中文维基百科的实体分类研究
2015-04-21徐志浩惠浩添钱龙华朱巧明
徐志浩,惠浩添,钱龙华,朱巧明
(1. 苏州大学 自然语言处理实验室,江苏 苏州 215006;2. 苏州大学 计算机科学与技术学院,江苏 苏州 215006)
中文维基百科的实体分类研究
徐志浩1,2,惠浩添1,2,钱龙华1,2,朱巧明1,2
(1. 苏州大学 自然语言处理实验室,江苏 苏州 215006;2. 苏州大学 计算机科学与技术学院,江苏 苏州 215006)
维基百科实体分类对自然语言处理和机器学习具有重要的作用。该文采用机器学习的方法对中文维基百科的条目进行实体分类,在利用维基百科页面中半结构化信息和无结构化文本作为基本特征的基础上,结合中文的特点使用扩展特征和语义特征来提高实体分类性能。在人工标注的语料库上的实验表明,这些额外特征有效地提高了ACE分类体系上的实体分类性能,总体F1值达到96%,同时在扩展实体分类上也取得了较好的效果,总体F1值达95%。
维基百科;实体分类;半结构化信息;信息框
1 引言
维基百科作为一个开放的知识库系统,其中的条目都是对一个概念或者实体的内容描述,每个条目的页面中包含了丰富的结构化、半结构化的信息和文本资源。维基百科实体分类是指对维基百科中的条目进行识别和分类,从中提取出各种类型的实体(如人物、组织、地名等)。对于这些实体的分类有助于进一步从维基百科中挖掘出更丰富的信息(如实体关系、语义关系等),同时维基百科中丰富的文本也为自然语言处理和机器学习提供了高质量的语料来源[1-2]。
2 相关工作
对维基百科条目进行实体的识别和分类,目前主要有两种方法: 基于启发式规则的方法和基于机器学习的方法。早期的方法主要是基于规则,如Bunescu 和Pasca[3]利用了标题首字母大写等一系列规则来识别英文维基百科的某个条目是否是一个命名实体。Zirn等[4]进一步利用分类框(Category)中心词的单复数形式这一规则,他们认为如果类别中心词是以单数形式出现的,这个中心词就是一个实体。Toral等[5]则首先提取条目摘要中的第一句(称为定义句),并找出句中所有名词在WordNet中的语义层次及类别来帮助确定条目所属的实体类别。基于规则方法的缺点是缺乏灵活性,需要对不同的实体类型制定不同的规则,并且随着规则的增多,不同规则之间可能会产生冲突。
利用机器学习来进行实体识别和分类可以克服这一缺点。Bhole[6]在维基百科条目文章的第一段和全文文本上,分别利用词包(bag-of-words)模型,使用SVM进行条目的实体分类工作。Tardif等[7]将维基百科的摘要文本作为基本特征,并使用了分类框、信息框(Infobox)和模板(Template)等内容作为额外特征。Dakka 和 Cucerzan[8]则将条目中的词汇、结构化信息(如表格)、摘要等内容作为特征进行组合,来获得最好的分类效果。在Tardif和Dakka的实验中,都对比了使用SVM分类器和朴素贝叶斯分类器的实验结果,他们的实验结果都表明SVM的分类性能更好。
上述工作都是针对英文维基百科上的实体识别和分类,目前还没有中文维基百科上的实体分类工作。虽然和英文维基百科相比,中文维基百科的容量要小得多,但它对中文自然语言处理的潜力还没有被充分挖掘出来,相关的工作也比较少[9-10]。因此,对中文维基百科的条目进行实体识别和分类具有一定的研究价值。本文在传统特征的基础上,提出了一系列针对中文特点的有效特征,使用SVM分类器进行中文维基百科的实体分类,取得了较好的结果。
3 维基百科页面格式
维基百科中每个条目都是对一个概念或实体的描述,条目的内容由网络志愿者协作编撰,任何使用互联网的用户都可以编写和修改维基百科条目的文章内容。在编写过程中,用户须遵循维基百科的格式要求。图1为一个典型的维基百科页面格式,它具有丰富的半结构化信息和非结构化文本,其主要内容有:
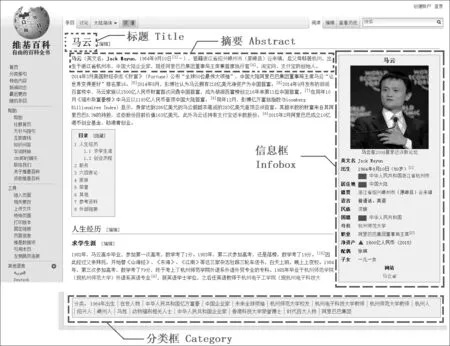
图1 维基百科页面格式
1. 信息框(Infobox): 信息框模板是一个总结性的提纲列表,总结了与条目相关的主题,亦或包含图像、地图等信息。信息框中内容的格式为标签(label)与数据(data),例如“马云”这个人物条目的信息框中有“出生 1964年9月10日”、“国籍 中华人民共和国”、“母校 杭州师范大学”、“职业 阿里巴巴集团董事局主席”等与主题相关的信息。
2. 页面分类(Category): 页面分类中列出了条目所属的类别,以及突出条目事物特征或是主题的相关类别。一个条目可以被分类到多个类别下,需要注意的是,该分类体系并非严格的层次体系,具有一定的随意性。例如,“马云”这个条目的分类有“1964年出生”、“在世人物”、“中国企业家”、“杭州人”、“阿里巴巴集团”等。
3. 摘要(Abstract): 摘要是指某个维基百科条目文章的第一段,其内容以简明扼要的文句给出该条目的主要信息内容。摘要中的第一句,往往会有类似“……是……”或“……为……”等句式,我们把这样的句子称为显式定义句,也会有不出现“是”或“为”的隐式定义句。定义句中的中心词,很有可能反映出条目所属的类别。例如,“马云”这个条目的定义句为“马云(英文名: Jack Ma,1964年9月10日-)中华人民共和国企业家”,其中心词为“企业家”,可以推断出,该条目的类别是人物。
4 基于SVM的实体分类
与传统机器学习的分类方法类似,本文将人工标注类别的维基百科条目分为训练集和测试集,从中提取各种特征,利用词包模型,构造相应的特征向量,然后使用SVM分类器从训练集的特征向量中学习得到分类模型,最后将该分类模型应用到测试集的特征向量上,预测条目的实体类别,并计算分类方法的性能。基于机器学习方法的关键在于找出有效的特征来表示维基百科中的条目,本文除了使用维基百科页面中获取的基本特征之外,还使用了一些扩展特征和语义特征来帮助提高中文维基百科的实体分类性能,详见表1。
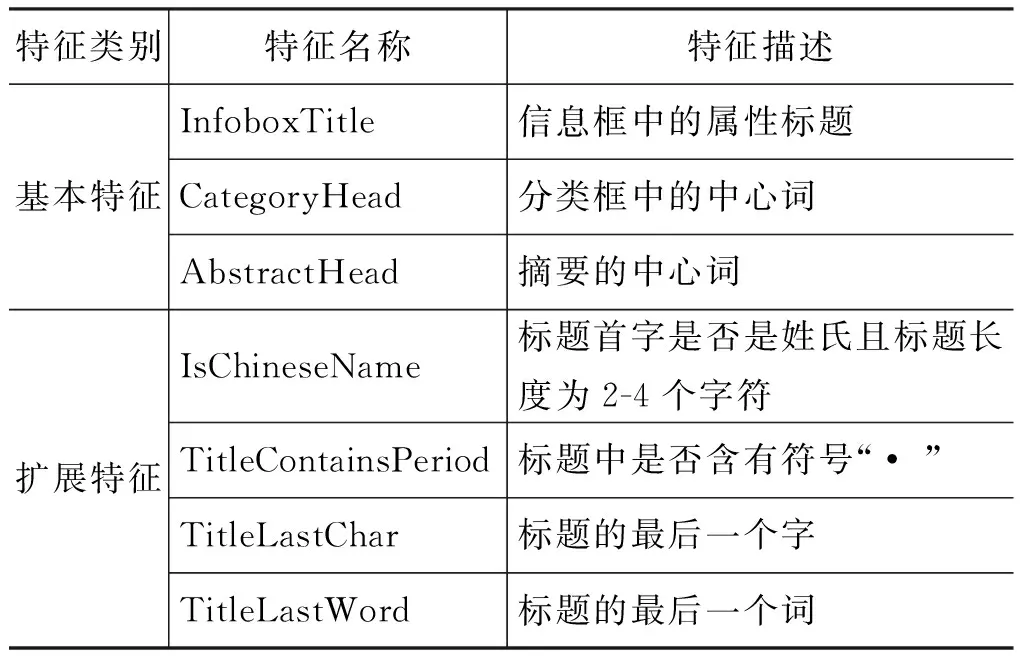
表1 维基百科中的实体分类特征
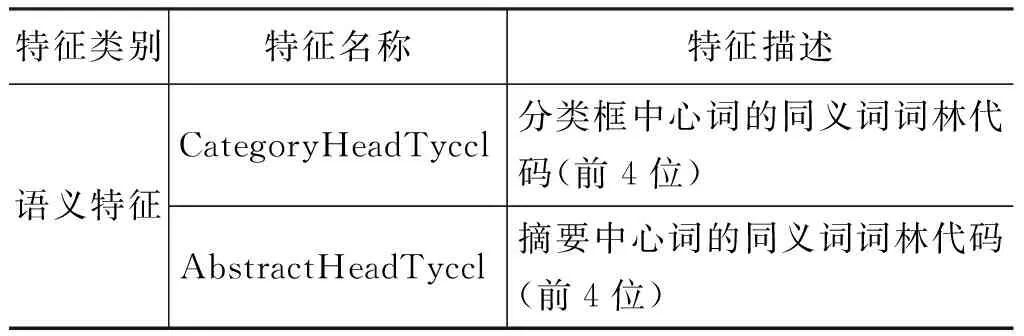
续表
4.1 基本特征
本文使用了以下三个类别的基本特征,即信息框、分类框和摘要中的相关内容,具体如下。
1. InfoboxTitle: 信息框中的内容对于实体类型具有很好的识别作用。信息框中的信息形式为“标签 数据”,我们提取其中的标签的内容作为一个特征,而不提取数据本身。例如,对于“国籍 中华人民共和国”,取“国籍”作为特征,因为不同的人物,对应的国籍是不同的,而“国籍”这个标签是共同拥有的。例如,对于“马云”这个条目,从其信息框中提取到的特征词为分别为“出生”、“国籍”、“母校”、“职业”、“净资产”、“配偶”和“子女”,这些特征词基本都是人物的相关信息。
2. CategoryHead: 分类框中的信息对实体分类同样具有明显的识别作用。对于每一个类别,通过分词处理后,取其中心词(即最右边一个词)作为特征。例如,“1964年出生”,通过分词取得中心词“出生”作为一个特征。因此,“马云”这个条目的分类框中得到的特征词分别为“出生”、“人物”、“企业家”、“亿万富豪”、“领袖”、“校友”、“教师”、“人”、“姓”、“人士”、“博士”和“集团”等。
3. AbstractHead: 除了上述半结构化信息外,在维基百科的文章中的第一段(即该条目的摘要)也可起到一定的补充作用。对于摘要的处理,我们取其第一句,通过分词和词性标注,找出第一句的中心词(最右边的名词)作为特征。特别地,当第一句的句式结构为“……是……”或“……为……”时,更能通过正则匹配轻松获得该句中心词。例如,从“马云”这个条目的摘要中提取到的特征为“企业家”。
4.2 扩展特征
为了更好地对某些类别(特别是人名、地名、组织名等)的实体进行识别,我们加入了下面有关条目标题的扩展特征。前两个特征是用来帮助提高人物类别的分类性能,而后两个特征对所有实体类别均有效。
1. IsChineseName: 加入了中文百家姓姓氏列表,将条目名的第一个或前两个字是否属于姓氏并且条目标题长度在2到4个字符为一个二元特征。
2. TitleContainsPeriod: 标题是否含有分隔符号。维基百科的外国人名的条目,标题中会使用 “• ”分隔外文姓氏和名字,因此将标题中是否含有分隔符作为一个二元特征。
以上两个特征的加入,用来帮助提高Person类别的分类性能。
3. TitleLastChar: 考虑到某些命名实体在名称上的特殊性,例如,地名中“XX省”、“XX市”、“XX县”,机构名中“XX局”、“XX部”,最后一个字有极高的规律性。因此通过加入条目标题的最后一个字和词作为两个特征,来帮助提高ORG、GPE等实体类别的分类性能。
4. TitleLastWord: 某些实体名如“XX协会”、“XX大学”,“XX山脉”等,最后一个词具有很强的规律性,因此通过加入标题的最后一个词作为特征,来帮助这类实体的分类。
4.3 语义特征
由于维基百科由网民以共享合作方式撰写,因此对于同一个或者类似的含义,可能会用不同的词进行表达,例如,“警察”、“警务人员”、“警官”都表达类似的含义,都指向人物这个类别,导致了特征词稀疏问题。因此,有必要在基本特征中对表达类似概念的词汇进行泛化,方法是引入了同义词词林,将特征词汇的语义代码作为一个特征加入到系统中。
《同义词词林》[11]是一部汉语分类词典,其中每一条词语都用一个编码来表示其语义类别。本文所用的《词林》为《词林(扩展版)》,是哈工大信息检索研究室在《同义词词林》的基础上研制的。最终的词表包含77 492条词语,共分为12个大类,94个中类,1 428个小类,小类下再以同义原则划分词群,最细的级别为原子词群。不同级别的分类结果可以为自然语言处理提供不同颗粒度的语义类别信息,本文选取词林语义代码的第二级和第三级(即语义代码的前2和前4位)进行实验。
5 实验
5.1 数据来源
实验中所使用的维基百科数据来自于维基百科网站上下载的2014年8月4日中文离线数据包。首先需要将原有数据包文件中的XML标记去除,保留所需要的文本内容。由于维基百科的内容中混合了繁体和简体中文,为了便于后期处理,需要将所有中文统一转化为简体,最后从中提取出每个条目的标题、信息框、分类框和摘要等相关信息。其中,对摘要的首句使用进行分词和词性标注。
我们从所有条目中随机取出8 000个条目作为实验数据,通过规则匹配去除消歧页面和列表页面后,剩下7 612个条目,然后根据ACE的中文命名实体的分类体系对条目进行类别的标注。
实验所使用的实体分类体系,是在ACE定义的中文命名实体分类基础上,结合Sekine的扩展命名实体分类体系[12],考虑到实际信息抽取的需要进行设置的。其中,PER、ORG、GPE、LOC和FAC等为ACE定义的五大类实体,其余九类为扩展类别。如非特别指出,下列实验中的实体分类是指五类ACE实体,其余都为非实体;而扩展实体分类时,14类为实体类别,其余为非实体。
5.2 实验设置
所有实验都按照五折交叉验证方式进行,即实验数据被随机分成大小相同的五份,训练集和测试集的比例为4∶1,使用的分类工具为LibSVM,且SVM的训练参数均采用默认值。实体分类结果分别使用准确率(P)、召回率(R)和调和平均值(F1)进行评估,最后取五次实验的平均值作为最终结果。
5.3 实验结果
5.3.1 各个特征对分类性能的影响
为了考察各个特征对分类性能的影响,本文分别进行了加入和分离实验,前者以信息框和分类框特征为基准系统,然后单独加入每个特征,比较它和基准系统之间的性能差异;而后者是以所有特征为基准系统,然后分离出单个特征,比较它和基准系统之间的性能差异。实验结果如表2所示,其中性能差异用P/R/F1的变化值来表示,每一列中性能变化的最大值用粗体表示,加入实验的正值表示该特征是有益的,而分离实验的负值表示该特征是有效的。为便于参考,表格的第1行列出了两个基准系统的P/R/F1性能。
从表2可以看出,各个特征加入实验时的性能贡献比分离实验时的性能贡献要大得多,这是由于特征之间往往存在着冗余性, 单独使用时性能提升很明显,而同时使用则效果不显著,此外:
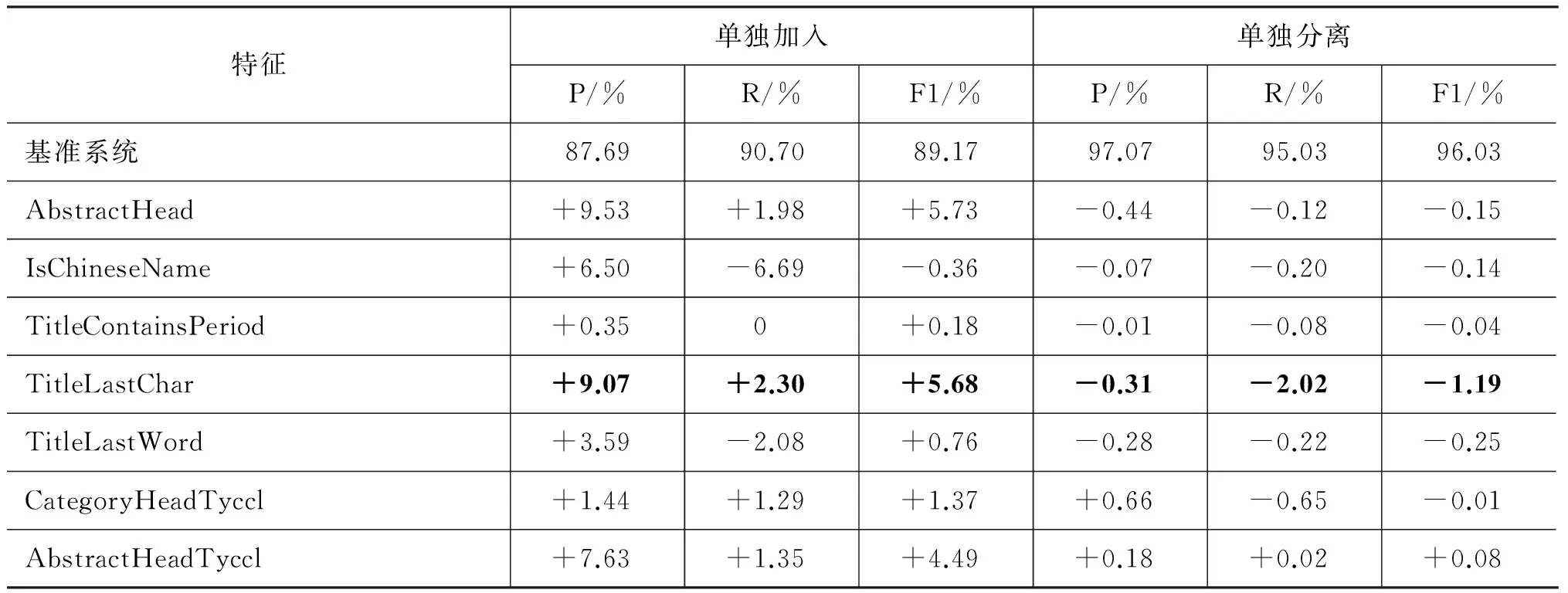
表2 加入和分离实验中不同特征的性能影响
1. 贡献最大的特征是TitleLastChar,无论是加入还是分离,都对准确率和召回率有明显的影响,这主要是由于条目标题的最后一个字对不同类别具有很高的区分性,特别是对于GPE类,如“XX省”,“XX市”等,标题最后一个字具有很强的区分性。同样TitleLastWord特征的贡献也很稳定,虽然没有TitleLastChar特征那么大;
2. 特征AbstractHead在加入实验中的作用很明显,但在分离实验中的变化要小得多,这可能是由于该特征本身很有用,但它和其他特征之间具有一定的冗余性;
3. 两个人名特征的效果并未达到预期值。特征IsChineseName的加入提高了准确率,但同时召回率也明显降低。这是由于不少GPE条目的首字母也是中文姓氏,与部分人名产生混淆。不过,虽然它在加入实验时降低总体性能,但在分离实验时却表现出对总体性能略有帮助。同样,特征TitleContainsPeriod对分类性能也有提高。
4. 两个语义特征的表现不一致。特征CategoryHeadTyccl的贡献比较稳定,无论是加入还是分离实验,都表现出对提高性能的有效性。而特征AbstractHeadTyccl的表现就不一致,尽管在加入实验中提高了总体性能,但在分离实验中删去该特征反而提高了总体性能,可以认为该特征过于泛化。
5.3.2 不同类别的性能比较
根据上述分离实验中各特征的性能表现,最后确定使用除AbstractHeadTyccl以外所有的其他特征,得到最好的分类性能如表3所示。
从表3可以看到,系统最终取得的分类性能还是较高的,平均F1值超过了96%。其中,性能最高的两个类别为PER和GPE,这是由于这两种类型的实例数较多且其条目的特征有较高的一致性, 因此在SVM中得以比较好的训练;而性能相对较低的三类为ORG、LOC和FAC等,F1值分别约为91%、94%和93%,且是召回率明显低于准确度,这是因为这三个类别的条目种类形态较多而样例又较少,无法得到充分的训练,另外这三个类别下,很多没召回的条目往往是Category和Abstract中能提取的特征较少或是有噪声,而标题中提取的特征词又很稀疏,最后由于没有提取到有效特征导致无法召回,例如,条目“日本邮政公社”,其摘要和Category中获取到的特征词分别为“体”和“邮政”、“事业”,而标题尾词“公社”在训练样例中又属于稀疏的词,导致其无法召回为ORG。
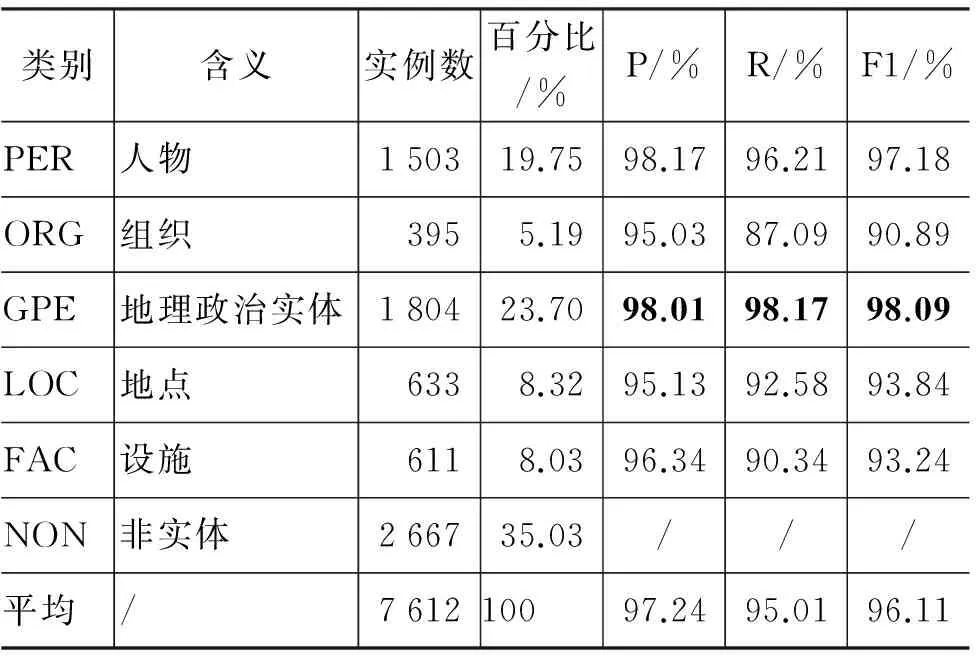
表3 不同类别的分类性能
5.3.3 扩展实体类别的分类性能
表4列出了在14个扩展实体类别上的分类性能(使用的特征集与表3相同)和每个类别的实体数量及所占比例,表中除ACE实体类别外最高的P/R/F1性能用粗体标出。
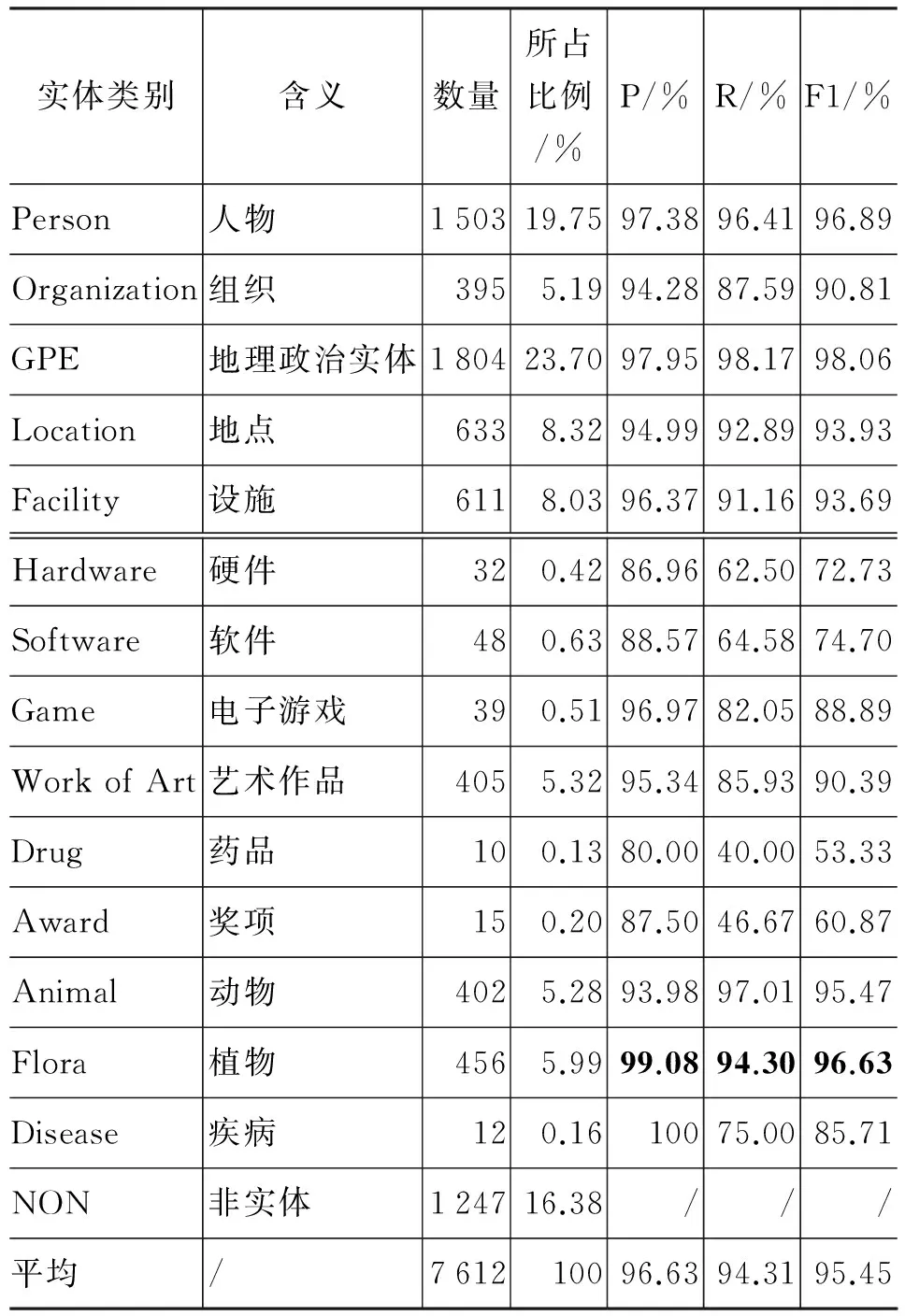
表4 扩展类别上的分类性能
从表4可以看出,扩展至14个实体类别后的P/R/F1平均值为96.63%/94.31%/95.45%,与五个实体大类的分类性能相比虽有降低,但幅度较小,这主要是由于非ACE的实体类别数量较少,占总数比例小于四分之一。对非ACE的九个实体类别,各个类别的F1值和其条目的数量,大致上呈现一个线性关系。即由于训练样例太少,从而导致特征稀疏,召回率下降,因此分类性能不尽理想,进一步分析发现:
1. Work of Art、Animal和Flora三个类别与ACE中的ORG实例数量接近,其中Work of Art的性能和ORG相当,因为Work of Art中包括了电影、音乐、书籍等多种艺术形式,因此特征较为多样化,而相比之下实例数较少,因此无法对特征进行很好的学习,导致召回率较低。Animal和Flora两类的性能相比ORG明显高,因为动物和植物的实例在特征上较为一致,都包含“属”、“种”、“动物”、“植物”等特征词,但由于这两类的特征很相似,因此错分的实例主要集中在这两类之间互相分错。
2. Game和Disease这两个类别尽管数量不多(前者不到40,后者略大于10),但F1性能都在85%以上,这是由于它们的特征虽然数量少但较为一致。例如,Game类实体中均含有“游戏”“开发商”“平台”等特征词;而Disease类的Category中都有“疾病”这个特征词。
5.3.4 与英文维基的实体分类性能比较
为了考察不同语言之间维基实体分类的难度,本文比较了中英文维基实体的分类性能。英文维基的实体分类中比较典型的是Tkatchenko等[13]的研究工作。他们总共划分了18个实体类别,本文共划分14个实体类别,两者共有的类别共有9个,因此本文选取了中英文共有且实例数量较多的类别进行比较,结果如表5所示。
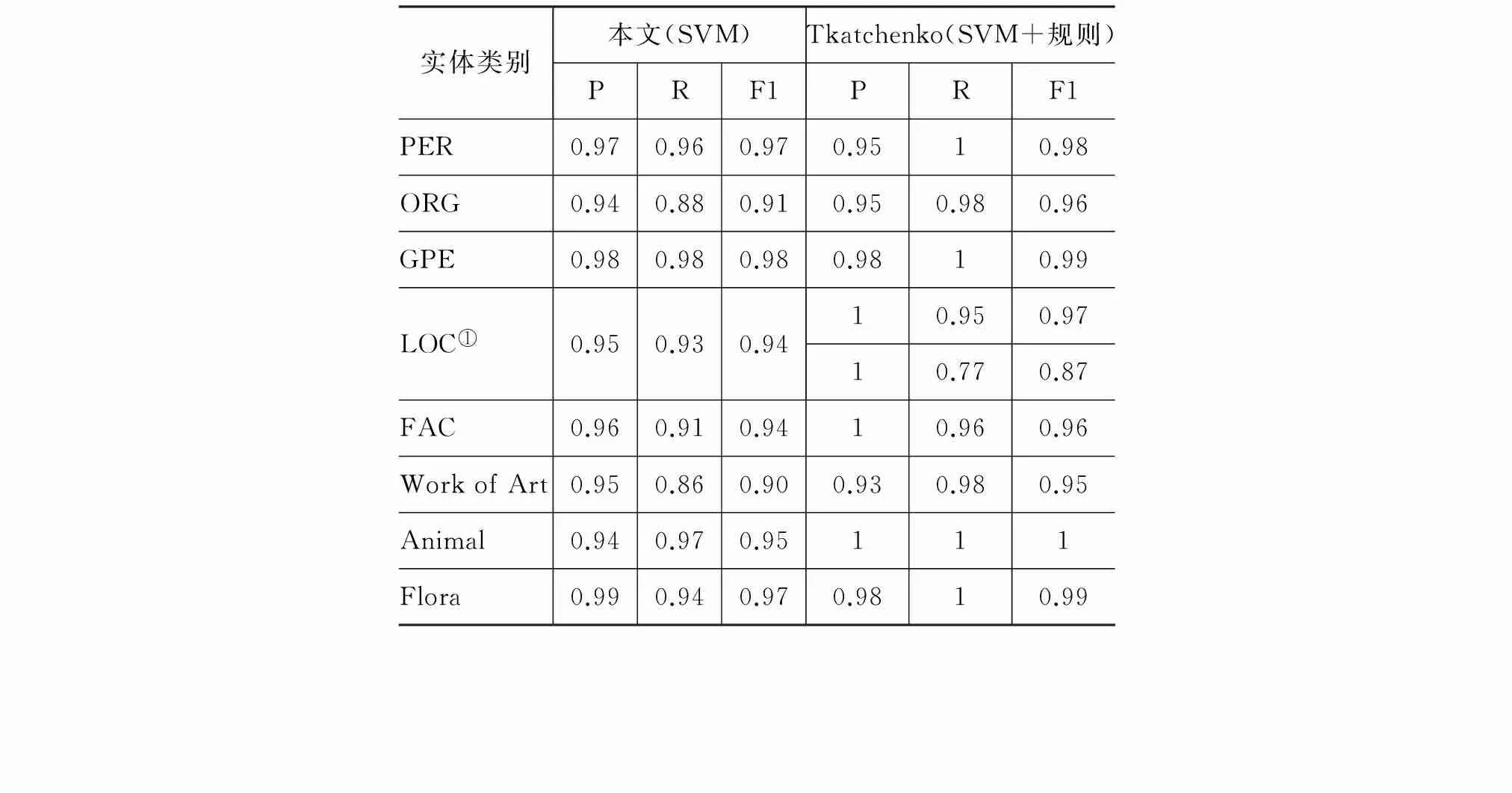
表5 中文和英文维基实体分类性能的比较
①由于本文的使用的实体分类体系和Tkatchenko论文的分类体系有所不同,Tkatchenko论文中ASTRAL_BODY和GEO_REGION两个类别为本文类别LOC的两个子类,故在对比时,将本文LOC的性能与其两类的性能作比较。
需要指出的是,两者所使用的分类体系和数据集不一样(英文中使用18个类别,5 294个条目,本文使用14个类别,7 612个条目),不过,我们还是可以看出,英文维基百科的扩展实体分类性能整体上都优于中文。在PER和GPE两个类别上,中英文的性能旗鼓相当;而在其他类别上,两者之间的分类性能还有相当差距。可能的原因是中文的PER在Category上的特征一致性较高,GPE在标题特征上一致性较高,另外这两类的训练样例数量相对较多,因此得到了比较理想的分类性能,而相比之下,中文的ORG、LOC和FAC,样例的形态较为多样,另外训练样例又较少,导致部分特征较为稀疏。
由于中文和英文在形态和语法上的区别,使得在英文中使用的很好的特征和规则,在中文上未必有效。例如,在Bunescu 和Pasca的论文中使用的首字母大写这一规则来判断某个条目是否属于实体就无法在中文中使用;在Tkatchenko的论文中,在对实体分类前,通过使用一系列规则对实体与非实体进行二元分类,精度和召回率都达到了95%。另外由于受到中文分词技术的限制,在提取Category和Abstract中心词时会出现一些错误和偏差,导致噪声的引入,影响分类性能,而在英文中,就不存在这样的分词问题。
此外,英文维基百科的发展比中文维基百科的发展更好,其在内容的正确性和完整性上都优于中文维基百科。我们观察到,未能召回的中文条目,很大一部分条目的页面内容十分少,并缺乏相应的Category和Infobox等半结构化信息,导致无法提取到这些条目的有效特征,从而无法对这一部分条目进行正确分类。
5.4 错误分析
为了进一步了解产生分类错误的原因,本文随机选取了100个错分的维基条目进行分析,发现分类错误原因主要有以下几个类别:
1. 分类框信息不规范。维基条目的分类框内容并非完全都是条目所属的严格意义上的某个类别,还包括与条目相关的类别。例如,条目“世界新闻自由日”的分类框中有“联合国教科文组织”,得到特征词“组织”,此特征导致条目被错分为ORG。这部分错误占总数的44%;
2. 标题名称的不确定性。某些类别的条目标题和其他类别的条目标题特征相似,从而产生误导。例如,条目“赫尔曼·凯斯滕奖”和“曹洞宗”被错分为PER类别,但实际上它们只是含有PER类别的某些特征。这类错误占总数的30%。
3. 类属条目和实体条目的相似性。所谓类属条目是对某一实体类别的描述,因而在特征上与实体条目相似。例如,条目“皇上”、“动作片演员”这类称谓、职业类条目易被错分为PER类别。这类错误占总数的13%;
4. 其他较为个别或者无法明确归类的错误,约占总数的13%。例如,语言中存在着一词多义现象,因此多义词作为一个统一的特征时,容易引起错误。例如,“组织”这个词,可能属于“机构”这个概念,也可能属于“生物体”的概念。
6 结论
本文利用维基百科条目中的半结构化信息作为特征,并根据中文实体的特点加入扩展特征和语义特征,从而对中文维基百科条目进行实体分类。实验表明,这些特征可以有效提高维基实体分类的性能。其中对于ACE实体类别的分类性能F1值超过96%,达到了实用价值;而对于扩展实体类别,则还需要通过标注更多的实例来提高实例数较少的类别的分类性能。
目前的方法都是基于词汇层面,还未考虑到句法和语义层面,因此今后的工作一方面可考虑挖掘句法和语义特征,以进一步提高分类性能;另一方面,可利用该分类模型对所有的维基百科条目进行实体分类,并将这些识别出的命名实体应用到自然语言处理的其他任务中。
[1] Nothman J, Curran J R, Murphy T. Transforming Wikipedia into named entity training data[C]//Proceedings of the Australian Language Technology Workshop. 2008: 124-132.
[2] Nothman J. Learning named entity recognition from Wikipedia[D]. The University of Sydney Australia 7, 2008.
[3] Bunescu R C, Pasca M. Using Encyclopedic Knowledge for Named entity Disambiguation[C]//Proceedings of the EACL. 2006, 6: 9-16.
[4] Zirn C, Nastase V, Strube M. Distinguishing between instances and classes in the wikipedia taxonomy[M]. Springer Berlin Heidelberg, 2008.
[5] Toral A, Munoz R. A proposal to automatically build and maintain gazetteers for Named Entity Recognition by using Wikipedia[J]. NEW TEXT Wikis and blogs and other dynamic text sources, 2006, 56.
[6] Bhole A, Fortuna B, Grobelnik M, et al. Extracting named entities and relating them over time based on wikipedia[J]. Informatica (Slovenia), 2007, 31(4): 463-468.
[7] Tardif S, Curran J R, Murphy T. Improved text categorisation for Wikipedia named entities[C]//Proceedings of the Australasian Language Technology Association Workshop 2009. 2009: 104.
[8] Dakka W, Cucerzan S. Augmenting Wikipedia withNamed Entity Tags[C]//Proceedings of the IJCNLP. 2008: 545-552.
[9] 谌志群, 高飞, 曾智军. 基于中文维基百科的词语相关度计算[J]. 情报学报, 2013, 31(12): 1265-1270.
[10] 张苇如, 孙乐, 韩先培. 基于维基百科和模式聚类的实体关系抽取方法[J]. 中文信息学报, 2012, 26(2): 75-81.
[11] 梅家驹. 同义詞詞林[M]. 上海: 上海辞书出版社, 1983.
[12] Sekine S, Sudo K, Nobata C. Extended Named Entity Hierarchy[C]//Proceedings of the LREC. 2002.
[13] Tkatchenko M, Ulanov A, Simanovsky A. Classifying Wikipedia entities into fine-grained classes[C]//Proceedings of the Data Engineering Workshops (ICDEW), 2011 IEEE 27th International Conference on. IEEE, 2011: 212-217.
Classifying Named Entities on Chinese Wikipedia
XU Zhihao1,2,HUI Haotian1,2,QIAN Longhua1,2,ZHU Qiaoming1,2
(1.Natural Language Processing Lab of Soochow University,Suzhou,Jiangsu 215006,China;2. School of Computer Science & Technology,Soochow University,Suzhou,Jiangsu 215006,China)
Classifying Wikipedia Entities is of great significance to NLP and machine learning. This paper presents a machine learning based method to classify the Chinese Wikipedia articles. Besides using semi-structured data and non-structured text as basic features, we also extend to use Chinese-oriented features and semantic features in order to improve the classification performance. The experimental results on a manually tagged corpus show that the additional features significantly boost the entity classification performance with the overall F1-measure as high as 96% on the ACE entity type hierarchy and 95% on the extended entity type hierarchy.
Wikipedia; named entities classification; semi-structured data; Infobox

徐志浩(1991—),通信作者,硕士研究生,主要研究领域为信息抽取。E-mail:20134227020@stu.suda.edu.cn惠浩添(1991—),硕士研究生,主要研究领域为信息抽取。E-mail:20134227019@stu.suda.edu.cn钱龙华(1966—),副教授,硕士生导师,主要研究领域为自然语言处理。E-mail:qianlonghua@suda.edu.cn
1003-0077(2015)05-0091-07
2015-07-08 定稿日期: 2015-09-08
国家自然科学基金(61373096,90920004),江苏省高校自然科学研究重大项目(11KJA520003)
TP391
A
