基于特征分析的微博炒作账户识别方法
2015-01-02罗军勇董雨辰
张 进,刘 琰,罗军勇,董雨辰
(数学工程与先进计算国家重点实验室,郑州450002)
1 概述
随着移动通信和Web技术的不断突破,以微博为代表的在线社交网络迅速发展起来。与传统的社交网络相比,微博具有更强的信息传播能力和成员组织能力,这一独特优势使其迅速成为当前主要社会媒体之一[1]。然而,由于微博的技术门槛比较低,信息真实性无法保证,使得近年来出现一些炒作账户采用违规手段开展网络公关活动,谋取非法利益,甚至恶意制造热点事件,煽动网民情绪,挟制舆论导向,严重干扰正常的互联网秩序。从“3Q大战”到“凉茶之争”,这些轰动一时的微博热门事件都有炒作账户参与的痕迹。
传统炒作账户识别方法通常依靠人工查找、分析样本数据特征的方式,这种方式效率低下而且成本高昂,不适合对海量账户进行分析[2]。此外,随着炒作账户力量的不断壮大,炒作账户进行微博炒作的形式呈现出多样化的趋势,具有较强的组织性和隐蔽性,传统识别方法很难将炒作账户和正常账户区分开。因此,如何准确、高效地从海量账户中识别出具有炒作嫌疑的账户,成为目前亟待解决的问题。
本文以微博中的炒作账户为研究对象,针对炒作账户隐蔽性高、难以识别的问题,提出一种基于特征分析的炒作账户识别方法。该方法从多个方面对炒作账户的特征进行分析,构建原始特征集,利用特征选择技术从原始特征集中筛选出具有显著判别能力的特征子集,并使用多种分类算法对本文方法的识别效果进行评估。
2 相关工作
目前国内外对炒作账户的研究尚处于起步阶段,相关工作主要有对垃圾账户(spammer)、马甲账户(sockpuppet)、僵尸账户(zombies)等微博不良账户的识别方法研究,这些不良账户与本文研究的炒作账户具有一定的相似性。
垃圾账户是指经常发布垃圾信息的账户。文献[3]从多个角度分析了垃圾账户的特征,并采用机器学习的方式自动识别垃圾账户。文献[4]深入分析了垃圾账户间的社会关系,提出一种根据账户间亲密度来发现垃圾账户的方法。文献[5]提出一种基于统计特征与双向投票的垃圾账户识别算法,利用账户信任的双向传播与其邻居节点的统计特征来发现微博中的垃圾账户。文献[6]利用账户和微博特征设计分类器并对正常账户和垃圾账户进行区分。文献[7]利用Twitter中的暂停账号分析了垃圾账户的特性。
马甲账户是指通过注册多个账号进行发帖、转发、评论等行为的虚假账户。文献[8]结合作者身份识别以及链接分析技术来检测马甲账户。文献[9]提出一种利用文本内容、相似度匹配来识别马甲账户的方法,实验结果表明具有较高的准确率。
僵尸账户是指为了进行粉丝买卖而恶意注册的账户。文献[10]在Twitter中综合考虑了账户发帖行为、博文内容和账户属性等特征,并利用机器学习的方法来识别僵尸账户。文献[11]提出一种基于微博注册账户名特征提取的智能分类方法,利用支持向量机和人工神经网络方法对账户进行分类。
综上所述,目前对不良账户识别方法的研究取得了一定的成果,但是识别方法相对单一,而且通常只针对特定的账户群体,尚未有专门面向炒作账户的识别方法。本文研究的炒作账户也属于微博中不良账户的范畴,与以上3类不良账户相比,炒作账户更加侧重于其“炒作”行为,隐蔽性和组织性比较强,也更加难以发现。
3 炒作账户相关概念与识别框架
3.1 相关概念
为有效发现微博中的炒作账户,以下给出了本文对炒作账户相关概念的界定。
定义1(炒作) 为扩大事物或人的影响而通过媒体进行反复宣传的行为。炒作的最终目的是让事件或人物达到轰动性的社会效应,以实现利益的最大化,其常见的表现形式有话题炒作、营销炒作、人物炒作等。
定义2(炒作账户) 在微博平台上从事炒作行为的账户,往往通过虚假转发、评论等行为进行宣传造势,以实现对话题、人物或产品炒作等目的。炒作账户大多受雇于网络公关公司,通过炒作来获取利益。
3.2 炒作账户识别框架
本文借鉴了数据挖掘中的分类[12]思想,并结合炒作账户的研究背景,提出微博炒作账户识别框架,该框架结构如图1所示。

图1 炒作账户识别框架
从图1可以看出,该框架主要分为3个部分:特征分析,特征选择以及分类判决。
(1)特征分析。分别从账户状态、历史微博以及账户邻居3个方面对炒作账户的特征进行分析,并构建账户特征集。
(2)特征选择。在得到账户特征集后,利用特征选择技术筛选出具有较强判别能力的特征子集,以提高识别的效率和准确率。
(3)分类判决。选择适当的分类器判断账户是否具有炒作嫌疑,同时对识别方法的性能进行评估。
4 炒作账户特征分析
由于炒作账户经常参与一些炒作任务,因此在账户特征上会与正常账户存在差异。通过研究发现,微博平台上与账户相关的信息主要包括基本资料、历史微博、好友关系、个人兴趣等。为尽可能全面地发现炒作账户与正常账户的区别,本文充分利用能够获取到的账户信息,分别从账户状态、历史微博以及账户邻居3个方面对炒作账户进行分析,构建炒作账户的特征集。
4.1 账户状态特征
账户状态特征来源于账户基本资料,反映了账户的基本状态,包括账户粉丝数、关注数、互粉数、微博数、账户等级、账户年龄等。虽然炒作模式多种多样,但绝大多数炒作账户具有相似的特征,而且与正常账户的差异较为明显。
由于炒作账户经常发布一些具有炒作性质的虚假、营销类信息,因此吸引的粉丝数往往低于正常账户。为避免因粉丝太少而降低影响力,大多数炒作账户会通过随机批量关注其他账户的方法获取回粉,导致其关注数一般高于正常账户。另外,一些炒作账户很可能被正常账户举报而被运营商封号,为此不得不重新注册新的账户,因此炒作账户等级一般较低,账户年龄比较小。
为进一步反映炒作账户与正常账户的区别,本文利用账户的基本状态构造2项新的特征——声望值和互粉率,具体定义如下:
定义3(声望值) 利用粉丝数与关注数的相对大小表示,能够反映账户的人气或声望。一般情况下,炒作账户的声望值要低于正常账户。
定义4(互粉率) 利用互粉数与关注数之比表示,反映账户的人气,间接反映与好友的亲密程度。一般情况下,炒作账户的互粉率要低于正常账户。
图2为炒作账户和正常账户部分状态特征的累积分布函数(Cumulative Distribution Function,CDF)曲线。
从图2(a)可以看出,80%左右的炒作账户关注数超过800,而80%左右的正常账户关注数低于300;从图2(b)可以看出,炒作账户的互粉率一般低于正常账户;从图2(c)可以看出,大约80%的炒作账户年龄在1年之内,而80%左右的正常账户年龄在500 d以上;从图2(d)可以看出,绝大多数正常账户的声望值要高于炒作账户。

图2 炒作账户和正常账户状态特征CDF曲线
4.2 历史微博特征
历史微博特征是指从账户发布或转发的历史微博中提取的特征,能够反映账户使用微博的个人习惯以及发布微博的质量,主要包括发布微博频率、原创微博比例、垃圾转发比例以及微博平均被转发数和被评论数等。
通过对大量数据的观察发现,炒作账户往往发布微博的频率高于正常账户,一方面是为了避免因活跃度太低而被判定为僵尸账号,另一方面是因为要不定期地完成一些炒作任务。另外,微博运营商会利用垃圾信息监测机制删除一些垃圾信息,而炒作账户转发的炒作微博很可能被判定为垃圾微博,所以,垃圾转发比例要高于正常账户。同时,为躲避这种垃圾信息监测机制,炒作账户也会经常转发其它微博,但很少直接发布一些反映个人意愿的原创微博,因此,原创微博比例略低于正常账户。此外,由于炒作账户经常发布或转发一些具有炒作、营销性质的微博,很难从内容上吸引正常账户进行再次转发或评论,因此炒作账户的微博平均被转发数和被评论数较小。
图3为炒作账户和正常账户部分微博特征的CDF曲线图。从图3(a)可以看出,大约有80%的炒作账户微博平均被评论次数低于0.02,而80%以上的正常账户历史微博平均被评论次数高于0.1。从图3(b)可以看出,绝大多数炒作账户微博平均被转发次数要低于正常账户。从图3(c)可以看出,大部分炒作账户的发布微博频率要高于正常账户。从图3(d)可以看出,大约90%的炒作账户原创微博比例低于10%,而80%以上的正常账户原创微博比例高于20%。

图3 炒作账户和正常账户历史微博特征CDF曲线
4.3 账户邻居特征
账户邻居特征是一系列描述账户粉丝及关注好友特征的指标,把账户的粉丝及关注好友称为“邻居”。这些特征能够从不同角度反映账户的粉丝质量以及关注质量,也间接反映了该账户的特性,主要包括邻居的平均粉丝数、平均关注数、平均互粉数、平均声望值等。
相关研究发现[13],炒作账户的关注行为具有一定的随机性,而正常账户则更倾向于关注自己的亲朋好友或名人、媒体,这就导致炒作账户关注好友的质量一般低于正常账户。另一方面,炒作账户的粉丝中包含了大量的僵尸粉或其他炒作账户,而正常账户的粉丝大多来自真实的社交圈或是对自己感兴趣的正常账户,因此,两者的粉丝质量也有高低之分。
图4为炒作账户和正常账户部分邻居特征的CDF曲线图。从图4(a)可以看出,大约80%以上的炒作账户关注好友的平均粉丝数不足1×104,而80%以上的正常账户关注好友的平均粉丝数高于1×106;从图4(b)可以看出,绝大多数炒作账户关注好友的平均互粉数要低于正常账户。以上2图说明炒作账户关注好友的质量要低于正常账户。另外,从图4(c)和4(d)可以看出,炒作账户的粉丝质量一般低于正常账户,但是这种差异相对较小,在实际分类中可能效果欠佳。
综上所述,分别从账户状态、历史微博以及账户邻居3个角度出发,共选取了21个特征来构建账户特征集。需要说明的是,所有特征的取值范围可能分布很大,例如账户粉丝数的最大值可以达到上千万,而最小值可以低于10,这将对分类的准确率造成影响。
为此,本文采用幂率压缩的方式对一些取值范围较大的特征进行归一化。具体方法为:对于特征F,其归一化后的值为F'=lg(F+1)。

图4 炒作账户和正常账户邻居特征CDF曲线
从账户状态、历史微博以及账户邻居选取的21个特征具体如下:
(1)账户状态属性,包含以下特征:
1)粉丝数,F1=Ner(u),其中,Ner(u)为账户粉丝数;
2)关注数,F2=Nee(u),其中,Nee(u)为账户关注数;
3)互粉数,F3=Nbi(u),其中,Nbi(u)为账户互粉数;
4)微博数,F4=Ns(u),其中,Ns(u)为账户微博数;
5)账户年龄,F5=Age(u),其中,Age(u)为账户年龄;
6)账户等级,F6=Rank(u),其中,Rank(u)为账户等级;


5 实验结果及分析
5.1 数据集
本文以国内最大的新浪微博作为实验平台,利用新浪开放的API接口,并结合网络爬虫来获取相关数据。这些数据主要包括账户基本资料、历史微博信息、好友关系(关注及粉丝列表),分别将这些数据存储到数据库的相应表中。本文只采集了账户的前200条微博和社会关系,一方面是为降低时间和空间开销,另一方面是因为相关研究[6]表明,账户的部分历史数据在一定程度上可以判定账户是否具有炒作嫌疑。
由于目前尚没有标准的炒作账户数据集,本文采用人工标注的方式对实验所需的数据集进行构建。另外,标注数据集需满足以下3个条件:(1)数据集要有一定的规模,而且炒作账户与正常账户的比例尽量符合真实情况;(2)尽量将炒作嫌疑较大、影响微博正常传播的账户标注为炒作账户;(3)在进行标注时尽可能避免人为主观因素造成的影响。
为满足以上3个条件,本文从2013年6月-2014年1月期间的3个不同话题中随机选择账户进行标注,这3个话题分别为:(1)“3Q大战”;(2)“凉茶之争”;(3)某减肥产品广告。经研究发现,以上3个话题中均有炒作账户参与的痕迹。为避免认为主观因素造成的影响,对每个账户均由2个人进行标注,当且仅当标注结果一致时才将该账户存储到数据集中。最终对7 648个账户进行了标注,其中有6 687个正常账户,961个炒作账户。此外,采集到这些账户的历史微博数目为1 315 453,好友关系数目为2 417 387。在后续实验中,本文将采用交叉验证的方式交替地将标注好的数据集作为训练集和测试集。
5.2 特征子集筛选
在对炒作账户识别方法进行评估前,本文首先在WEKA[14]实验平台上,利用其内嵌的特征选择算法,从原始特征集中筛选出特征子集,然后分别利用原始特征集和特征子集对方法效果进行评估。
本文选用WEKA中的2种算法进行特征选择,分别为 ChiSquaredAttributeEval和 InfoGainAttributeEval,前者根据每一个特征的卡方值进行评估,后者根据每一个特征的信息增益进行评估。
实验结果发现,利用以上2种特征选择算法得到的特征子集是基本一致的,只是对个别特征的重要性排序稍有不同。表1为利用信息增益方法得到的特征子集列表。

表1 微博账户特征子集
从表1可以发现,账户关注好友的质量最能体现炒作账户和正常账户之间的区别,其次为反映账户状态和微博质量的特征,而较难从账户粉丝质量和发布微博的个人习惯上区分炒作账户和正常账户。
5.3 评价指标
为评估炒作账户识别效果的优劣,本文利用常用的分类模型评估指标对算法性能进行评估。表2为炒作账户识别结果的混淆矩阵。
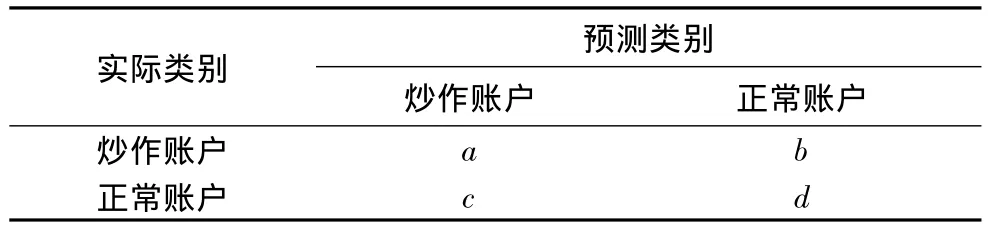
表2 炒作账户识别结果混淆矩阵
常用评价指标主要包括:准确率(P),召回率(R),误报率(FP)以及F1度量值(F1),计算公式如下:
(1)准确率:

(2)召回率:

(3)误报率:

(4)F1度量值:

5.4 结果分析
为评估筛选后特征子集的判别能力,本文在WEKA实验平台上,分别利用原始特征集和特征子集对分类模型进行评估,选用4种常用的分类算法:朴素贝叶斯(Na ve Bayes,NB),随机森林(Random Forest,RF),支持向量机(Support Vector Machine,SVM)以及 K 最近邻(K Nearest Neighbor,KNN)分类算法[15]。在进行评估时,采用10折交叉验证的方式,并依据4个常用的评价指标综合比较分类器的性能。实验结果如图5所示。

图5 不同分类算法在2种特征集下的性能对比
从图5可以看出,将筛选出的特征子集应用于4种分类器的评估效果要明显优于原始特征集,说明本文的特征选择方法是有效的。其中,支持向量机分类器(SVM)的分类效果最好,准确率可达到95%,而且误报率只有0.9%。
综上所述,本文提出的基于特征分析的炒作账户识别方法能有效发现微博中的炒作账户,具有较高的准确率。同时,与传统的人工识别方式相比,本文方法能高效地解决炒作账户识别问题,为网络违规行为取证提供了可靠依据。
6 结束语
本文对微博中的炒作账户进行深入研究,提出一种基于特征分析的炒作账户识别方法。该方法从3个方面对账户特征进行提取,并利用特征选择技术从原始特征集中筛选出具有显著判别能力的特征子集,最后在多种分类器上对识别效果进行评估。实验结果表明,本文方法能有效识别出微博中的炒作账户,其中支持向量机分类算法效果最好,准确率高达95%。目前对炒作账户的研究尚处于起步阶段,下一阶段的工作主要包括:(1)充分考虑炒作账户参与微博炒作的时间特征、发布内容特征以及情感特征等,以发现更隐蔽的炒作账户;(2)进一步研究炒作账户间的组织架构,对重点炒作账户进行监管。
[1] Kwak H,Lee C,Parket H,et al.What Is Twitter,A Social Network or a News Media[C]//Proceedings of the 19th International Conference on World Wide Web.New York,USA:ACM Press,2010:591-600.
[2] 陈 昱,张慧琳.社会计算在信息安全中的应用[J].清华大学学报:自然科学版,2011,51(10):1323-1328.
[3] Zhou Yi,Chen Kai,Song Li,et al.Feature Analysis of Spammers in Social Networks with Active Honeypots:A Case Study of Chinese Microblogging Networks[C]//Proceedings of the International Conference on Advances in Social Networks Analysis and Mining.Washington D.C.,USA:IEEE Press,2012:728-729.
[4] Yang C,Harkreader R,Zhang J.Analyzing Spammer’s Social Networks for Fun and Profit[C]//Proceedings of the 21th International Conference on World Wide Web.New York,USA:ACM Press,2012:71-80.
[5] 丁兆云,周 斌,贾 焰,等.微博中基于统计特征与双向投票的垃圾用户发现[J].计算机研究与发展,2013,50(11):2336-2348.
[6] McCord M,Chuah M.Spam Detection on Twitter Using Traditional Classifiers[C]//Proceedings ofthe 8th International Conference on Autonomic and Trusted Computing.Piscataway,USA:IEEE Press,2011:175-186.
[7] Thomas K,GrierC,Paxson V,etal.Suspended Accounts in Retrospect:An Analysis of Twitter Spam[C]//Proceedings of the 11th ACM SIGCOMM International Conference on Internet Measurement Conference.New York,USA:ACM Press,2011:243-258.
[8] Bu Zhan,Xia Zhengyou,Wang Jiandong.A SockPuppet Detection Algorithm on Virtual Spaces[J].Knowledgebased Systems,2013,37:366-377.
[9] Zheng Xueling,Lai Yiu Ming,Chow K P,et al.Sockpuppet Detection in Online Discussion Forums[C]//Proceedings ofthe 7th International Conference on Intelligent Information Hiding and Multimedia Signal Processing.Washington D.C.,USA:IEEE Press,2011:374-377.
[10] Chu Zi,Gianvecchio S,Wang Haining,et al.Who Is Tweeting on Twitter:Human,Bot,or Cyborg[C]//Proceedings ofthe 26th Annual Computer Security Applications Conference.New York,USA:ACM Press,2010:21-30.
[11] 方 明,方 易.一种新型智能僵尸粉甄别方法[J].计算机工程,2013,39(4):190-193,198.
[12] 韩家炜.数据挖掘:概念与技术[M].3版.北京:机械工业出版社,2012.
[13] Hofman J M,Winter A.Who Says What to Whom on Twitter[C]//Proceedingsofthe 20th International Conference on World Wide Web.New York,USA:ACM Press,2011:705-714.
[14] Hall M,Frank E,Holmes G,et al.The WEKA Data Mining Software:An Update[J].SIGKDD Explorations,2009,11(1):10-18.
[15] Tan P,Steinbach M,Kumar V.数据挖掘导论(完整版)[M].范 明,范宏建,译.北京:人民邮电出版社,2011.
