基于查询-概念的用户兴趣模型构建
2015-01-12宋天勇郑山红王国春
宋天勇,赵 辉,郑山红,王国春
(长春工业大学计算机科学与工程学院,长春130012)
0 引言
Internet信息的指数增长所导致的“信息迷航”和“信息过载”已经日益制约人们高效地使用网络信息,为更好地适应Internet的发展,个性化推荐服务应运而生[1]。个性化推荐服务根据用户兴趣模型主动向用户推荐网络信息,满足用户的个性化需求,便于用户高效地利用网络资源。用户兴趣模型是个性化推荐服务的核心,用户兴趣模型的构建可分为显式和隐式两种。显示的用户兴趣模型构建需要用户参与,隐式的用户兴趣建模则是系统通过分析用户的浏览历史自动构建用户兴趣模型。用户兴趣模型的表示方式主要分为:基于关键词模型、基于概念和概念层次模型、基于本体技术的语义模型[1,2]。用户兴趣模型的更新机制是保证用户兴趣模型长期有效的关键,用户兴趣建模的质量和更新机制的合理性制约着个性化服务的质量。
目前一些学者将用户兴趣分为长期兴趣和短期兴趣,通过对两种兴趣进行不同的处理提高推荐的准确率[2,3];宋艳娟等[4]提出一种基于文档结果和网页兴趣权重的TF.IDF算法,该算法能有效地对网页特征词进行提取;张玉连等[5]在提取特征词时提出TF.IDF.IG算法,以词语的信息增益作为一个特征词表示一个因子,衡量特征词在文本集合中分布比例在量上的差异。该方法能获得更有价值的特征词;刘鑫等[6]设计了时间元函数、并利用二次曲线对该函数进行拟合,通过该函数计算网页的兴趣度;南智敏等[7]在时间分段机制的基础上对兴趣模型进行衰减,使兴趣模型的表征更加准确;此外,陈文涛等[8]在微博领域对3种概率主题模型的用户兴趣模型进行了分析和对比;蒲国林等[9]利用语义网对用户兴趣模型进行改进;Zheng等[10]将时间作为权重的一部分,提高了社会化标签系统的推荐性能;Mariam等[11]利用概念图表示文档和用户模型,并通过用户模型概念图和文档概念图之间相互连接的部分计算两者间的相似度;马恩穹[12]通过查询概念二分图构建用户兴趣模型,利用用户兴趣模型实现查询优化,以此满足用户的个性化检索需求。
虽然普通的查询概念二分图结构具有较好的可解释性,但随着记录查询数量的增多,无法对查询进行有效合并和归类,容易造成用户兴趣模型维度过高;由于查询概念二分图将捕捉到的查询统一视为历史,并不考虑查询时间,所以不能较好地应对用户兴趣漂移的问题。基于以上两点,笔者在查询权重的表示上融入时间权重,并利用一定的用户兴趣建模算法,不断将新得到的查询注入已有用户兴趣模型,使用户兴趣模型不断完善,以提高生成的用户兴趣模型的质量。
1 查询-概念二分图
1.1 概念的提取
概念是思维的基本形式之一,反应客观事物一般的、本质的特征。在客观世界中,任何事物都有概念,也可以理解为名称[13]。如用户检索时输入的“Java程序员”中,Java和程序员就是两个独立的概念。对于用户输入的任一查询,用户会点击自己所需要的页面,这些被点击的页面中包含能表示该查询的概念。概念的提取范围包括被点击网页的标题和摘要,概念提取时首先需要对网页进行分词,并去除其中的停用词,如连词、代词等;其次,将分词的结果定义为词集S,对于∀ti∈S,利用

计算support(ti,q)。其中q代表查询词,f(ti,q)是包含ti和q的标题和摘要的数目,n表示全部的标题和摘要的总数,support(ti,q)越大说明词ti和q关系越紧密,如果support(ti,q)大于阈值ξ,则认为ti和q概念相关,support(ti,q)小于阈值ξ,则认为ti和q概念无关。将与q概念相关的词作为查询词q的概念。
1.2 查询-概念二分图构造
实验表明,82%的点击所涉及的查询和页面是相关的[13],所以对于任意查询,用户在系统返回的结果中点击过的页面都可认为是与查询相关的。从用户点击过的页面中提取能表示该页面的概念,将概念和查询看作两个集合,集合中的顶点分别代表不同的查询和不同概念,利用边表示概念和查询之间的关系。如用户输入查询词:“Java”、“Java web”、“Java android”,从用户点击的页面中提取的概念为:“程序开发”、“JavaScript”、“sdk”、“培训”,根据二分图定义可构造查询-概念二分图如图1所示。
在查询-概念二分图中,若两个查询词对应的概念集合重叠较多,则认为这两个查询词是相似的。对于任意两个查询词其相似度计算如下

图1 查询-概念二分图Fig.1 Query concept of binary figure

其中concepts(x)表示查询词x所涉及的概念集合,如,concepts(“java”)={“程序开发”,“培训”,“javascript”}。
2 改进的查询-概念二分图
2.1 问题的提出
对网页进行概念提取时,若浏览历史集合较小,则式(1)无法有效提取表达能力较强的关键词作为概念,只有当浏览历史集合每个查询词所对应的网页数目较大时提取的概念支持度才可靠。系统并不考虑每个查询对用户兴趣的贡献,如:用户输入“apple”进行检索,经过t1时间后,输入“apple iPhone”进行检索,历经t2时间,且t1≪t2,显然用户对于“apple iPhone”更感兴趣,但查询-概念二分图并没有体现不同查询词的不同权重。
2.2 查询-概念二分图的改进

笔者将在概念提取时利用式代替式(1)对浏览历史集合的规模表现出良好的可伸缩性,当浏览历史规模较小时,依然能提取较好的特征词作为概念的候选对象。其中w(tk)表示词的权重,ftk表示tk在网页中出现的频率,N表示一段时期内用户浏览的网页总数,nk代表N中出现了tk的网页数量。对每个被点击的网页,笔者选取其中权重较大的前L个特征词作为代表该网页的概念。用户进行检索时,对其感兴趣的网页,往往花费较多的时间阅读,因此,在捕捉用户浏览行为时可记录用户对每个网页的浏览时间,记为TB(pi),设用户浏览的全部网页集合为P,查询词q1对应的点击网页集合为clickSet(q1),则q1的权重计算公式如下

2.3 用户兴趣建模算法
在捕捉用户浏览行为阶段,系统需要记录一些信息并存入用户浏览历史数据库中,需要记录的信息包括:用户名、点击的url和时间、网页的阅读时间以及用户输入的查询词。
首先,通过分词等(如处理利用用户浏览历史)构建查询-概念二分图G;其次,根据查询词的权重将相似查询所包涵的概念组合成一个行向量,利用概念以空间向量模型为基础构建用户兴趣模型(UIM:User Interest Model),构建用户兴趣模型算法伪代码如下。
输入:查询-概念二分图G
输出:UIM
1)根据式(1)计算G中所有查询间的相似度,生成查询相似度矩阵Q;
2)若Q中两点间的相似度大于η,则两点间有一条边;
3)将Q划分成L个连通图g,令i=0;
4)while(i<L);
5)若连通图gi不为空,转6);否则,转10);
6)选取gi中查询编号最小的查询顶点qj;
7)取qj指向权值较大的前W(qj)个概念,记为cj;
8)将cj拼接到UIM的第j行中;
9)从gi中删除qj,转5);
10)i++,转4);
3 实验与分析
笔者从新浪门户网站上采集了10类900个网页作为网页库,通过模拟用户对网页的浏览行为构建用户兴趣模型,实验平台为myEclipse 8.5,中文分词器为中科院语义分词ICTCLAS。实验利用F-measure评价函数验证UIM建模算法的有效性公式其中P=Q/M为准确率,R=Q/N为召回率。设实际中属于类别C的网页数目为N,通过计算得到属于类别C的网页数为M,其中正确划分到类别C中的网页数目为Q。

实验中η=0.2、L=32,实验测试了笔者建模算法和文献[13]建模算法对不同用户浏览历史规模的性能,对每个规模进行5次Fmeasure测评并取其平均值作为结果,实现结果如图2所示。
在图2中,当用户浏览历史规模较小时利用式(1)得到的支持度不可靠,其提取的概念较为随意,构建的UIM的可解释性较差;但利用式(2)能较好地克服概念提取对用户浏览历史规模的依赖,并且当用户历史数据量较大时仍有较好的效果。
由于文献[13]将用户输入的所有查询同等对待,即不强调用户最近的查询对用户最新兴趣的贡献,也不考虑用户重点浏览的网页可能包含了用户相对较为重要的兴趣。笔者建模算法优先强调从最近的查询中提取概念,对于用户浏览时间较长的查询,加大其所对应的概念在UIM中的比重,以此保证用户的重要兴趣能在UIM得到合理体现,使生成的UIM具有更好的可解释性。综合考虑用户浏览历史规模,笔者建模算法构建的UIM更合理。
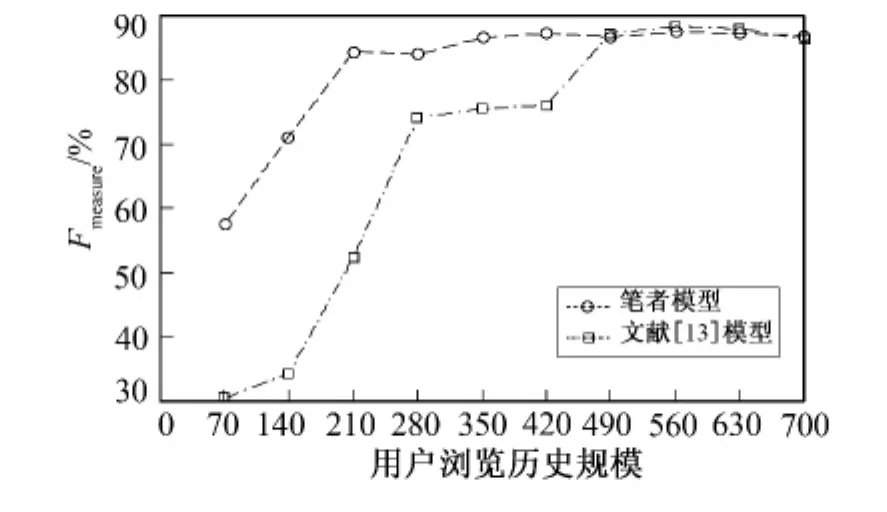
图2 Fmeasure值对比图Fig.2 Fmeasurevalue contrast figure
4 结语
笔者在参考以往用户兴趣模型研究的基础上,通过分析查询-概念二分图在概念抽取、对查询词重要性的衡量上的不足,利用tf×idf公式及用户对查询词的浏览时间进行改进。实验中通过模拟用户浏览生成不同规模的用户浏览历史验证了改进后的用户兴趣建模算法的有效性。在未来的研究中,将考虑用户兴趣模型的更新问题,致力于构建的用户兴趣模型能更好地拟合用户的真实兴趣;兴趣模型更新和利用用户兴趣模型进行相似度计算的过程中,考虑利用本体使计算结果更为合理。
[1]郝水龙,吴共庆,胡学钢.基于层次向量空间模型的用户兴趣表示及更新[J].南京大学学报:自然科学版,2012,42(8):190-197.HAO Shuilong,WU Gongqing,HU Xuegang.Presentation and Updation for User Profile Based on Hierarchical Vector Space Model[J].Journal of Nanjing University:Nature Science Edition,2012,42(8):190-197.
[2]李峰,裴军,游之洋.基于隐式反馈的自适应用户兴趣模型[J].计算机工程与应用,2008,44(9):76-80.LI Feng,PEI Jun,YOU Zhiyang.Adaptive User Interest Model Based on the Implicit Feedback[J].Computer Engineering and Applications,2008,44(9):76-80.
[3]费洪晓,蒋羽中,徐丽娟.基于树状向量空间模型的用户兴趣建模[J].计算机技术与发展,2009,19(5):82-85.FEI Hongxiao,JIANG Yuzhong,XU Lijuan.User Profile Based on Dendriform Vector Space Model [J].Computer Engineering and Developing,2009,19(5):82-85.
[4]宋艳娟,陈振标.个性化检索系统中用户兴趣模型的研究[J].计算机与数字工程,2013,41(2):271-274.SONG Yanjuan,CHEN Zhenbiao.User Interest Model in Personalized Retrieval System [J].Computer and Digital Engineering,2013,41(2):271-274.
[5]张玉连,王权.基于浏览行为和浏览内容的用户兴趣建模[J].现代图书情报技术,2007(6):52-55.ZHANG Yulian,WANG Quan.User Profile Mining of Combining Web Behavior and Content Analysis[J].New Technology of Library and Information Service,2007(6):52-55.
[6]刘鑫,钱松荣.时间元兴趣度度量方法和扩展 VSM用户兴趣模型研究[J].小型微型计算机系统,2011,32(4):708-712.LIU Xin,QIAN Songrong.Research on User Profile Based on Time Element Interest Rate Quantification Method and VSM Extension [J].Journal of Chinese Computer Systems,2011,32(4):708-712.
[7]南智敏,钱松荣.引入漂移特性的用户兴趣模型优化研究[J].微型电脑应用,2012,28(3):30-32.NAN Zhimin,QIAN Songrong.Research into the Drift Characteristics of User Interest Model Optimization[J].Microcomputer Applications,2012,28(3):30-32.
[8]陈文涛,张小明,李舟军.构建微博用户兴趣模型的主题模型的分析[J].计算机科学,2013,40(4):127-130.CHEN Wentao,ZHANG Xiaoming,LI Zhoujun.Analysis of Topic Models on Modeling MicroBlog User Interestingness Model Optimization [J].Computer Science,2013,40(4):127-130.
[9]蒲国林,杨清平,王刚,等.基于语义的个性化用户兴趣模型[J].计算机科学,2008,35(7):181-184.PU Guolin,YANG Qingping,WANG Gang,et al.Personalized Model of User Interests Based on Semantics[J].Computer Science,2008,35(7):181-184.
[10]ZHENG Nan,LI Qiudan.A Recommender System Based on Tag and Time Information for Social Tagging Systems[J].Expert Systems with Application,2011,38(4):4575-4587.
[11]MARIAM DAOUD,LYNDA TAMINE,MOHAND BOUGHANEM.A Personalized Search Using a Semantic Distance Measure in a Graph-Based Ranking Model[J].Journal of Information Science,2011,37(6):614-636.
[12]马恩穹.基于Web数据挖掘的个性化搜索引擎研究[D].南京:南京理工大学计算机科学与工程学院,2012.MA Enqiong.Research Based on Web Data Mining of Personalized Search Engine[D].Nanjing:School of Computer Science and Engineering,Nanjing University of Science and Technology,2012.
[13]孙雨生,刘伟,仇蓉蓉,等.国内用户兴趣建模研究进展[J].情报杂志,2013,32(5):145-149.SUN Yusheng,LIU Wei,QIU Rongrong,et al.Research Development of User Interest Modeling in China [J].Journal of Intelligence,2013,32(5):145-149.
