Fast Chinese syntactic parsing method based on conditional random fields
2015-04-22HANLei韩磊LUOSenlin罗森林CHENQianrou陈倩柔PANLimin潘丽敏
HAN Lei(韩磊), LUO Sen-lin(罗森林), CHEN Qian-rou(陈倩柔), PAN Li-min(潘丽敏)
(School of Information and Electronics, Beijing Institute of Technology, Beijing 100081, China)
Fast Chinese syntactic parsing method based on conditional random fields
HAN Lei(韩磊), LUO Sen-lin(罗森林), CHEN Qian-rou(陈倩柔), PAN Li-min(潘丽敏)
(School of Information and Electronics, Beijing Institute of Technology, Beijing 100081, China)
A fast method for phrase structure grammar analysis is proposed based on conditional random fields (CRF). The method trains several CRF classifiers for recognizing the phrase nodes at different levels, and uses the bottom-up to connect the recognized phrase nodes to construct the syntactic tree. On the basis of Beijing forest studio Chinese tagged corpus, two experiments are designed to select the training parameters and verify the validity of the method. The result shows that the method costs 78.98 ms and 4.63 ms to train and test a Chinese sentence of 17.9 words. The method is a new way to parse the phrase structure grammar for Chinese, and has good generalization ability and fast speed.
phrase structure grammar; syntactic tree; syntactic parsing; conditional random field
Chinese syntactic parsing is one of the significant components in natural language processing. With the large scale development of Chinese Treebank[1], the corpus-based techniques that are successful for English have been applied extensively to Chinese. The two main approaches are traditional statistical and deterministic parsing.
Traditional statistical approaches build models to obtain the unique tree with the highest PCFG probability (Viterbi tree)[2-9]. These algorithms require calculating PCFG probability of every kind of possible trees. Only at the expense of testing time, the Viterbi tree can be obtained. To reduce the testing time, deterministic parsing emerges as an attractive alternative to probabilistic parsing, offering accuracy just below the state-of-the-art in syntactic analysis of English, but running in linear time. Yamada and Matsumoto[10]proposed a method for analyzing word-word dependencies using deterministic bottom-up manner using support vector machines (SVM), and achieved R/P of over 90% accuracy of word-word dependency. Sagae and Lavie[11]used a basic bottom-up shift-reduce algorithm, but employed a classifier to determine parser actions instead of a grammar and achieved R/P of 87.54%/87.61%. Cheng et al.[12]presented a deterministic dependency structure analyzer which implements two algorithms—Yamada and Nivre algorithms—and two sorts of classifiers—SVM and Maximum Entropy models for Chinese. Encouraging results have also been shown in applying deterministic models to Chinese parsing. Wang et al.[13]presented classifier-based deterministic parser for Chinese constituency parsing. Their parser computes parse trees from bottom up in one pass, and uses classifiers to make shift-reduce decisions and achieves R/P of 88.3%/88.1%.
In this paper, a faster deterministic parsing method is proposed based on conditional random fields (CRF) to reduce the runtime of parsing. The proposed method applies the CRF++[14]as the classifiers training and testing software to label the phrase nodes in syntactic levels for each segment. The nodes labeled are combined to construct the phrase structure syntactic tree.
1 Method
Base on the part-of-speech (POS) tagging results, the method labels the phrase and sentence nodes (both of them are defined as nodes) of each segment to construct a syntactic tree. The principle of the method is shown in Fig.1.

Fig. 1 Principle of the method
1.1 Data processing
Data processing contains two parts, i.e. data training and data testing. The aim of data training is to change the data format from the POS and syntax tagging result to one word per line. The data training inputs are the POS and syntax tagging results and outputs are nodes in the format of one word per line. Take the sentence of “姚明说范甘迪是核心(Yao Ming said that Van Gundy is the core)。” as an example. The data training inputs are the POS and syntax tagging results, which are “0^姚明(Yao Ming)/nr 1^说(said)/v 2^范甘迪(Van Gundy)/nr 3^是(is)/v 4^核心(the core)/n 5^。/w” and “[dj [np 0^姚明/nr] [vp 1^说/v [dj [np 2^范甘迪/nr] [vp 3^是/v 4^核心/n]]] 5^。/w]”. The data training outputs are shown in Tab.1. And the syntax tree is shown in Fig. 2.

Tab. 1 Format of one word per line for“姚明说范甘迪是核心”
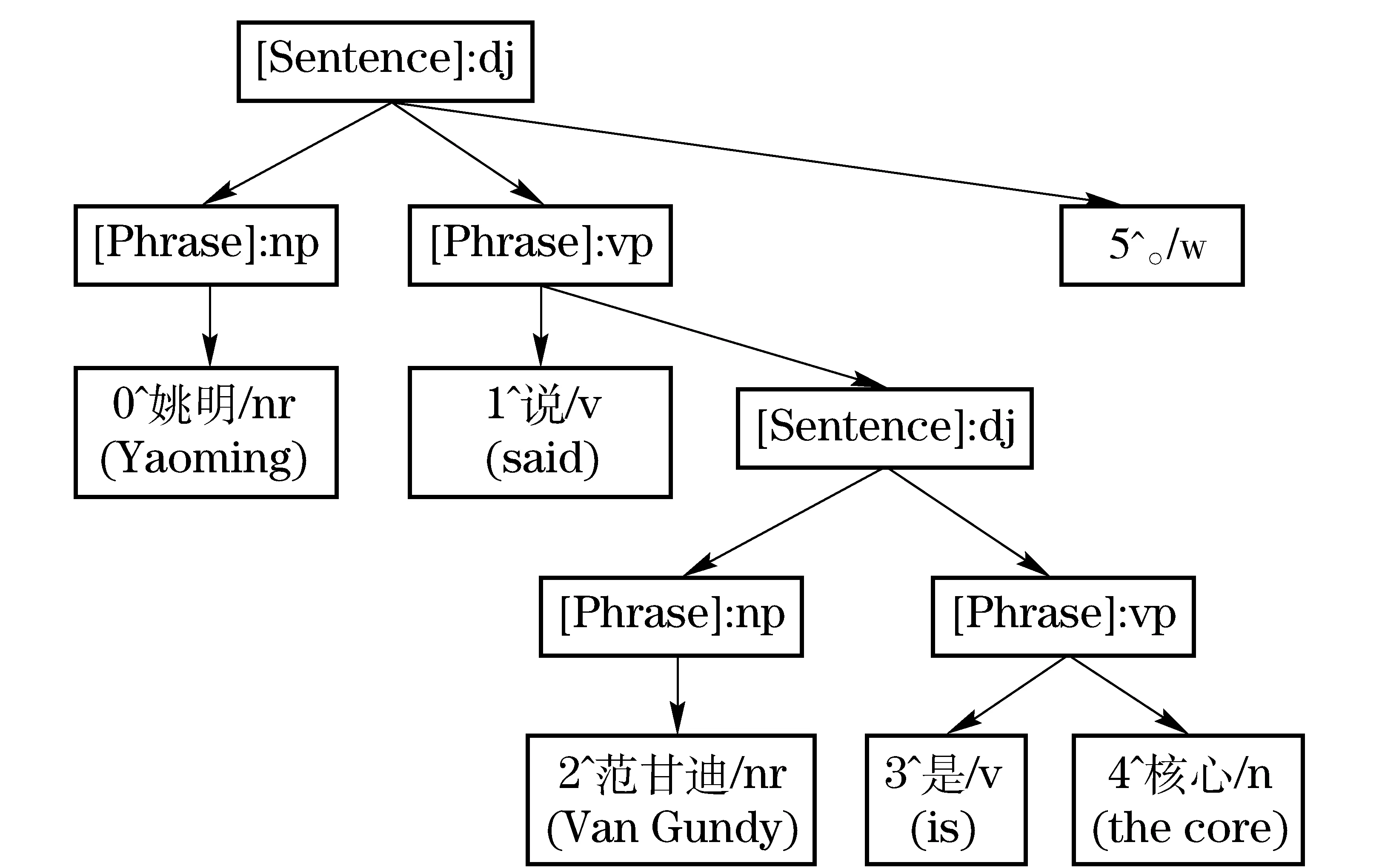
Fig. 2 Syntactic tree of “姚明说范甘迪是核心”
To explain the process of data training, the concept of syntactic level (hereinafter referred to as level) is introduced. The closest node to the segment is defined in the 1stlevel (1L) of the segment and less close node to the segment is defined in the 2ndlevel (2L) of the segment. The further the distance between segment and the node is, the higher level the node is in. The root node of the syntactic tree is defined in the last level of the segment. It can conclude that different segments may have different levels. Take the segment of “核心(the core)” as an example in Fig. 2. The phrase node of vp is in the 1stlevel, dj that does not belong to the root node is in the 2ndlevel, vp that is further from the segment is in the 3rdlevel (3L) and dj of the root node is in the 4thlevel (4L). In addition, the maximum level number among the segments in a sentence equals the level number of the sentence.
In Tab. 1, the first column shows word segmentation results of the example sentence, the second column shows the POS tagging of each segment, the third column contains the segment order (SO) which means the order of the segment in the sentence, the other columns contain all the nodes in the syntactic tree including phrase nodes and sentence nodes.
The data testing changes the POS tagging results into the format for the next recognition. Its inputs are POS tagging results and its outputs are the POS in the format as the first three columns in Tab. 1.
1.2 Model training and testing
Model training is to train the recognition models for each level labeling. Its inputs are the tagged syntactic tree and feature template. Its outputs are the recognition models for each level labeling. The model for labeling the nodes in the 1stlevel is defined as the 1stmodel and the model for labeling the nodes in the 2ndlevel is defined as the 2ndmodel and so on. Considering the data set for testing, the maximum level number of sentences is 14, thus 14 models need to be trained at least. Take the sentence in Tab. 1 as an example. The sentence needs 4 models to label each level. If the 2ndmodel needs to be trained, the inputs are the first 5 columns in Tab. 1 and the outputs are the model for labeling the nodes in the 2ndlevel. Each model has its own feature template and the parameters for training.
Model testing labels the nodes of each segment from the 1stlevel to the highest level. Its inputs are the POS tagging results and outputs are the syntactic tree in the format of one word per line. Take the sentence in Tab. 1 as an example. The inputs are the first three columns, the 1stmodel, the 2ndmodel, the 3rdmodel and the 4thmodel. Firstly, the method uses the first three columns and the 1stmodel to label the nodes (np, vp, np, vp, vp, dj) in the 1stlevel. Secondly, the method uses the first 3 columns, the labeled nodes in the 1stlevel and the 2ndmodel to label the nodes in the 2ndlevel. Thirdly, the method uses the first 3 columns, the labeled nodes in the 1stand 2ndlevels and the 3rdmodel to label the nodes in the 3rdlevel. At last, based on all the labeled nodes and the 4thmodel, the output of the model testing is obtained as shown in Tab. 1.
1.3 Constructing syntactic tree
Constructing syntactic tree is an inverse process of data processing. Take the sentence in Tab. 1 as an example. Firstly, it connects the nodes from a segment to the node in the highest level as a single tree. Secondly, it combines the same node of dj. Thirdly, it combines the same child nodes of dj. Then, it combines the same nodes of every child node until the POS. The process is shown in Fig. 3.

Fig. 3 Process of constructing syntactic tree
2 Experiment
Two experiments are designed to choose the CRF++ training parameters and verify the efficiency, stability and precision of the method. One is parameters selecting and the other is method verifying. For choosing the training parameters of 14 models, the parameters selecting applies the grid method to select the bestcandf. The value ofcranges from 0.2 to 6 with the step length of 0.2. The value offranges from 1 to 5 with the step length of 1. The method verifying uses the parameters with the highest precision for labeling the nodes in different levels to train the models, and then the syntactic tree is verified both in open and closed testing based on the method of 10-fold-cross-validation. At the same time, the training and testing time are recorded.
2.1 Data set and hardware
The data set is 10 000 Chinese tagged syntactic sentences in Beijing forest studio Chinese tagged corpus (BFS-CTC)[15-16]. The number of words in a sentence is 17.9 on the average. The maximum number of words in a sentence is 53, the minimum number of words in a sentence is 3, and the maximum syntactic level number is 14 in the BFS-CTC.
The main hardware which is mostly relevance with the computing speedis as follows.
① CPU: Intel®Xeon®X5650 @ 2.67 GHz. (2 CPUs)
② Memory: 8 G.
③ System type:Windows Server 2008 R2 Enterprise sp1 64 bit.
2.2 Evaluating

2.3 Results
2.3.1 Parameters selecting
Take the 1stmodel training as an example to show the process of parameters selecting. There are total of 18 features used for 1stmodel training, including POS, POS of former segment etc., as shown in Tab. 2. Based on these features, the partly results are shown in Fig. 4, whose best result is 90.47% for nodes labeling in 1stlevel whencequals 0.4 andfequals 1. The process of parameters choosing of the other 13 models is the same.
2.3.2 Method verifying
Method verifying contains closed test and open test.In the closed test, theP,RandFvalues of 10 experimental groups are shown in Fig. 5. The averageP,RandFvalues are 76.32%, 81.25% and 0.787 1 respectively. In the open test, the result is shown in Fig.6. The averageP,RandFvalues are 73.27%, 78.25% and 0.756 8.

Tab.2 Features used in model training of first level

Fig. 4 Partly results of choosing parameters

Fig.5 P, R and F in closed test

Fig. 6 P, R and F in open test

In the same condition, the recently results of the PCFGs[9]are shown in Tab. 4. The time of the table contains the rule collecting and testing for one group experiment. In Tab.4, theP,RandFare calculated by using the PARSEVAL[17]. The time of testing a sentence for PCFG, L-PCFG, S-PCFG and SL-PCFG is 1 847.1 ms, 1 425.9 ms, 205.8 ms and 82 ms in closed set, and 1 850.2 ms, 1 412.2 ms, 178.3 ms and 68.1 ms in open set. In comparison with previous work, the time of proposed method is very competitive. Compared with the PCFGs, the proposed method is 22 times faster and gives almost equal results for all three measures. In particular, although the SL-PCFG is the fastest in Tab.4 and almost equals the sum time of the proposed method in closed test, the proposed method gives a significantly better results in open test as shown in Tab.4.

Tab.3 Time of training and testing in closed and open set ms

Tab.4 Results of PCFGs
Some other previous related works are shown in Tab.5. These models used the Penn Chinese Treebank. The average runtime of Levy & Manning’s, Bikel’s and stacked classifier model to analysis a sentence in Penn Chinese Treebank is 117.7 ms, 776.6 ms and 64.1 ms respectively. The runtime is calculated by using the time[13]divides the sum of sentences used in the experiment. Because of the differences of data set in the experiment, the results can’t be compared directly with the proposed method. But these results also have significant reference. The results show that the previous works are not fast enough until the machine learning algorithms are applied to the parser. The fastest result in Tab. 5 costs 64.1 ms to analysis a sentence while the proposed method costs 4.63 ms. But the three measures of the proposed method are lower much.

Tab. 5 Previous related works
In a word, the proposed method is fast for testing a sentence and stable in closed and open test. In addition, the syntactic structure may be failed to analyze in PCFGs and the previous works in Tab. 5, while there is no fail condition in the proposed method. But thePof the proposed method is not high, possibly because the nodes and number of syntactic levels tested by the classifiers cannot be all correct.
3 Conclusion
A fast method based on conditional random fields is proposed for syntactic parsing. For constructing a syntactic tree, firstly, the method uses the bottom-up to recognize the nodes from the nearest node to the segment to the root node. Secondly, it uses the up-bottom to combine the same node tested from the root node to the segment. Based on the BFS-CTC, two experiments are designed to illustrate the process of choosing training parameters and verify the validity of method. In addition, the results of the method are compared to PCFGs. The results show that the method has a faster time in training and testing. The method is a new way for syntactic analysis. According to the ability of machine learning, the method has good generalization ability and can be used for applications which don’t need high precision but fast speed.
[1] Xue N, Xia F, Chiou F, et al. The Penn Chinese TreeBank: phrase structure annotation of a large corpus [J]. Natural Language Engineering, 2005, 11(02): 207-38.
[2] Bikel D M, Chiang D. Two statistical parsing models applied to the Chinese Treebank[C]∥Proceedings of the second workshop on Chinese language processing: held in conjunction with the 38th Annual Meeting of the Association for Computational Linguistics-Volume 12. Stroudsburg, PA, USA: Association for Computational Linguistics, 2000: 1-6.
[3] Bikel D M. On the parameter space of generative lexicalized statistical parsing models [D]. PhiLadelphia: University of Pennsylvania, 2004.
[4] Chiang D, Bikel D M. Recovering latent information in treebanks[C]∥Proceedings of the 19th international conference on Computational linguistics-Volume 1, Stroudsbury, PA, USA: Association for Computational Linguistics, 2002: 1-7.
[5] Levy R, Manning C. Is it harder to parse Chinese, or the Chinese Treebank?[C]∥Proceedings of the 41st Annual Meeting on Association for Computational Linguistics-Volume 1. Stroudsburg, PA, USA: Association for Computational Linguistics, 2003: 439-446.
[6] Xiong D, Li S, Liu Q, et al. Parsing the penn chinese treebank with semantic knowledge[M]∥Natural Language Processing-IJCNLP 2005. Berlin, Heidelberg: Springer, 2005: 70-81.
[7] Jiang Zhengping. Statistical Chinese parsing [D]. Singapore: National University of Singapore, 2004.
[8] Mi H T, Xiong D Y, Liu Q. Research on strategies for integrating Chinese lexical analysis and parsing[J]. Journal of Chinese Information Processing, 2008, 22(2): 10-17. (in Chinese)
[9] Chen Gong, Luo Senlin, Chen Kaijiang, et al. Method for layered Chinese parsing based on subsidiary context and lexical information [J]. Journal of Chinese Information Processing, 2012, 26(01): 9-15. (in Chinese)
[10] Yamada H, Matsumoto Y. Statistical dependency analysis with support vector machines [J]. Machine Learning, 1999, 34(1-3): 151-175.
[11] Sagae K, Lavie A. A classifier-based parser with linear run-time complexity [C]∥Parsing 05 Proceedings of the Ninth International Workshop on Parsing Technology. Stroudsburg, PA, USA: Association for Computational Linguistics, 2005: 125-132.
[12] Cheng Y, Asahara M, Matsumoto Y. Machine learning-based dependency analyzer for Chinese [J]. Journal of Chinese Language and Computing, 2005, 15(1): 13-24.
[13] Wang M, Sagae K, Mitamura T. A fast, accurate deterministic parser for Chinese [C]∥Proceeding ACL-44 Proceedings of the 21st International Conference on Computational Linguistics and the 44th annual meeting of the Association for Computational Linguistics. Stroudsburg, PA, USA: Association for Computational Linguistics, 2006: 425-432.
[14] Lafferty J, McCallum A, Pereira F. Conditional random fields: probabilistic models for segmenting and labeling sequence data [C]∥the Eighteenth International Conference on Machine Learning, San Francisco, CA, USA, 2012.
[15] Luo Senlin, Liu Yingying, Feng Yang, et al. Method of building BFS-CTC: a Chinese tagged corpus of sentential semantic structure [J]. Transactions of Beijing Institute of Technology, 2012, 32(03): 311-315. (in Chinese)
[16] Liu Yingying, Luo Senlin, Feng Yang, et al. BFS-CTC: a Chinese corpus of sentential semantic structure [J]. Journal of Chinese Information Processing, 2013, (27): 72-80. (in Chinese)
[17] Charniak E. Statistical parsing with a context-free grammar and word statistics [C]∥the Fourteenth National Conference on Artificial Intelligence and Ninth Conference on Innovative Applications of Artificial Intelligence, Providence, Rhode Island, 1997.
(Edited by Cai Jianying)
10.15918/j.jbit1004-0579.201524.0414
TP 391.1 Document code: A Article ID: 1004- 0579(2015)04- 0519- 07
Received 2014- 05- 03
Supported by the Science and Technology Innovation Plan of Beijing Institute of Technology (2013)
E-mail: panlimin_bit@126.com
猜你喜欢
杂志排行

Journal of Beijing Institute of Technology的其它文章
- Influence of shear sensitivities of steel projectiles on their ballistic performances
- Generalized ionospheric dispersion simulation method for wideband satellite-ground-link radio systems
- Multi-subpulse process of large time-bandwidth product chirp signal
- Factor-graph-based iterative channel estimation and signal detection algorithm over time-varying frequency-selective fading channels
- Nano-silica particles enhanced adsorption and recognition of lysozyme on imprinted polymers gels
- Similarity matrix-based K-means algorithm for text clustering