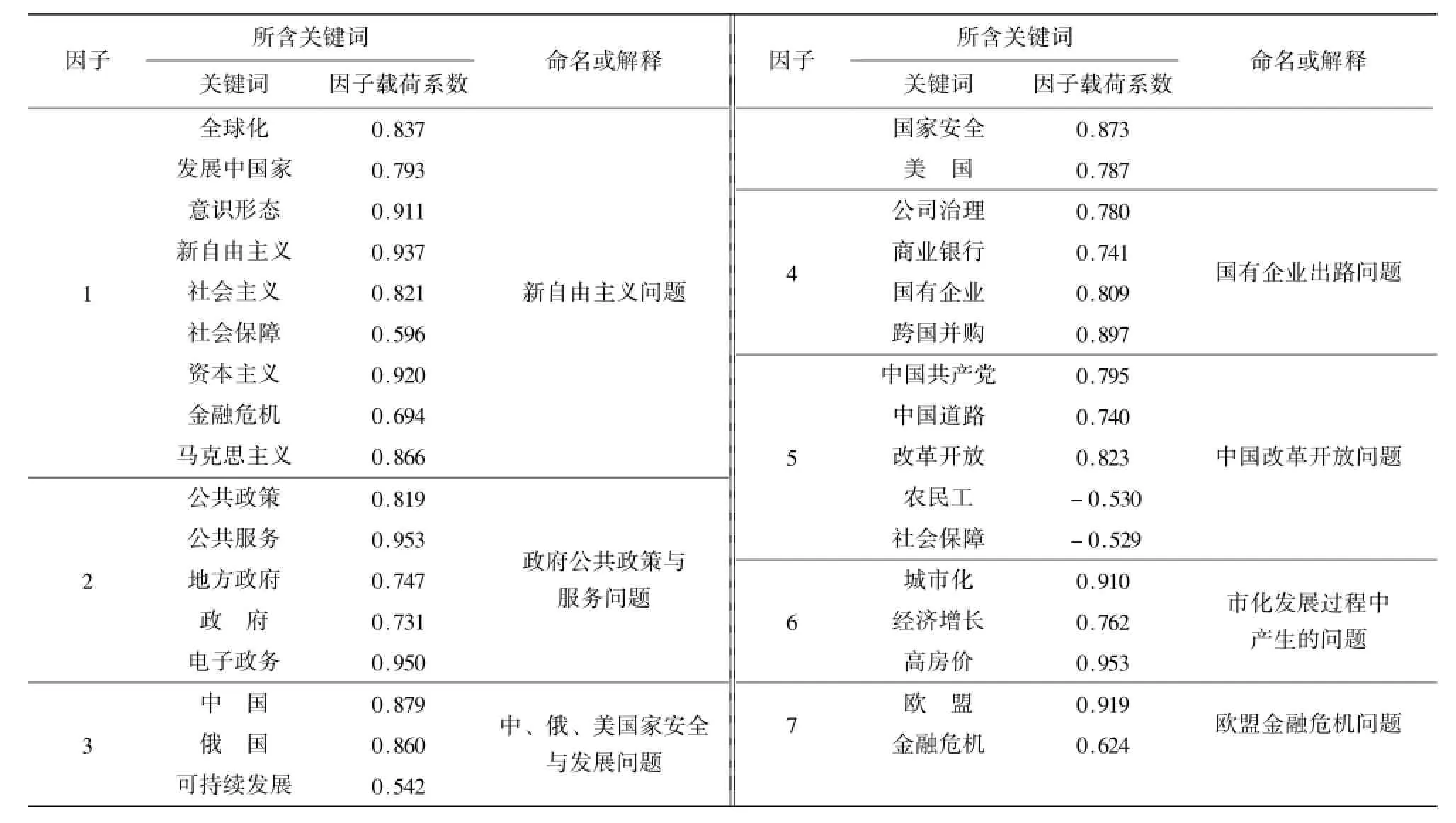
表7 因子分析确定的DF 学科交叉热点研究
从表7因子分布情况可以看出,因子分析结果中的关键词总体分布有如下特点:
①绝大多数关键词都归于相应因子。根据因子载荷大于0.7就对因子解释有帮助的原则,并综合因子中其他关键词的属性,对7个因子进行归类命名和解释,如表7所示。
②有两个关键词跨区分布。关键词“金融危机”同时出现在第1、第7个因子中,它们的因子载荷系数均在0.6左右,体现这两个因子——“新自由主义问题”、“欧盟金融危机问题”之间的相关性。
③有2个关键词的因子载荷系数为负,同相应因子构成负相关关系。如:第5个因子中的“农民工”(因子载荷系数为-0.530),“社会保障”(-0.529)。
(2)学科交叉热点聚类分析

图2DF系统聚类分析树状图
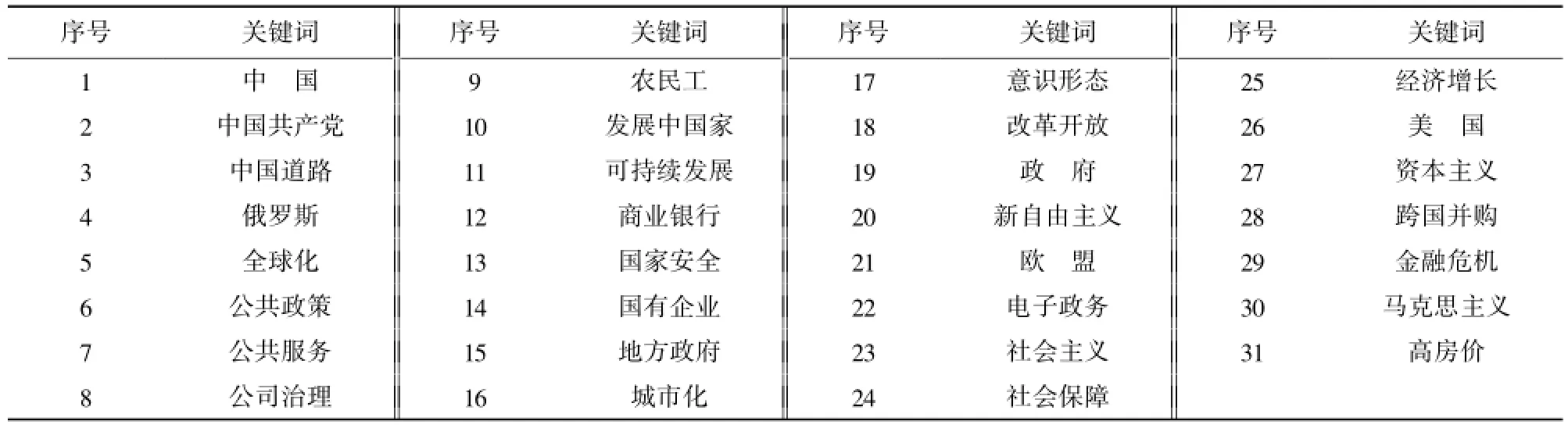
表8 DF 关键词与序号对照表
聚类分析的结果,如果没有因子分析的结果做比较,仅依靠聚类分析的结果,分析难度明显较大,既无法确定分为几类合适,也无法有对聚类的类进行命名的依据。结合因子分析的效果,可以明确地将关键词分为6大类:新自由主义问题、政府公共政策与服务问题、国家或区域的国家安全与发展问题、国有企业出路问题、中国改革开放问题、城市化发展过程中产生的问题。需要说明的是第9号关键词“农民工”在因子分析中与第5个因子是负相关关系,而又与其他因子没有正相关关系,但是与第24号关键词“社会保障”又是紧密相关的(都与第5个因子是负相关关系)。而第21号关键“欧盟”所属同一个因子(第7)的第29号关键词“金融危机”是跨因子分类的,二者无法再聚类,则其与第3个因子的所有关键词聚为一类,形成国家或区域的国家安全与发展问题研究。归纳以上分析,最后确定DF学科交叉热点分析结果如表9所示。
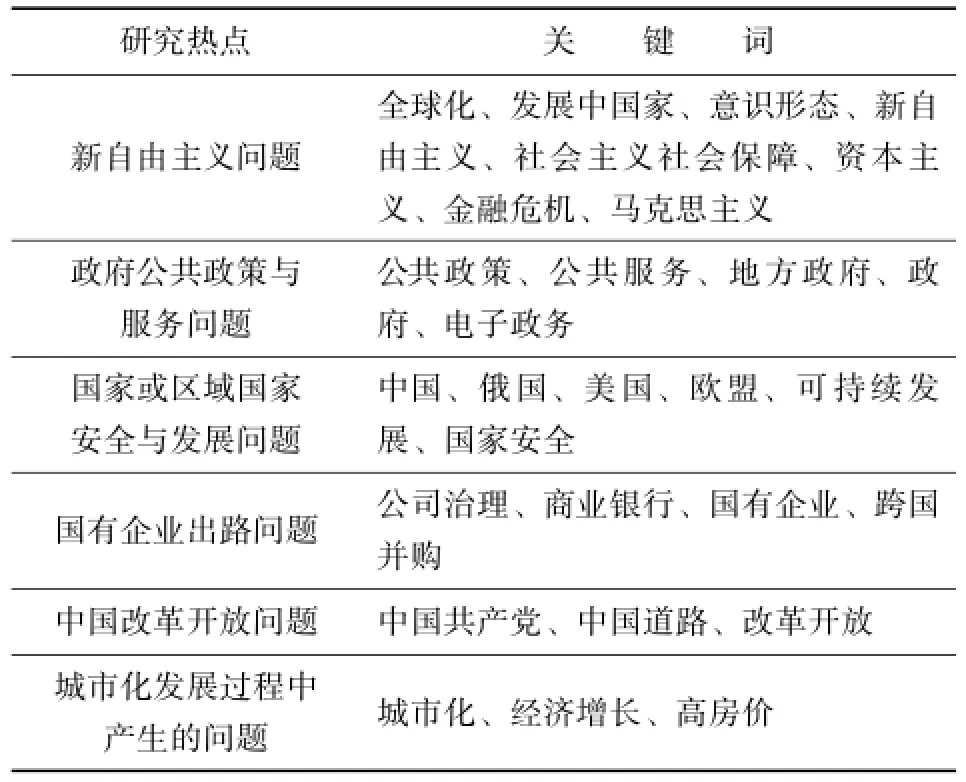
表9 DF 学科交叉研究热点
(3)学科交叉热点综合分析
各个学科由于发展程度不同,研究重点不同,对于相同的问题的认识解决程度也不同。学科交叉研究热点所反映出的对于相同问题的解决,各个学科会采用不同的学科理论,同时也会运用其他学科的理论帮助问题的解决。对于某学科早已形成的成熟理论被其他学科用来解决不同学科的问题,说明前者学科的理论得到推广和扩展,而后者学科找到了理论的源头,指导解决问题的研究,说明交叉融合的学科越多,解决问题所面对的角度也就越多。
3 结语
本文与以往学科交叉研究不同之处在于通过运用ERU数据采集平台,采集到用户在访问图书馆的各类电子资源数据库的各种行为,从网络底层统一获取其动态数据,利用Session ID关系、因子分析和聚类分析的方法,对学科交叉程度以及学科交叉的研究热点进行分析。这一研究方法开拓了数据源的使用,拓展了研究的宽度,并且弥补了以往研究中仅针对静态数据分析研究的不足。本文也存在很多不足之处,如:分类不够细化、数据量少、数据优化欠缺等。分析研究对象的数据量较窄,如何增加分析对象数据,扩大此研究方法的适用范围,是未来研究的重点。此外,对数据的解读,具有一定的主观性。未来在研究中将会增强对分析数据源以及分析方法的应用,采取更加合理的学科分类方法,提高数据量,找到合适的关键词筛选方法,对数据进行合理分析,获得学科交叉的程度和学科交叉研究热点等信息,促进在学术研究和科学创新上激发新的生长点的出现。
[1]薛澜.关于学科交叉问题的一些理论探讨[J].中国科学基金,1997,(1):59-64.
[2]杨建林,孙明军.利用引文索引数据挖掘学科交叉信息[J].情报学报,2004,(6):672-676.
[3]阚连合,黄晓鹏,刘梅申.情报学交叉学科的发展趋势——我国情报学期刊被引分析的启示[J].现代情报,2007,(1):62-64.
[4]李长玲,纪雪梅,支岭.基于E-I指数的学科交叉程度分析——以情报学等5个学科为例[J].图书情报工作,2011,(6):33-36.
[5]王昊.基于关联规则挖掘研究学科间相关性[J].现代图书情报技术,2005,(3):23-28.
[6]魏建香,孙越泓,苏新宁.学科交叉知识挖掘模型研究[J].情报理论与实践,2012,(4):76-80.
[7]闵超,孙建军.学科交叉研究热点聚类分析——以国内图书情报学和新闻传播学为例[J].图书情报工作,2014,(1):109-116.
[8]张春美,郝凤霞,闫红秀.学科交叉研究的神韵——百年诺贝尔自然科学奖探析[J].科学技术与辩证法,2001,(6):63-67.
[9]刘煜,刘仲林.学科交叉中的科研创新契机——以中科院院士增选为例[J].科技进步与对策,2005,(12):61-63.
[10]于江,党延忠.用信息可视化方法分析科研领域发展状况[J].科学学与科学技术管理,2009,(6):10-14.
[11]吴骏.SPSS统计分析从零开始学[M].北京:清华大学出版社,2014:261-278.
[12]聚类分析[OL].http:∥wiki.mbalib.com/wiki/%E8%81% 9A%E7%B1%BB%E5%88%86%E6%9E%90,2014-06-06.
[13]吴骏.SPSS统计分析从零开始学[M].北京:清华大学出版社,2014:279-295.
[14]邱均平.关于共被引分析方法的再认识和在思考[J].情报学报,2008,(1):69-74.
(本文责任编辑:郭沫含)
An Analysis of the Degree of Inter-disciplines and Research Hotspots:Based on Fudan University ERU Data
Zhang ChunmeiZhang JilongYin ShenqinWang DongweiGuo Yaodong
(Library,Fudan University,Shanghai 200433,China)
This article studied the degree of inter-disciplines and research hotspots by making use of the methods of Session ID,Factor Analysis,and Cluster Analysis,on the basis of the Fudan University ERU data of searching behavior of the library digital resources.It improved the research on inter-disciplines through the use of data sources,and made up the shortfall of static data analysis.
inter-disciplines;dynamic data;session ID;factor analysis;cluster analysis
10.3969/j.issn.1008-0821.2015.03.013
G250.73
A
1008-0821(2015)03-0068-09
2014-12-17
国家社科基金“泛在知识环境下图书馆知识发现技术与应用研究”(项目编号:12CTQ006)。
张春梅(1979-),女,馆员,硕士,研究方向:信息服务、馆藏建设。
