三维可视语音合成系统中唇部特征点的采集与处理
2014-09-21陶京京王丽荣
陶京京,王丽荣
(1.长春理工大学 电子信息工程学院,长春 130022;2.长春大学 电子信息工程学院,长春 130022)
0 引言
从人类现代语音感知学的相关研究来看,听觉存在障碍的人或正常人在噪声环境下对于语音信息并不能完全获取,这样就需要通过表情信息来有效获取对方所表达的信息。对于语言障碍人群来说,文本驱动的可视语音技术无疑给他们的生活带来了一道新的曙光。
首先,对于听觉障碍患者而言,其不能完整接收另一方传递的语音信息。而人脸语音动画是将人类的语音信息与唇形、表情信息同步传输的,能够对其接收信息和识别信息起到极大的辅助作用,在很大程度上增强其对语音信息的识别效果。
其次,对于发声存在障碍的人而言,人脸语音动画系统能够通过生成与语音同步的信息来规范口型,并对唇部各种器官发生过程中的动作变化进行调整,从而起到矫正发音障碍患者的发音的作用。
虽然国内外学者在人脸特征获取方面取得很多成果,但将其直接应用于聋儿语言康复训练当中仍存在一些问题,上述方法中大多采用二维进行特征提取,在此过程中人脸图像受到很多因素的干扰:人脸表情的多样性,外在成像过程中的光照,图像尺寸,旋转,以及姿态变化等,导致即使同一个人,不同环境下拍摄的人脸图像也不相同,甚至会有很大的差异。为此,国内外学者已开始采用三维深度图像研究具有不变性的人脸识别系统,提出了一些方法,获得了一定成果,但目前针对该方法在聋儿康复方面的研究还很不充分。
本文主要针对聋儿康复方面对三维唇部特征点进行采集和处理,得到的数据是整个文本驱动的可视语音合成系统中重要部分。在这些数据基础上,对唇部发音动作类型进行分类和整合,从而建立文本驱动的可视语音合成系统。本文的研究对聋儿康复和发音校正奠定了基础。

图1 实验场景
1 唇部特征点数据采集
1.1 实验环境
采集过程利用美国魔神三维动态捕捉系统,本研究采用6个摄像头,其余两台Angle镜头高度为1.6m,在中间作为主镜头,四台Hawk镜头高度为1.8m在两侧作为辅助镜头,在数据采集场地长宽各为2m。将摄像头按弧形位置排列,摄像头面向圆内,待测点在圆心附近为最佳。如图1所示。
选取在室内自然光照下,实验者不进行任何特别的化装,唇部和脸部粘贴上Marker点,端正地做在无反光背景前,头部自然地面对三维动态捕捉系统,在发音过程中头部运动限制在一个较小的范围内基础上,旋转角度小于5度,本实验人脸标记点(marker)直径为3mm。
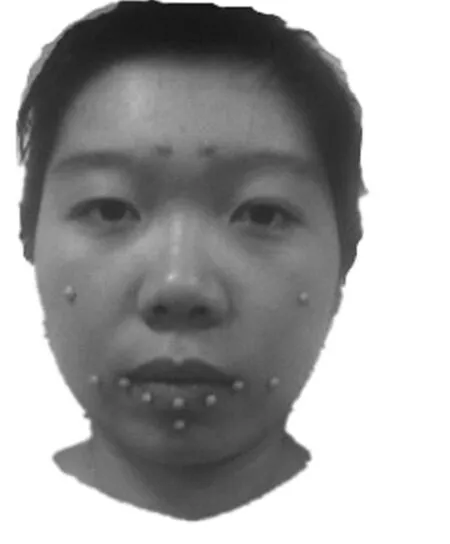
图2 特征点分布图
1.2 特征点的确定
特征点的选取结合了MPEG-4对于人脸特征点的定义[4],标注过程根据实际情况对特征点进行了适当删除,由于本文主要研究唇部信息,因此删除了眼部以及面颊部位的特征点。主要选取了12个点作为特征点,其中眉部一个特征点作为参考点H,用于校准数据,其他参考点大多数位于唇部及唇部周围。具体分布如图2所示。
该系统采集的是说话人的连续发音动作,以每秒60帧的速率获取说话人发音时面部特征点坐标数据,通过输出为对应特征点运动轨迹坐标,确定特征点的运动轨迹。图3为采集过程中系统运行窗口。

图3 动作捕捉窗口
采集到的数据是60帧/秒的离散值。每个音素发声时间约为2s,系统将记录下这2s内所有特征点的运动坐标。图4为截取音素 /a/在发声时系统所显示的特征点运动情况。

图4 /a/发音时特征点运动情况
运动捕捉的数据形式
帧为单位的运动序列,每一帧数据为离散的三维坐标点集.


其中FRAMEn表示为第n帧数据;MKm表示第m个特征标记点,三个浮点数分别表示其x,y,z坐标,单位为毫米。
2 唇部特征点数据处理
2.1 放射变换方法
在唇部取19个特征点,为了更加精细和逼真地得到不同发音时的口型,可以基于这19个特征点再向其外围自动扩充13个特征点,如图5所示。在得到这些特征点之后,进一步将嘴部图像区域做三角化,如图6所示。做三角化可以更加方便地通过移动特征点获得变形和控制局部变形的幅度[5]。
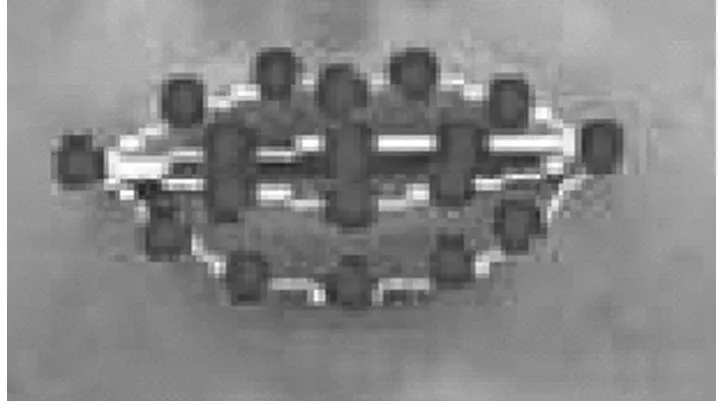
图5 嘴部19个原始特征点

图6 扩展过的嘴部特征点
运用仿射变换方法,可以合成16组中文可视音素的图像作为人脸动画的关键帧,部分中文可视音素如图5所示。但由于该合成方法仅根据发音时视觉口型经验得来,并且目前只能应用于二维模型,因此真实感不强,实用性较差,本文未采用。
2.2 三维空间坐标变换方法
通过三维动态捕捉系统得到的实时运动数据,在采集过程中由于人脸头部在发声时会产生轻微晃动,对唇部特征点的运动轨迹坐标会产生一定影响。因此在设定特征点时,采用在眉处设定一个参考特征点H:(hx,hy,hz)。这点由于离唇部距离较远,无表情发声时可近似看做在该点坐标不变。通过H点运动轨迹的分析与校准,达到使其余特征点得到校准的目的。以参考特征点的第1帧作为基准帧,运用空间坐标变换法求得第K帧到基准帧的坐标变换向量,从而得到第K帧其余特征点在基准帧坐标系下的坐标。由于只考虑第K帧各特征点坐标,H点从第一帧到第K帧的运动轨迹可近似看作一条直线。则第K帧时H点在基准帧坐标系下的坐标可以表示为:

设根据系统直接测得的第i个特征点在第K帧的坐标为:

校准后的坐标可以表示为

在后续的单个音素合成时,120帧数据运算量较大,因此需要提取最能代表该因素特点的一帧作为关键帧,并在后续运动轨迹合成中作为终止点。因此我们通过对单音素每一帧与静止帧(首帧)的欧式距离[6]大小来定义该音素的关键帧,即欧氏距离越大,变化幅度最大,最能体现该音素特点的就定义为关键帧。
欧氏距离计算方法如下:
设第i个特征点静止帧和第K帧的坐标分别为:

则可求出这两点之间的欧氏距离,

将各特征点每一帧的欧式距离做方差,可以作为从静止帧到第K帧口型的变化的程度,
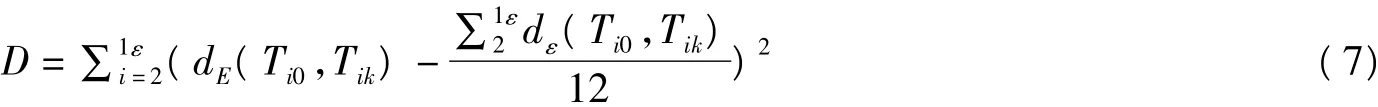
通过计算可以得到单音素的关键帧,如图5所示为/u/的关键帧与静态帧。
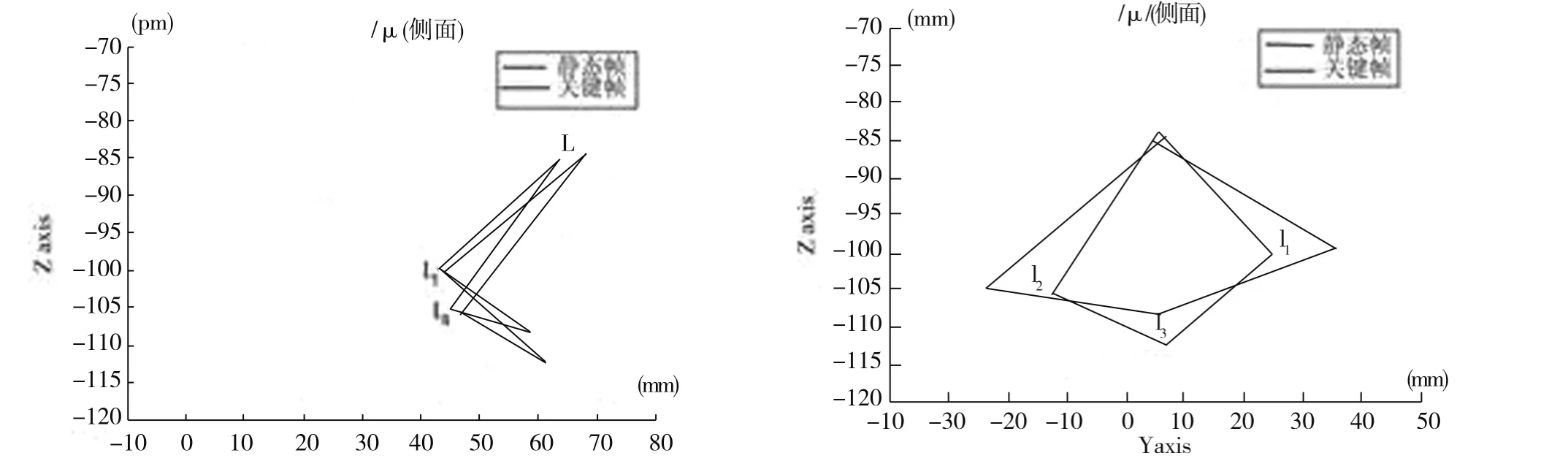
图5 /u/的关键帧与静态帧
运用该方法能够得到较为理想的唇部三维运动坐标,在后期合成轨迹运动时提高了真实感,因此在实际研究中采用了坐标变换方法对三维数据进行处理。
3 结语
本文研究了在三维可视语音系统中唇部特征点的数据采集和处理方法,该方法真实感强,计算量小,为后续的可视语音系统合成奠定了基础。使通过可视语音技术帮助聋儿康复,校正发音成为可能。对未来听障患者的生活和学习起到了一定的帮助作用。
[1]徐琳,袁宝宗,龙涛,等.真实感人脸建模研究的进展与展望[J].软件学报,2003,23(1):90-92.
[2]董兰芳,王洵,陈意云.真实感虚拟人脸的实现和应用[J].小型微型计算机系统,2002,14(4):804-809.
[3]晏洁.文本驱动的唇动合成系统[J].1998,19(1):31-34.
[4]尹宝才,王恺,王立春.基于MPEG-4的融合多元素的三维人脸动画合成方法[J].北京工业大学学报,2011,37(2):266-271.
[5]杜鹏,房宁,赵群飞.基于汉语文本驱动的人脸语音同步动画系统[J].计算机工程,2012:261-264.
[6]郑红娜,白静,王岚,朱云.基于发音轨迹的可视语音合[J]成.计算机应用与软件,2013,30(6):253-261.
