基于Matlab的英语语音自动评价方法研究
2014-12-11孙艺璇
孙艺璇
(南京邮电大学,江苏 南京 210046)
0 引言
语音识别技术自1952 年起至今经历了几十年的发展历史,从识别10 个英文单词开始到现在能够建立一个完整的语音识别系统。近年来人们的研究思路和研究框架也在不断发生变化,从模式匹配转到统计模型,识别的成功率也在不断的提高,对于非特定人的孤立词和小词汇量的识别成功率现已达到98%。虽然现今语音识别技术还不能完全模拟出人的发声系统,还需要随着不同的语音识别系统改变发音方式,但是人类在未来一定会建立一个非常完善的语音识别系统。
1 现有语音识别方法存在的缺陷
语音特征提取是语音识别的第一步,目前语音特征提取的方法一般有线性预测编码系数LPC 参数,Mel 频域倒谱系数MFCC 及小波变换系数分析法等。虽然它们有很多优点,但也存在一些不足之处。例如,对辅音描述能力较差,在有噪环境下以及频谱失真环境下的表现糟糕,多次用到FFT 导致算法复杂度提高等。
2 对语音特征的提取
下面给出“help the local economy”标准英音的语音信号,运用15 个语音特征分别进行分析。
2.1 预处理
预处理也被称为前段处理,是在语言信号被读取之后首先进行的步骤,放在语音特征的提取之前,能够放大语音信号中的有效成分,提高语音识别的精确程度。预处理主要包括预加重,加窗分帧3 个部分。
2.2 预加重
预加重能够去除口腔等人体部分对于语音高频部分的压制和削弱作用,通过对语音信号施加一个高通滤波器,文章分别尝试了IIR 以及FIR 滤波器,用以抵消口腔对于语音高音部分的压制。公式为:

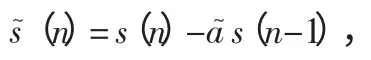
文章尝试对对语音信号作用IIR 以及FIR 滤波器来实现语音信号的预加重。
2.3 分帧
因为语音数据内容过大,将语音所有的采样点作为输入是不合适的,这样不仅计算量大,无法体现语音过程短时变化特点,而且只有等到整段语音接收结束后才能开始对语音进行识别,不能实时流处理。所以分帧技术的应用是必要的,将语音信号分割成较小的等长的语音片段,并近似认为语音内部音频信息稳定。通过分帧,既能保有语音的局部特征,还能够找到帧与帧之间的联系。计算机的采样频率为44100Hz,实验中选取语音帧长为32ms,帧移为16ms。在Matlab 中用y=enframe(x,framelength,step)进行分帧,每帧长framelength,分得的帧数是nf=fix((nx-framelength+step)/step);其中nx 是x 的长度。y 是framelength×nf 或nf×framelength 的数组,取决于x 是列数据还是行数据。
2.4 加窗
在信号处理中,加窗处理是不可避免的,因为我们难以对无限长的序列进行测量和运算,因此原始信号需要被采样时间截断,实现信号长度的有限化。然后用截断后的信号进行周期延拓,形成一个虚拟的无限长信号,再进行相关分析。但是这些被截断的信号会发生频谱畸变,即频谱能量泄露。为了减少这种频谱能量的泄露,我们就需要采用不同的截取函数来对信号进行截断,这些截断函数,就被我们称为窗函数。常用的窗函数有矩形窗,三角窗,汉宁窗,指数窗等。在文章中主要选择了2种有代表性窗函数对信号进行处理,能够精确读出主瓣宽度,主瓣宽度窄且利于分辨的矩形窗和分析窄带信号,旁瓣幅度较小的汉宁窗。
2.5 短时谱
短时谱在语音信号增强方面有着广泛的应用,方法简单,使用信噪比范围较大,并且适用于实时处理。
2.6 加矩形窗的倒谱与复倒谱
很多时候,在知道信号之后,我们需要反过来求解声门信号或者声道冲击响应。这就需要在知道卷积的情况下,利用“解卷”来求得参与卷积的各个信号。同态处理就是一种常用的解卷方法,语音信号在进行同态分析后得到语音信号的倒谱参数。卷积同态处理的基本思路就是运用Z 变换将卷积变为乘积,在取对数运算过后,由乘积变为加法运算。表达如下:
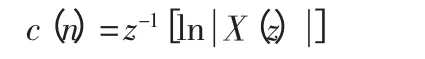
而复倒谱就是由信号的Z 变换取对数运算之后的逆Z 变换,表达如下:
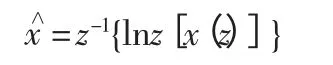
在文章中运用了矩形窗和汉明窗求取信号的倒谱域复倒谱。
2.7 短时能量
短时能量:语音信号的能量随时间变化,清音与浊音之间的能量变化十分明显。因此对语音的短时能量进行分析,同时可以描述语音的短时变化特征。定义短时能量为:

2.8 过零率
过零率:过零率可以粗略估计语音信号的频谱特性。当离散时间相邻两个样点的正负号相异时,被称之为“过零”。统计单位时间内样点值改变符号的次数即可以得到平均过零率。定义短时平均过零率:

2.9 短时平均幅度
短时能量因为计算时用的是信号的平方,所以它对信号高电平十分敏感。因此,采用另外一个度量语音幅度变化值得函数,它与短时平均能量的 区别在于在取样时,小取样值与大取样值不会因为平方而造成较大差异。短时平均幅度函数:

2.10 语音端点
所谓的语音端点检测就是想找出语音的起始点与终止点,能够减少计算量以及提高语音识别的精确度。同时在一定程度上,能够避免噪音干扰。文章采用双门限的方法来进行语音端点检测,其重点是综合利用语音的短时能量以及短时过零率两个特征。先利用语音短时能量来制定一个较高的门限。然后用噪音的能量在制定一个较低的门限,这就完成了初级的语音端点的检测。然后开始再一轮的语音端点检测,由于语音很有可能由能量很弱的清音开始,所以需要运用过零率来设置一个新的较低的门槛。这就基本完成了语音的端点检测。
将语音端点的位置表示出来,即:
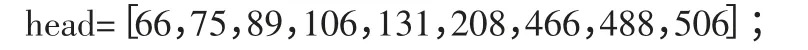
2.11 短时自相关
自相关函数用来测量语音信号自身时间波形的相似性。由于清浊音发音机制的不同,因此在波形上存在这较大的差异。浊音在波形上存在着一定的周期性,波形之间相似性较好,而清音在时间波形上则存在随机噪音的特性,样点间的相似性较差。自相关函数表示为:
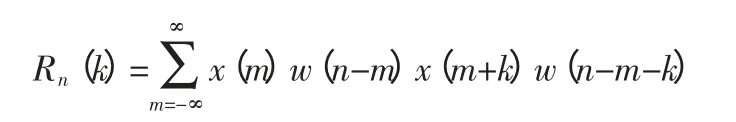
2.12 持续时间
发音持续时间的长短主要决定了声音的长短,也成为音长。
实验结果:T=1.1916
2.13 语谱图
语谱图反应了语音信号的动态频率特性。水平方向是时间轴,竖直方向是频率轴,图上的变化的纹路代表了不同时刻的语音短时谱。语谱图由于其不同的灰度,形成不同的纹路,被称为“声纹”。
2.14 基音周期
声音是由发音体经过一系列震动产生的,在这个过程中,频率和振幅各不相同。在这些振动中,由频率最低的振动发出的音就成为基音,它决定着音高。
人在发出浊音时,产生一股准周期脉冲气流,刺激声道后就产生浊音,又称有声语言,它携带着语音中的大部分能量,这种声带振动的频率成称为基频,相应的周期就被称为基音周期。它由声带逐渐开启到面积最大,逐渐关闭至完全闭合,完全闭合3 部分组成。文章采用自相关法来进行语音的基音周期检测。
2.15 共振峰
共振峰是指在声音的频谱上,能量相对集中的一些区域。文章采用线性预测的方法来求得语音信号的共振峰。
在以上提取的15 个语音特征中,每个语音特征的数据表均可表示为一个行矩阵,这也是文章采用的语音识别方法所需要用到的。
详细来说,如果将一段语音的上文提到的所有语音特征都计算出来,每一个语音特征都能够用一个行矩阵来表示。在间隔一定距离对语音特征的行矩阵进行数据提取,同时保证提取到的15 个甚至21 个行向量的容量相同。从上文中的21 个数据表中提取数据或者根据15 个语音特征结果提取数据。数据不足则用0 元素补足。提取一定数量m 的数据组成的新的行矩阵,一定程度上就能够充分代表这段语音的数据。然后将这15 个或21 个特征行向量组成15*m 或21*m 的矩阵。最后在进行语音比对时,我们可以直接将不同语音得到的矩阵直接进行对比。
文章直接采用15 个语音特征的结果来提取标准男声英音信号的数据并构成语音特征15*1000 的矩阵,忽略得到语音特征的中间过程。例如,在获取预加重过程中对语音信号进行的IIR 及FIR 滤波器处理的高通滤波。为了方便显示,截取标准男声英音信号15*1000 特征矩阵的一部分与母语为汉语的女声英音信号15*1000 特征矩阵的一部分进行对比。下一步是需要厘清标准男声英音信号15×1000 特征矩阵部分及母语为汉语的女声英音信号15*1000 特征矩阵的一部分,如表1、表2 所示。
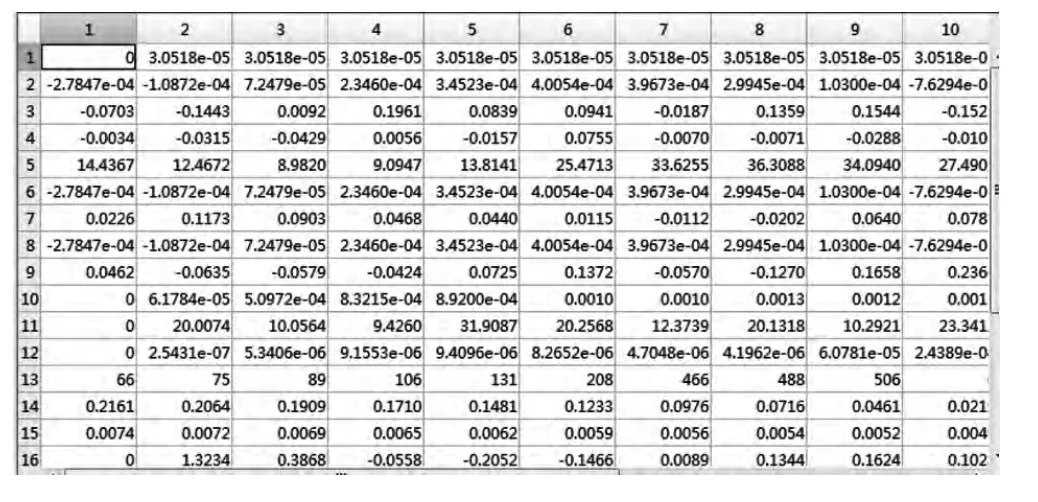
表1 标准男声英音信号15×1000 特征矩阵部分
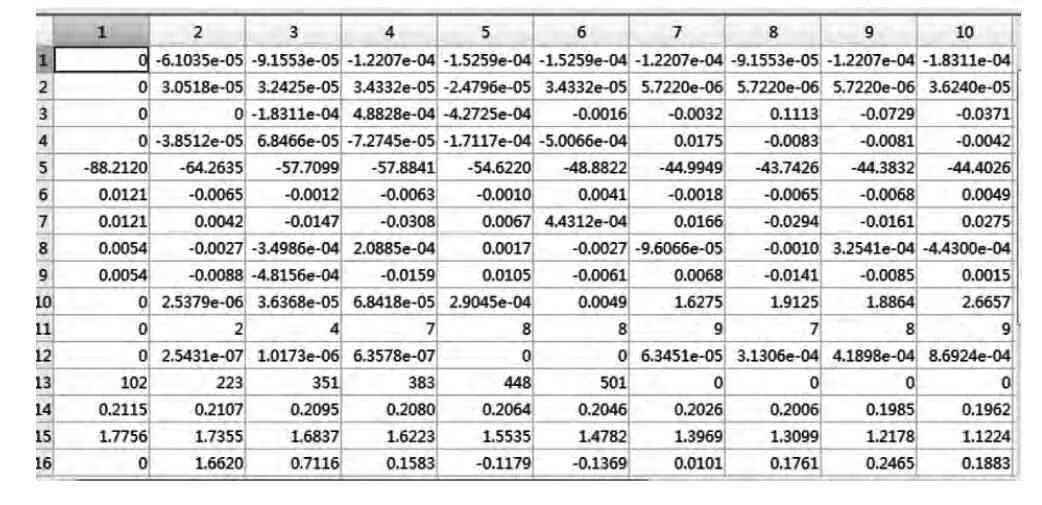
表2 母语为汉语的女声英音信号15*1000 特征矩阵的一部分
经过实验,将男声英音标准语音信号与内容相同但母语为汉语的女声英音信号进行对比,首先对这样的两个语音信号进行特征提取,在经过矩阵的数据对比之后,得到语音内容的相似度为0.96 的结果。下一步是需要厘清男声英音标准语音信号和母语为汉语的女声英音信号,如图1、图2 所示。
文章采用的矩阵对比的方法是Matlab 中自带的求矩阵相似度的corr2 函数,返回值范围在[-1,1]之间,完全相关的两个矩阵返回值为1 或-1,完全不相关的两个矩阵的返回值为0,矩阵相似度越高返回值越接近1。
文章仅对标准男声英音信号与内容相同,均为“help the local economy”,但母语为汉语的女声英音信号进行对比,得到语音识别结果为大概0.96 的相似度。由此能够初步判断2 段语音内容基本相同。这种方法的可行性以及准确度还需要大量的实验来进行验证。这种语音识别技术成熟之后,可以用于英语学习的人群,提供给他们一种纠正英语发音的方式,面对数据可以直观的看到发音需要改进的地方。
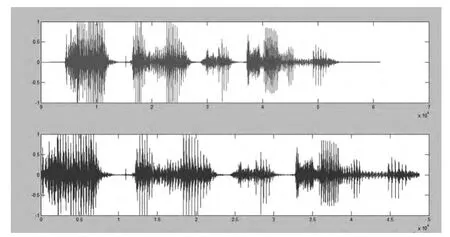
图1 男声英音标准语音信号
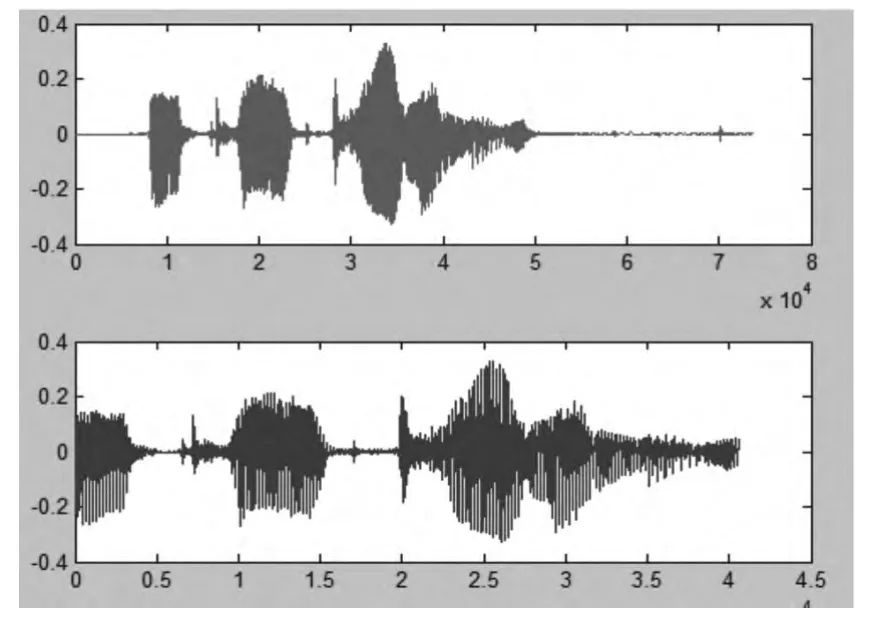
图2 母语为汉语的女声英音信号
3 结论
语音特征矩阵法分析语音信号基本克服了其他几种语音分析方法的不足,因为有足够多的语音特征,即使有些语音不适用于某几种语音特征的提取,还有足够多的其他语音特征可以用于语音之间的相互比对。同时,因为不同语音特征波形图的差别,即使适当缩小每一个语音特征所提取的数据行向量的容量,也能够相对充分的表示一段语音信号,可以在数据库中轻易找到与实验语音相匹配的内容。因此,这种方法复杂度较低,识别效果较好。但矩阵法分析语音信号的不足之处在于还需要更完善的矩阵对比方法,很有可能会由于矩阵对比方法的不足导致语音信号识别的准确度降低。而且一旦需要更细致的对发音相似的语音信号进行识别,就需要注意对语音特征行矩阵的数据提取的足够多来保证语音信号的准确性,这样无疑会增加方法的计算量。
[1]王彪.基于Matlab 的语音识别系统研究[J].计算机与数字工程,2011(12).
[2]阴艳丽.基于MATLAB 语音信号处理的研究[J].中国新技术新成品,2012(12).
[3]奉小慧.音频噪声环境下唇动信息在语音识别中的应用技术研究[D].广州:华南理工大学,2010.
