Similarity matrix-based K-means algorithm for text clustering
2015-04-22CAOQimin曹奇敏GUOQiao郭巧WUXianghua吴向华
CAO Qi-min(曹奇敏), GUO Qiao(郭巧) WU Xiang-hua(吴向华)
(School of Automation, Beijing Institute of Technology, Beijing 100081,China)
Similarity matrix-basedK-means algorithm for text clustering
CAO Qi-min(曹奇敏), GUO Qiao(郭巧)1, WU Xiang-hua(吴向华)1
(School of Automation, Beijing Institute of Technology, Beijing 100081,China)
K-means algorithm is one of the most widely used algorithms in the clustering analysis. To deal with the problem caused by the random selection of initial center points in the traditional algorithm, this paper proposes an improvedK-means algorithm based on the similarity matrix. The improved algorithm can effectively avoid the random selection of initial center points, therefore it can provide effective initial points for clustering process, and reduce the fluctuation of clustering results which are resulted from initial points selections, thus a better clustering quality can be obtained. The experimental results also show that theF-measure of the improvedK-means algorithm has been greatly improved and the clustering results are more stable.
text clustering;K-means algorithm; similarity matrix;F-measure
Text clustering is a typical unsupervised machine learning task, the aim is to divide a document set into several clusters, and it requires that the intra-document similarity is higher than inter-document similarity[1-4]. In recent years, text clustering has been widely used in information retrieval, multi document automatic summarization, information processing of short text and so on[5].
Recently, commonly-used text clustering algorithms are categoried into two types: hierarchical method and partitioning method. AGNES and DIANA are the representatives of hierarchical clustering algorithms, they have good clustering results, but time consumption is increasing rapidly with the increase of data[6]. As one representative of partitioning method,K-means algorithm has linear time complexity, its computational consumption is low, so it is applicable to a large set of text clustering[7]. However, this algorithm often end into a local optimal value, it is mainly due to that the number of cluster centers and the selection of the initial cluster centers can affect its results[8]. Especially the selection of the initial center points can easily lead to the fluctuation of the clustering results[9].
Some researchers use different distance measures to select centroid points, such as Jaccard distance co-efficient[10]and the shape similarity distance[11], they can improve the quality of clustering in some degree, but different distance measures are used for different features of heterogeneous samples. In Ref.[12], it is an incremental approach; in Ref.[13], it starts from some random points and tries to minimize the maximum intra-cluster variance, they can eliminate the dependence on random initial conditions, but they are computationally more expensive. For the choice of initial points, Ref.[14] randomly selects theKcenter points from all the objects, its drawback is that the clustering results are not consistent; Refs.[15-16] use modified differential algorithm(DE) to obtain initial center points, but the initial points of DE are randomly selected and it also increases the time of clustering. Ref.[17] presents theK-means algorithm based onk-dtrees, which is called filtering algorithm, but the initial centers are randomly selected.
In order to obtain stable clustering results and a better clustering accuracy, in this paper a new initialization method is designed to discover a reasonable set of centorids. Experiment verifies that the improved algorithm is better than the traditionalK-means algorithm.
The structure of this paper is organized as follows. Section 1 introduces the background knowledge, including vector space model, the definition of similarity and the traditionalK-means algorithm. Section 2 presents the improvedK-means algorithm. Experimental results are shown in section 3. Finally, section 4 concludes the paper.
1 Background knowledge
In the process of text clustering, vector space model (VSM) proposed by professor Salton is generally used for text representation[18]. First of all, the document was pretreated, including Chinese word segmentation and removing stop words, and then it is to use the VSM model to represent the text, where the feature words of the text consist of the vector and the weight of the feature which is the value of the vector, and finally theK-means algorithm is used to cluster documents. The flowchart of text clustering is shown in Fig.1.
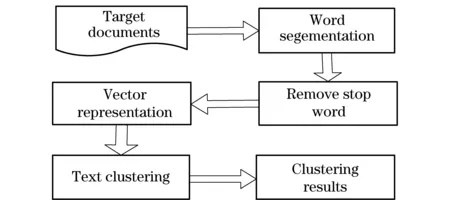
Fig.1 Flowchart of text clustering
1.1 VSM model and definition of similarity
The main idea of VSM model is to put each document into a vector, so that it realizes the transformation for text from linguistic issues to mathematical problems identified by computer. LetDrepresent a collection of documents, that isD=(d1,d2,…,dn), wherediis thei-th document in the document collection,i=1,…,n. The document can be represented as:di=(Ti1,Ti2,…,Tim), whereTijis the feature item, 1≤i≤n,1≤j≤m. The feature item is the word contained in the document. Usually each feature item was given with a weight showing the degree of importance, i.e.di=(Ti1,Wi1;Ti2,Wi2;…Tim,Wim) , abbreviated asdi=(Wi1,Wi2,…,Wim), whereWijis the weight ofTij,1≤i≤n,1≤j≤m.
In this paper, a TF-IDF weighting scheme is used as one of the best known schemes, where TF represents term frequency and IDF represents the inverse document frequency. The weight formula using TF-IDF is as follows:
(1)
whereftijis the frequency of termtiin the documentdj,fdiis the number of documents containingtiin all documents,Nis the number of all documents, the denominator is a normalization factor.
In this article, we use a cosine distance to measure similarity between the two texts. The definition of similarity is as follows:
(2)
1.2K-means algorithm
The objective function ofK-means algorithm is the square error criterion, defined as follows:
(3)
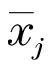
Step 1 Randomly selectKobjects as the cluster centers.
Step 2 Assign each document to its nearest cluster center according to similarity between the document and the cluster center.
Step 3 Calculate the mean value of each changed cluster as the new cluster center.
Step 4 If the new cluster center and the original cluster is the same, exit the algorithm, else go to step 2.
2 Improved K-means algorithm
TheK-means algorithm is used for text clustering. When the result clusters are compact and the differences between clusters are obvious, its results are better. However, because the initial center point is selected randomly, the algorithm often ends into the local optimal. In addition, it is sensitive to “noise” and outliner data, small amounts of such data can have a great effect on the result.
Although there is no guarantee of achieving a global optimal value, at leastK-means algorithm can converge[19]. So, it is very important to choose proper initial cluster centers for theK-means algorithm. TheK-means algorithm can obtain better results when the initial centroid points were close to the final solution[20]. Therefore, this paper presents similarity matrix-basedK-means text clustering algorithm, the specific process is as follows:
In step 1 a VSM model is used to present the document as the vector, the similarity between every two documents is calculated by using cosine distance. Assume that there arendocuments, then the similarity matrix S is: S=(sij)n×n, wheresij=Sim(di,dj),i,j=1,…,n.
Step 2 sums each row of the matrixSaccording to the following formula
(4)
this is to calculate the similarity between each document and the document set.
Step 3 rankssi(i=1,…,n) in a descending order, the maximum is set tosl, and then the documentdlis selected corresponding toslas the first initial center point.
Step 4 ranksslj(j=1,…,n) in an ascending order, might as well let theK-1 minimum values areslj(j=1,…,K-1), select the documentsdj(j=1,…,K-1) corresponding toslj(j=1,…,K-1) as theK-1 initial center points. Therefore,dlanddj(j=1,…,K-1) consist ofKinitial center points, whereK
Step 5 is done for each of the remaining documents (not being chosen as initial cluster center), they are assigned to their nearest cluster centers according to their similarities with the cluster center, andKclusters can be obtained.
Step 6 calculates the mean value of each changed cluster as the new cluster center.
In step 7 if the new cluster center and the original cluster are the same, exit the algorithm, else go to step 5.
The logic workflow of this algorithm is in Fig. 2.
From theK-means algorithm, it is not difficult to see thatKpoints are chosen as initial cluster centers in the initial stage of the algorithm, and then iterate repeatedly on the basis of them. If the initial center points are different, the clustering results might vary significantly. The clustering results of theK-means algorithm are highly dependent on the initial value, which may result into unstable clustering results. The algorithm proposed by this article is on the basis of similarity matrix, first select the central one in all the files, and then selectK-1 documents which are at the greatest distance from the central one, each iteration uses the mean value of the cluster as the judgment standard, if two consecutive iteration results are the same, then algorithm terminates, otherwise the iteration continues.

Fig.2 Logic workflow of improved algorithm
Theoretically, theKinitial points selected by the proposed method can be as close to the true centers of clusters as possible and they can belong to different clusters as far as possible, so it can reduce the number of iterations and can improve the accuracy of clustering. Even if the clusters are very sparse, the algorithm also can obtain good clustering results, it reduces the impact of “noise” and outlier data. The improvedK-means algorithm can also avoid the empty cluster problem that plagues traditionalK-means algorithm which is likely to lead to an unsuitable solution. In the next section, experiments will validate this conclusion.
3 Experiments and analysis
3.1 Evaluation method of text clustering
In this paper,F-measure is applied as the evaluation method of text clustering.F-measure belongs to external evaluation, external evaluation method is to compare the clustering results with the results previously specified, and the differences between the subjective of people are measured with the clustering results. For the clusterjand the correct categoryi, the formula of the precision rateP, recall rateK,F-measureF(i) are as follows:
(5)
(6)
(7)
whereNidenotes the number of text in the correct categoryi,Njdenotes the number of text in the clusterj,Nijdenotes the number of text in the clusterj, which originally belong to the correct categoryi.
3.2 Datasets
In the experiment, texts are downloaded from standard corpora. For evaluating its performance in different languages, Reuters 21578 classical corpus and CCL (Peking University modern Chinese corpus) are used. Nine categories are chosen from each corpus, they are Politics, Economics, Sports, Society, Weather, Science, Military, Literature, Culture. Each category contains 2000 documents.
3.3 Experimental results
In order to evaluate the improvement of the improvedK-means algorithm in the performance ofF-measure, experiments are carried out to compare with the traditionalK-means algorithm, DE basedK-means algorithm and filtering algorithm, the experimental results are as shown in Tab.1 and Tab.2.

Tab.1 F-measure comparison in English text clustering
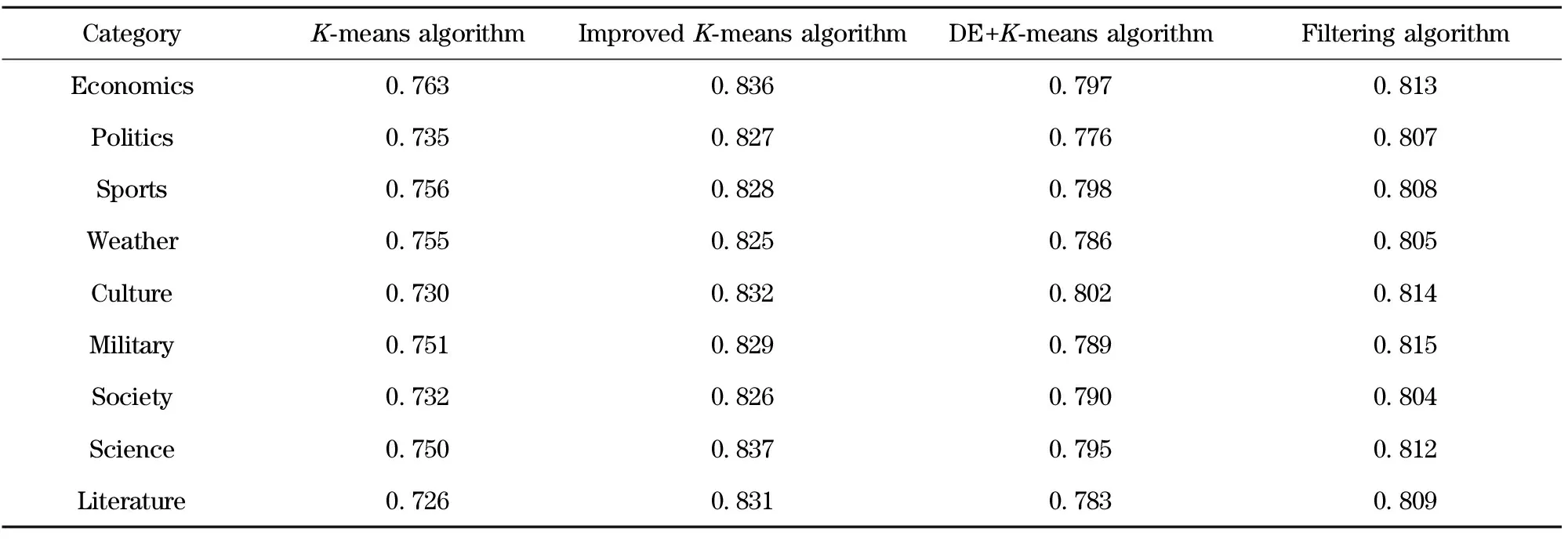
Tab.2 F-measure comparison in Chinese text clustering
Meanwhile, in order to literally visualize the effectiveness of the initial centroids selected by the proposed method, some points are selected from three Gaussians and these points are of two dimensions. The experimental results are as shown in Figs.3-6.
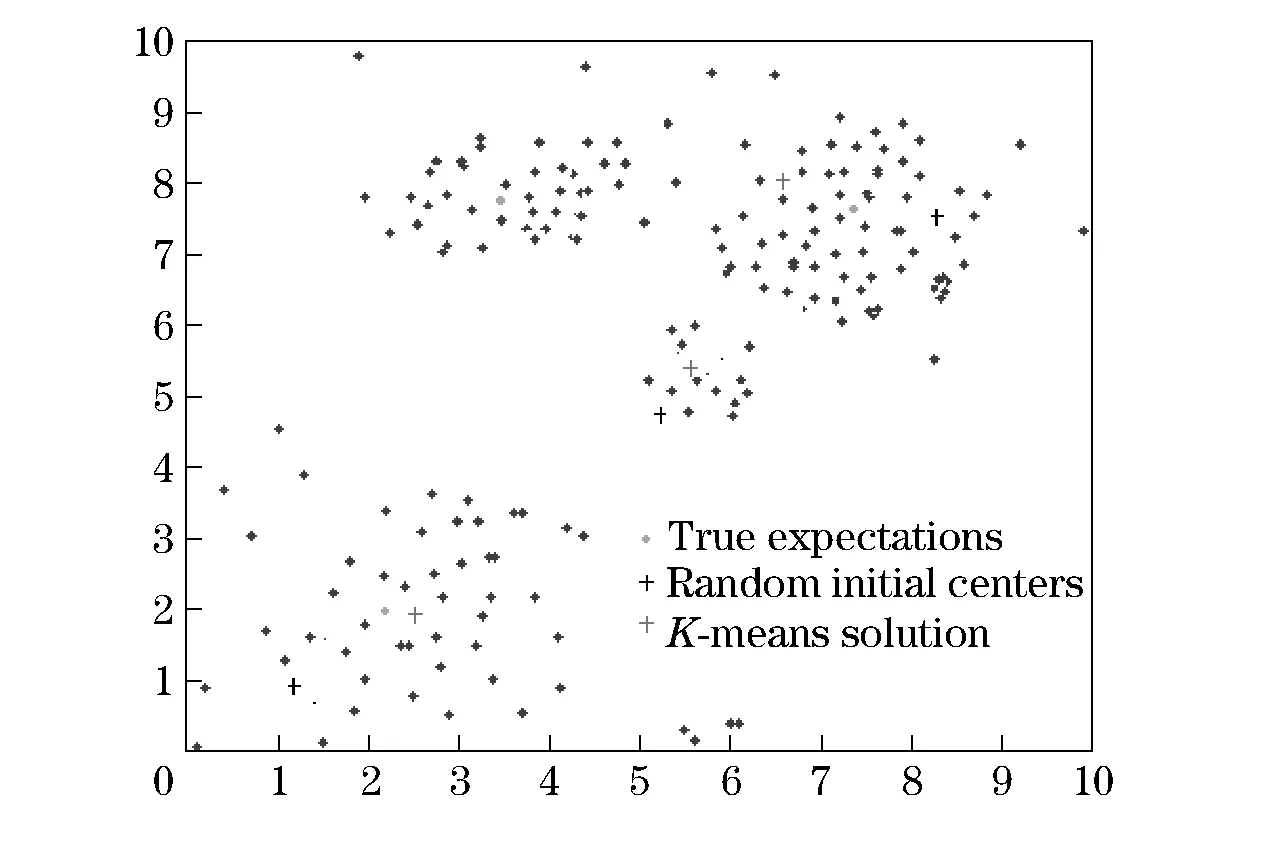
Fig.3 K-means solution from random initial centers
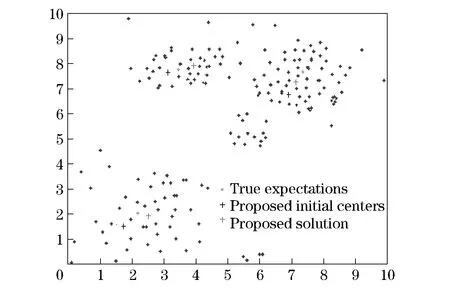
Fig.4 Proposed solution from proposed initial centers

Fig.5 DE+K-means solution from its initial centers
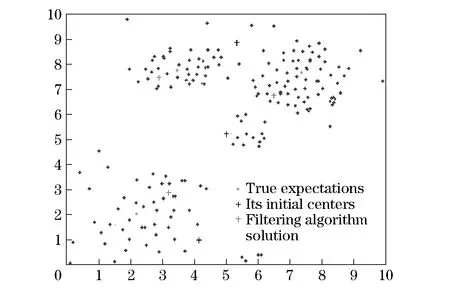
Fig.6 Filtering algorithm solution from its initial centers
Fig.3 shows random initial center points and the corresponding solution of the traditionalK-means algorithm. Fig.4 shows the initial points chosen using similarity matrix and the results of the algorithm proposed by this paper. Fig.5 shows the initial center points chosen by the DE module and the results of theK-means algorithm based on DE. Fig.6 shows the initial center points and the results of the filtering algorithm.
3.4 Analysis of experimental results
It is seen from Tab.1 and Tab.2, compared to the traditionalK-means algorithm,F-measure of the improvedK-means algorithm has been improved obviously, and the experimental results are relatively stable. Compared to DE basedK-means algorithm and filtering algorithm, the improvedK-means algorithm also has higherF-measure. This shows that the improvedK-means algorithm in the certain degree avoids failing into local minima problem, which was met when the traditionalK-means algorithm converges. The initial center points chosen by the improvedK-means algorithm are representative, thus the improvedK-means algorithm obtained a higherF-measure and more stable clustering results.
From Fig.3- Fig.6, it is shown that the proposed initial points are very close to the true solution. So it can be concluded that the improved algorithm has a better performance.
4 Conclusion
TheK-means algorithm is sensitive to initial center points in the process of document clustering, this paper proposes an improvedK-means algorithm based on the similarity matrix. The improved algorithm can effectively avoid the random selection of initial center points, it provides effective initial points for clustering process which are very close to the true solution, reduces the fluctuation of clustering results resulted from initial points, thus it can obtain a better clustering quality. The experimental results also show that theF-measure of the improvedK-means algorithm has been greatly improved and the clustering results are more stable. In this paper, the effectiveness of the initial centroids selected by the proposed method have been literally visualized through experiments.
However, the performance of the algorithm still has space to be improved by determining the number of clusters automatically. The traditionalK-means algorithm itself has two flaws, first it is easily influenced by the outliner data and poor clustering results can be obtained, the second is that it is influenced by the numberKof clusters, which is appropriate or not, has a great impact on the clustering results. The selection of initial points effectively just only solves the first one flaw, does not resolve the second flaw. Therefore the direction of future research is how to adaptively determine the value ofK.
[1] Shi Z Z. Knowledge discovery[M]. Beijing: Tsinghua University Press, 2002.
[2] Han J, Kamber M. Data mining: concepts and techniques[M]. San Francisco: Morgan Kaufmann Publishers, 2000.
[3] Grabmeier J, Rudolph A. Techniques of cluster algorithms in data mining[J]. Data Mining and Knowledge Discovery, 2002, 6(4):303-360.
[4] Meyer C D, Wessell C D. Stochastic data clustering[J]. SIAM Journal on Matrix Analysis and Applications, 2012, 33(4): 1214-1236.
[5] Hammouda K M, Kamel M S. Efficient phrase-based document indexing for web document clustering[J]. IEEE Transactions on Knowledge and Data Engineering, 2004, 16(10):1279-1296.
[6] Rousseeuw P J, Kaufman L. Finding groups in data: an introduction to cluster analysis[M].New York: John Wiley & Sons, 2009.
[7] Gnanadesikan R. Methods for statistical data analysis of multivariate observations[M]. New York: John Wiley & Sons, 2011.
[8] Huang J Z, Ng M K, Rong H, et al. Automated variable weighting inK-means type clustering[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(5):657-668.
[9] Celebi M E, Kingravi H A, Vela P A. A comparative study of efficient initialization methods for the k-means clustering algorithm[J]. Expert Systems with Applications, 2013, 40(1): 200-210.
[10] Shameem M U S, Ferdous R. An efficient k-means algorithm integrated with Jaccard distance measure for document clustering[C]∥AH-ICI 2009, First Asian Himalayas International Conference on Internet, 2009: 1-6.
[11] Li D, Li X B, A modified version of the K-means algorithm based on the shape similarity distance[J]. Applied Mechanics and Materials, 2014, 457: 1064-1068.
[12] Bagirov A M, Ugon J, Webb D. Fast modified global k-means algorithm for incremental cluster construction[J]. Pattern Recognition, 2011, 44(4): 866-876.
[13] Tzortzis G, Likas A. The MinMax k-means clustering algorithm[J]. Pattern Recognition, 2014, 47(7): 2505-2516.
[14] Khan S S, Ahmad A. A cluster center initialization algorithm for K-means clustering[J]. Pattern Recognition Letters, 2004, 25(11):1293-1302.
[15] Aliguliyev R M. Clustering of document collection a weighting approach[J]. Expert Systems with Applications, 2009, 36(4):7904-7916.
[16] Abraham A, Das S, Konar A. Document clustering using differential evolution[C]∥CEC 2006 IEEE Congress on Evolutionary Computation, 2006: 1784-1791.
[17] Kanungo T, Mount D M, Netanyahu N S, et al. An efficient K-means clustering algorithm: analysis and implementation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002,24(7):881-892.
[18] Salton G, Wong A, Yang C S. A vector space model for automatic indexing[J]. Communications of the ACM, 1975, 18(11): 613-620.
[19] Selim S Z, Ismail M A. K-means-type algorithms: a generalized convergence theorem and characterization of local optimality[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1984(1): 81-87.
[20] Jain A K, Dubes R C. Algorithms for clustering data[M]. Englewood Cliffs:Prentice Hall, 1988.
(Edited by Wang Yuxia)
10.15918/j.jbit1004-0579.201524.0421
TP 391.1 Document code: A Article ID: 1004- 0579(2015)04- 0566- 07
Received 2014- 04- 14
E-mail: caoqiminisbest@163.com
杂志排行

Journal of Beijing Institute of Technology的其它文章
- Influence of shear sensitivities of steel projectiles on their ballistic performances
- Generalized ionospheric dispersion simulation method for wideband satellite-ground-link radio systems
- Multi-subpulse process of large time-bandwidth product chirp signal
- Factor-graph-based iterative channel estimation and signal detection algorithm over time-varying frequency-selective fading channels
- Nano-silica particles enhanced adsorption and recognition of lysozyme on imprinted polymers gels
- Optimizing control of a two-span rotor system with magnetorheological fluid dampers