基于K-Means和Apriori算法的多层特征提取方法
2015-03-21钱慎一朱艳玲朱颢东
钱慎一, 朱艳玲, 朱颢东
(郑州轻工业学院 计算机与通信工程学院, 郑州 450002)
基于K-Means和Apriori算法的多层特征提取方法
钱慎一, 朱艳玲, 朱颢东*
(郑州轻工业学院 计算机与通信工程学院, 郑州 450002)
根据科技文献的结构特点,论文提出了一种四层挖掘模式,并结合K-means算法和Apriori算法,构建一个新的特征词提取方法——MultiLM-FE方法.该方法首先依据科技文献的结构将其分为4个层次,然后通过K-means聚类对前3层逐层实现特征词提取,最后再使用Aprori算法找出第4层的最大频繁项集,并作为第4层的特征词集合.该方法能够解决K-means算法不能自动确定最佳聚类初始点的问题,减少了聚类过程中信息损耗,这使得该方法能够在文献语料库中更加准确地找到特征词,较之以前的方法有很大提升,尤其是在科技文献方面更为适用.实验结果表明,该方法是可行有效的.
科技文献; 特征提取;K-means算法; Apriori算法
随着文献检索能力的提高,越来越多的用户习惯于从中国知网和数字图书馆进行快速检索,获取所需文献资料.但是在知识更新不断加快的今天,新主题、新事物、新学科大量涌现,信息种类和数量激增,这使得科技文献的数量每年近似指数的速度增长.如此海量的科技文献,往往需要消耗读者大量的时间.如何对其进行高效组织,满足广大读者的需求,已经成为该领域的一个研究热点.目前,诸多检索机构已将文献资料进行分类处理,例如,在中国知网中输入检索词“绿色网络”,能够检索到74 050条数据记录,其中,在宏观经济管理与可持续发展学科领域有10 227条数据记录,在工业经济领域有8 402条记录,在建筑科学与工程领域有8 080条记录,在农业经济领域有7 217条记录,在计算机软件及计算机应用领域有2 419条记录等等.但是,目前文献的学科领域分类不够精准,导致可能漏掉一些用户所需的文献资料,这无疑是对传统检索方式的一种极大挑战.
科技文献主要以文本的形式存在,对科技文献进行分类即是对文本进行分类处理.特征选择是实现文本高效分类的前提,是文本自动分类的一个重要环节,特征选择算法的性能将直接影响分类系统的最终效果.
目前,通常采用向量空间模型来描述文本向量,但是如果直接用分词算法和词频统计方法得到的特征项来表示文本向量,那么这个向量的维度将会非常的大.这种未经处理的文本矢量不仅会给后续工作带来巨大的计算开销,导致整个处理过程的效率非常低下,而且还会损害分类、聚类算法的精确性,以致使所得到的结果很难令人满意.因此,需要对文本向量做进一步净化处理,在保证原文含义的基础之上,找出对文本特征类别最具有代表性的文本特征.目前关于特征词的基本方法主要由以下几种:互信息(Mutual Information))[1],信息增益方法(Information Gain)[2],χ-2统计量方法[3],期望交叉熵(Expected Cross Entropy)[3],文档频次方法(Document Frequency)[3].以上几种方法,在英文特征提取方面都有各自的优势,但是由于中文和英文在语言表达形式上、句法分析和语义分析等方面都有较大差异,因此,将其用于中文文本分类并没有很高的效率.
本文针对中文的科技文献进行分类,科技文献主要以文本的形式存在,由标题、摘要,关键字,正文等组成,其中最能代表文章主题的是标题和关键字,其次是摘要部分,再次是正文的引言和总结部分,最后是正文的其他部分,为了更加精准的提取特征词,本文组建四层挖掘模式,逐层对科技文献进行特征提取.因此,本文提出一种结合K-means算法和Apriori算法的多层挖掘特征提取方法—— MultiLM-FE方法,来对科技文献进行分类处理.
1 相关知识简介
1.1 K-means算法
K-means算法是一种基于样本间相似性度量的间接聚类方法,也被称为K-平均或K-均值算法.算法的主要思想是通过迭代的过程把数据集划分为不同的类别,使得评价聚类性能的准则函数达到最优.算法描述:首先要确定K值.第二,使用欧氏距离计算数据样本之间的距离.欧式距离公式如下:
(1)
式中,d(xi,xj)表示xi和xj之间的相似度,该值越小,说明样本xi和xj越相似.xi=(xi1,xi2,…,xid),其中xi1,xi2,…,xid为xi的具体取值,xj=(xj1,xj2,…,xjd),其中xj1,xj2,…,xjd为xj的具体取值.第三,对各个数据对象按照其到聚类中心距离进行聚类,最后更新聚类中心点,这个过程不断重复直到满足某个准则函数且中心的的改变小于某个特定的值才停止.
1.2 关联规则与Apriori算法
关联规则是描述数据项之间存在的潜在关系的规则,其形式化描述如下:设A=(A1,A2,…,Am)为数据项的集合,D为数据库事务的集合,其中每个事务C都是数据项的集合,即C⊆A.关联规则是形如W≥Z的蕴涵式,其中W和Z是项目集,且W⊂A,Z⊂A,W∪Z=∅.定义支持度为D中包含W∪Z的事务占全部事务的百分比,记作supprot(W⟹Z)=P(W∪Z);置信度为D中包含W∪Z的事务数与包含X的事务数的比值,记作confidence(W⟹Z)=P(W|Z).多个项组成的集合成为项集.包含k个项的项集称为k-项集.若某个项集的支持度不小于设定的最小支持度阈值min_sup.则称这个项集为频繁项集.所有的频繁k-项集组成的集合成为最大频繁项集.
Apriori算法是一种逐层迭代挖掘关联规则的频繁项集算法,其核心思想是通过候选集生成和情节的向下封闭检测两个阶段来寻找数据项之间的关联关系.首先找出频繁1-项集的集合.通过频繁1-项集来寻找频繁2-项集,…,通过k-1项集寻找K项集合,直至找到最大频繁项集合.Apriori算法使用如下性质来找到K维最大频繁项集:
性质1XK是K维频繁项集,若所有K-1维频繁项集集合Xk-1中包含XK的K-1维子项集的个数小于K,那么Xk不可能为K维最大频繁项集.
K的值每增加1就需要扫描一次数据库,为了提高频繁项集的搜索效率,Apriori算法使用下述性质用于压缩搜索空间:
性质2若k维数据项集Xk中有一k-1维子集不是频繁项集,那么X不是频繁项集.
2 基于K-means和Apriori算法的多层特征提取
科技文献一般结构规范,特征清晰,易于对其进行线性化处理,从而进行聚类分析.本文根据科技文献的结构特点提出一种4层挖掘模式,并将K-means聚类分析方法应用于该模式的前3层,将Apriori方法应用于第4层,从而实现逐层特征提取.特征提取流程如图1所示.
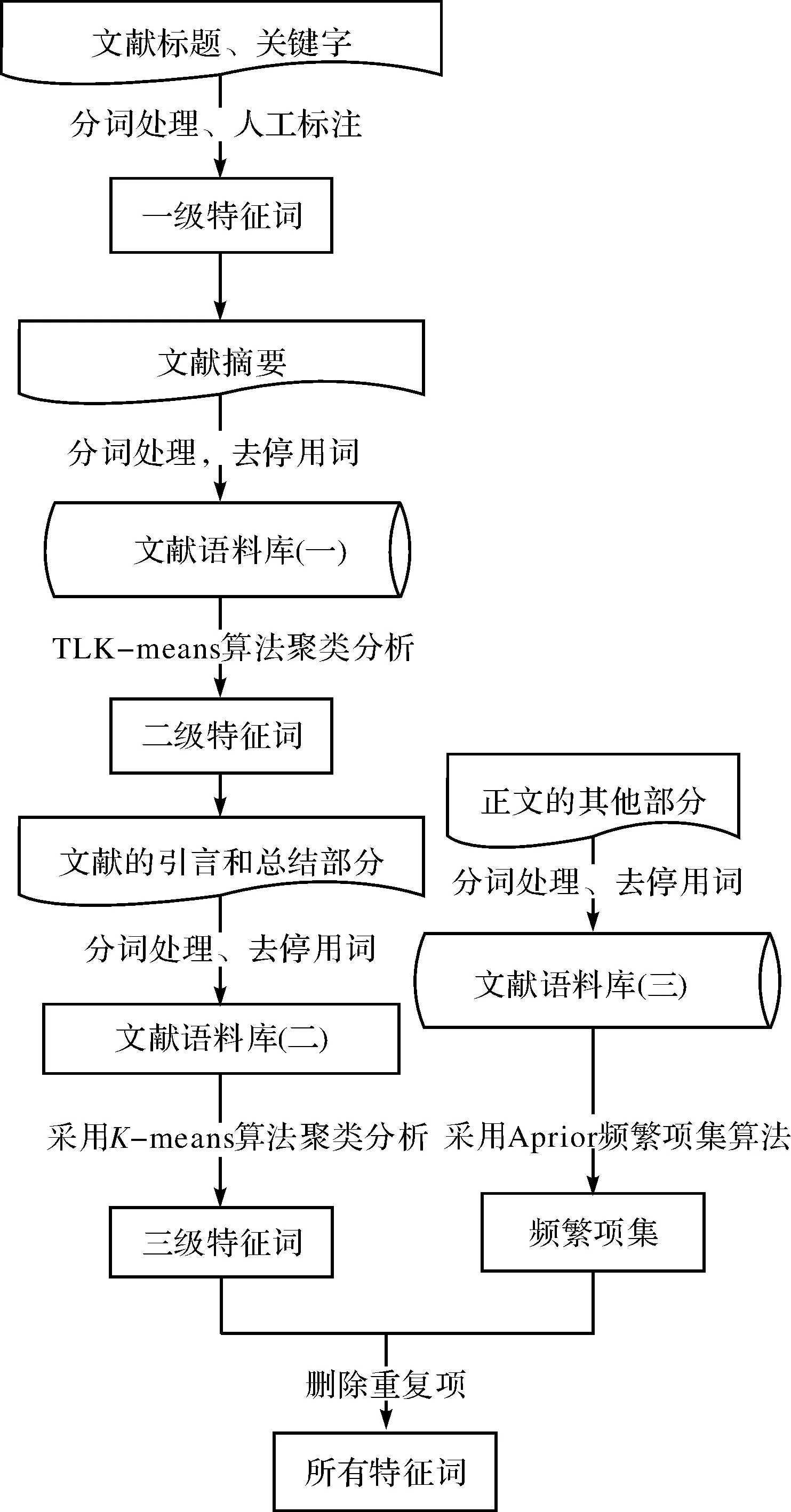
图1 科技文献特征提取流程图Fig.1 Feature extraction flow chart of scientific literatures
这种方法的基本思想是,首先将挖掘过程分为4层:标题与关键字、摘要、文献引言与总结部分、正文的其他部分.逐层定位中心点,这就使得簇的数目K不必由用户事先指定.然后将第1层的 K个一级特征词作为第2层的初始中心点,使用欧氏距离公式计算第2层数据对象之间的距离,根据其与中心点的距离分配给最近的一个簇,其次计算每个簇的平均值,并用该平均值代表相应的簇.再次根据每个对象与各个簇中心的距离,分配给最近的簇.中心点若有改变,重新计算数据对象之间的距离,并计算每个簇的平均值,这个过程不断重复直到满足某个准则函数且中心的改变小于某个特定的值才停止.最后在每个簇中选择一个或多个代表词作为二级特征词,并且指定这些二级特征词作为第3层的初始中心点.步骤相同,待算法收敛时得到三级特征词.正文部分属于四层挖掘模式中的第4层,采用Apriori算法对正文部分进频繁项集的挖掘.将提取出的频繁项集和三级特征词进行比较,消除重复词,最终得出特征词集.
2.1 科技文献标题和关键字中一级特征词的提取
对科技文献标题、关键字用汉语分词系统进行切分,经去停用词处理,得出一级特征词,作为第2层正文的引言和总结部分聚类算法的中心点.例如文献标题为:基于潜在语义分析的微博主题挖掘模型研究,关键字为:微博;短文本;主题挖掘;LDA模型;增量聚类,得到的切分效果如图2所示.

图2 汉语自动分词系统Fig.2 Chinese auto-segmentation system
2.2 科技文献摘要中二级特征词的提取
对文献的摘要部分用上文提到的汉语分词系统进行分词处理,经过去停用词处理得到得到文献语料库(一).特征提取过程如下:
Step1:依据一级特征词的个数确定K-means算法的K值;
Step2:使用欧氏距离计算数据样本之间的距离Li;
Step3:对各个数据对象按照其到聚类中心距离进行聚类;
Step4:计算每个簇的平均值,并用该平均值代表相应的簇;
Step5:根据每个对象与各个簇中心的距离,分配给最近的簇.中心点若有改变,重新计算数据对象之间的距离,这个过程不断重复直到满足某个准则函数且中心点的改变小于某个特定的;
Step6:输出结果簇.
此时只需对每个簇选择一个或多个代表词作为二级特征词,同时作为下一层聚类的初始中心点.
2.3 科技文献引言和总结中三级级特征词的提取
引言主要介绍该文献主题的应用背景,目前所取得的一些成果,所处的一个阶段及存在的不足之处,段尾是对该文献的总结和展望.提取过程同二级特征词提取的方法相似,用单词切分器对段首和段尾文本进行切分,切分出的单词经过去停用词处理后,形成文献语料库(二).
2.4 科技文献正文的其他部分获取四级特征词
用相同的方法对正文部分数据处理得到文献语料库(三),由于科技文献的正文部分数据量较大,特征词的密度相对较小.适合采用挖掘布尔关联规则频繁项集的方法进行频繁项的抽取.
Step1:扫描文献语料库(三)中主题为“数据信息,产生频繁的1-项集;
Stept2:由频繁1-项集经过两两结合生成频繁的2-项集;
Step3:通过频繁(k-1)-项集产生k-项集候选集.
如果在两个频繁的(k-1)-项集只有最后一个元素不同,其他都相同,那么这两个(k-1)-项集项集可以“连接”为一个k-项集.如果不能连接,将其舍弃;
Step4:从候选集中剔除非频繁项集.
如果候选集中某个k-项集的子项集不在频繁的(k-1)-项集中,将其删除;
Step5:扫描文献语料库(三),计算候选项集的支持度,将其与最小支持度比较,从而得到k维频繁项集.直至生成最大项集,否则转向(3);
Step6:将挖掘出的频繁项经过频率过滤和名词剪枝,得到评价对象集,作为四级特征词.
将提取出的频繁项集和三级特征词进行比较,消除重复词,最终得出特征词集.
3 仿真实验
在知网上搜集1 320篇属于计算机行业的科技文献,作为实验数据的训练集,其中80篇主题为“离散化”的文献,220篇主题为“绿色网络”的文献,360篇主题为“特征词选择”的文献,其余660篇作为测试集,测试集的文献数量训练集数量相一致.本文选择一篇题目为“文本分类中连续属性离散化方法的研究”的文献作为特征词挖掘的实验样例,进行MultiLM-FE方法中提出的四层挖掘模式的前三层的聚类分析实验.
3.1 从文献标题和关键字中获取一级特征词
文献的标题为:“文本分类中连续属性离散化方法的研究”,关键字为:机器学习;文本分类;信息增益;连续属性离散化;Boosting算法.采用中国科学院计算技术研究所的切分器切分,结果为:文本/n分类/v中/f连续/a属性/n离散/v化/v方法/n的/u研究/v机器/n学习/v;/w文本/n分类/v;/w信息/n增益/v;/w连续/a属性/n离散/v化/v Boosting/n 算法/n.经停用词处理之后得出一级特征词.如表1所示.

表1 一级特征词
3.2 从摘要中获取二级特征词
首先对摘要进行分词切分:针对/p_机器/n_学习/v_领域/n_的/u_一些/m_分类/v_算法/n_不能/v_处理/v_连续/a_属性/n_的/u问题/n ……将/d_问题/n_转换/v_成二/m_值/a_表示/v_方式/n_,/w_以/p_使得/v_这些/r_分类/v_算法/n_适用/v_于/p_连续/a_属性/n_值/v_./w,由于数据使用不同的尺度度量,在使用欧氏距离之前先进行归一化处理,属性值归一化定义为:
(2)
其中,ai是指某个对象的属性i,vi是属性i的真实值,最大属性值maxvi和最小属性值minvi是从训练集实例中获得的.选择表1中的13个一级特征词作为此步聚类的初始中心点,即K-means算法中K=13.算法收敛时得到13个结果簇,不同的结果簇会有不同的属性词,同时属性词的个数也不同.在个数较少的簇选择一个词作为此簇的代表,在个数较多的簇中可以选择2个及2个以上的代表词,目的是为了保证选出的代表词能够很好地反映出第二层即引言部分的特征属性,将这些代表词作为二级特征词.结果如表2所示.

表2 二级特征词
3.3 从文献引言和总结部分获取三级特征词
使用分词器对科技文献的引言和总结部分进行单词切分处理,然后经去除停用词处理和聚类对象的归一化处理,再用Multi-Tap-FE算法进行聚类分析,初始中心点为表3的36个二级特征词,即K-means算法中K=36,进行迭代计算,直至算法收敛,得到184个三级特征词如表3所示.

表3 三级特征词
对80篇关于“离散化”文献均采用以上的方法对其进行特征提取.其中一级特征词有948个,消除重复词后有386个(以下均为消除停用词后的数量).二级特征词有1 954个,三级特征词有7 285个.220篇关于“绿色网络”的文献的一级特征词有1 023个,二级特征词有4 563个,三级特征词有18 956个,360篇关于“特征词选择”的文献中一级特征词有1 320个,二级特征词有6 451,三级特征词有10 034个.
3.4 从文献正文中获取频繁项集获得四级特征词
本文采用C#语言,Visual Studio 2010开发环境编写程序,分别对660篇训练集的部分正文信息进行提取,将提取的信息进行分词处理和去除停用词处理,为了减少数据量剔除词频小于3的词,按主题分类存入数据库,形成评价语料库,将660篇文献当做是660个事务,用Apriori算法挖掘频繁项集,本文以80篇主题为“离散化”的科技文献作为Apriori算法的实验数据.文献语料库如表4所示,设最小支持度为40%,用Java语言实现Apriori算法,A_Algorithm类实现频繁项集和频繁关联规则的挖掘过程,A_SubsetCombination类用于计算某频繁项集的真子集.

表4 文献语料库
80篇主题为“离散化”的文献,经过Apriori算法处理,最终得到39 450维最大频繁项集52组,将52组数据全部组合得到39 608个特征词.
4 实验结果与对比
4.1 对660篇测试集进行特征词选择
实验结果如表5所示.
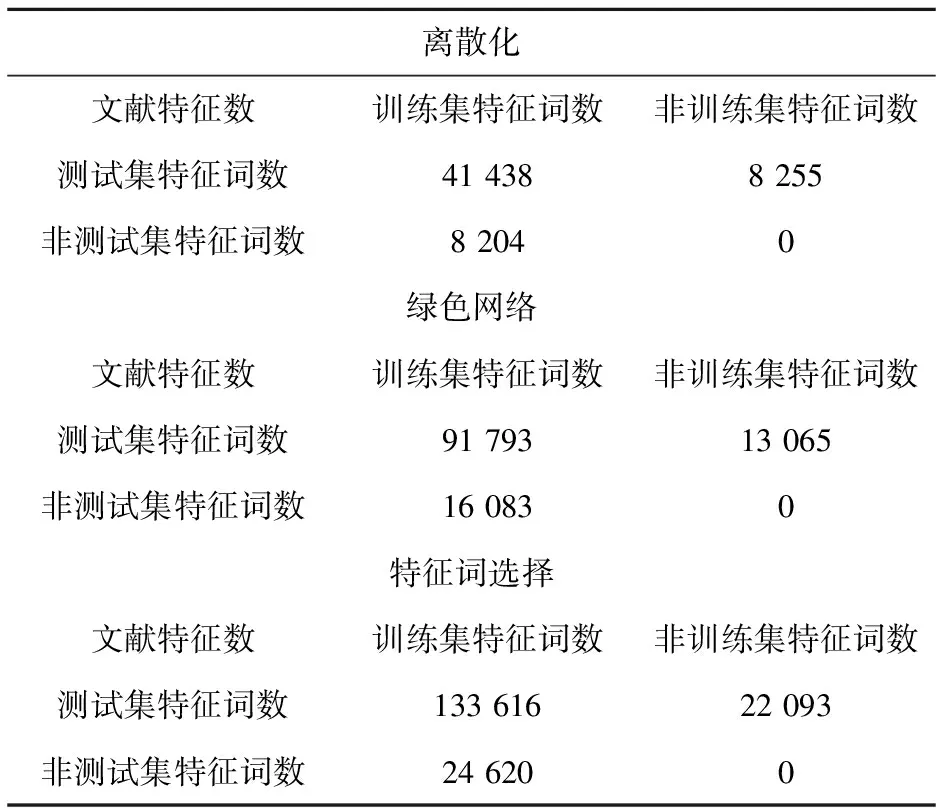
表5 本文特征词提取方法特征词提取结果
4.2 MultiLM-FE方法与IACA方法[1]比较
2012年复旦大学的刘海燕提出一种基于条件互信息的特征选择改进算法(IACA方法).该算法采用K-means 的基本思想聚类特征,并从中选出类相关度最大的特征,从而去除不相关和冗余特征.该算法比较适合处理高维数据集,能够较好地降维,并且达到不错的效果.在此,本文所提出的方法MultiLM-FE方法与之在查全率、查准率和F值3方面做比较, F-score值为:
对文献特征词挖掘结果对比,如表6所示.
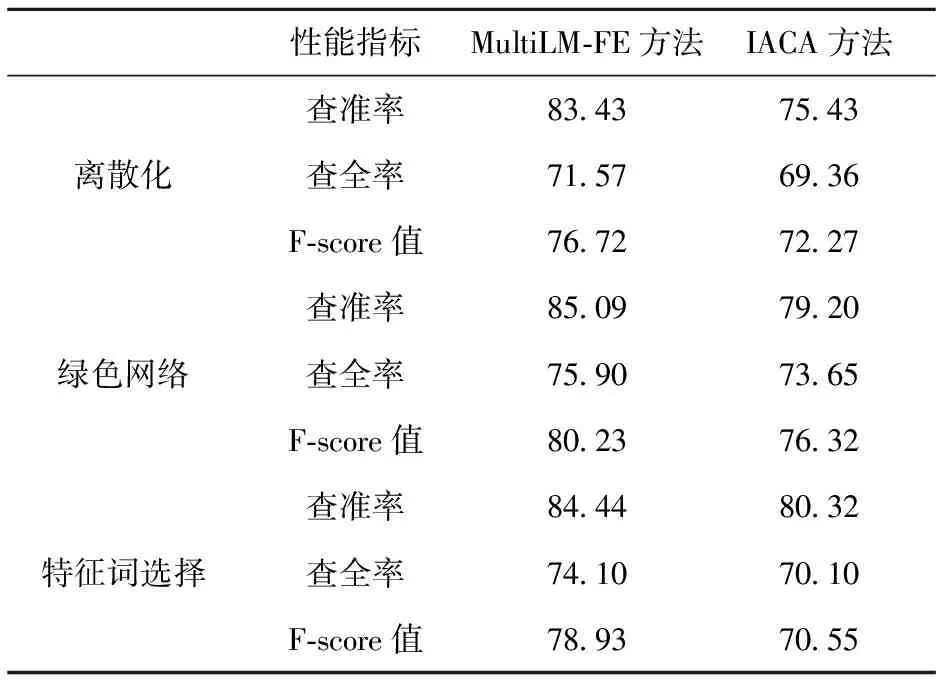
表6 各特征词提取方法实验对比结果
通过以上的比较,可以看出本文所提出MultiLM-FE方法的查全率、查准率都优于普通的K-means与Apriori方法,在特征词选择算法的研究中有一定的有效性,表明Multi-Tap-FE方法在科技文献抽取特征词方面有着较好性能.
5 结束语
本文提出的Multi-Tap-FE方法,解决了K-means聚类算法不能自动确定最佳聚类初始点的问题,减少了聚类过程中信息损耗,能够在文献语料库中更加准确的找到特征词,较之以前的方法有很大提升,但该方法也受到一定因素的影响,如k-means算法对孤立点数据很敏感,孤立点会使聚类中心偏离从而影响聚类结果;Apriori算法在每次计算项集的支持度时,都对文献语料库中的所有数据进行扫描比较,若是一个大型的文献语料库,这种扫描比较会使得计算机系统的I/O开销大大增加.而这种代价是随着文献语料库记录的增加呈现出几何级数的增加.这些都是我们今后做研究应该考虑的方向.
[1] 刘海燕, 王 超, 牛军钰. 基于条件互信息的特征选择改进算法[J]. 计算机工程, 2012, 14(38): 36-42.
[2] 毛国君, 段丽娟, 王 实,等. 数据挖掘原理与算法[M].北京:清华大学出版社, 2007.
[3] 刘海峰, 苏 展, 刘守生. 一种基于词频信息的改进CHI文本特征选择[J]. 计算机工程与应用, 2013, 49(22): 110-114.
[4] Yang C C, Tobun D N. Analyzing and visualizing Web opinion development and social interactions with density-based clustering[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part A :Systems and Humans, 2011, 41(6): 1144-1155.
[5] Dernoncourt D.Analysis of feature selection stability on high dimension and small sample data[J]. Computational Statistics and Data Analysis, 2014, 71(6): 681-693.
[6] Sina T. An unsupervised feature selection algorithm based on ant colony optimization[J]. Engineering Applications of Artificial intelligence, 2014, 32(1): 112-123.
[7] Salwani A. An exponential Monte-carlo algorithm for feature selection problems[J]. Computers and Industrial Engineering, 2014, 67(1): 160-167.
[8] Wu X. Online feature selection with streaming features[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(5): 1178-1192.
[9] Han J, Kamber M. Data Mining: Concepts and Techniques[M]. 北京: 机械工程出版社,2001.
[10] 朱颢东, 吴怀广. 基于论域划分的无监督文本特征选择方法[J]. 科学技术与工程, 2013, 13(7): 1836-1839.
[11] 郭亚维, 刘晓霞. 文本分类中信息增益特征选择方法的研究[J]. 计算机工程与应用, 2012, 48(27): 119-127.
[12] 周丽红, 刘 勘. 基于关联规则的科技文献分类研究[J]. 图书情报工作, 2012, 56(4): 12-16.
Multi-level feature extraction method based onK-means and Apriori
QIAN Shenyi, ZHU Yanling, ZHU Haodong
(School of Computer and Communication Engineering, Zhengzhou University of Light Industry, Zhengzhou 450002)
This article proposed a four-mining model based on the structural characteristics of scientific literature, and combinedK-means algorithm and Apriori algorithm to construct an new feature extraction method-MultiLM-FE Method. Firstly, scientific literature was divided into four layers according to its structure. And then, it selected features progressively for the former three layers byK-means clustering. Finally, it found out the maximum frequent itemsets of fourth layer by Aprori algorithm to act as a collection of features fourth layer. This method can solve the problem that theK-means clustering algorithm can’t determine the most appropriate clustering starting point automatically, and reduces the loss of information in the clustering process, so it is possible to find features more accurately in the literature corpus. Experimental results showed that this method was feasible and effective and had greatly improved especially in terms of the scientific literature when compared with the previous method.
scientificl iterature; feature extraction;K-means; Apriori
2014-11-24.
国家自然科学基金项目(61201447); 河南省科技攻关项目(122102210024、122300410287); 河南省高等学校青年骨干教师资助计划项目(2014GGJS-084); 河南省教育厅科学技术研究重点项目(13A520367); 郑州市科技计划项目(121PPTG362-12,131PPTGG411-8); 郑州轻工业学院校级青年骨干教师培养对象资助计划项目(XGGJS02).
1000-1190(2015)03-0357-06
TP311
A
*通讯联系人. E-mail: zhuhaodong80@163.com.
