基于多特征分类的微博好友推荐
2015-01-02程倩倩王路路姬东鸿
程倩倩,王路路,郑 涛,姬东鸿
(武汉大学计算机学院,武汉430072)
1 概述
随着Web2.0的迅速发展,社交网络与人们的生活越来越密切,成为人们生活中必不可少的一部分。一方面,社交网络能够帮助用户认识有相同爱好的人,联系现实生活中的好友、分享信息等。另一方面,社交网络也为用户提供了海量社交信息,使大家可以共同分享与交流。社交网络的运作蕴藏了巨大商机,挖掘和利用这些信息已经在各领域展开,但是随着用户数量和信息量的增大,信息过载问题变得越来越严重,如何从大量用户中为目标用户推荐感兴趣的用户,即好友推荐系统是一个重要的研究方向。
好友推荐系统研究在学术界引起了高度关注,存在诸多推荐算法,主要包括:基于协同过滤的推荐,基于内容的推荐,基于关联规则技术的推荐,基于聚类技术的推荐等。其中,基于协同过滤的推荐算法是目前最受欢迎的推荐技术,不依赖物品本身,主要依赖目标用户或与目标用户相似的用户对物品的评分矩阵进行推荐。但是社交网络中不存在这种共同的打分项,所以,这种经典的推荐算法不能直接用于用户社交网络的好友推荐,并且也存在一些难以克服的问题,比如:可信问题,冷启动问题和数据稀疏问题等[1]。
由于在用户微博内容中隐含用户感兴趣的话题和领域,因此基于用户内容的推荐算法也是一项重要技术。文献[2]对用户的Twitter内容进行处理,发现用户的兴趣点,进而为目标用户推荐具有相同兴趣的用户。这是对基于用户内容的推荐算法的一个运用。但是这种推荐算法仅使用用户的内容信息,推荐结果往往过于专一化,更倾向于推荐具有相同兴趣爱好的陌生人[3]。
一些研究者将基于内容的推荐算法和社交网络的好友关系相结合。文献[4]提出Twittomender系统,根据目标用户的Twitter内容、好友、粉丝以及好友和粉丝的Twitter内容进行建模。文献[5]利用概率模型进行协同过滤,进而为目标用户进行推荐最感兴趣的用户,概率模型综合考虑Twitter内容和用户间的关系。但是上述研究都没有使用大量存在的用户间的交互信息和用户的个人信息。
综上所述,目前在好友推荐系统中采用的信息过于单一,没有综合利用多种信息特征,导致推荐效果不佳。本文归纳了影响用户推荐的4类信息:用户标签信息,用户内容信息,用户交互信息,用户社交拓扑信息,利用这些信息计算出相关特征,并采用分类算法为目标用户进行好友推荐。
2 相关知识
2.1 线性判别分析主题模型
线性判别分析(Linear Discriminant Analysis,LDA)是一种非监督学习技术,可以用来挖掘大规模文档集或语料库中潜藏的主题信息。它采用词袋的方法,将每一篇文档视为一个词频向量,从而将文本信息转化为易于建模的数字信息。每一篇文档被看作主题的一种概率分布,主题又被看作是单词的一种概率分布。
对于语料库中的每一篇文档,LDA定义了如下的生成过程:
(1)选择N~Possion(ξ);
(2)选择一个多项式分布参数θ~Dir(i);
(3)对于文档中的每个词:
1)选择一个topic z~Multinomial(θ),z是从以θ为参数的多项式分布中选出,共有k个topic;
2)从概率分布p(wn|zn,β)中选择一个词 wn,p为topic zn下的一个多项式分布。
上述过程可以用图1所示的贝叶斯网络图来表示。
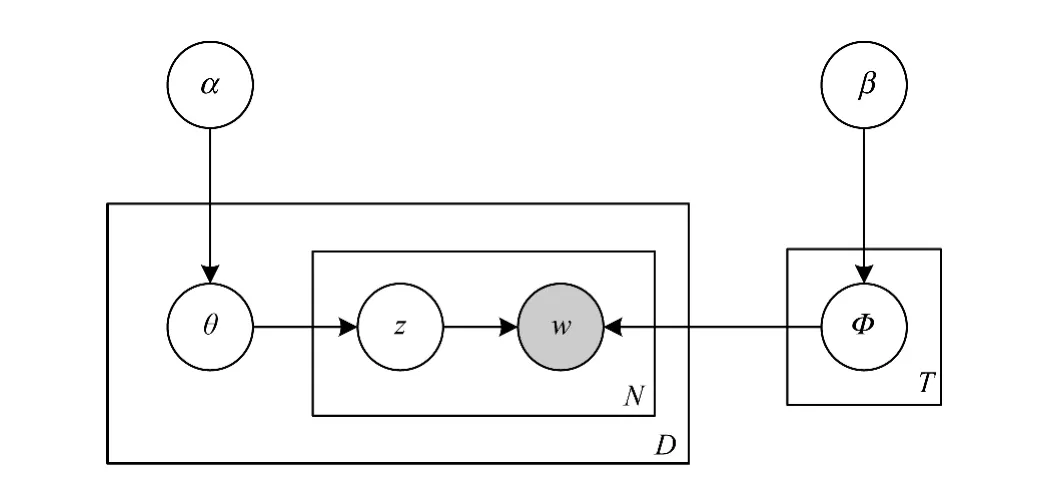
图1 贝叶斯网络
在图1中,α是θ的超参数;β是Φ的超参数;θ是文档-主题概率分布;Φ是主题-词概率分布;z是词的主题分布;w是词;D是文档数;N是词数;T是主题数。整个贝叶斯网络图的联合概率为:
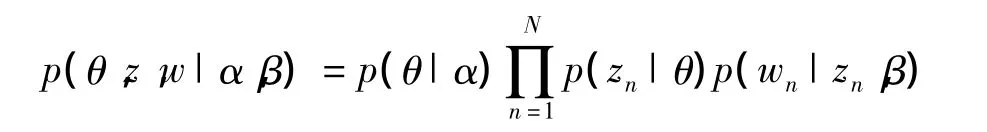
2.2 K最近邻算法
K最近邻(K Nearest Neighbor,KNN)分类算法的核心思想是如果一个对象在特征空间中的k个最相似的对象中的大多数属于某一个类别,则该对象也属于该类别,并具有该类别上对象的特性。
使用KNN算法对未知类别的点进行分类,具体步骤如下:
(1)计算已知类别数据集中的点与该点之间的距离;
(2)按照距离递增次序排列;
(3)选取与当前点距离最小的k个点;
(4)确定前k个点所在类别的出现频率;
(5)返回前k个点出现频率最高的类别作为当前点的预测分类。
3 微博好友推荐算法
本文通过分析总结了影响好友推荐的4类关键用户信息:(1)用户内容信息,主要是指用户发布、转发的微博内容;(2)用户标签信息,这是用户注册时对自己兴趣爱好的一组标签描述;(3)用户交互信息,这是用户间评论、转发、赞等交互行为;(4)用户社交拓扑信息,这是用户的关注列表和用户的被关注列表,即粉丝列表。在这4类关键信息的基础上,利用LDA主题模型从用户内容信息中挖掘用户潜在的兴趣爱好,并计算用户间的主题相关度;通过用户标签信息,计算用户间的显式的兴趣相关度;从用户交互信息和社交拓扑信息中,利用加权最小信息比率(Weighted Minimum-message Ratio,WMR)[6]算法计算用户间的亲密度;最后将主题相关度、兴趣相关度、亲密度作为特征向量,利用KNN分类方法进行好友推荐。
3.1 主题相关度计算
主题模型已经成功应用于很多文本挖掘任务中,比如热点主题发现、用户兴趣发现、文本分类等[7-9]。本文采用LDA主题模型对用户潜在的兴趣进行发现。由于微博内容长度必须限制在140字以内,而一些研究者指出LDA模型应用于短文本时准确率较低[10],它适合用于长文本。但文献[11]实验证明在特定参数设置下,LDA模型应用于短文本时同样可以取得和长文本一样的效果。另外,文献[12]通过在WebMd数据集上的实验证明,即使在平均长度仅为5.2个词的短文本上LDA模型也可以取得很好的效果。为准确挖掘用户感兴趣的主题,本文把用户的所有微博内容集中到一个文档中,即一个用户对应一篇内容文档;然后利用汉语词法分词系统(Institute of Computing Technology,Chinese LexicalAnalysis System,ICTCLAS)对文档进行分词,由于名词和动词对主题的辨识作用较大,因此只提取出文档中的名词和动词,去掉其他词性的词语以及停用词;然后利用LDA主题模型挖掘每篇文档的主题,结果存储到矩阵中;最后使用Jensen-Shannon散度计算主题的相关度:

3.2 标签相关度计算
标签是用户在完善个人资料时填写的关于个人兴趣爱好描述的一组关键字,是表征用户兴趣爱好的一种重要信息。用户相同的标签越多,用户与标签的关联度越大,则2个用户的兴趣爱好越相似。本文采用式(1)计算2个用户的标签相似度:
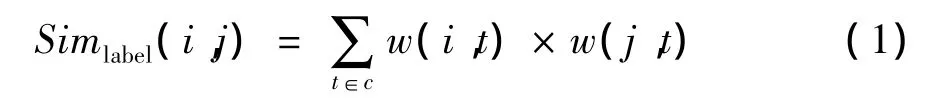
其中,c为用户 i、用户 j共同的标签集合;t∈c,w(i,t)表示标签 t与用户 i的关联度,w(i,t)的初始值为1,标签每次在用户i的关注用户中出现一次值增加0.1,最后对Simlabel值进行归一化处理。
3.3 亲密度计算
用户交互信息即微博用户间的信息交互行为,包括评论、转发、赞等动作。交互行为直接反映了用户间社交关系的强弱,即用户间的亲密度,交互越频繁说明用户间的关系越亲密。文献[13]将用户网络分成2个部分,即相似用户网络和熟悉用户网络,并通过比较这2类网络的推荐情况,证明基于熟悉用户网络推荐的效果要好于基于相似网络的推荐。因此,构建一个以用户为顶点、交互次数为边的有向网络是十分有必要的。根据文献[14]中提出的小世界理论,任何2个陌生人最多不超过6个中间人就可以互相认识。所以,只需以目标用户为根节点,向外延伸6层即可。用户间的交互信息可以使用图2的网络图进行模拟。
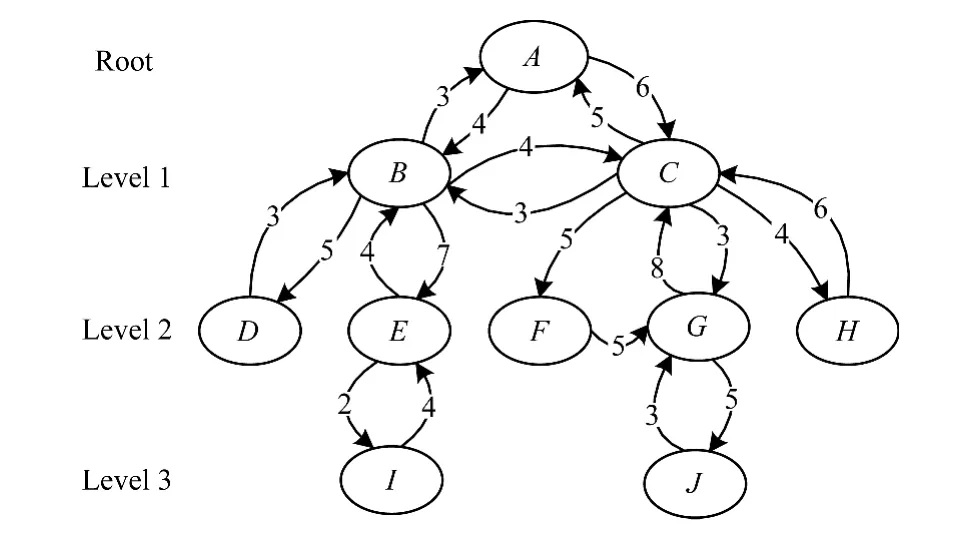
图2 用户交互网络
本文结合文献[6]中提出的WMR算法,计算用户间的亲密度。首先用户交互是一个双向的行为,取2边中较小的一个值,这样可以有效防止骚扰性的用户交互;然后取消同层用户间交互的信息,因为这些信息对最终不同层用户与目标用户的亲密度的计算没有影响,经过处理,得到如图3所示的一个无向的网络图;最后使用式(2)计算用户间的亲密度。
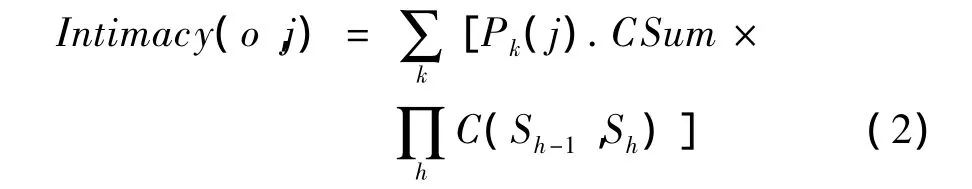
其中,Sh∈Pk(j)∩L(h),h=1,2,…,6;j∈L(h)且h≠1;Cij表示用户i和用户j之间交互的次数;L(h)表示在网络图中所有属于第h层的用户;Pk(j)表示从根节点即目标用户开始到达用户j的第k条路径;Pk(j).CSum表示路径Pk(j)上交互次数的总和;L(h).CSum表示第h层交互次数的总和;C(i,j)表示 Cij占 L(h).CSum 的比例,用户 i∈L(h-1),用户j∈L(h);Intimacy(o,j)表示用户j与目标用户o的亲密度。
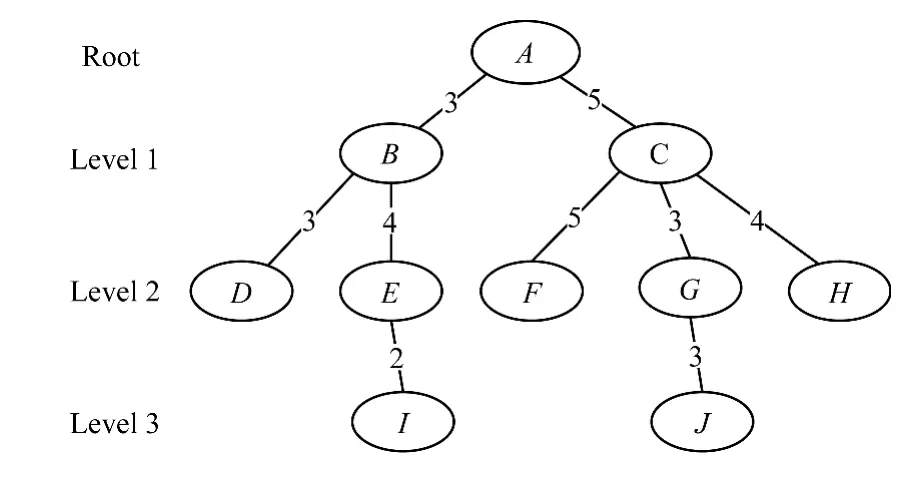
图3 改进后的用户交互网络
3.4 利用KNN分类算法的微博好友推荐
目前用户推荐研究采用的信息都比较单一[15-16],且都是采用排序函数实现排序,最终得到推荐列表,这样的推荐模型在参数较多的情况下效果都不理想。因此,本文充分考虑用户内容的主题相似度Simtopic、用户的标签相似度Simlabel,以及用户的亲密度Intimacy,然后利用KNN分类算法进行分类推荐。推荐框架如图4所示,带箭头的虚线表示用户间的关注关系。训练数据是由目标用户u的部分好友以及非好友组成的集合,如果用户i是用户u的好友,标记为+1,否则标记为-1。测试数据使用的用户数据类型和训练数据相同,对于每个测试用户i,利用KNN算法计算分类结果。然后根据式(3)计算测试用户i的推荐得分,最后根据得分降序为目标用户u产生一个好友推荐列表。
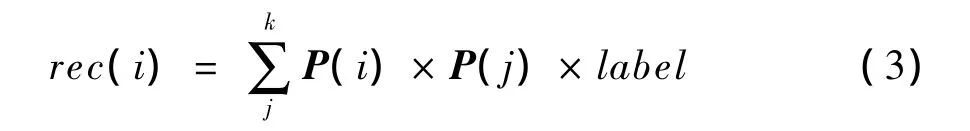
其中,P(i)表示测试用户的特征向量;P(j)表示训练用户的特征向量;k为KNN算法中k的取值;label表示用户i的分类结果,label的取值为+1,-1。
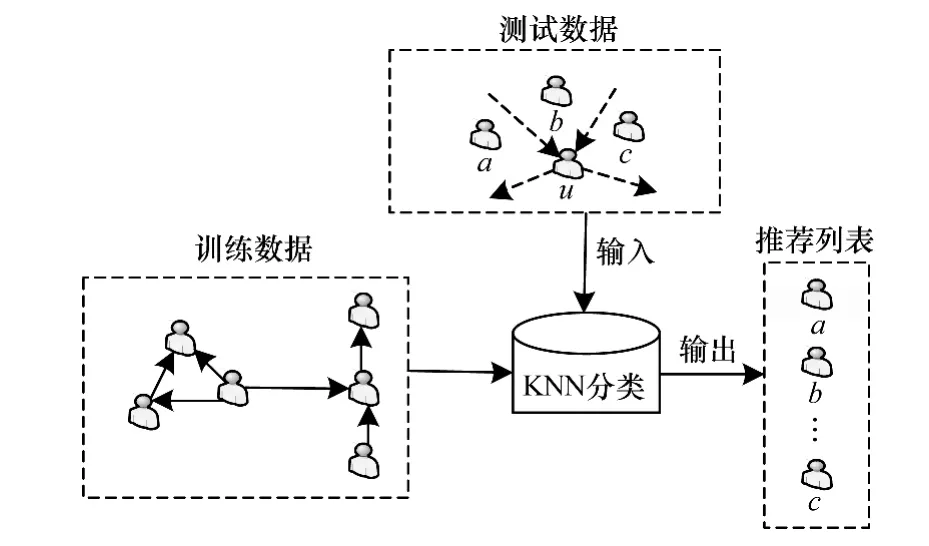
图4 利用KNN分类算法的微博好友推荐框架
4 实验结果及评估
4.1 实验数据及参数设置
新浪微博是在国内使用人数最多、最受欢迎的微博,用户可以标示自己的兴趣爱好、添加好友、关注主题等。本文实验使用新浪微博API抓取用户的标签信息,用户的微博以及每条微博的交互信息,如:评论,转发,赞。从8个不同的领域选取一些用户作为目标用户,采用广度优先的算法,抓取了2万个用户从2013年10月16日-2014年1月16日的数据。为了提高实验算法的准确性,首先对数据进行清洗:
(1)排除粉丝数超过10万但好友人数小于500的用户。这类用户通常是非常出名的用户,这些用户的微博有大量粉丝的转发、评论,但是鲜有互动,因此本文暂不考虑这类用户。
(2)排除粉丝数少于10且微博数少于10的用户。这些用户粉丝和微博数过少,说明这些用户很少使用微博,因此为他们推荐的意义不大。
经过处理后,得到5 224个用户数据,其中包括266 627条微博,105 583条交互信息。本文采用交叉实验,将数据集划分为80%训练集和20%测试集并进行多次实验以验证本文算法。
当用LDA模型挖掘用户微博的主题时,本文根据文献[17],采用贝叶斯统计中的标准方法对LDA模型的参数进行设置。令α=50/T,T是主题数,取T=50,迭代次数为100次。该设置为经验值,经过多次实验结果表明,这些值在本文数据集上为最佳参数值。
4.2 评价指标
对于实验结果,本文采用准确率(precision)、召回率(recall)、F1度量值(F1-measure)作为衡量标准。
准确率是推荐列表中正确推荐个数Nrt与推荐总数Nr之比,其值越高说明推荐准确率越大。
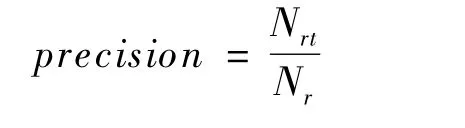
召回率是推荐列表中正确推荐个数Nrt与用户总的好友个数Nf之比,值越高表示推荐效果越好。
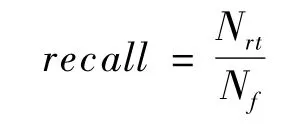
F1度量值(F1-measure)是准确率和召回率的加权调和平均,它综合了准确率和召回率的结果。F1度量值越高说明推荐效果越好。
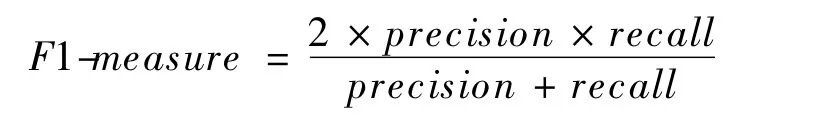
在本文实验中,取不同推荐个数(N=2,4,6,8,10)进行对比。
4.3 结果分析
本文针对基于内容的推荐算法、基于社会过滤的推荐算法[18]和基于多因素分类的推荐算法(本文算法)分别进行实验并进行对比。当N取不同值时3种算法的准确率、召回率、F1度量值分别如图5~图7所示。

图5 算法准确率对比
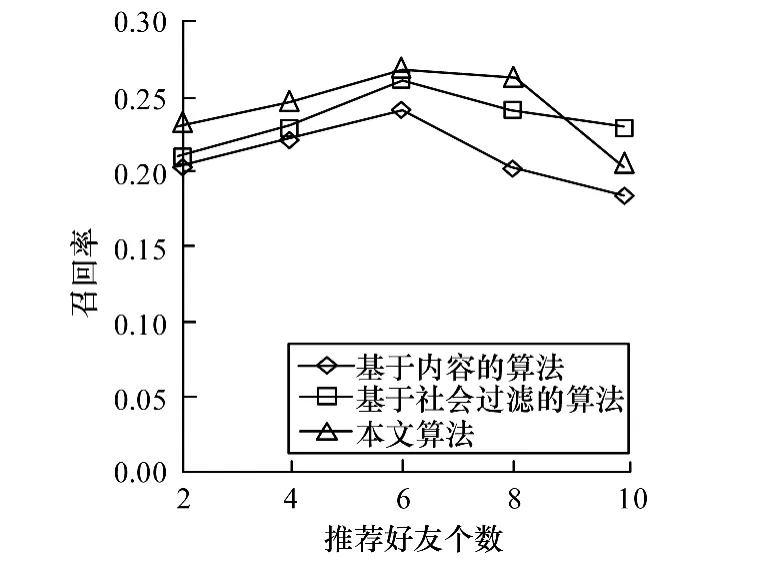
图6 算法召回率对比
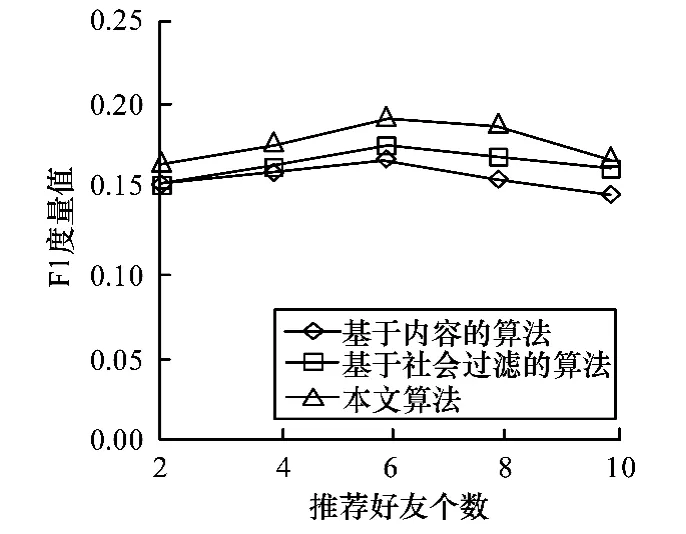
图7 算法F1度量值对比
当N≤4时,基于内容的算法准确率高于基于社会过滤的推荐算法的准确率,而随着N的增大,基于内容的算法准确率低于基于社会过滤的算法,它是这3种算法中准确率最低的,本文算法准确率最高。当N=4时,本文算法准确率达到最高的16.5%。
在召回率方面,当N<10时,基于多特征分类的算法的召回率最高,基于社会过滤的算法次之,基于内容的算法最低。当N=10时,本文算法召回率最低。当N=6时,本文算法的召回率达到了最高的26.8%。
从F1度量值方面,本文算法的推荐效果最好,而基于内容的算法推荐效果最差。一方面可能是因为微博内容简短,而且内容中存在大量符号、表情、缩写等,导致效果不好;另一方面,本文算法综合考虑了用户的主题相似度、标签相似度和用户间的亲密度,利用更多的特征,所以取得了较好的推荐效果。而本文算法效果好于基于社会过滤的算法效果,是因为本文在计算用户亲密度时已经隐含利用用户的社交网络信息,而且还进一步利用用户的主题相似度和标签相似度来提高推荐效果。当N=6时,本文算法的F1度量值达到最高的19.2%。
综上所述,本文提出的基于多特征分类的推荐算法要优于其他推荐算法。
5 结束语
本文总结影响微博用户推荐的4类信息,并提出如何使用这些信息的方法,通过在新浪微博数据集上进行实验,结果表明本文提出的基于多特征分类的推荐算法能有效为用户进行好友推荐,但其对于新用户,由于缺少用户内容信息、交互信息和社交拓扑信息,因此退化为类似基于标签的推荐算法,推荐效果不理想。在今后工作中,将研究使用微博用户的其他信息进行好友推荐,如用户的影响力、传播范围等,进一步改善推荐效果。
[1] 李克潮,梁正友.基于多特征的个性化图书推荐算法[J].计算机工程,2012,38(11):34-37.
[2] Piao S,Whittle J.A Feasibility Study on Extracting Twitter Users’Interests Using NLP Tools for Serendipitous Connections[C]//Proceedings of the 3rd International Conference on Privacy,Security,Risk and Trust and the 3rd International Conference on Social Computing.Washington D.C.,USA:IEEE Press,2011:910-915.
[3] Chen J,Geyer W,Duguan C,et al.Make New Friends,But Keep the Old:Recommending People on Social Networking Sites[C]//Proceedings of SIGCHI Conference on Human Factors in Computing Systems.New York,USA:ACM Press,2009:201-210.
[4] Hannon J,Bennett M,Smyth B.Recommending Twitter Usersto Follow Using Contentand Collaborative Filtering Approaches[C]//Proceedings of the 4th ACM Conference on Recommender Systems.New York,USA:ACM Press,2010:199-206.
[5] Jamali M,Ester M.A Matrix Factorization Technique with Trust Propagation for Recommendation in Social Networks[C]//Proceedings of the 4th ACM Conference on Recommender Systems.New York,USA:ACM Press,2010:135-142.
[6] Lo S,Lin C.WMR——A Graph-based Algorithm for Friend Recommendation[C]//Proceedingsof2006 IEEE/WIC/ACM InternationalConferenceonWeb Intelligence.Piscataway,USA:IEEE Computer Society,2006:121-128.
[7] Blei D M,Ng A Y,Jordan M I.LatentDirichlet Allocation[J].Journal of Machine Learning Research,2003,(3):993-1022.
[8] Zeng Jianping,Zhang Shiyong.Variable Space Hidden Markov Model for Topic Detection and Analysis[J].Knowledge-based Systems,2007,20(7):607-613.
[9] Zeng Jianping,Duan Jiangjiao,Wang Wei,etal.Semantic Multi-grain Mixture Topic Model for Text Analysis[J].Expert Systems with Applications,2011,38(4):3574-3579.
[10] Titov I,McDonald R.ModelingOnline Reviews with Multigrain Topic Models[C]//Proceedings ofthe17th International Conference on World Wide Web.New York,USA:ACM Press,2008:111-120.
[11] Duan J,Zeng J.Web Objectionable TextContent Detection Using Topic Modeling Technique[J].Expert Systems with Applications,2013,40(15):6094-6104.
[12] Denecke K,Brosowski M.TopicDetection in Noisy Data Sources[C]//Proceedings of the 15th International Conference on Digital Information Management.Piscataway,USA:IEEE Press,2010:50-55.
[13] Guy I,Zwerdling N,Carmel D,et al.Person-alized Recommendation of Social Software Items Based on Social Relations[C]//Proceedings of the 3rd ACM Conference on Recommender Systems.New York,USA:ACM Press,2009:53-60.
[14] Milgram S.TheSmall World Problem[J].Psychology Today,1967,2(1):60-67.
[15] Zhou T C,Ma H,Lyu M R,et al.UserRec:A User Recommendation Framework in Social Tagging Systems[C]//Proceedings of the 24th AAAI Conference on Artificial Intelligence.Palo Alto,USA:AAAI Press,2010.
[16] Koga H,Taniguchi T.Developing aUser Recommendation Engine on Twitter Using Estimated Latent Topics[M]//Jacko J A.Human-computer Interaction.Design and Development Approaches.Berlin,Germany:Springer,2011:461-470.
[17] Weng J,Lim E P,Jiang J,et al.Twitterrank:Finding Topic-sensitive Influential Twitterers[C]//Proceedings of the 3rd ACM International Conference on Web Search And Data Mining.New York,USA:ACM Press,2010:261-270.
[18] 高永兵,杨红磊,刘春祥,等.基于内容与社会过滤的好友推荐算法研究[J].微型机与应用,2013,32(14):75-78.
