供应链协同预测模型及实证研究
2015-03-20沈阳工学院姚海波
沈阳工学院 姚海波
1 引言
供应链上的需求是供应链管理中的关键问题,尤其是在由需求拉动的链条上,进行需求预测可以有效地减少不确定性因素对供应链绩效的负面影响。当前,供应商、制造商、分销商、零售商以至最终用户之间不再是独立的个体,追求的也不是自身利益的最大化,而是逐渐形成战略合作伙伴关系,寻求的是整体的最优。
协同计划、预测与补给(Collaborative Planning,Forecast and Replenishment, CPFR),可以实现供应链上合作伙伴间协同计划、预测并共享需要的资源和信息,减少需求的不确定性,更精确地掌握用户的需求情况。而预测模型的构建和选择直接关系到最终预测结果的精度,因此,有必要研究基于信息共享机制的协同需求量预测模型。
2 遗传算法(GA)与BP神经网络
2.1 GA简介
遗传算法由美国Michigan大学的Holland教授首先提出,是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。遗传算法是从代表问题可能潜在的解集的一个种群(population)开始的,而一个种群则由经过基因(gene)编码的一定数目的个体(individual)组成。每个个体实际上是染色体(chromosome)带有特征的实体。染色体作为遗传物质的主要载体,即多个基因的集合,其内部表现(即基因型)是某种基因组合,它决定了个体的形状的外部表现,如黑头发的特征是由染色体中控制这一特征的某种基因组合决定的。因此,在一开始需要实现从表现型到基因型的映射即编码工作。
由于仿照基因编码的工作很复杂,我们往往进行简化,如二进制编码,初代种群产生之后,按照适者生存和优胜劣汰的原理,逐代(generation)演化产生出越来越好的近似解,在每一代,根据问题域中个体的适应度(fitness)大小选择(selection)个体,并借助于自然遗传学的遗传算子(genetic operators)进行组合交叉(crossover)和变异(mutation),产生出代表新的解集的种群。这个过程将导致种群像自然进化一样的后生代种群比前代更加适应于环境,末代种群中的最优个体经过解码(decoding),可以作为问题近似最优解。遗传算法能以很大的概率找到全局最优解,特别适合处理传统搜索方法解决不了的复杂和非线性问题。
遗传算法是解决搜索问题的一种通用算法,对于各种通用问题都可以使用。搜索算法的共同特征为:一是首先组成一组候选解;二是依据某些适应性条件测算这些候选解的适应度;三是根据适应度保留某些候选解,放弃其他候选解;四是对保留的候选解进行某些操作,生成新的候选解。在遗传算法中,上述几个特征以一种特殊的方式组合在一起:基于染色体群并行搜索,带有猜测性质的选择操作、交换操作和突变操作。
2.2 BP神经网络
反向传播网络(Back-Propagation Network,简称BP网络)是将W-H学习规则一般化,对非线性可微分函数进行权值训练的多层网络。
BP神经网络的产生归功于BP算法的获得。BP算法是由两部分组成:信息的正向传递与误差的反向传播。在正向传播过程中,输入信息从输入经隐含层逐层计算传向输出层,每一层神经元的状态只影响下一层神经元的状态。如果在输出层没有得到期望的输出,则计算输出层的误差变化值,然后转向反向传播,通过网络将误差信号沿着原来的连线线路反向传递回来修改各层神经元的权值,直到达到网络期望的目标值。
为了训练一个BP网络,需要计算网络加权输入矢量、网络输出和误差矢量,然后计算误差平方和。当所训练矢量的误差平方和小于目标误差,训练停止,否则在输出层计算误差变化,而且采用反向传播学习规则来调整权值,并重复这个过程。当网络悬链完成后,对网络输入一个不是训练集合中的矢量时,网络可以以泛化方式输出结果。
神经网络权值的调整是在误差反向传播过程中逐层进行的,当网络的所有权值都被更新一次之后,网络就经过了一个学习周期。网络经过若干个学习周期后,便得到了网络的最优权值。在此基础上就可以利用所建立的BP网络对需求进行相对准确的预测。
3 GA-BP神经网络模型的建立
BP神经网络使用广泛,但其对隐含层神经元的个数没有确定的最佳数目,初始权值和阈值是随机产生,以及网络训练最终的结果是得到的是局部最优解。遗传算法遵循“优胜劣汰”的原则,能从进化好的个体中选择最优解,是可以求得全局最优解的方法。遗传算法可以通过优化神经网络的初始权值和阈值,恰能很好地克服BP神经网络的缺陷,提高神经网络的稳定性,进而获得全局最优解。
GA-BP神经网络具体操作步骤如下:
(1)构建BP神经网络结构,本文采取三层网络,即输入层—隐含层—输出层,输入层节点数由供应链协同预测的影响因素个数确定,隐含层的节点数由误差值和样本的个数共同确定,输出层节点数由需求预测的时间段来确定;
(2)初始化神经网络的权值和阈值,用遗传算法对其进行优化编码,本文采用实数编码,随机生成初始种群;
(3)训练神经网络,以误差值调整初始值;
(4)遗传操作:选择、交叉和变异,进化种群;
(5)判断:计算适应值,如果不满足条件,返回上一步操作,如果满足,则结束,得到最优的权值和阈值;
(6)计算神经网络误差值,在允许范围内,则可利用该模型进行需求预测,如果不满足,则回到上一步,直至满足条件。
4 实证研究
预测一般可以分为短期预测、中期预测和长期预测,本文选取某日用品为例,考虑到商品属于便利品的属性,日常需求量大的特点,也为了保证有足够的样本数量,本文选取的采样频度为一周。该日用品的供应商与零售商,建立了基于信息和资源共享的协同机制,零售商实时向供应商共享其过往一周的实际销量,供应商采用GA-BP神经网络进行预测,以应对下一期的需求,保证足够的销量,提高该供应链条的有效供给量。现以某品牌日用品的供应商得到有关数据,这个数据是从多个大型超市获得本周总需求量,如表1所示。
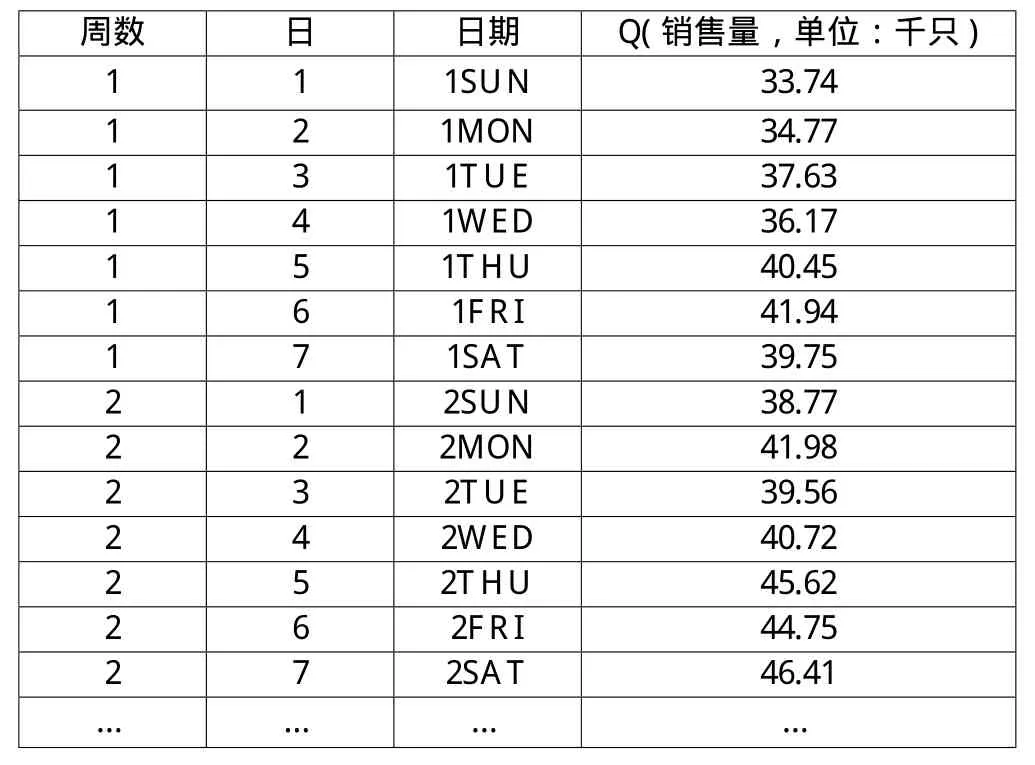
表1 日用品供应商各周需求数据汇总表
将历史数据作为样本输入BP网络的输入层,对GA-BP神经网络进行训练。模型中网络结构为输入12-隐含25-输出1。这里取遗传算法的初始种群数为50,最大的遗传代数设为60,交叉概率0.9,变异概率0.01,初始权值的取值范围是-1~1;网络学习速率为0.02,最大迭代次数是2000次,误差目标值定为0.005。模型运用MATLAB工具求解,预测结果如图1所示。
图1 某日用品GA-BP神经网络预测结果
图1中的星号代表各期的预测值,实线代表实际的销售量构成的曲线,很明显,预测值相对实际值的偏离是非常小的。本文用平均平方误差MSE和平均绝对偏差MAD两个指标来衡量GA-BP神经网络的预测效果,如表2所示。

表2 GA-BP预测结果比较
5 结语
供应链协同是当前供应链管理的主流形式,供应商、制造商、分销商和零售商以及最终用户都已经意识到只有共享的合作机制可以提高整体的收益,如果脱离整体去寻求自身利益最大已不再可行。对于需求拉动的供应链,能利用有效的预测模型近乎准确地得到未来需求数据是供应链上合作企业的共同目标。本文提出将GA-BP神经网络模型用于供应链上的协同预测,并用实例证明了该模型的有效性,未来研究可以考虑如何更好地加快神经网络的收敛速度,以获得更高的预测精度。
[1] Partovi F Y,Anandarajan M,Classifying inventory using an artificial neural network approach.Computers & Industrial Engineering,vol.41,2002.
[2] 后锐,张毕西.基于MLP神经网络的区域物流需求预测方法及其应用[J].系统工程理论与实践,2005(12).
[3] 董绍辉,张志清,西宝.供应链协同需求预测机制研究[J].运筹与管理,2010(10).
[4] 胡万达.基于遗传BP神经网络的区域物流需求预测[J].重庆三峡学院学报,2014(5).
[5] 丛爽.面向MATLAB工具箱的神经网络理论与应用(第二版)[M].中国科学技术大学出版社,2003.
