基于最小描述长度和K2的贝叶斯网络结构学习算法
2014-09-15李晓兵杨海东
曾 安,李晓兵,杨海东,潘 丹
(1.广东工业大学计算机学院,广东 广州 510006;2.中油管道物资装备总公司,河北 廊坊 065000;3.美国Batteries Plus公司,哈特兰市 威斯康辛州 53029)
贝叶斯网络是以概率论和图论为理论基础,用一个带有条件概率的有向无环图来表示随机变量间依赖和独立关系的网络模型[1].由于贝叶斯网络具有独特的不确定性表达形式、易于综合先验知识以及直观的推理结果等特性,贝叶斯网络已逐渐成为在不确定情况下进行推理和决策的一种很受欢迎的网络结构,并已在故障检测、交通管理和金融投资与市场分析等领域取得了应用[2-4].实际上,贝叶斯网络也常用在医疗领域之中.例如:CPCSBN远程医疗系统[5],它是一个多层贝叶斯网络,有448个结点和908条边,是优于世界上主要的远程医疗诊断分析方法;Alarm网[6]具有37个结点和46条边,描述了在医院手术室中所存在的潜在细菌问题;Take HeartⅡ系统[7]是基于贝叶斯网的用于心血管并诊断的临床支持决策系统(Clinical Decision Support System,CDSS)等.国内使用贝叶斯网络在冠脉支架临床进行试验[8],使用贝叶斯决策分类提高了药物分类的准确性[9].通过贝叶斯网络图形化的特点,建立起疾病诊断、终点与症状、临床检验的因果关系的模型,使医疗的诊断、处理更加科学和客观.
贝叶斯网络结构学习是目前研究的热点,其目的是获取能较好吻合数据集并且尽可能简单的网络结构.同时,贝叶斯网络结构学习也是一个NP难题.在实际中,人们主要是通过启发式方法来获取最优的网络结构[10-11].它主要分为两类:一类是基于条件独立性测试的学习方法,这类方法过程比较复杂,学习效率比较低,需要假设一些限制条件来提高算法的学习效率[12];另一类是基于评分搜索的学习方法,该类方法对个体测试的错误并不敏感,可以在数据变量的依赖程度与添加边的复杂度之间选择一个折中的方法,如G.Cooper和E.Herskovits提出的K2算法[13].如今,已经提出了很多贝叶斯结构学习的算法[14-15],并且大多研究是基于评分搜索的学习方法.
本文提出了一种新颖的基于KMBN算法.该算法在利用logistic回归和互信息对数据集进行降维的基础上,将MDL评分与K2算法结合,以构建出一种较优的网络结构.实验结果证实了该方法在效率和可靠性方面都明显优于传统的网络结构学习算法.
1 贝叶斯网络简述
贝叶斯网络又称为信念网络、因果概率网络等.它可以将具体问题中复杂的变量关系体现在一个网络结构中,并通过局部条件概率紧凑地表达出来.它描述了变量之间的依赖和因果关系,并使变量间的关系形成相对稳定的状态.贝叶斯网络分为有向无环图(directed acyclic graph,DAG)和条件概率表(conditional probability table,CPT)两部分.其中,有向无环图包括结点集合与结点之间的有向边,有向边代表结点之间的依赖关系;条件概率表表示结点之间的关联强度或置信度.学习贝叶斯网络结构来解决问题,不仅需要考虑先验知识的融合、评估函数的选择,而且也要考虑不完备数据等因素的影响.
众所周知,K2算法是贝叶斯网络结构学习领域的经典算法[16],具有非常优异的学习性能.K2算法有2个前提条件,就是要先给出结点的顺序和每个结点的父结点个数的上限.它的目的是寻找结构G的Cooper-Herskovis(CH)评分较高的模型,通过对数据集D的分析,找到与D吻合最好的贝叶斯网络结构G,即CH(G|D)最大的网络结构.其中

式中CH(〈Xi,πi〉|D)为Xi的家族CH评分.依据这一思想,在给出结点序ρ以及每个结点的父结点个数的上限u的情况下,K2利用贪婪搜索一次为每个结点找到其父结点集,从而最终构建出完整的贝叶斯网络.但在使用CH评分之前,首先需要选定先验分布中的超参数.通常这并非易事,因为理论上我们需要对每一个可能的结构都提供参数先验分布,而结构数目众多,无法一一罗列.MDL准则不需要计算其参数的先验分布,计算较简单,且由于明确地将结构复杂性作为一个指标而倾向于选择较简单的网络结构,计算结果更容易被接受.因此,基于MDL准则的算法可较好地实现目标网络结构的拓扑简单性与对实例数据集拟合度之间的权衡.
MDL是Rissanen在研究通用编码时提出的[17-18].它综合考虑了似然函数和计算复杂度两方面的因素.这个准则的基本原理是对于给定的实例数据进行压缩,从而降低数据的编码(描述)长度.一个MDL评分由以下2部分构成:
因此,贝叶斯网络结构的MDL评分为

2 基于KMBN算法
基于KMBN算法主要包含3个步骤:(1)属性(变量)降维,在对连续性变量进行离散化的基础上,利用logistic多变量回归分析找出相关性较为显著的变量;(2)构建无向图,然后计算每一个属性变量和决策变量间的互信息熵,互信息熵较小的变量之间连接边;(3)构建有向图,运用MDL局部打分原理和K2算法来确定边的方向.
设一个数据集D 有M 个变量,记为X={X1,X2,…,XM},假设{X1,X2,…,XM-1}是属性变量,XM是决策变量.
2.1 属性降维
利用logistic多变量回归分析从结点变量X={X1,X2,…,XM}中找出用来构建贝叶斯网络结构所需的变量.记rij=p,对于属性变量Xi和决策变量XM(i<M),用riM来表示它们之间的关系.如果riM≤0.05,则表示Xi和XM间为显著关系,即该属性变量对决策变量的影响显著;如果riM>0.05,则表示Xi和XM间为非显著关系,或者说与它们无关.这样就得出了构建贝叶斯网络结构的变量,记为{X1,X2,…,XN,其中XN=XM为决策变量.
本研究对象选择2016年12月~2017年12月在我院接受治疗的120例初诊2型糖尿病患者。将其按照就诊时间先后分为观察组与对照组,每组各60例患者。其中对照组男性32例,女性28例;年龄为37~70岁,平均年龄为(48.5±3.5)岁;病程1~7年,平均病程为(3.5±1.5)年;观察组男性31例,女性29例;年龄为38~70岁,平均年龄为(49.0±3.2)岁;病程1~6年,平均病程为(3.2±1.0)年。两组患者一般资料相比,无显著差异(P>0.05),具有可比性。
2.2 构建无向图
依次对每一个属性变量和决策变量〈Xi,XN〉,i=1,2,…,N-1计算,其互信息熵为

其中xi为Xi的值,xN为XN的值.给定一个阈值e(e通常是一个很小的正数).当I<e时,连接边Xi~XN.
将I按大小进行排序,可得到初始结构结点的先验顺序,记为ρ.
2.3 构建有向图
对于上述已经存在的无向图,运用MDL局部打分原理来确定边的方向.MDL局部打分原理如下:
设2个贝叶斯网络结构分别为G1,G2,其中变量Xi的父结点集分别为Π1和Π2,如果Π1和Π2中只有π1和π2不同,那么ScoreMDL(G1|D)-ScoreMDL(G2|D)=ScoreMDL(X1∪π1|D)-ScoreMDL(X2∪π2|D),π1和π2分别为Π1和Π2中的父结点,ScoreMDL(Gi|D)表示结构Gi在数据集D 上的最小描述长度,i=1,2.
对变量Xj,假设它已经有了一些父结点为πj.若|πj|<u,即变量Xj的父结点个数还没达到u,则就要继续找寻它的父结点.首先考虑那些在ρ中排在Xj之前、但却还不是Xj的父结点的变量,从这些变量中选出Xi,计算新测度值MDL评分(记为ScoreNew).然后将其与旧测度(记为ScoreOld)做比较,如果ScoreNew<ScoreOld,则记Xi为Xj的父结点,否则停止寻找Xj的父结点.
2.4 算法的伪代码
输入:n个变量的集合X={X1,X2,…,Xn};变量父结点的上限个数为u;变量的顺序ρ;一个包含N个样本的完整数据集D.
输出:一个贝叶斯网络结构.

3 实验结果分析
3.1 可靠性分析
为了验证本文提出的基于KMBN算法的有效性,采用广东省某医院MICU病房提供的数据集对KMBN算法、基于K2的贝叶斯结构学习算法和基于K2与模拟退火的贝叶斯结构学习算法进行仿真实验.该数据集包括209个病历,每个病历有44个属性,其中6个属性是系统疾病,可将它们合并成一个属性.则属性有Balance,Speak和Platelet等38属性变量和1个决策变量Event.该决策变量记录了病人出MICU后是否存活了300d以上.38个属性中,21个为连续型,17个为离散型的.为了简化,仅选择了其中一部分数据进行说明,相关信息见表1.对于连续型属性,主要是根据专家经验知识设置断点进行离散化,例如:对于属性Platelet(100~300)×109个/L的为正常,低于100×109个/L或高于300×109个/L的为异常;属性Procalcitonin小于0.5μg/L的为正常,大于或等于0.5μg/L的为异常;属性Lactic Acid在0.5~2mmol/L之间为正常,小于0.5mmol/L或者大于2mmol/L的为异常.

表1 部分数据信息
对上述39个属性采用回归分析方法降维后,其中的12个属性被保留了下来,它们包括11个属性变量和1个决策变量(为了作图方便,将它们用字母代替):

我们对余下的12个属性采用本文中提出的KMBN算法来构建贝叶斯网络结构.取结点变量的父结点的最大个数u=4,结果如图1所示.

图1 KMBN算法的贝叶斯网络结构学习结果
为了验证提出算法的性能,将结果分别与文献[13]中的基于K2的贝叶斯结构学习算法,文献[19]中的K2与模拟退火相结合的贝叶斯结构学习算法进行了比较.依然取结点变量的父结点的最大个数u=4,基于K2算法的贝叶斯网络结构学习结果如图2所示.
文献[19]中的K2与模拟退火相结合的贝叶斯结构学习算法的结果如图3所示.

图2 基于K2算法的贝叶斯网络结构学习结果

图3 基于K2与模拟退火的贝叶斯网络结构学习结果
医学诊断,特别是在临床,需要简洁、快速的诊断模型,冗长而耗费时间的诊断模型难以在临床中推广.ApacheⅡ评分模型[20]、GCS评分模型[21]就是临床中快速的诊断模型.本文通过回归分析方法来降维,在原本39个属性中保留12个属性,结点的减少简化了决策变量的分析.通过KMBN算法得出的贝叶斯网络结构提示结果受Survival Desire和FAST评分[22]的直接影响,两属性使诊断快速而有效,文献[13]方法显示结果受到多个因素(H,K,G和A)影响,本文方法明显提高了效率.而图3方法显示,结果受属性(Eyesight,Temperature)影响,对照医学领域,不符合实际.图2中,显示B,C,D,E,F,I,J之间没有依赖关系.实际上,随着疾病的进展和脏器功能衰竭,这些属性是相互影响的,因此使用图1解释疾病发展更加合理.
本文算法、文献[13]和文献[19]的学习结果数据如表2所示.从表2中可以看出,KMBN算法、基于K2的贝叶斯结构学习算法和基于K2与模拟退火的贝叶斯结构学习算法得出的边数分别为19条,37条,20条.明显基于K2的贝叶斯结构学习方法得出的关系更为复杂,而KMBN方法和基于K2与模拟退火的贝叶斯结构学习方法的关系复杂度相似.它们精确度的检验有待验证.但由模型中边的情况观察,通过医学理解可知,图1中FAST功能评级的下降提示患者存在老年痴呆,因此影响患者语言能力,语言能力的下降直接导致社交功能受损,然后将伴随生存欲望的下降,最终导致结果的发生.而氧合指数的下降往往伴随着呼吸机辅助呼吸,因此其语言及生存欲望下降,同时,乳酸的上升导致脏器灌注的下降,将影响视觉和肾脏血流(尿素氮上升),其他的结果也有类似的联系.总体来说,图1对于结果的解释较为合理,反观图3中生存欲望对于体温、胆红素的影响在医学中难以解释.同时,体温和视觉对于结果的直接影响也无法通过医学理论解释.实际上,在该方法中多个边所确定的关系均无法在医学领域中解释,因此极大影响结果的可信度判断.
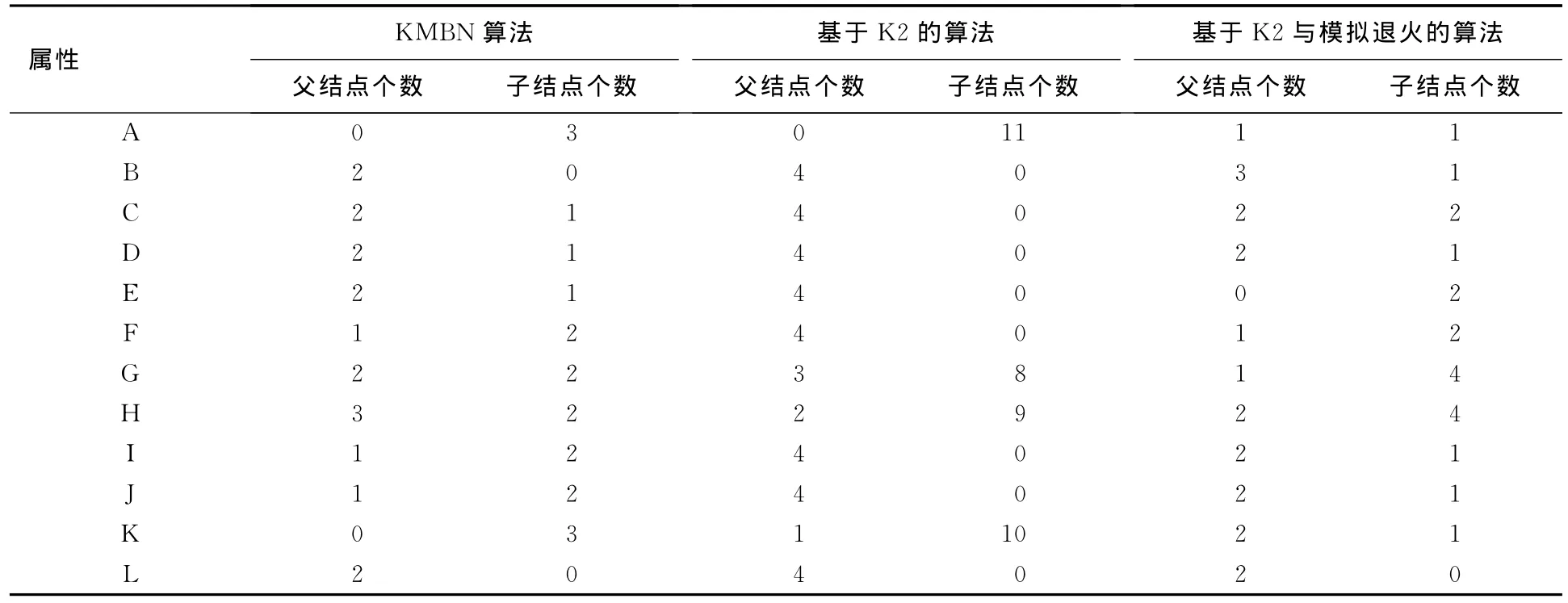
表2 几种算法学习结果的对比
3.2 计算复杂度分析
K2算法的时间复杂度为O(mk2n2r),其中:m表示实例样本个数,k表示父结点个数,r表示每一个结点的取值个数.在基于K2与模拟退火算法中,计算的复杂度与K2算法不同的就是多了等温搜索次数t和最大迭代次数s,所以基于K2与模拟退火算法的时间复杂度是O(mk2n2rts).对于文中改进的KMBN算法,在得出先验结点顺序后不再依赖实例样本个数,因此其时间复杂度为O(k2n2r).
由此可看出,基于K2与模拟退火的贝叶斯结构学习算法的计算时间比较复杂,基于K2的贝叶斯结构学习算法和本文算法接近,但基于K2的贝叶斯结构学习算法得出的结果受到多个因素影响,效率明显较低.再者,基于K2的贝叶斯结构学习算法得出的结构图中的边数比其他2个多很多,这在搜索诊断治疗结果时需要花费更多的时间.虽然基于K2与模拟退火的贝叶斯结构学习算法得出的结构图边数与本文算法很接近,但前者确定的很多关系无法在医学领域中证实,缺乏准确性.
4 结论
贝叶斯网络结构学习是数据挖掘的重要研究方向,它提供了不确定性环境下的知识表示、推理、学习手段,可以解决诊断、预测、分类等问题.本文充分考虑了条件变量与决策变量的数据分布关系,通过logistic回归分析和条件互信息熵对案例数据进行了预处理,接着用提出的打分——搜索算法即KMBN算法对数据集进行了贝叶斯网络结构学习.实验结果表明,本文算法与传统的基于K2算法的贝叶斯结构学习比较,前者明显简化了网络结构.本文算法与基于K2与模拟退火的贝叶斯结构学习算法比较,可以看出,本文算法具有较好的可靠性.同时,本文算法在时间复杂度上面也有改善,为贝叶斯网络广泛应用于解决实际问题又提供了一种新的有效方法.
[1]王双成,冷翠平,李小琳.小数据集的贝叶斯网络结构学习[J].自动化学报,2009,35(8):1063-1069.
[2]HUANG YINGPING,MCMURRAN R,DHADYALLA G.Probability based vehicle fault diagnosis:Bayesian network method[J].Journal of Intelligent Manufacturing,2008,19(3):301-311.
[3]JULIO C R,GUILLERMINA M,LUDIVINA G.Fault diagnosis in an industrial process using Bayesian networks:application of the junction tree algorithm[C]//Proceedings of Electronics,Robotics and Automotive Mechanics Conference,Cerma:Mexico,2009:301-306.
[4]JUAN M F,JUAN F H,BENJAMIN P.Introduction to the special issue on graphical models and information retrieval[J].Journal of Approximate Reasoning,2009,50(7):929-931.
[5]OLIÉSKO A,LUCAS P,DRUZDZEL MJ.Comparison of rule-based and Bayesian network approaches in medical diagnostic systems[J].Artificial Intelligence in Medicine,Lecture Notes in Computer Science,2001(8):283-292.
[6]BEINLICH IA,SUERMONDT HJ,CHAVEZ RM,et al.The alarm monitoring system:a case study with two probabilistic inference techniques for belief networks[C]//Artificial Intelligence in Medicine,Lecture Notes in Medical Informatics,London:AMAZON,1989:247-256.
[7]HOPE LR,NICHOLSON AE,KORB KB,et al.Take heartⅡ:a tool to support clinical cardiovascular risk assessment[J].Tech Rep,2007:209.
[8]王杨,王睿,陈涛,等.贝叶斯分层模型在医疗器械临床试验中的应用[J].中华疾病控制杂志,2012,3(16):254-256.
[9]周扬,吕进,戴曙光,等.基于贝叶斯决策的近红外光谱药片分类方法[J].分析化学,2013,2(41):293-296.
[10]TAE YOUNG YANG,JAE CHANG LEE.Bayesian nearest-neighbor analysis via record value statistics and nonhomogeneous spatial Poisson processes[J].Computational Statistics & Data Analysis,2007,51:4438-4449.
[11]FEELDERS AD,LINDA C VAN DER GAAG.Learning Bayesian network parameters under order constraints[J].International Journal of Approximate Reasoning,2006,33:37-53.
[12]孙岩,吕世聘,王秀坤,等.贝叶斯网络结构模型的构建[J].小型微型计算机系统,2008,29(5):859-862.
[13]COOPER G,HERSOVITS E.A Bayesian method for the induction of probabilistic networks from data[J].Machine Learning,1992,9(4):309-347.
[14]BRENDAN J FREY,NEBOJSA JOJIC.A comparison of algorithms for inference and learning in probabilistic graphical models[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2005,27(9):1392-1416.
[15]ZGUROVSKII M Z,BIDYUK P I,TERENT'EV A N.Methods of constructing Bayesian networks based on scoring functions[J].Cybernetics and Systems Analysis,2008,44(2):219-224.
[16]朱明敏,刘三阳,汪春锋.基于先验结点序学习贝叶斯网络结优化方法[J].自动化学报,2011,12:1514-1519.
[17]HUANLLU H,MOTODA H,SETIONO R,et al.An ever evolving frontier in data mining[J].Workshop and Conference Proceedings,2010,10:4-13.
[18]MARKOV Z.MDL-based unsupervised attribute ranking[C]//Proceedings of the twenty-sixth international florida artificial intelligence research society conference.California:The AAAI Press,2013:444-449.
[19]金焱,胡云安,张瑾,等.K2与模拟退火相结合的贝叶斯网络结构学习[J].东南大学学报,2012,42(1):82-86.
[20]KNAUS WA,DRAPER EA,WAGNER DP,et al.ApacheⅡ:a severity of disease classification system[J].Crit Care Med,1985,13(10):818-829.
[21]TEASDALE G,JENNETT B.Assessment of coma and impaired consciousness[J].A practical Scale Lancet,1974(2):81-84.
[22]HEISBERG B.Functional assessment staging(Fast)[J].Psychopharmacol Bull,1988,24(4):653-659.
