基于原子分类关联规则的网络入侵检测研究
2014-10-18郭红艳谷保平
郭红艳,谷保平
(河南广播电视大学,郑州 450000)
一、引言
入侵检测方法一般分为两大类:误用检测和异常检测[1],误用检测技术主要是检测与已知的不可接受行为之间的匹配程度。收集非正常操作的行为特征,建立特征库,检测时依据具体特征库进行判断是否有入侵行为,这种检测模型误报率低、漏报率高;异常检测技术是先定义一组系统 “正常”情况的数值,如CPU利用率、内存利用率等,然后将系统运行时的数据与所定义的“正常”情况比较,得出是否有被攻击的迹象,若两者偏差足够大,则说明发生了入侵。这种方法的优点是能检测未知的攻击类型,适应性强。
入侵检测的关键技术在于分类。目前,应用于入侵检测分类方法有很多,如统计分类方法、支持向量机、神经网络和遗传算法等。随着新技术的大规模应用,研究者发现一些新颖的分类方法,例如关联规则分类法就是其中一种,目前普遍接受的观点是关联规则分类准确度高。
本文中,我们把原子分类关联规则应用于入侵检测中,利用原子型分类关联规则构建分类器的思想,它是模仿认识事物一般规律,运用“先易后难策略”分类。它具有执行速度快、准确度较高、挖掘的分类模型易于理解的特点,比较适合于大规模数据挖掘。
二、原子分类关联规则
基于关联规则的入侵检测分类学习包括以下三个主要步骤:
(1)入侵信息的收集。入侵检测首先要进行信息源的收集,包括审计迹、系统日志、网络数据包、数据等。
(2)入侵信息的分析。入侵行为一般都是隐藏在大量正常的信息之中,为了获取入侵信息,就必须对信息源进行分析。常用的分析方法有关联规则、聚类分析和模式匹配等。可见,信息分析是入侵检测过程中的关键环节。
(3)入侵检测的响应。系统对攻击行为发出报警通知或实施控制,从而降低攻击行为对系统所造成的破坏。
1.关联规则。
自Agrawal提出关联规则挖掘后,关联规则算法及应用得到迅速发展。在1998年的KDD (KDD:Knowledge Discovery in Databases)会议上,B.Liu等人提出了分类关联规则算法(CBA0)。该算法使用类Apriori算法产生关联规则,被认为关联分类的基准算法。使用支持度阈值是1%与置信度阈值是50%。该算法有两个问题:一是候选规则的运算非常耗时同时占有大量内存资源;二是由于是基于置信度的关联分类从而降低分类准确度。
2.原子分类关联规则。
原子分类关联规则算法是利用“基于突出特征和先易后难策略”的分类原理,采取人们认识事物一般常识:“先易后难”。具体做法如下:先找出最易识别进行一次分类,删除第一次易分类,在余下的数据分类中,进行同样的分类处理,直到将所有数据分类完毕。原子分类关联规则分类技术的关键技术是分类原子性,它的主要原理是找事物的“突出特征”和人们处理事情“先易后难”分类方法。为了便于记忆,我们把原子分类关联规则 (Atomic Association Rule)简称为AAR。
(1)数据结构。
AAR算法中比较关键的步骤是发现强原子规则。
在AAR算法的数据挖掘算法中,为了方便数据集中的项和项集计数,我们使用一个的双层Hash树来实现。为了提高算法的计算效率,可以将双层的Hash树简化为一个三维数组。
(2)AAR 分类步骤。
AAR产生分类器经过以下三个步骤:
①选择高置信度规则进行分类。首先进行数据集的扫描,比较各种分类方法置信度,然后选择置信度比较高的规则进行分类。
②强原子规则进行排序、删除分类好的记录。对强原子分类关联规则按置信度高低进行降序排序,首先找第一关键字;然后,进行强原子分类关联规则分类,分类完成后,把覆盖的记录从数据集中删除。
③数据集中剩余的数据继续步骤②进行分类处理,到数据集没有任何记录为止。
最后,正确组合分类数据,生成正确的数据模型。
(3)分类器的算法。
①项集计数:扫描数据集,利用一个两层的Hash树,用来标记每个类标签的数目和候选原子分类关联规则的数目。
②为Hash树的各个叶子节点生成一个候选原子规则r。
③通过Hash树直接计算候选原子规则r的支持度。
④删除支持度小于最小支持度的候选原子规则,得到频繁的原子规则集。并计算原子分类关联规则的置信度。利用置信度阈值提取强的原子分类关联规则。
⑤利用频繁的原子规则集在后件相同的条件下进行组合,导出候选的复合规则。
⑥最后输出知识要点。

图1 是建立原子分类关联规则分类器的算法:
AAR算法具有如下显著的优点:
①原子分类关联规则挖掘的是占有系统资源比较少,分类时间短;
②使用最高置信度的强原子分类关联规则可以保证分类预测精度;
③该规则产生的分类模型包含的规则数少,规则简单,易于理解,分类过程具有置信度阈值自适应的特点,无需用户设定。
下面把原子分类关联规则算法应用于入侵检测的情况进行了研究,详细研究了AAR与CBA两种典型的关联分类算法在数据集分类中的应用,结果表明AAR算法在分类准确度、分类模型的简洁性、分类学习速度和鲁棒性等方面显著地优于CBA。
三、基于AAR入侵检测实验
1.实验环境。
实验用的处理器为2.2 GHz CUP:E2200,主存为2048MB。操作系统为Windows 7,入侵检测数据集是来自KDD cup“kddcup.data10.percent”。在该数据集中,入侵记录的类型有Dos、U2R、R2L和 Probe。实验选用的样本集如表1所示,分别是Dos、U2R、R2L和ALL(所有四类入侵数据)。为了评价分析原子分类关联规则算法的分类准确性,我们使用误报率FAR(false alarm rate)和检测率 DR(detection rate)来测试算法性能[2,3]。
2.性能评估。
为了评估AAR的算法性能,我们从执行时间和产生的规则数两个方面与CBA算法进行比较。经过反复实验,对于该数据集,AAR的自适应置信度阈值调节系数为COEF=0.92。这样既保证了较高的分类准确度又具有能接受的建模时间。而CBA的置信度阈值取缺省值minconf=50%。
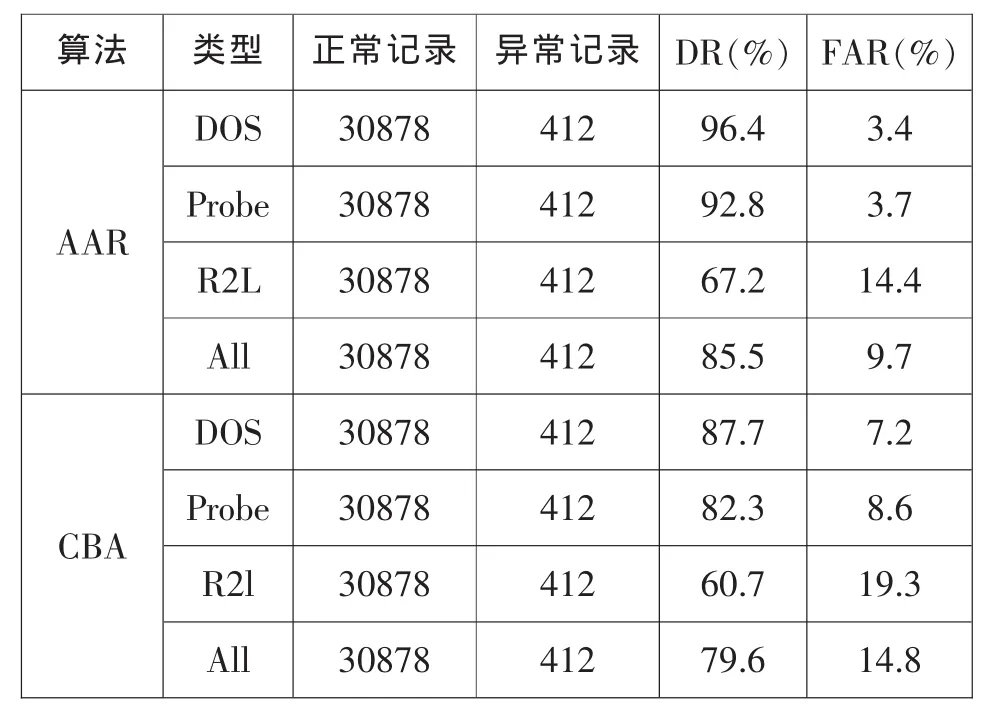
表1 两种算法系统性能
执行时间:
两种算法执行时间如图2所示,在同样的条件下实验结果表明:CBA比AAR算法要占有更多的时间。在较小的minsup下,CBA算法会产生大量满足约束的强规则。因此在最小支持度比较小的情况下,挖掘频繁k-项集的k值较小,执行时间较短。随着minsup的增加,k值相对变大,挖掘频繁候选k-项集也相应地增加,产生强规则要花费更多的时间。当minsup值较大时,由于产生频繁k-项集的减少,执行速度也较快,执行时间更短。
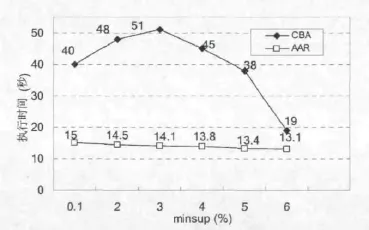
图2 不同minsup的执行时间
从图2也可以看出,在minsup从小变大时,AAR算法的执行时间相对于CBA算法比较平稳,执行时间大概在14秒上下,minsup的改变对AAR挖掘的影响比较小。
分类规则数:
两种算法分类规则数如图3所示,从图中可以看出在CBA算法和AAR算法在不同最小支持度下产生的分类关联规则数目。CBA比AAR算法要产生更多的分类规则数。对于CBA算法,最小支持度从小到大增加时,规则数目迅速降低,同时有部分分类规则不能形成正确的分类效果。而AAR算法采用加入自适应的置信度阈值的思想。所以,产生的分类关联规则数目变化不大,相对于CBA算法来说,AAR算法比较平稳,效果更好些。
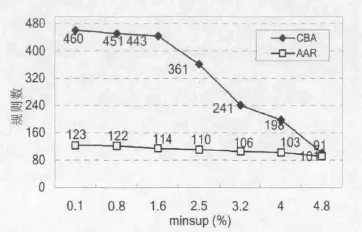
图3 不同minsup的规则数
通过AAR和CBA的综合指标比较,两种关联分类算法在入侵检测数据集的分类结果可以看出AAR表现优异,同时AAR算法生成了更少的规则数,执行效率高。而CBA算法执行速度较慢,产生分类规则数较多。
3.实验对比。
综合考虑算法性能下,把最小支持度的默认值设置为1%。对AAR算法与CBA在入侵检测方面进行对比实验,实验结果如表1所示。从实验数据结果可以看出,原子分类关联规则(AAR)算法不论在误报率还是在检测率方面都优于CBA算法,特别是对于DOS类型的入侵检测效果更好,说明改进的算法(AAR算法)是可行的。
四、结论
在本文中,介绍了原子关联规则算法 (AAR算法),并将其应用于网络入侵检测中,AAR算法可以快速准确对入侵检测数据进行分类,该分类算法支持动态阀值,能提高分类的准确性。对比AAR算法和CBA算法,实验表明,AAR能快速和准确分类入侵检测数据,取得了不错的综合性能表现。今后的工作是进一步研究增强该算法适应能力,研究改进特征提取的方法,建立准确、简单、易于理解的分类模型。
[1]蒋建春,马恒太,任党恩,等.网络安全入侵检测研究综述[J].软件学报,2000,11(11):1460-1466.
[2]谷保平,许孝元,郭红艳.基于粒子群优化的k均值算法在网络入侵检测中的应用[J].计算机应用,2007,27(6):1368-1370.
[3]Wang Hai-rui,Li Wei.Decision Tree Algorithm Based on Association Rules[J].Computer Engineering,2011,37(9):104-106.
