固态硬盘混合存储数据库的数据分布优化算法
2015-01-02周世民柴云鹏
周世民,柴云鹏,王 良,王 鑫
(1.中国人民大学a.数据工程与知识工程教育部重点实验室;b.信息学院,北京100872;2.天津大学计算机科学与技术学院,天津300072)
1 概述
联机事务处理(On-line Transaction Processing,OLTP)数据库在IT系统中占有非常重要的地位,很多应用系统大多离不开数据库,系统整体性能往往也由数据库的性能所制约。因此,提升数据库的性能具有非常重要的意义。传统数据库一般基于磁盘,磁盘具有稳定、非易失、大容量、成本低等优点,但主要的问题是访问速度比较慢,因此不利于构造高性能的数据库。
近年来,闪存存储得到长足发展,不仅容量迅速增大,而且制造成本也逐渐降低,目前已经以固态硬盘(Solid State Drive,SSD)的形式进入了很多实际的存储系统中,获得实际的应用。但SSD的成本目前仍然比磁盘高很多,因此目前多和磁盘构成混合存储,这样既能提升系统性能,又能用较低的成本得到很大的存储容量。基于SSD-磁盘混合存储来构造OLTP数据库系统是一种提升数据库性能的有效方法。
OLTP数据库要处理大量的交易请求,既需要大量的查询等读操作,同时也需要更新表和索引,有大量的随机写操作。在存储层引入SSD,尤其是用来存储一些访问频繁的数据,能够充分利用SSD的访问性能明显高于磁盘的优点,尤其是对于随机读写操作,从而提升OLTP数据整体的性能和服务能力。
但各种应用情况下数据库中数据特征、访问特征都有很大差别,数据库不可能出厂时就确定一种普适的、面向混合存储的数据分布优化策略,最理想的情况就是在运行时能够自适应,根据应用特征自动调节数据分布。
本文提出一种面向混合存储的OLTP数据库数据分布自适应优化算法,可自动适应应用的特征,并通过观测判断各个数据元素的性能,从而在SSD和磁盘之间自动形成理想的数据分布。
2 相关工作
2.1 闪存和固态硬盘
随着闪存在容量上的迅速增长和成本的降低,以闪存作为存储介质的新型固态硬盘已经在企业得到实际的应用。SSD最大的优点就是随机读写性能高,较普通磁盘的读写性能要高出1个~3个数量级[1],其中随机读性能比随机写性能更好。对于连续读写操作,SSD较普通磁盘高出2倍~4倍[2]。
SSD的随机和连续的读性能都比相应的写性能要高,这个特性称为读写不平衡[3],这不同于磁盘的读写性能平衡的特性,在一些情况下可能带来不利的影响。比如数据从一块SSD读出并写入另一块SSD,那么由于读性能高于写性能,读操作就必须等待写操作。
SSD的另一个缺点是不支持写覆盖[3],和磁盘不同,SSD无法直接重用已经写入数据的存储单元,只有先进行擦除操作后才能执行下次的写操作。而且,对于每块存储单元,允许擦除的总次数是存在上限的,即SSD的使用寿命有限。在SSD内部,如果部分存储单元频繁的执行擦除写入操作,相应的存储芯片就很容易出现擦写寿命耗尽,从而变为坏块的问题,从而导致SSD无法使用。目前主流SSD中闪存芯片的每个单元只能擦除5 000次~10 000次[4-5]。
2.2 OLTP数据库和性能测试
数据库产品一般可以简单分为联机事务处理(OLTP)和联机分析处理(On-line Analytical Processing,OLAP)两大类。OLTP是传统关系型数据库的主要应用形式,例如银行交易等。OLTP数据库对性能要求非常高,因此引入基于SSD的混合存储能够有效缓解I/O瓶颈,提升OLTP数据库的性能。
针对OLTP数据的性能测试,一般都采用数据库性能委员会发布的TPC-C测试[10]。TPC-C模拟了一个比较复杂并具有代表意义的OLTP应用环境:一个大型的商品批发销售公司,它拥有若干个分布在不同区域的商品仓库。当业务扩展时,公司将添加新的仓库。每个仓库负责为10个销售点供货,其中每个销售点为3 00个客户提供服务,每个客户提交的订单中,平均每个订单有10项产品,所有订单中约1%的产品在其直接所属的仓库中没有存货,必须由其他区域的仓库来供货。同时,每个仓库都要维护公司销售的100 000种商品的库存记录。
2.3 基于SSD的混合存储
尽管SSD在性能等方面有明显的优势,但由于其价格相对较高,而且具有擦除寿命的限制,因此一般企业还是多以混合存储的形式使用SSD,即由SSD和HDD来构成混合存储。具体混合的方式分为两大类:(1)SSD作为内存之下的二级缓存;(2)SSD代替部分磁盘,负责存储一部分数据。
由于SSD缓存接入系统就可以直接使用,不需要对原有系统进行修改,因此现在基于这种结构的技术比较多,包括:EMC 的 FAST Cache[6],Intel的Turbo Memory[7],Solaris ZFS 文件系统中 L2ARC 算法管理的闪存缓存[8],以及Oracle数据库中的智能闪存缓存[9]等。但是SSD缓存的主要挑战是SSD的写入量太大,容易导致SSD较短时间就报废。SSD代替部分磁盘构成混合存储的方案如果设计合理,可以避免写入量过大的问题,也能够得到更好的性能加速,也是本文所关注的方案。
3 自适应优化算法
3.1 数据分布自适应优化算法
图1给出了数据分布自适应优化算法的流程,算法周期性执行,每个周期中分为观测、决策、数据迁移几个主要步骤。

图1 数据分布自适应优化分布算法流程
首先经过较长时间的观测期,算法会记录每个表和索引的访问特征,以便进行后续的决策。在决策步骤中,会根据SSD的空间,以及各个表和索引的访问特征对其进行排序,排序方法由具体的决策策略决定。在决策之后,算法会判断是否需要执行数据迁移方案:如果是第一次决策,SSD还是空白状态,或者此次决策方案和目前SSD中存储的数据差异较大,则执行数据迁移;否则不执行,此周期结束。如果需要执行数据迁移,则目标是将决策中排序最前面的若干个表和索引存入SSD中,直至SSD空间基本被占满。
3.2 混合存储优化策略
自适应数据分布优化算法框架中,数据分布决策部分是整个算法的核心。但实际上算法框架可以支持多种决策策略,每种策略有自己的特点,可以在不同环境下选择不同的策略。
(1)I/O吞吐量优先策略
SSD的数据访问性能全面高于磁盘。当把SSD和磁盘组成混合存储时,SSD应该承担更多的I/O访问,这样才能充分发挥SSD的性能优势;但是SSD的空间有限,因此SSD中单位容量的数据应该承担更多的I/O数据访问。具体来说,数据库中表和索引的按照rw/space因子进行排序,rw/space因子的含义是某个数据元素(表或索引)单位存储空间数据的读写总量的贡献值。
(2)I/O次数优先策略
由于SSD相对于磁盘在随机读、写方面的性能优势更为明显,因此应该将小块数据的随机读写请求更多的数据元素存储的SSD上。如果将尽可能多的I/O次数放到SSD上,那么很多小块数据的随机访问都将由SSD承担,而磁盘则承担自己比较擅长的连续读写,即使访问的数据量较大,性能相对也会比较高。因此,本文提出的I/O次数优先策略按照io/space因子对所有表和索引进行排序。io指每秒钟完成的I/O请求次数,它反映的是数据I/O访问的频繁程度。io/space因子的含义是某个数据元素单位空间的数据对访问次数的贡献值。
4 实验结果与分析
4.1 实验环境
OLTP数据库的性能测试一般采用国际标准的TPC-C测试(见2.3节的介绍),因此本文采用TPCC测试来进行数据分布自适应优化算法的实验。实验中生成的TPC-C测试数据总量约为13 GB,其中所涉及的9个表和11个索引,它们各自所占空间如表1所示。
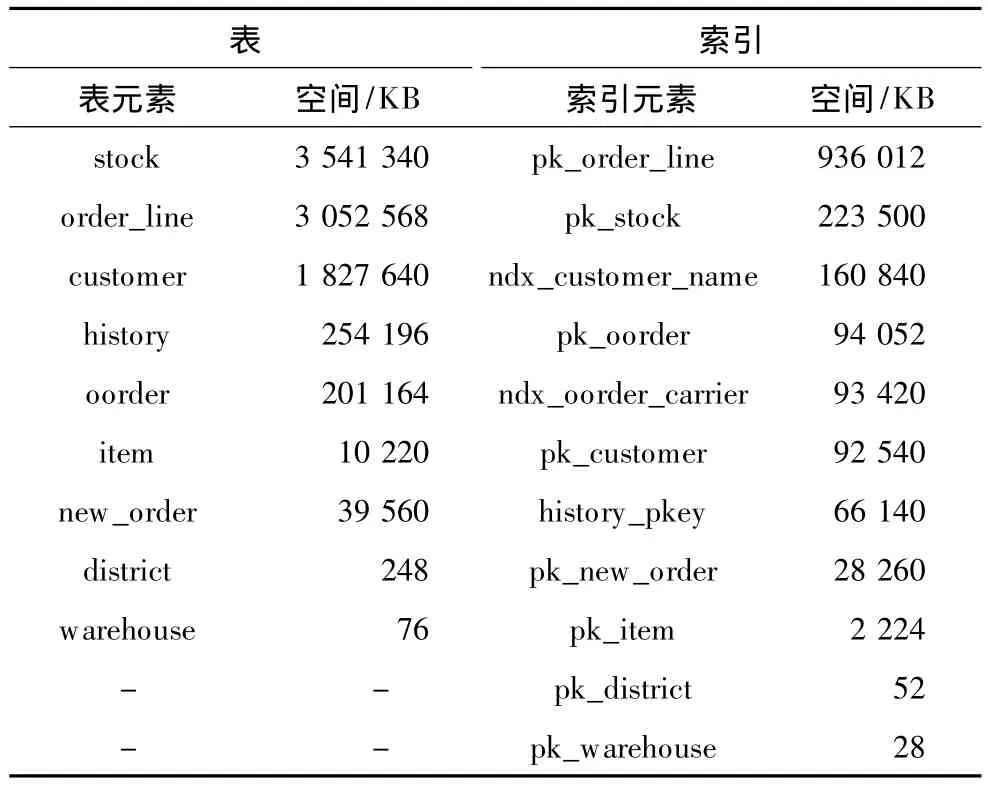
表1 TPC-C测试中表元素和索引元素所占空间
为进行准确的测试,在服务器上搭建了完整的实验环境。服务器为HP Proliant DL380,其中包括Intel Xeon E5-2609 CPU 2.40 GHz、16 GB 内存、4 块SAS 1 TB 7200RPM构成的RAID5磁盘阵列,以及1块三星的128 GB SSD。
数据库软件采用开源的PostgreSQL,PostgreSQL是当前最流行的对象关系型数据库之一,主要用于OLTP应用。其主要特点是开源、功能完备、高可扩展性、可编程性强等[11]。而TPC-C测试工具采用开源的 BenchmarkSQL[12]。
4.2 性能测试
本部分在上述实验环境中应用本文提出的数据分布自适应优化算法,分别测量了以下2种优化策略的性能。性能指标采用了TPC-C测试中常用的tpmC指标,即平均每分钟可以完成多少次事务处理。
(1)I/O吞吐量优先策略
I/O吞吐量优先策略在观测阶段会按照数据元素单位存储空间的读写访问总量对所有数据元素进行排序,并优先选择排名靠前的数据元素进入SSD存储,TPC-C测试实验中排名前10位的数据元素如表2所示。
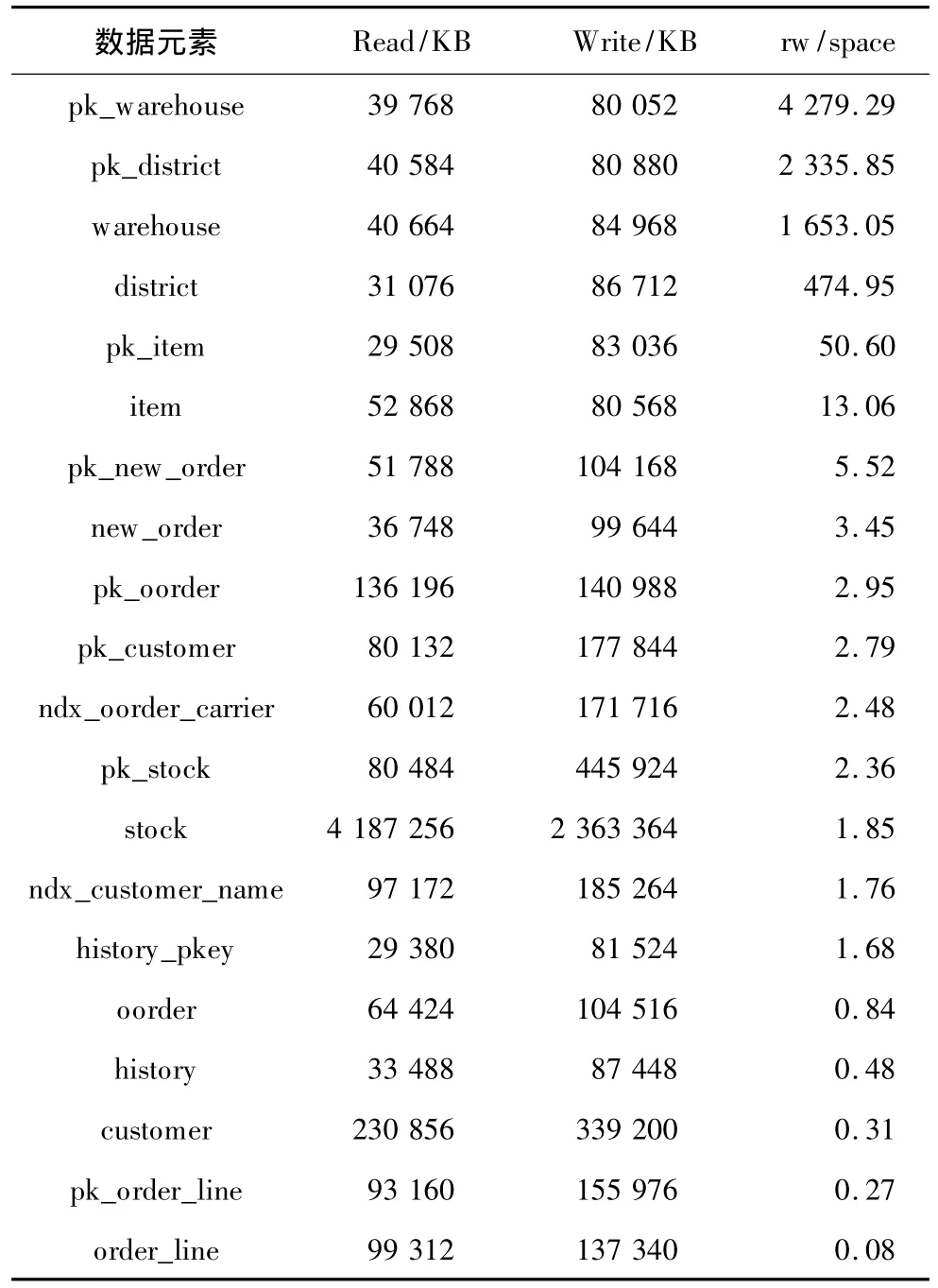
表2 I/O吞吐量优先策略对数据元素的排序
基于表2的结果,图2给出了不同SSD大小的情况下,整个数据库系统的tpmC值,即性能情况。由图2可知,随着混合存储中SSD空间占总空间比重的增大,数据库系统的性能提升非常明显,基本上是线性增加。其中当SSD空间占混合存储总空间的比例约为40%左右时,性能提升更为迅速。

图2 OLTP数据库性能随SSD空间增长的变化曲线1
值得注意的是SSD空间比例在40%附近经历一个性能快速上升的阶段后,有一个性能短暂下降的过程。其原因主要是增大SSD空间存储更多内容时,按照本文方案,SSD中新增内容的热度比之前有所下降;但新增数据却要抢占有限的SSD访问带宽。由于新增数据热度和之前SSD中数据相差较大,因此导致性能有短暂的下降。
(2)I/O次数优先策略
相对于前一种策略,I/O次数优先策略更倾向于把小块数据的随机访问定向到混合存储中的SSD,获得更好的性能提升。在算法的观测阶段,I/O次数优先策略会以数据元素单位存储空间的读写I/O总次数来作为排序标准。观测结果如表3所示,其中,IO/space为单位存储空间每小时的 IO次数。
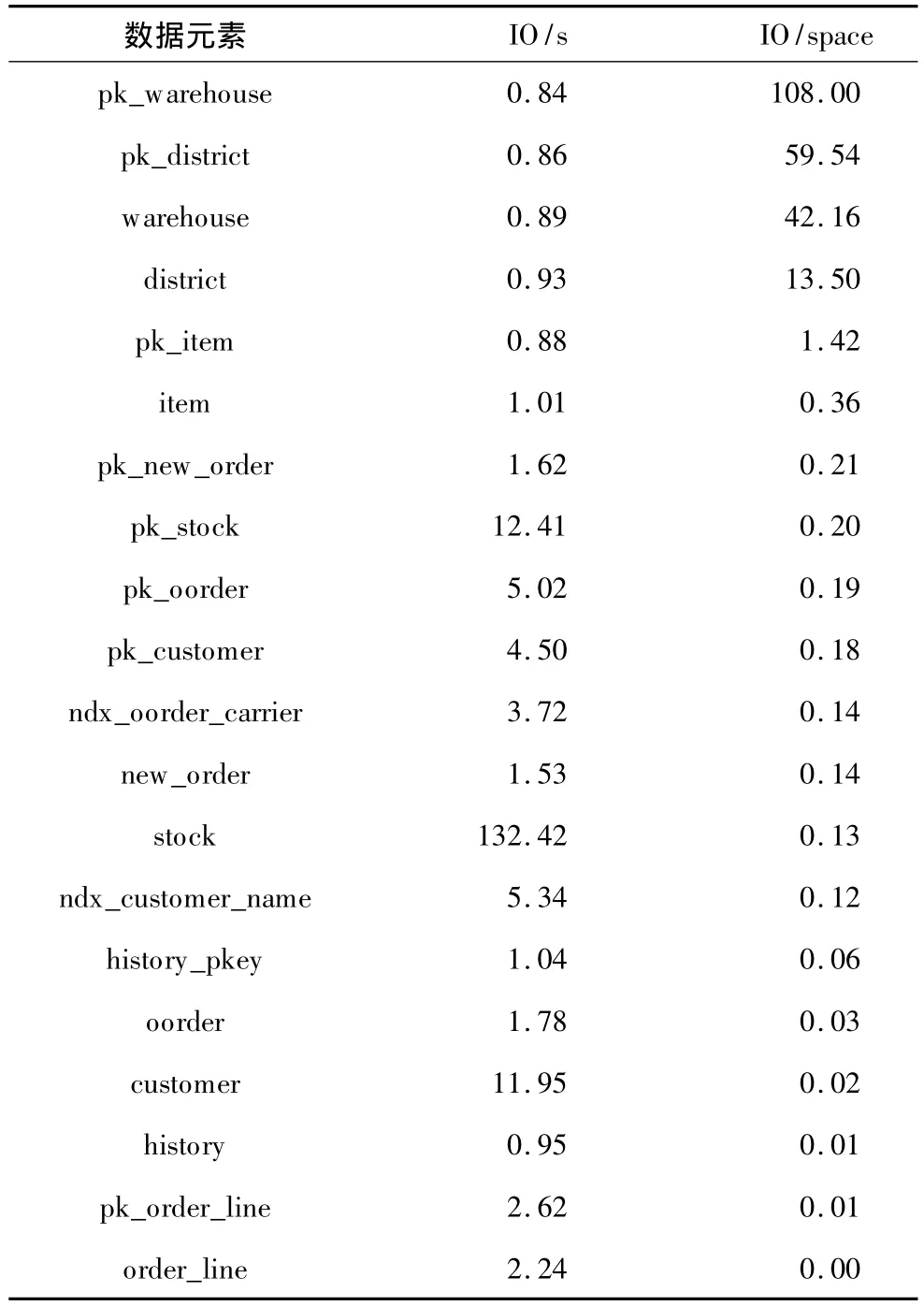
表3 I/O次数优先策略对数据元素的排序
基于表3的决策结果,图3给出了不同SSD大小的情况下,整个数据库系统的tpmC值。由图3可知,I/O次数优先策略的规律与I/O吞吐量优先策略非常相似,区别并不大。这也说明不论是以吞吐量为标准,还是以I/O次数为标准,只要将I/O更集中的数据元素存储于SSD,混合存储方案对OLTP数据的性能提升效果就非常明显,基本可以达到线性提升。投入越多的SSD,就可以得到近乎同比例的更高性能。
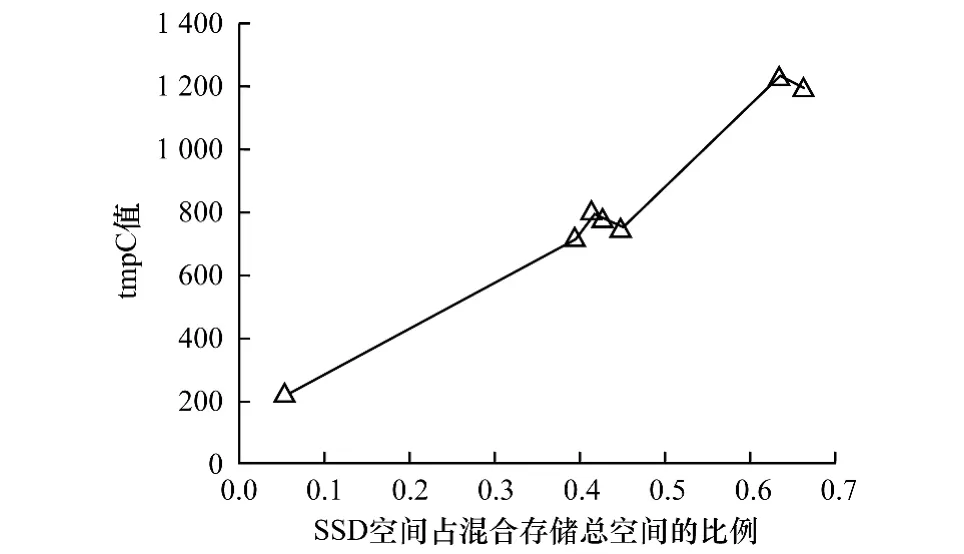
图3 OLTP数据库性能随SSD空间增长的变化曲线2
对于I/O吞吐量优先策略,SSD空间占比从5.5%提升到65.9%时,tpmC 可以提高到 5.44倍(1 220/224.3);而I/O次数优先策略,当SSD空间占比从5.5%提升到66.3%时,tpmC可以提高到5.53 倍(1 227.4/222.1)。
5 结束语
本文提出了一种基于混合存储的OLTP数据库的数据分布自适应优化算法,可通过自动观测决定数据库在SSD和磁盘之间的优化数据分布。基于实际数据系统的TPC-C实验结果证明,本文提出的优化算法和2种优化策略,可以实现OLTP数据库性能的线性提升。
[1] 陈明达.固态硬盘(SSD)产品现状与展望[J].移动通信,2009,(11):29-31.
[2] Bausch D,Petrov I,Buchmann A.On The Performance of Database Query Processing Algorithms on Flash Solid State Disks[C]//Proceedings of the 22nd International Workshop on DatabaseandExpertSystemsApplications.Toulouse,French:IEEE Press,2011:139-144.
[3] Solid-state Revolution:In-depth on How SSDs Really Work[EB/OL].(2013-10-21).http://arstechnica.com/information-technology/2012/06/inside-the-ssd-re volution-how-solid-state-disks-really-work.
[4] Andersen D,Swanson S.Rethinking Flash in the Data Center[J].IEEE Micro,2010,30(4):52-54.
[5] Gal E,Toledo S.Algorithms and Data Structures for Flash Memories[J].ACM Computing Surveys,2005,37(2):138-163.
[6] EMC.EMC FAST Cache:A Detailed Review[EB/OL].(2011-12-12).http://www.emc.com/collateral/soft ware/white-papers/h8046-clariion-celerra-unified-fast-ca che-wp.pdf.
[7] Matthews J,Trika S,Hensgen D,et al.Intel® Turbo Memory:Nonvolatile Disk Cachesin the Storage Hierarchy of Mainstream Computer Systems[J].ACM Transactions on Storage,2008,4(2).
[8] Bitar R.Deploying Hybrid Storage Pools with Sun Flash Technology and the Solaris ZFS file System[EB/OL].(2011-02-13).http://wikis.sun.com/download/attach ments/190326221/820-5881.pdf.
[9] Oracle.Exadata Smart Flash Cache and the Sun Oracle Database Machine[EB/OL].(2009-03-06).http://www.oracle.com/technetwork/middleware/bifoundation/exadata-smart-flash-cache-twp-v5-1-128560.pdf.
[10] TPC-C标准文档[EB/OL].(2010-05-06).http://www.tpc.org/tpcc/spec/tpcc_current.pdf.
[11] PostgreSQL Introduction[EB/OL].(2013-08-09).http://www.postgresql.org/about.
[12] BenchmarkSQL[EB/OL].(2014-09-10).http://sourceforge.net/projects/benchmarksql.
