基于感知器的中文分词增量训练方法研究
2015-04-21刘一佳车万翔
韩 冰,刘一佳,车万翔,刘 挺
(哈尔滨工业大学 计算机学院社会计算与信息检索研究中心,黑龙江 哈尔滨 150001)
基于感知器的中文分词增量训练方法研究
韩 冰,刘一佳,车万翔,刘 挺
(哈尔滨工业大学 计算机学院社会计算与信息检索研究中心,黑龙江 哈尔滨 150001)
该文提出了一种基于感知器的中文分词增量训练方法。该方法可在训练好的模型基础上添加目标领域标注数据继续训练,解决了大规模切分数据难于共享,源领域与目标领域数据混合需要重新训练等问题。实验表明,增量训练可以有效提升领域适应性,达到与传统数据混合相类似的效果。同时该文方法模型占用空间小,训练时间短,可以快速训练获得目标领域的模型。
中文分词;领域适应;增量训练
1 引言
词是汉语中的最小语义单元。由于汉语以字为基本书写单位,词与词之间没有明显的分割标记,中文分词成为中文信息处理的基础与关键,在信息检索、文本挖掘等任务中被广泛使用。近年来,基于统计的中文分词方法在新闻领域取得了很好的性能[1-4]。但随着互联网、社交媒体与移动平台的迅猛发展,当前中文分词方法处理的数据不单局限于新闻领域,不断增长的开放领域数据对中文分词方法提出了新的挑战。前人研究[5-7]表明,使用新闻领域资料训练的中文分词模型切换到诸如论坛、微博、小说等领域时,性能往往严重下降。
前人工作[6]将这种训练与测试领域的不一致导致模型性能下降的问题归纳为领域适应问题。在使用新闻领域训练的分词模型处理开放领域时,新闻领域为源领域,开放领域为目标领域。出现这种问题主要有两点原因: 一是不同领域数据文体不一致,例如,小说与新闻使用不同的语言风格;二是不同领域间领域词典不一致,例如,金融领域经常使用“做空”“配资”等新闻领域不常用的词汇。Liu和Zhang[6]通过在分词词性标注联合模型上加入聚类特征的方式捕捉源领域与目标领域的相似性,以解决文体差异过大问题。Zhang等[5]将目标领域词典融入模型,避免了源领域与目标领域词典差异过大。Liu等[7]提出了一种利用网络文本中自然存在的分词边界的方法,在基于条件随机场(CRF)模型的分词系统上提高了领域适应性。
上述研究表明,使用目标领域切分数据训练模型是一种领域适应问题的高精度方法。同时,在源领域切分数据的基础上加入目标领域数据这类混合训练数据的方法可以进一步提高切分中文分词准确率[5,7-8]。然而,多方面因素限制了这一类方法的适用性。其一,大规模切分数据往往很难获得,使得混合训练数据的方法难以应用于实际场景;其二,针对每个目标领域,混合数据方法都需要在包含源领域的大规模数据上重新训练模型,使得这种方法很难快速获得模型并部署。
针对上述问题,本文提出一种了基于感知器的中文分词增量训练方法。该方法通过在已有模型的基础上继续训练,可以在不需要源领域切分数据的情况下,利用少量目标领域标注数据获得与混合模型相近的性能。同时本文针对增量训练提出了一种优化的实现方法,显著降低了训练代价。本文分词器将在https://github.com/HIT-SCIR/ltp开源。
2 问题描述
本文主要解决多领域应用场景下的中文分词领域适应问题(图1)。本文假设源领域数据在训练领域适应模型时对用户不可见,但源领域模型可见。本文同时假设用户有少量目标领域标注数据。最后,本文假设源领域模型同时服务于多个目标领域。
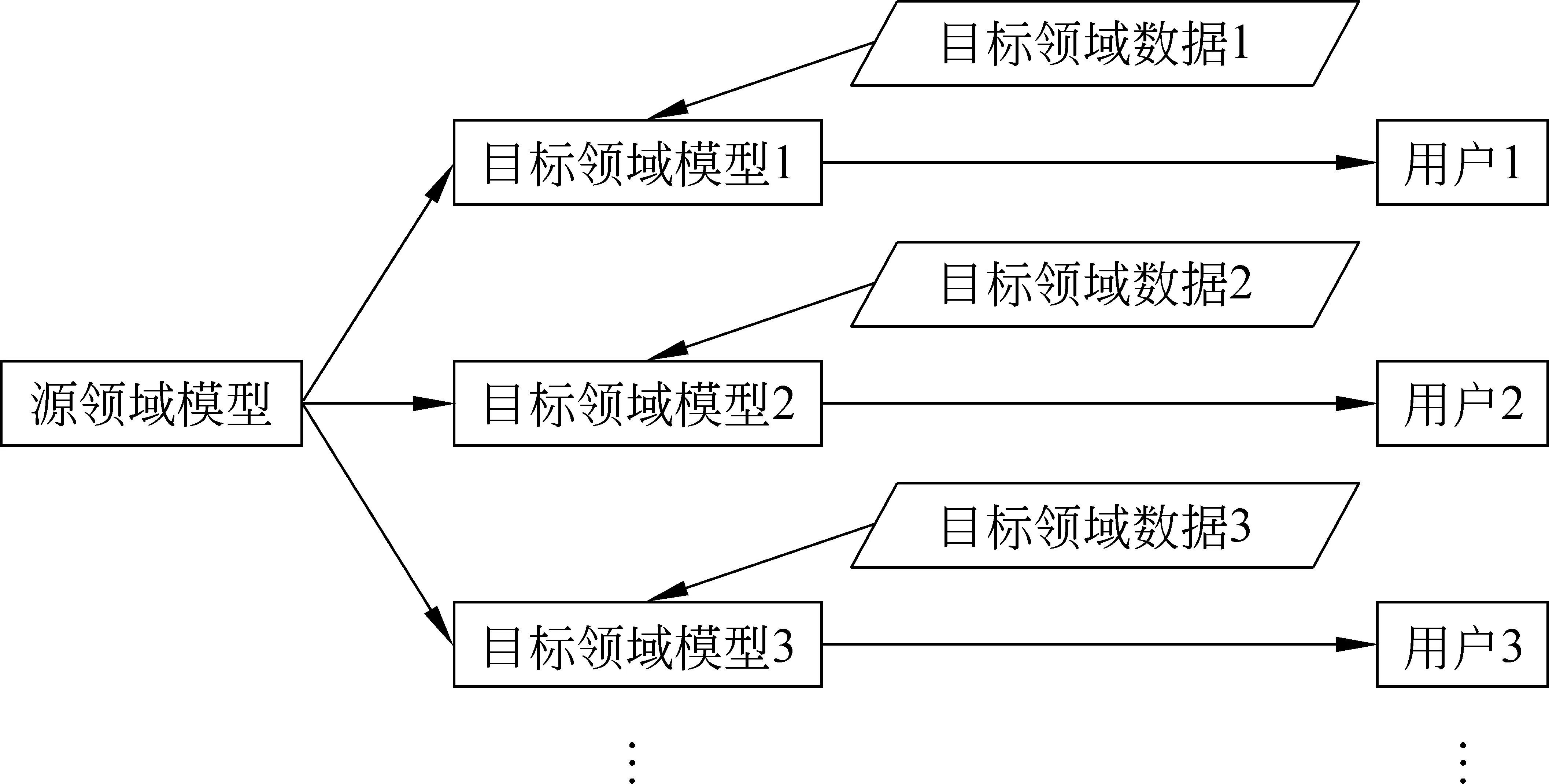
图1 多领域应用场景示意图
针对以上问题描述,本文训练算法应具有下述特点:
• 不更改源领域模型;
• 目标领域模型与混合数据训练的模型性能相近;
• 目标领域模型精简。
3 基于感知器的中文分词
本文参照前人工作[3,9],将中文分词建模为基于字的序列标注问题。模型给句子中的每个字标注一个表示词边界的标记。本文采用了{B、I、E、S}四种标记,其中B代表词语的开始,I代表词语的中间,E代表词语的结尾,S代表单个字词语。以“总理李克强调研上海外高桥”为例,标注结果如图2所示。
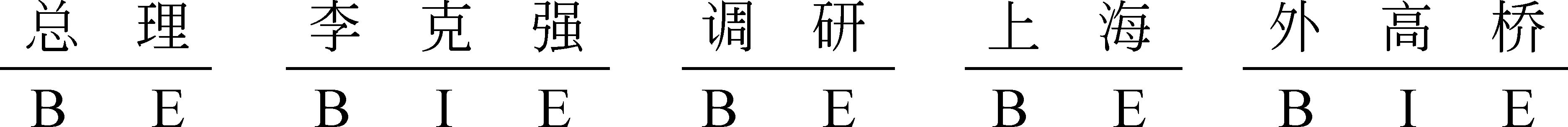
图2 分词序列标注示例
本文采用结构化感知器模型(Structured Perceptron[10])训练。为了防止模型过拟合,采用平均感知器算法对训练过程中的参数求平均。基于感知器的中文分词训练算法如算法1所示。

算法1 平均感知器模型训练算法1:输入:D={(x,y)}N2:w←03:fort=1…Tdo4: forxi,yi()∈Ddo5: z=argmaxy'∈GEN(xi)(φ(xi,y')·w)6: ifz≠ythen w←w+φxi,yi()-φ(xi,z)8: endif9: endfor10:endfor11:w-=1NT∑n=1..N,t=1..Twn,t12:returnw-
4 平均感知器增量训练算法
为了解决重复训练,领域数据快速更迭等问题,本文在结构化感知器中文分词的基础上提出一种增量式训练算法。
4.1 算法
本文方法可以归纳为在已有感知器分词模型基础之上继续训练。增量式训练算法包含两个阶段: 第一阶段的训练算法与传统感知器算法相同,用数据集D1训练得到模型w1;第二阶段,用数据集D2和模型w1训练模型得到模型w2(如算法2所示)。

算法2 感知器模型增量训练算法1:w1←perceptron-train(D1)2:w2←incremental-perceptron-train(w1,D2)
在实际应用情景中,D1是相对丰富且不同于目标领域的标注数据,例如新闻领域数据;D2是目标领域(如财经、小说等)的相对较少的标注数据。第二阶段的训练算法,以模型w1和目标领域数据D2为输入。设D1有N1条数据,第一阶段迭代训练T1次,第二阶段同理,wn,t表示在第t轮更新第n个数据时的参数向量,则第二阶段的平均参数为式(1)。
(1)
4.2 增量训练收敛性的证明
Collins等人[10]证明了结构化感知器算法的收敛性。本文提出了一种增量训练算法,需要回答“增量训练算法能否在D2数据上有限步骤内收敛”,亦即证明其收敛性。由于增量训练采用第一阶段的模型参数做为初始参数值,增量训练的收敛性证明问题等价于证明感知器算法在初始权重w1≠0时的收敛性。本文沿用Collins等人[10]的证明方法,在这一段证明增量训练算法在D2线性可分的情况下收敛。
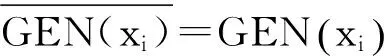
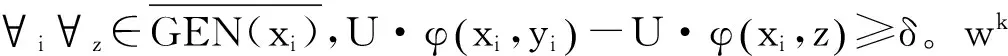
定理: 增量训练算法在D2线性可分情况下收敛。
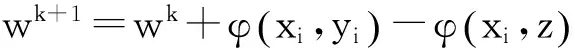
同理可证线性不可分的情况下增量训练依旧收敛,限于篇幅限制该证明省略。
4.3 优化的增量训练实现方法
在上述增量训练算法中,第二阶段先复制创建一个与w1一样的模型,并在此基础上增添训练语料D2迭代更新参数,最终输出一个新的模型w2。然而,第二阶段仅更新了在D2语料中出现的特征对应的参数,完全复制一份w1在空间上是十分低效的。为此本文提出了一种更高效的实现方法。在第二阶段,方法创建一个新的模型wΔ来记录原始第二阶段训练的参数改变量,新模型wΔ的工作依赖于w1。原始领域特征空间、混合训练特空间与增量训练特空间如图3所示。由于第二阶段仅更新了D2中出现的参数,因此增量模型wΔ只需记录与D2相关的参数,大大缩小了空间。优化后的增量训练第二阶段算法如算法3所示。

图3 特征空间对比图

算法3 优化增量训练第二阶段算法1:输入:D2={(x,y)}N2,w12:fort=T1+1…T2do3: forxi,yi()∈D2do4: z=argmaxy'∈GENxi()(φ(xi,y')·w+φΔ(xi,y')·wΔ)5: ifz≠ythen6: wΔ←wΔ+φΔxi,yi()-φΔ(xi,z)7: endif8: endfor9:endfor10:wΔ=1N1T1+N2T2æèç∑n=1..N1,t=1..T1wn,t+∑n=1..N2,t=T1.T1+T2.wn,töø÷11:returnwΔ
5 实验
5.1 实验设置
本文在CTB5.0和诛仙网络小说数据上进行试验。CTB5.0数据划分参照前人工作[11],用于训练第一阶段模型。诛仙小说数据划分参照Zhang等[5],训练集用于训练第二阶段模型,测试集用于评价模型性能。为了模拟不同训练数据规模下算法的性能,随机选取500句诛仙训练数据作为小规模训练集,并用全部训练数据作为大规模数据。
在基于字的分词模型的特征方面,本文参考张梅山等[12]的论文,并从一定程度上简化了其中的词典特征。本文的分词器使用的特征列表如表1所示。
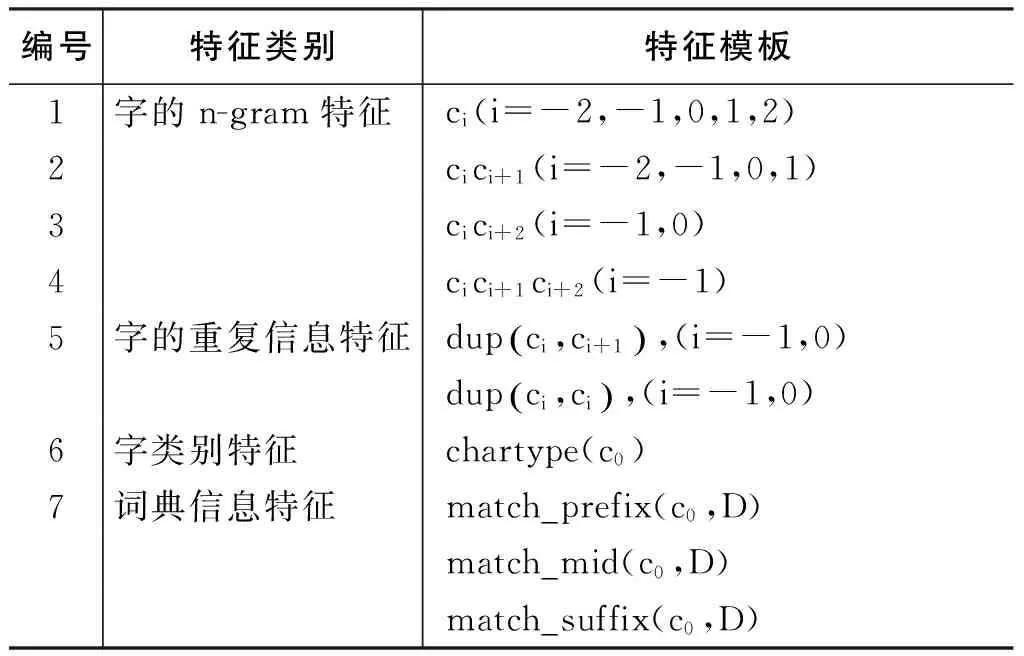
表1 分词器使用的特征
其中,下标i代表特征模板中的字与待标注字的相对位置。dup(x,y)表示x,y是否为相同字,chartype(c)表示c的字类型,字类型包括字母(例如,“A”),数字(例如,“1”)以及标点(例如,“,”)。本文使用的词典特征主要有三类,match_prefix(c0,D)表示以c0为词首的句子片段在词典D中匹配的最长的词,match_mid(c0,D)表示以c0为词中而match_suffix(c0,D)表示以c0为词尾。本文使用的词典通过训练语料构造。构造方法是抽取训练语料中出现的频率大于等于5的词以及其词性构成词典。
5.2 增量训练实验
本文基线系统是使用CTB5.0训练数据训练的基于字的感知器中文分词模型,表2显示了基线模型的实验结果。本文分别在新闻(CTB5.0)和诛仙(ZX)测试集上评价基线模型性能。在与训练数据同源的新闻(CTB5.0)测试集上,基线模型的F值为96.65%,而在诛仙测试集上,F值降到86.55%。这说明单独由新闻领域数据训练的模型在诛仙数据集上存在领域适应问题。

表2 基线分词模型实验结果
为模拟不同规模目标领域的情况,本文分别采用随机选取的500句和2 400句诛仙领域语料作为目标领域的训练数据。表3显示了不同方法利用两种规模训练数据训练的模型在诛仙测试集上的性能。第一行表示仅使用诛仙训练数据训练模型的情况下模型的性能;第二行表示使用新闻语料和诛仙语料混合训练获得的模型在诛仙领域上的性能;第三行表示使用本文提出的增量训练方法训练获得的模型的性能。
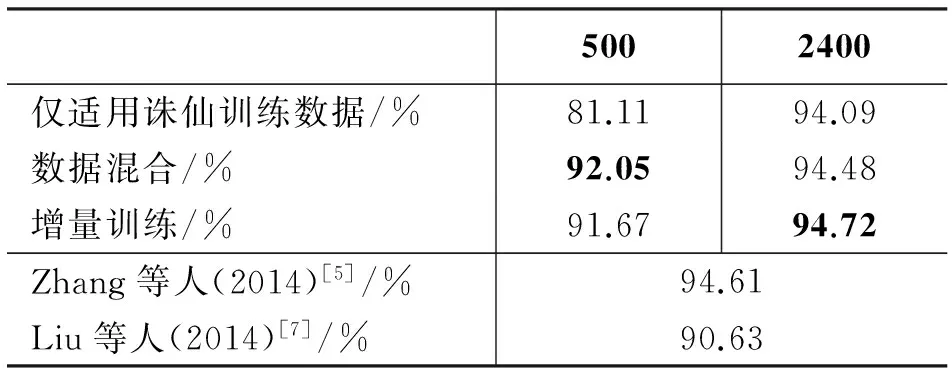
表3 增量训练实验结果
通过对比表3第一行和第二行结果,可以得出结论: 对于数据规模较小的领域,单独使用小规模数据并不能获得性能令人满意的模型。通过对比表3第二行和第三行结果,F值在小规模训练集上下降0.39%,在大规模数据集上提升了0.24%,结果表明二者性能相近。
本文也将实验结果与相同数据集上的前人工作进行了对比。本文提出的增量训练方法在2 400句训练数据条件下,较Zhang等人[5]提出的当前准确率最好的模型获得了微小的提升。但由于Zhang等人使用的模型是分词词性标注联合模型,同时使用了词典以及自学习等策略。两者不具备直接考可比性。
5.3 实验分析
在关注增量训练准确率的同时,模型大小以及模型训练时间也是本文关注的一个方面。本文经验性地比较了增量训练与传统混合训练的模型大小(表4)。从表4可以看出,本文提出的优化实现方法可以显著减少模型大小。
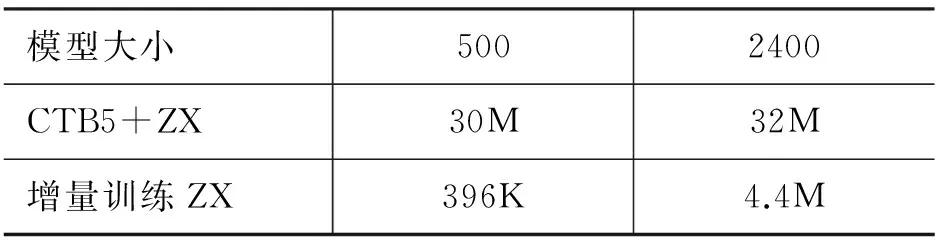
表4 不同实现方法的模型大小
同时,本文比较了增量训练与混合数据方式训练的时间开销。在开发集上,本文将不同数据规模下增量训练的时间收敛曲线如图4所示。在小规模训练集上,增量训练相对于传统训练迅速达到最优结果。在大规模训练集上,二者趋于一致。
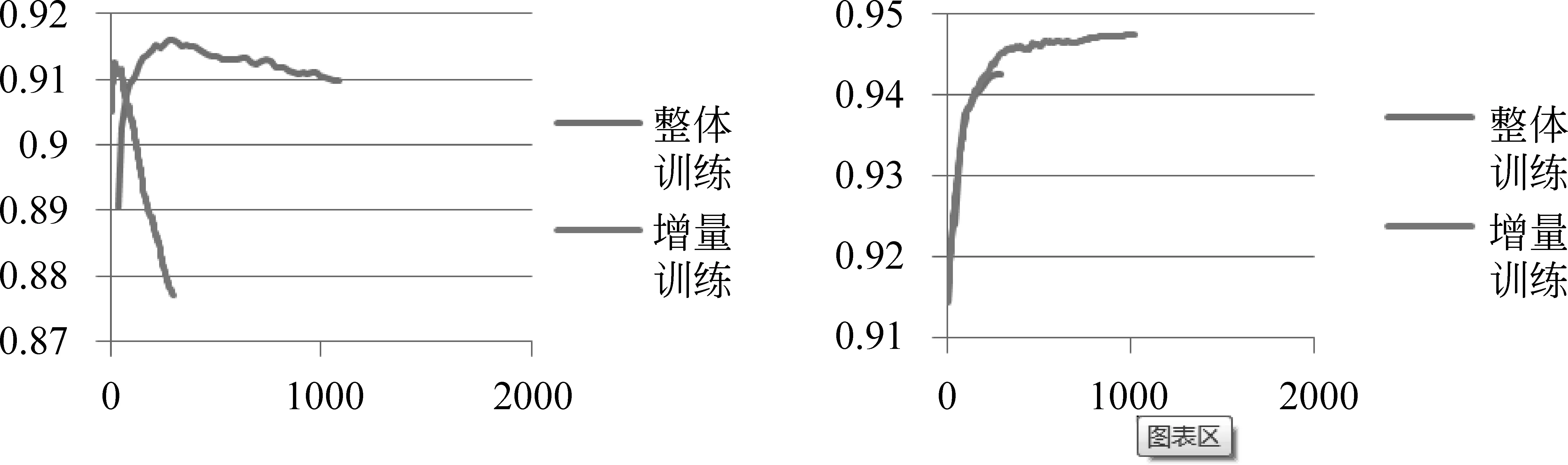
图4 训练时间效率对比图左图为500句训练集的,右图为2 400句训练集,图中横轴代表训练时间,单位为秒,纵轴为开发集上的F值
上述实验表明,增量训练算法可以有效解决领域适应问题,通过在增量训练第二阶段添加目标领域语料,能有效提高在目标领域的性能。增量训练相对于传统混合训练方式,在准确性上基本持平,而在空间效率和时间效率上具有明显优势。
6 结论
针对领域适应问题,本文提出了一种增量训练算法来解决增加目标领域数据方面的限制。我们证明了增量训练算法可以在目标领域训练数据收敛。实验表明,通过在增量训练第二阶段添加目标领域训练语料,可以有效提升目标领域分词效果,并且增量训练算法模型占用的空间小,训练速度更快。
[1] XUE N, SHEN L. Chinese word segmentation as LMR tagging[C]//Proceedings of the second SIGHAN workshop on Chinese language processing. 2003, 17: 176-179.
[2] ZHANG Y, CLARK S. Chinese Segmentation with a Word-Based Perceptron Algorithm[C]//Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics. 2007: 840-847.
[3] SHI Y, WANG M. A dual-layer CRFs based joint decoding method for cascaded segmentation and labeling tasks[C]//Proceedings of IJCAI. 2007, 7: 1707-1712.
[4] SUN W. Word-based and Character-based Word Segmentation Models: Comparison and Combination[C]//Proceedings of the COLING 2010: Posters. 2010: 1211-1219.
[5] ZHANG M, ZHANG Y, CHE W,et al. Type-Supervised Domain Adaptation for Joint Segmentation and POS-Tagging[C]//Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics. 2014: 588-597.
[6] LIU Y, ZHANG Y. Unsupervised Domain Adaptation for Joint Segmentation and POS-Tagging[C]//Proceedings of COLING 2012: Posters. 2012: 745-754.
[7] LIU Y, ZHANG Y, CHE W, et al. Domain Adaptation for CRF-based Chinese Word Segmentation using Free Annotations[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2014: 864-874.
[8] LIU Y, ZHANG M, CHE W, et al. Micro blogs Oriented Word Segmentation System[C]//Proceedings of the Second CIPS-SIGHAN Joint Conference on Chinese Language Processing. 2012: 85-89.
[9] XUE N. Chinese word segmentation as character tagging[J]. Computational Linguistics and Chinese Language Processing, 2003, 8(1): 29-48.
[10] COLLINS M. Discriminative Training Methods for Hidden Markov Models: Theory and experiments with perceptron algorithms[C]//Proceedings of the ACL-02 conference on Empirical methods in natural language processing-Volume 10. 2002: 1-8.
[11] SUN W, XU J. Enhancing Chinese word segmentation using unlabeled data[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. 2011: 970-979.
[12] 张梅山, 邓知龙, 车万翔,等. 统计与词典相结合的领域自适应中文分词[J]. 中文信息学报, 2010, 26(2): 8-12.
An Incremental Learning Scheme for Perceptron Based Chinese Word Segmentation
HAN Bing, LIU Yijia, CHE Wanxiang, LIU Ting
(Research Center for Social Computing and Information Retrieval,Harbin Institute of Technology, Harbin, Hei Longjiang 150001, China)
In this paper, we propose an incremental learning scheme for perceptron based Chinese word segmentation. Our method can perform continuous training over a fine tuned source domain model, enabling to deliver model without annotated data and re-training. Experimental results shows the scheme proposed can significantly improve adaptation performance on Chinese word segmentation and achieve comparable performance with traditional method. At the same time, our method can significantly reduce the model size and the training time.
Chinese word segmentation; domain adaptation; incremental learning

韩冰(1990—),硕士研究生,主要研究领域为自然语言处理。E-mail:bhan@ir.hit.edu.cn刘一佳(1988—),博士研究生,主要研究领域为自然语言处理。E-mail:yjliu@ir.hit.edu.cn车万翔(1980—),副教授,主要研究领域为自然语言处理。E-mail:car@ir.hit.edu.cn
1003-0077(2015)05-0049-06
2015-07-26 定稿日期: 2015-09-16
TP391
A
