一种用于嵌入式软核的动态可重构容错方案
2015-03-30谭龙生梁华国
谭龙生,梁华国,王 存
(合肥工业大学 电子科学与应用物理学院,安徽 合肥 230009)
0 引言
随着集成电路技术的不断进步,器件工艺尺寸越来越小,集成度越来越高,但电路也更易受到外界环境影响,发生错误[1]。现场可编程逻辑门阵列(field-programmable gate array,FPGA)的特点决定了其易受高能粒子或者辐射的影响,产生单粒子翻转(single event upset,SEU)或软错误[2]。当FPGA受到高能粒子轰击或者辐射影响,产生SEU,往往会造成逻辑状态存储器单元或者配置位存储器的翻转,后者将使电路的结构发生改变,从而导致电路功能及结果的错误。基于FPGA的设计具有很高的灵活性,使得FPGA的应用越来越广泛,但同时上述可靠性方面的缺点使得FPGA在高可靠性要求的应用中受到限制。为此,对FPGA采取措施进行容错(一般包含错误检测、错误定位与故障修复3个部分)显得尤为必要。
FPGA所具有的动态可重构功能,简单地说,是可以在线对电路结构进行修改,这就为FPGA的容错加固提供了一种方法。只要可以正确地检测并且定位出发生错误的电路位置,即可结合动态重构功能重新配置电路,修复故障,使电路继续正常运行。
由于FPGA结构特点使其易受外界干扰发生错误,所以对其进行的容错加固通常采用变换电路结构的方法,使得所设计电路具有在线故障检测、快速故障定位以及快速故障修复等功能,在故障发生后迅速检测、定位和修复故障,以达到使电路正常运行的目的。
基于以上原因,目前在FPGA电路设计中应用最广泛的容错加固方案是硬件冗余,主要包括双模冗余(dual modular redundancy,DMR)、三模冗余(triple modular redundancy,TMR)以及多模冗余等。它主要是通过对电路做多模复制并比较输出来检测故障的发生,并通过与其他电路的配合,定位故障。但是它在容错加固的同时,也带来了较大的电路面积开销。目前对于通过FPGA动态可重构功能来实现电路容错加固的相关研究,主要集中在如何降低电路面积的开销,同时尽量减小时间开销,保障电路的连续运行。
文献[3]表述了一种基于双模冗余的容错加固方案。显而易见,双模冗余本身并不具备错误的定位功能,其故障发生后对2个电路模块都进行重配置,同时其采用的检查点方案和回滚恢复,使得整个系统的时间开销非常大。
文献[4]阐述了一种基于三模冗余的容错加固方案,并结合了前滚恢复技术。虽然在系统无故障运行时无需周期性地保存数据,在时间开销上比文献[2]要有所减少,但是该方案的硬件开销非常大。
文献[5]采用一种锁步策略来实现双模冗余,并构建了一个硬件冗余的控制核心,有效地降低了系统的硬件开销。但同时,它采用扫描的方式定位故障,系统资源占用大,并且提高了时间开销。
文献[6]采用对电路的部分关键位置进行三模冗余加固。这种方法在一定程度上减少电路的硬件开销,但是没有用三模冗余加固的电路部分如果发生故障,将无法检测故障,从而会一直伴随系统的运行,使得系统持续出错。
本文提出一种用于嵌入式系统的三模冗余容错加固方案,采用处理器之间相互控制重构的方法,能够快速检测、定位并修复故障,同时结合前滚恢复,使得故障修复后,系统能够同步在低时间开销的基础上,降低硬件开销。
1 相关工作
1.1 动态可重构
动态可重构是指电子电路系统在工作状态下动态地改变电路的结构与功能,主要通过对可编程逻辑器件重新配置来完成。动态重构按实现面积可分为全局重构与局部重构。
(1)全局重构。对FPGA器件或者系统只能进行全部的重配置,配置过程期间的中间结果要存放到额外的存储器,直到配置完成为止,配置前后的电路相互独立。
(2)局部重构。对FPGA器件或者系统的局部进行重配置,同时电路或者系统的其他部分仍能正常工作,不受影响。局部重构能大大缩短重构时间。
Xilinx FPGA提供了ICAP(Internal Configuration Access Port)原语[7],系统可以通过ICAP加载比特流文件来完成电路的局部重配置,也可以手动更新对应的比特流文件完成局部重配置。
FPGA的动态可重构功能,使得基于FPGA的开发设计具有更高的灵活性,它能够通过重构屏蔽当前功能无关电路降低功耗,通过重构,在同一区域实现两个相独立的电路功能模块降低面积开销,还可以修复故障电路。
FPGA动态可重构的电路在设计时,通常把电路划分为2部分,即静态逻辑和动态可重构模块。一般将需要做动态重配置的电路部分作为动态模块,其他的电路部分作为静态逻辑。在工具软件PlanAhead(针对Xilinx公司的FPGA器件)中,将静态逻辑和动态模块网表结合到一起,并划分动态模块的物理实现约束区域。
1.2 硬件冗余
在电路设计中,硬件冗余是最广泛采用的用来减轻软错误影响的容错技术。
按冗余模块的数量划分,硬件冗余可分为双模冗余、三模冗余以及多模冗余。
双模冗余即对原始电路进行复制,形成2个相同的电路模块,它们拥有相同输入,最终输出由原始模块产生,被复制的模块用来与原始模块作比较,以检测电路是否出错。显然,双模冗余只能检测错误,而不能定位错误。
三模冗余则是将原电路复制2次,形成3个相同电路模块,它们具有相同输入,输出接入多数表决器,不但能检测错误,还能够定位错误模块。但同时,它会带来至少额外200%的面积开销。
电路复制次数大于2次的,均可称为多模冗余。多模冗余的硬件面积开销会非常大,除非设计特殊要求,否则使用较少。
按冗余的电路范围划分,硬件冗余还可分为全局冗余和部分冗余。全局冗余是指对电路的整体进行冗余,而部分冗余则是对电路的关键部位进行冗余处理,其他部分则不进行冗余。两相比较,部分冗余要比全局冗余节省硬件面积开销。但同时,一旦有错误发生在未冗余加固的电路时,错误将无法被检测定位,这会使得故障一直持续下去。因此,部分冗余的电路可靠性要低于全局冗余。在本文的设计中,将对电路采取全局冗余的方法。
1.3 配置位翻转
SEU发生在配置存储器,会对FPGA设计实现的电路功能产生影响,但并不一定会造成电路故障。FPGA的配置位,根据翻转后对电路的影响可以分为敏感位与非敏感位。
对于敏感位,当SEU发生时会使电路产生错误。而对于非敏感位,当SEU发生时不会造成电路的错误。根据NASA给出的统计数据,电路设计中敏感位大约占FPGA配置位的10%。
对于三模冗余电路,3个同模电路模块的敏感位同时发生SEU的概率是非常低的,在本文的讨论中将暂不考虑。
1.4 恢复策略
对于带有存储器的电路,故障发生后的故障信息可能被后续的存储器存储。如果仅仅对故障电路做重配置,并不能完全消除错误。因此,需要配合数据恢复来保证电路重配置之后恢复正常状态。
目前常用的恢复策略主要有回滚恢复和前滚恢复[8-9]。回滚恢复的原理基于时间冗余,需要定期对数据进行存储,当故障移除后,将最近一次保存点的数据重载到电路中。可以看出,回滚虽然能有效恢复原有状态,但是由于定期存储数据(此时电路需要暂停),带来了很高的时间开销。
前滚恢复则不需要定期存储数据,当错误被修复后,将从未发生错误的模块复制其数据,装载到发生错误的模块中。这需要电路提供检测区分错误与正常模块的功能支持。可以看出,前滚恢复的时间开销明显缩小。
2 新的容错加固方案
图1所示为本文容错加固方案的基本结构,主要由三模冗余的MicroBlaze软核处理器[10]、状态编码器、多路控制器、多路选择器以及数据恢复模块等组成。本文的开发试验平台为Virtex 5 XC5VLX110T[11]。
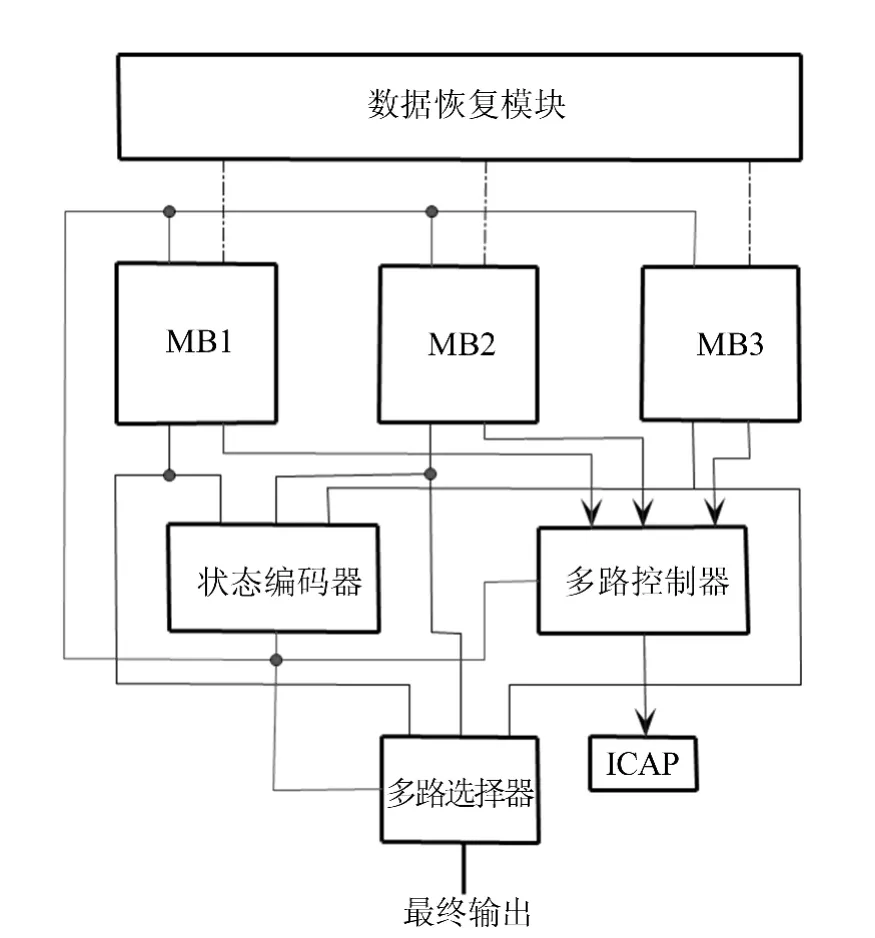
图1 方案基础框架图
2.1 三模冗余的处理器
这一部分由三模冗余的MicroBlaze软核处理器构成,每个软核中的C程序代码均由正常工作时的C程序代码以及故障发生后的重配置控制C程序代码组成。其中,3个软核正常工作时的程序代码均相同,仅在重配置控制C程序代码上略有区别。
对于一般的MicroBlaze软核嵌入式系统,主要包含PLB总线、MicroBlaze软核,程序存储器以及用户定制的外设。本文中3个三模冗余的模块都是由1个MicroBlaze软核及其附属外设构成的。
这3个三模冗余的MicroBlaze软核处理器同步运行,当接收到由状态编码器提供的错误状态编码之后,每个处理器根据错误状态编码会有不同的动作执行。
当状态编码器提供的编码指示MB1出现错误时,MB2将转入对MB1的重配置控制状态,通过ICAP读取对应的比特流文件加载,对MB1进行重配置。与此同时,未发生故障处于正常状态的MB3将继续运行。当MB1的重配置完成时,将以MB3内部当前数据为基准,对MB1和MB2处理器进行恢复操作。
同理,当状态编码器提供的编码指示MB2出现错误时,MB3将转入对MB2的重配置控制状态,MB1继续运行,并以 MB1内部数据作为对MB2和MB3恢复操作的基准;当状态编码器提供的编码指示MB3出现错误时,MB1将转入对MB3的重配置控制状态,MB2继续运行,并以MB2内部数据作为对MB1和MB3恢复操作的基准。
由上述可知,每个MicroBlaze软核在控制重配置的仅针对1个固定的软核,同时它所读取加载的比特流文件也就是固定的。
2.2状态编码器
状态编码器的作用主要是对3个MicroBlaze软核模块的输出做比较之后,生成一个状态编码,并将此状态编码通过GPIO(General Purpose Input/Output)反馈给3个 MicroBlaze软核模块,同时这个状态编码也作为多路选择器和多路控制器的关键输入信息。

表1 状态编码器的基本编码结果
表1所列为状态编码器的基本编码结果,MicroBlaze软核是一种32位的软核处理器,它的输入输出均为32位,表1中X和O表示3个输出的差异与否,并不代表实际输出。
可以看出,编码器会根据发生故障模块的不同生成对应的2位二进制编码。这样编码器就为MicroBlaze软核提供了错误状态编码,标识了发生错误的模块。
在本文中,2个模块同时发生错误的概率非常低,而且三模冗余的机制无法处理3个模块中2个出现错误的情况,所以未考虑。
2.3 多路选择器
多路选择器的主要作用是根据状态编码器的错误状态编码,选择正确的输出作为整个系统的最后输出。
如前所述,MicroBlaze软核相互控制重构的机制使系统除了在进行数据恢复操作时,3个MicroBlaze软核均处于暂停状态,其他时刻至少有1个MicroBlaze软核处于正常工作状态。因此,多路选择器根据错误状态编码,选择在重配置阶段仍处于正常输出状态的模块结果作为最终输出。当错误状态编码处于无错状态(即00)时,多路选择器将保持当前选中模块输出不变。
2.4 多路控制器
由于在Virtex 5FPGA中,仅有2个ICAP资源,而本文中的3个MicroBlaze软核模块在不同的状态编码下,分别控制重配置的进行,显然ICAP资源是不足的。因此,这里设置了多路控制器,它将用来参与调度当前ICAP由某个MicroBlaze软核模块链接驱动。
多路控制器一方面和3个MicroBlaze软核模块相链接,另一方面引入状态编码器的错误状态编码作为选择依据,将相对应的MicroBlaze软核模块连接至ICAP,使其能够通过ICAP读取加载对应的比特流文件,完成对错误模块的重配置。
2.5 数据恢复
为了消除被存储器锁存的错误数据,需要对错误模块进行数据恢复,同时也是为了确保3个MicroBlaze软核模块能够继续同步向下运行。鉴于回滚恢复和前滚恢复的特点,本文采用前滚恢复作为数据恢复策略。数据恢复模块内部包含BRAM,同时3个MicroBlaze软核模块分别通过一条数据总线和数据恢复模块相连。
假设故障发生在MB1,数据恢复的流程时序如图2所示。

图2 数据恢复流程时序图
当重配置完成后,MB2会向数据恢复模块发送信号,数据恢复模块接收信号后,将送出中断信号,使3个MicroBlaze软核模块进入数据恢复阶段。首先,MB3将会把其内部的数据通过数据总线发送到数据恢复模块中,并存储在BRAM中。发送完成后,向数据恢复模块发送完成信号。然后MB1和MB2将从数据恢复模块中读取数据并取代本身原有数据。在完成数据恢复操作后,向数据恢复模块发送恢复完成信号。在数据恢复模块确认数据恢复完成之后,撤销中断信号,3个MicroBlaze软核模块恢复正常的同步运行状态,直到下次错误发生。
2.6 其他相关细节
本设计的实现采用了EAPR(Early Access Partial Reconfiguration)的设计方法,它来源于基于模块的重构设计方法。但是与基于模块重构设计方法相比,EAPR的设计方法在划分区域时不必是整列,可随意划分。同时,它不需要总线宏作为各个模块之间的通信通道,这使得设计具有更高的灵活性。
本文中3个MicroBlaze软核模块均为动态可重构模块,余下的状态编码器、多路控制器、多路选择器以及数据恢复模块均属于静态逻辑。
本文所提出的容错机制,一旦有敏感位发生翻转造成错误,错误能够立刻被检测定位,并通过重配置进行修复。而对于非敏感位错误,由于其并不会造成电路的输出发生错误,本文所提出的容错机制无法对其检测定位。当非敏感位错误积累到一定程度时,也会造成电路发生错误,这种错误是可以被检测定位并通过重配置修复的。如果对于非敏感位错误采取扫描的方式检测并进行修复,除了会使系统复杂化之外,也会造成时间开销的显著提高。因此,本文采取忽略非敏感位错误,当其积累产生敏感错误时再予以处理的方案。
2.7 系统工作流程
整个系统工作的流程时序如图3所示。
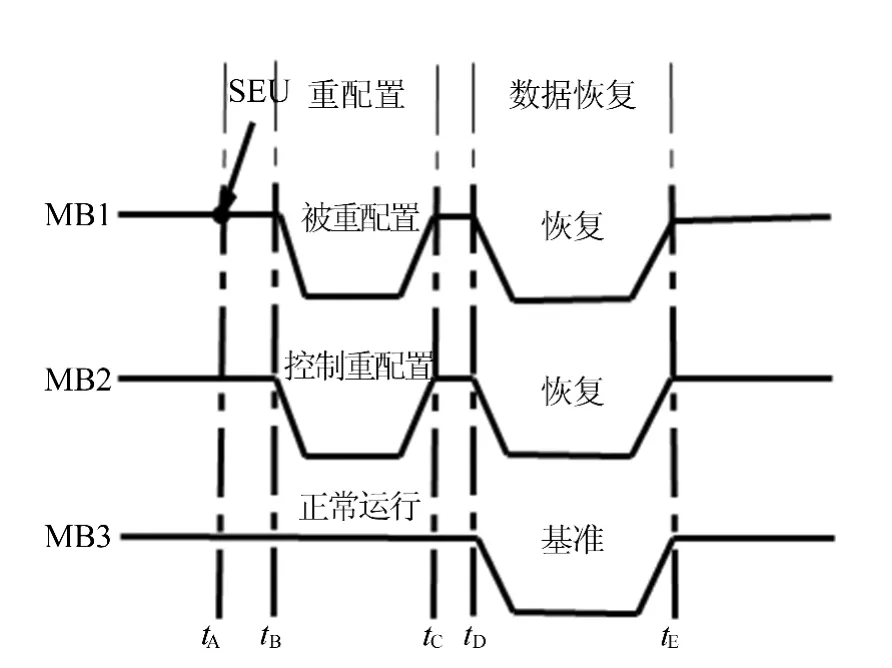
图3 系统工作的流程时序
在时间tA之前,3个MicroBlaze软核模块均处于正常工作状态。在tA时间,MB1模块中发生SEU,导致电路出错。
在时间tA和时间tB之间,是一段非常短暂的时间。这期间,状态编码器会成功将错误编码发送给3个MicroBlaze软核模块、多路控制器以及多路选择器。多路控制器收到错误状态编码,会将ICAP连接到将要控制ICAP进行重配置的MicroBlaze软核(这里为 MB2),同时,多路选择器会根据错误状态编码,将电路的最终输出切换到tB时间之后仍保持正常运行的MicroBlaze软核模块(这里为MB3)上,并在之后保持选中此模块的输出。
在时间tB至时间tC之间,MB2转入重配置的控制状态,通过ICAP对 MB1模块进行重配置,与此同时,MB3仍处于正常运行阶段,多路选择器也会保持选中 MB3,为整个电路提供正常输出。
在时间tC时,重配置完成,MB2向数据恢复模块发送标识信号,数据恢复模块接收信号后,会向3个MicroBlaze软核模块发送中断信号。
在时间tD,3个MicroBlaze软核模块接收中断信号,转入数据恢复操作,数据恢复阶段开始。
在时间tE,数据恢复完成,这时MB1和MB2中数据将与时间tD时的MB3中数据保持一致。时间tE之后,整个电路恢复同步的正常运行,直到下一次错误发生,将会再一次进行上述步骤。
在整个流程中,时间tB与时间tD之间只有1个处理器处于正常运行,也有可能另外一个错误发生在这个处理器上。但是这段时间非常短暂,仅有4ms,4ms内连续发生2次SEU并都导致敏感位错误的概率非常低。根据资料,在实验室环境、95%置信区间的条件下,Virtex 5FPGA的故障率大概为151fit/Mb,4s内连续2个处理器发生1次配置为翻转的概率为2×10-17,如果再计算均是敏感位错误的概率,将为2×10-19,几乎是不可能事件。
3 结果分析与对比
3.1 时间开销分析对比
文献[3-4]由于采取容错机制的原因,时间开销很高,这里就不做详细比较,主要与文献[5]进行对比结果见表2所列。
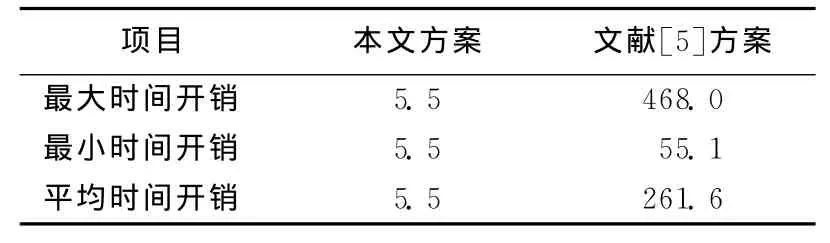
表2 时间开销对比 μs
本文中系统方案中的时间开销主要来源于数据恢复过程的时间开销,时间开销固定。数据恢复过程中,数据存储与数据恢复大约需要648个时钟周期,耗时4.8μs,加上系统控制过程的时间开销,处理1次错误所需时间开销大约为5.5μs。
文献[5]中,由于发生错误后,需要对双模的MicroBlaze软核模块进行扫描来定位故障位置,扫描期间2个MicroBlaze软核均处于暂停状态。从tA起始位置开始扫描,直到扫描到故障发生位置为止,最长扫描时间为扫描一个MicroBlaze软核用时,为413.6μs。由于故障发生位置不同,其时间开销不同,取其平均时间开销,为261.6μs(其中包含了数据恢复的用时5.2μs)。
3.2 面积开销分析对比
本文与其他方案的硬件面积开销对比见表3所列。首先,对于传统的三模冗余方案,例如文献[4],要完成 MicroBlaze软核模块三模冗余的同时,还需要加入另外一个嵌入式软核作为控制核心,加上电路的静态逻辑以及数据恢复部分,面积开销高达2 374slice(slice为FPGA物理区域划分的最小单位)。文献[5]提供的方案面积开销为1 664slice,但是以提高系统资源占用和时间开销为代价。

表3 面积开销对比 slice
本文中总面积开销和各个模块面积开销见表4所列。表4中所给出的MicroBlaze软核模块面积开销已经包含了动态可重构的额外开销(即划分动态模块区域时,区域包含区域面积要比实现面积大,以保证重配置的执行,也称为动态设计余量)。
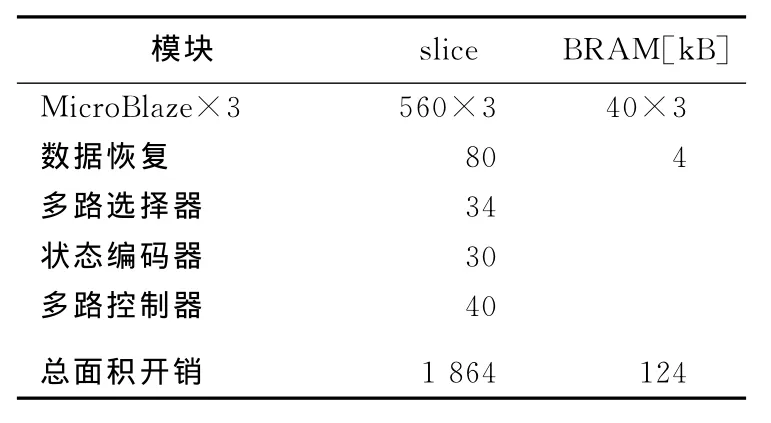
表4 面积开销
可以看出,虽然和文献[5]的方案相比,本文方案的面积开销有所提高,但与常规的三模方案相比,面积开销明显降低。
4 结束语
本文提出了一种用于嵌入式系统的容错重构方法,以三模冗余为基础,运用嵌入式软核的互相调度重构,能够快速检测错误、定位故障并修复电路,并且结合了前滚恢复,使故障修复后,系统能够同步地继续运行。本文的方案使系统时间开销极大缩小并保持系统工作较高连续性的同时,又在一定程度上降低了硬件的面积开销。
[1]黄正峰,刘彦斌,易茂祥,等.一种基于功能复用的容错扫描链电路结构[J].合肥工业大学学报:自然科学版,2012,35(1):53-56.
[2]Morgan K.SEU-induced persistent error propagation in FPGAs[J].IEEE Trans Nucl Sci,2005,52(6):2438-2445.
[3]Abateet F.New techniques for improving the performance of the lockstep architecture for SEEs mitigation in FPGA embedded processors[J].IEEE Trans Nucl Sci,2009,56(4):1992-2000.
[4]Ichinomiya Y.Improving the robustness of a softcore processor against SEUs by using TMR and partial reconfiguration[C]//IEEE Annu Int Symp on Field Programmable Custom Computing Machines,2010:47-54.
[5]Pham H M,Pillement S,Piestrak S J.Low-overhead faulttolerance technique for a dynamically reconfigurable softcore processor[J].IEEE Transactions on Computers,2012,62(6):1179-1192.
[6]Liu S F.Increasing reliability of FPGA-based adaptive equalizers in the presence of single event upsets[J].IEEE Trans Nucl Sci,2011,58(3):1072-1077.
[7]Xilinx Inc.Virtex-5FPGA user-guide(UG190)[EB/OL].(2012-10-26)[2014-06-15].http://www.xilinx.com/support/documentation/userguides/ug190.pdf.
[8]Pradhan D K,Vaidya N H.Roll-forward and rollback recovery:performance-reliability trade-off[J].IEEE Transactions on Computers,1997,46:372-378.
[9]Pradhan D K,Vaidya N H.Roll-forward checkpointing scheme:a novel fault-tolerant architecture[J].IEEE Transactions on Computers,1994,43(10):1163-1174.
[10]Xilinx Inc. MicroBlaze processor reference guide(UG081v10.3) [EB/OL].(2013-04-06)[2014-06-26].http://www.xilinx.com/support/documentation/userguides/ug081.pdf.
[11]Xilinx Inc.Virtex-5FPGA configuration user guide(UG191v3.6)[EB/OL].(2013-01-24)[2014-06-30].http://www.xilinx.com/support/documentation/userguides/ug191.pdf.
