支持依赖关系的并行任务软件框架研究与实现
2014-12-04李凌
李 凌
(淮北职业技术学院 计算机科学技术系,安徽 淮北 235000)
日益复杂的科学计算、多媒体、虚拟化等应用领域要求强大的计算能力,并行计算可以快速解决复杂的计算问题,同时使用多种资源,克服单个计算机上存在的存储器限制,降低问题的求解时间,增加问题求解规模,提高问题求解精度、吞吐率和可用性[1]。并行计算主要有任务并行和数据并行两种,任务并行依据求解过程,把任务切片分解成若干子任务,[2]旨在提高CPU的利用率。随着CPU核心数的不断增加,计算机的计算能力得到极大提高,从云计算到网格计算,再到桌面计算机系统中各种线程池技术,软件开发需要大步提高以适应计算机系统的发展,并行任务软件设计已经成为一个热点。
一、相关概念
(一)并行任务
一个并行任务可以抽象为一个有向无环图,用四元组表示[3],记为 DAG=(V,E,W,D),其中:V={v1,v2…vn}表示子任务的集合,vi∈V;E={e1,e2…em},E∈V×V,表示有向边的集合,ek=(vm,vn)∈E,表示子任务vm和vn依赖关系,只有当vm执行完成后,vn才能执行;W={w1,w2…wn},任务负载向量集合;D=(dij)m×n,其中dij表示子任务vi和vj的数据通信量。并行任务的DAG图如图1所示。图1是包含10个节点的并行计算任务图,圆圈内的vi表示节点的编号,圆圈旁边的数字是任务节点的计算机量,有向边旁的数字是任务间的数据通信量。
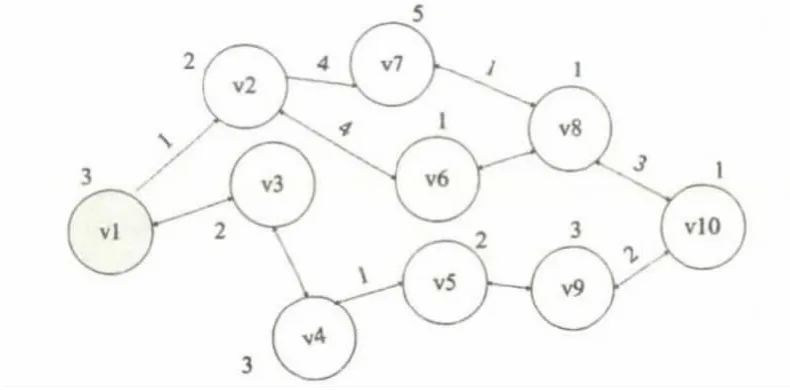
图1 并行任务DAG图
(二)任务间的依赖关系
程序的各个部分之间总是存在一定的依赖关系[4],在不破坏依赖关系的前提下,把程序分解成多个任务并行执行,进而缩短整个程序的运行时间,这就是并行处理。任务之间的依赖关系主要有数据依赖和控制依赖[5]。
1.数据依赖关系
运行的多个任务同时访问相同的数据,即为数据依赖,数据依赖的形式化定义如下:
已知任务S和T,若存在数据X满足如下条件之一,则称任务T数据依赖任务S,记为SδT,否则任务S和T不存在依赖关系。
(1)任务T使用由S计算出的X,且同时x∈OUT(s)∧x∈IN(T),则称T依赖S,记作:SδfT(WAR)
(2)S使用的X先于T对X的定值,且x∈IN(s)∧x∈OUT(T),则称 T反依赖于S,记为:SδaT(WAR)
(3)S对X的定值先于 T对X的定值,且x∈OUT(s)∧x∈OUT(T),则称 T输出依赖于S,记为:Sδ0T(WAR)
2.控制依赖关系
依赖关系是由程序流程引起的,若一个任务是否执行取决于其他任务执行的结果,称这种任务之间的依赖关系为控制依赖。对于有控制依赖的任务,在实际使用中应提供预测方法,一旦预测失误,则必须实现任务回滚机制。控制依赖的形式化定义如下:
已知任务S和T,T控制依赖S,当且仅当:
(1)S和T之间存在一条路径;
(2)存在一条路径S到程序结束但是不经过T。
数据依赖由读、写同一数据引起,控制依赖导致程序流程的变化,数据依赖是影响程序并行化的主要因素[4],本文所说的依赖关系是指数据依赖关系。如何能够在确保依赖关系稳定的情况下最快地计算出最终结果,是现代计算机软件技术发展的重要趋势。本文设计了一种并行框架,可以并行化处理任务,充分利用计算机硬件资源,实验表明可以有效提高并行任务的并行度,提高软件的性能。
二、软件框架
软件框架通常采用分层设计,每一层实现不同的功能,下层为上层提供健壮稳定的服务。在支持依赖关系的并行任务软件框架中,需要解决如下问题:
1)完成任务的执行;2)确保依赖关系中后续任务必须在前置任务之后执行;3)充分利用计算机系统资源,在最短时间内完成运算,提高软件性能的可伸缩性。
假定有相互依赖关系的任务需要运算的对象为一大块(chunk)可切分的数据,本软件框架将解决如何在最短的时间内完成整个运算。整个软件框架分为任务分发和线程执行两层,如图2所示,线程执行层为任务分发层提供任务执行的服务,借鉴操作系统中的多线程库(.NET task库)提供线程能力。
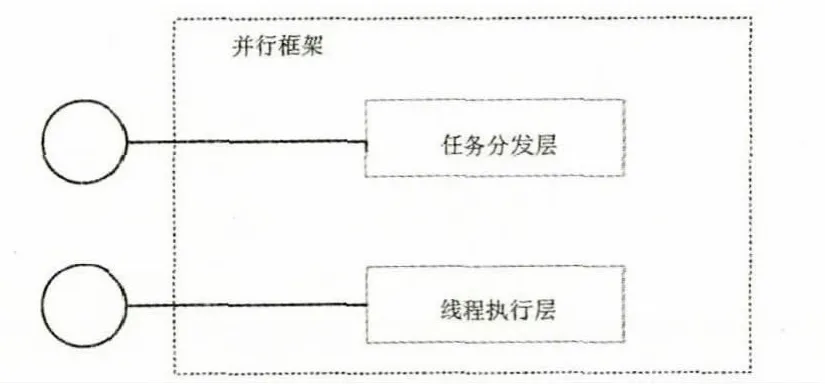
图2 软件框架图
(一)任务分发层(Dispatching Layer)
相互依赖的任务在任务分发层基于数据驱动被切分为相互无关的任务,每个运行于此数据段上的任务定义为子任务,基于任务之间的相互依赖关系,按照顺序生成子任务,把他们分发到线程执行层,执行子任务,每个子任务在生成时都是可运行的。公共大块数据被切分为若干个数据段(Segment),如图3所示,当前置任务完成处理一个数据段之后,相应的后续任务才可以处理该数据段。

图3 块数据切分图
1.模块划分
任务分发层主要有依赖关系图(Topology)、段切分(Partition)和分发器(Task Dispatcher)三个模块构成,如图4所示:

图4 任务分发模块图
(1)依赖关系图模块。依赖关系图模块维护任务之间的相互关系,并在整个运算过程中维护并更新无前置任务或前置任务已经完成的任务列表。依赖关系图模块提供扩展接口,当任务之间的关系同时依赖于任务运算的部分结果时,通过扩展接口,依赖关系图模块可以维护运算过程中动态改变的任务关系。当一个任务的依赖关系被改变时,该任务所有的后置任务在相同的数据段上也应当重新配置依赖关系。这种改变是通过数据驱动的异步通知进行的。只有当后置模块运算到前置任务关系改变的数据段时,才会得到该异步通知。
(2)段切分模块。段切分模块基于具体任务的依赖关系,首先计算出该任务可以运行的所有数据段区间,然后根据不同的算法为该任务动态生成可运行的子任务。为了提高运算性能,算法中可以为轻量级任务生成大数据段,为重量级任务生成小数据段,以达到负载平衡的目的,或者为重量级任务生成多个子任务,提高并行度。
在段切分模块中,为了提高性能,采用一种依赖控制算法来计算一个任务的所有可运行数据段区间。假设依赖关系如图5所示:
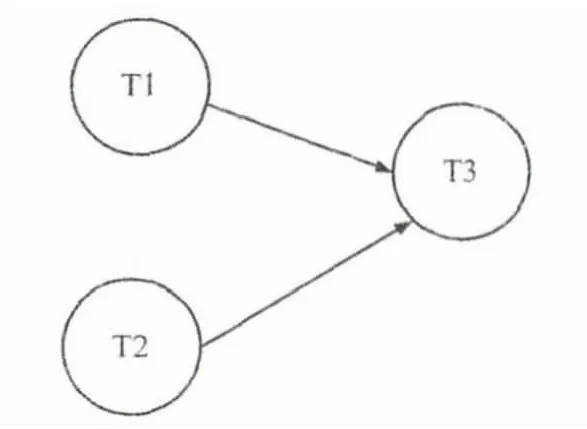
图5 依赖关系图
任务T1已经完成数据段[1,4][6,9]上的运算,任务T2已经完成数据段[2,4]和[5,8]上的运算。该依赖控制算法首先为来自于任务T1和T2的每个数据段的开始位置定义权值1,为每个数据段的结束位置定义权值-1。并对所有的开始和结束位置统一进行排序。然后从所有数据运算的开始位置向结束位置累积权值,最终得到权值如表1所示:

表1 权值表
在累积权值中,若某个数值等于该任务T3的所有依赖任务个数,那么相对应的位置即为可运行数据段的开始位置。从表中可以看到,任务T3的可运行数据段有[2,4]和[6,8]。
该依赖控制算法的前置条件是:同一个任务的所有数据段不允许有相互重叠的部分。因此,如果在切分模块中使用了重试策略,即如果一个数据段运算失败,那么该数据库会重新尝试第二次运行时,在应用依赖控制算法之前,需要对数据段记录进行预处理,去除重叠的部分。段切分模块同样支持算法扩展,如:控制所有子任务在固定时间内完成,以实现负载均衡;或者为重量级任务生成多个子任务实例以提高并发度。
(3)分发器模块。分发器模块负责分发子任务。首先,它从依赖关系图模块中获取无依赖关系的任务,委派段切分模块生成子任务,然后把子任务分发执行,并监听执行的结果;在子任务完成后对相关的任务更新状态,分发对应的后续任务,直至最终所有的任务结束。该模块实现进度的管理,并可根据需要,按照优先级分发不同的任务。表2列出了在分发器中可能的算法实现,针对不同的需求,在分发器中可以采用不同的分发算法。

表2 分发器算法比较
2.工作流程
分发器从依赖关系图模块中获取无依赖关系的任务,段切分模块为这些可执行的任务生成子任务;分发器把这些子任务依据优先级分发到线程执行层,并监听子任务结束事件;当子任务完成后,分发器收到通知;分发器把子任务的运行结果通知给相应的任务以及该任务的后续任务。
图6给出了在任务分发层中任务分发的简要流程:

图6 任务分发流程图
在运算过程中,对数据段的读写涉及大量的I/O操作,为了提高性能,在框架中运用了任务优化的方式。一个任务通常由读取数据段、数据运算和写数据段三个步骤组成。优化后把每个步骤作为一个任务,一个常规任务被优化为有依赖关系的三个任务,并在读取数据段和写数据段任务中采用异步I/O算法提高任务的并行度。
(二)线程执行层
线程执行层实现了计算机系统线程池的接口管理。作为任务分发层和系统线程池之间的中介,该层抽象了子任务的执行接口,因此在总体框架实现之后能够很容易的替换具体的线程池技术,当新技术出现时,采用更合适的新技术替换现有软件中的技术债务,获取新技术带来的好处。
三、原型测试
基于以上并行框架,本文实现了一个简单的原型。该原型使用配置文件来自定义任务的类型及具体算法,在段切分模块中未使用任何优化算法,在分发器中采用前置任务优先的分发算法。在原型测试中,本文使用了Visual Studio中的分析工具,分析运算消耗的时间和CPU的使用率。任务的相互依赖关系如图7所示:

图7 任务的相互依赖关系图
(一)理想状态下的负载测试
在理想状态下,任务中没有I/O操作且任务之间负载均衡,在一台虚拟8核的计算机上,所有核都在满负荷运算,任务的并行度被调度到了最高。
(二)数据量测试
本文测试了在运算不同数据量时,并行框架所消耗时间与顺序执行所有任务时所消耗时间的对比。测试分两次进行,第一次依赖关系图中的所有任务负载均衡,所有任务与计算单独一个数据时消耗的时间相似,并行运算所消耗的时间随数据量的增加线性增加,增长的速度远远小于顺序运算时消耗时间增长的速度,在虚拟8核计算机中,RATIO数值(顺序运算时间/并行运算时间)在5到5.5之间。测试结果如图8所示:

图8 并行框架所消耗时间与顺序执行所有任务时所消耗时间的对比
第二次在任务相互依赖关系图中,设置三个菱形的三个最高顶点任务为重量级任务,任务在计算一个数据时所消耗的时间是其他任务的20倍左右。测试结果如图9所示:

图9 并行框架所消耗时间与顺序执行所有任务时所消耗时间的对比
从测试结果中可以看到,如果在依赖关系中出现了负载不平衡,RATIO数值下降到4.5左右,CPU的运算资源没有能够得到最大利用。
(三)段总数测试
在固定数据量情况下,段切分模块采用不同的固定段大小,切分数据时,测试了运算所消耗的时间。当段的数量多于计算机中逻辑核数(8)时,总运算所消耗的时间稳定在一个常数附近。当段的数量非常多时,子任务的个数也会增多,运算过程中对于系统内存等资源的消耗也会增多。在实际运用中段的数量应当保持在区间[计算机CPU逻辑核数,16*计算机CPU逻辑核数]内。
测试结果如图10所示:

图10 数据段的数量与子任务的个数关系
(四)异步IO测试
本文测试了在非SSD硬盘上,采用同步I/O和异步I/O时运算所消耗的时间及RATIO值。与其他测试时后续任务直接从内存中读取前置任务的输出数据不同,该测试中每个任务都从磁盘中读取输入数据,并在每段数据计算结束时把结果存储在磁盘上。
同步I/O时采用操作系统默认的缓存机制。异步I/O时直接使用系统的Complete I/O模型实现。测试如图11所示:

图11 同步I/O和异步I/O时运算所消耗的时间的对比
四、结 论
本文阐述了并行任务框架设计中,如何从设计以及算法的角度提高相互依赖的并行任务框架的并行程度,以提高框架的性能。设计了一种并行框架,实现了原型。实验结果表明,该框架可有效提高并行任务的并行程度,具有良好的可靠性、稳定性以及可扩展性。
[1] 魏长虎.多核并行计算在流媒体服务系统中的研究与应用[D].济南:山东大学,2009:1-2.
[2] 汪前进,高勇,李存华.基于多核处理器的多任务并行处理技术研究[J].计算机应用与软件,2012:29(7):141-142.
[3] 郝水侠,许金超.云计算中相似驱动的并行任务划分方法[J].计算机科学与探索,2012:6(8):41-43.
[4] 闫邵,刘磊.基于数据依赖关系的程序自动并行化方法[J].吉林大学学报,2010:48(1):94-95.
[5] 郭龙,陈闳中,叶青.构造串行程序对应的并行任务(DAG)图[J].计算机工程与应用,2007:43(1):41-42.
