基于B2C帐号在线评论特征的聚类分析
——以京东商城为例*
2014-08-08段轶轩罗泽举
段轶轩, 罗泽举
(重庆工商大学 数学与统计学院,重庆 400067)
对商品在线评论的研究伴随着电子商务网站的崛起而兴起。国内外在这一领域的研究热点主要集中在:(1) 评论内容对在线评论效用的影响,如:严建援等[1],通过对221个评论文本采用回归分析的方法研究了在线评论内容对评论有用性的影响,结果发现评论深度越深、越客观,效用越高;而在评论中涉及到越多的个人情感,效用反而越低,评论传达的情感强度与效用关系不显著;文献[2]采用文本挖掘相关技术,对在线商品评论进行情感极性的抽取,进而对其进行有用性打分,去辅助购物者更好的做购物决策;(2) 在线商品评论是企业竞争情报重要来源,如:施国良等[2]讨论了产品评论的预处理并从行业监测、用户研究、企业自身以及竞争对手分析4个方面分别探讨了产品评论挖掘在企业竞争情报中的具体应用。(3) 在线商品评论与购买行为的研究,如:郑媛媛[4]分别从在线评论的数量和情感极性对消费者总体购买行为的绝对影响和相对影响、评论的情感极性对商品类别调节作用的不对称性、构建在线评论感知有用性的影响因素模型,提高评论有用性的分类识别能力、造成评论没有有用性的原因和因素4个方面研究了在线商品评论与消费者购买行为的关系。(4) 在线评论的价值研究综述,如:杨铭等[5]是对在线评论最新的研究进展进行综述的文章,对商品评论的效用从评价目标、评价特征、评价技术和评价对象4个维度进行划分,进一步地,将评价目标划分为排序、汇总和分类;评价特征划分为语法特征、语义特征、体裁特征、元数据;评价技术划分为机器学习和相似度得分;评价对象分为实用型商品和享受型商品。认为对商品在线评论的研究要充分关注消费者的购买决策过程,进行设计新的数据挖掘方法更好地辅助消费者的购买决策。(5) 商品评论与商品销量的关系。如:郑媛媛[6]在面板数据环境下分析了商品在线评论情感倾向与商品销售收入的关系,以揭示在线口碑劝说作用对消费者总体购买行为的影响机理。分析结果表明,仅在电影发布后第3周,在线评论的情感倾向对电影票房收入存在显著影响,且极端好评的影响力大于极端差评的影响力。
创新点在于对商品在线评论从帐号的角度进行数据汇总,对参与京东商城在线商品评论的人群进行聚类,发现不同类人群的评论特征。进一步地对京东商城的运营状况站在帐号在线商品评论的层面进行推测。
数据来自2013年5月12日从京东商城网页摘取的2万个账户的在线评论数据,使用mysql数据库对数据进行存取、社区版pentaho商业智能分析套件中的WEKA[7]进行聚类算法的实现和聚类算法的评估。在算法选取中,使用混合模型的聚类思想,并使用EM算法予以实现;同时,使用SimpleKMeans作为对照算法。在聚类评估中,引入基于似然度的聚类算法评估准则作为聚类算法选取标准。具体来源可以从WEKA源代码中weka.clusterers.ClusterEvaluation和weka.clusterers. MakeDensityBasedClusterer两个类中找到,方法也是WEKA官方使用手册中推荐的聚类算法评估准则。
1 似然度的聚类评估准则
大多数聚类算法都会对每一个个体分派一个簇,在得到不同的簇以后,对每一个簇构建一个概率分布,这里假定每一个簇中的样本属性间相互独立,数值属性服从正态分布、名词性属性则构建一个离散分布。这样,在聚类以后,就可以对不同的簇分派一个明确的概率分布。根据极大似然估计的启示,可以构建一个基于对数似然取值的评估函数。
假定随机变量x=(x(1),x(2),…,x(n))g(x(i))为随机变量x每一个属性的概率密度(或质量)函数,其中,概率密度函数对应的是正态分布。x在簇j的联合概率密度函数由公式(1)给出。
(1)
(2)
在公式(2)中:wi是每一个簇的优先概率
max(A(x))=max(ln (w1f1(x|θ1)),ln (w2f2(x|θ2)),…,ln (wKfK(x|θK)))
A(x)=[ln (w1f1(x|θ1)),ln (w2f2(x|θ2)),…,ln (wKfK(x|θK))]
A[i]是A(x)的第i个分量
(3)
d(x)是个体在每一次聚类算法结束后,在其所在的簇分布的一个测度,值越大,说明这个个体在这个簇分布中出现的概率越大。公式(3)则是一组测试样本在每一次聚类算法结束后对聚类算法效果的测度,即log_likelihood的取值反映了数据集拟合这些簇的程度。取值越大,说明拟合效果越好(注:上述公式是使用java程序在DEBUG模式下调用了WEKA 的API中weka.clusterers.ClusterEvaluation类的静态方法evaluateClusterer得到的)。
实际在对不同聚类算法进行评估时,将数据随机划分为k个互不相交的子集D1,D2,…,Dk,每一个子集的大小大致相等。训练和测试进行k次。在第i次迭代,划分Di用做检验集,其余的划分一起用来训练模型。也就是说,在第一次迭代,子集D2,D3…,Dk一起作为训练集,得到第一个模型,并在D1上检验,得到一个似然度的取值;第二次迭代在子集D1,D3…,Dk上训练,并在D2上检验,得到另外一个似然度的取值;这样,一种算法作用在一个数据集上就会产生k个似然值。
如上所述,每一个聚类算法作用在一个数据集上便会产生一组似然值,这样,两个聚类算法作用在一个数据集的评估就变成两组似然值均值的比较问题;统计学中,成对双样本t-检验,正是为了这一场景设计的。算法评估就是按照上述流程进行的。
2 聚类分析
2.1 数据提取和整合
使用java语言并使用jsoup-1.6.3、spring-3.2、hibernate-4.17等诸多框架包进行web数据提取应用程序的书写,使用mysql数据库进行数据的存储,并利用Spring开启事务功能,确保数据收集的完整性(注:一个账户自身信息以及对应的评论数对应多次数据插入操作,因此,将多个Dao集成到一个Service中,将该层开启事务功能,确保出现特殊情况,能够回滚,以免造成数据缺失)。数据以2张一对多关系的表结构形式进行存储。抓取数据的流程图(图1)。
具体字段信息如表1、表2。

图1 抓取数据流程图
表1账户表字段信息

属性属性类型帐号ID数值型用户名名词型帐号等级名词型帐号所在地名词型回复总数数值型
实际提取账号的数据量是19 887条,评论表的数据量是123 655条;然后,通过SQL语句将数据汇总成表3中字段对应的数据,并剔除一些异常属性值,最终,便得到4 689条数据。这些人都是至少发表过1篇以上评论的人群。根据这些数据,发现大约有23.6%的京东账户发表过在线商品评论。表3字段信息如下:

表2 评论表字段信息
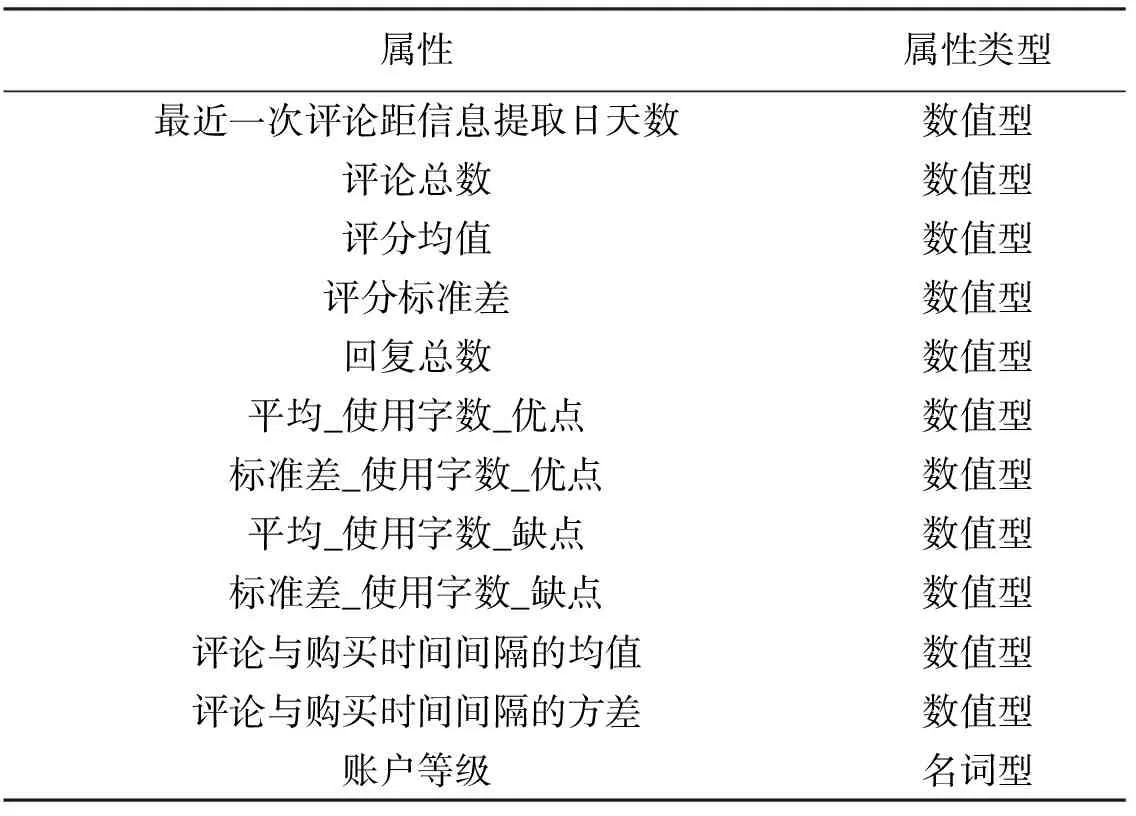
表3 聚类属性信息
注:(聚类时,账户等级除外;平均_使用字数_优点是指帐号在对商品的优点进行评论时,所有评论使用字数的均值;其他类似选项依次类推)
2.2 聚类算法的选取
根据算法评估体系,得到聚类算法评估表4(注:详细操作步骤见WEKA官方手册中Cluster Experiments章节介绍):

表4 聚类算法评估表
选取k=10进行分层交叉校验,做出一个样本量为10的成对T检验,表4是每一个算法分别取似然值均值的结果。根据检验结果,我们发现EM算法在95%的显著性水平下优于SimpleKmeans。因此,选取EM算法。
聚类结果见表5,优先概率见表6。

表5 簇的均值特征
注:表中数据对应各个分布簇修正后的对应属性均值

表6 优先概率
2.3 簇描述与对应人群推测
第一类簇:绝大多数只发表了一篇评论,他们在最近一次评论距信息提取日天数的取值是所有簇中最大的,评分均值最低,但是,单位回复率(注:单位回复率=总回复数/总的评论数)最高。在对购物体验进行评论时,使用的字数最多,特别是在缺点的评价中,在所有簇中最高。他们的评论时间一般在购物后一个月进行,与除第二类以外的簇相当。
人群推测如下:流失风险最高,并且发表的评论,特别是负面的评论受到了其他购物者广泛的关注,大量在缺点上的评论文字似乎在宣泄对这次购物体验的不满,这类人群发表评论的时间一般在购物后一个月进行,说明从评论的谨慎态度而言,还是比较谨慎的。
第二类簇:发现占比最大的簇是第二类簇,特征概括如下:他们购买体验满意度最高,但是,平均来说,他们只是发表了5篇评论,在对购物体验的优、缺点进行评论时,使用字数差不多,并且使用字数很短,平均来说只有9个字。在所有的簇中,这类人群的购物时间与评论时间的间隔最短,说明他们未经过足够长的商品体验就发表了评论。
人群特征推测如下:这类人群对商品评论的态度较随意,未对商品进行较长时间的体验就给予购物体验较高的评分导致了评论质量不高,这一点可以从单位回复率得到验证,他们尝试过但并未对发表商品评论给予过多的关注。
第三类簇:他们的人数仅次于第二类簇,平均来说,他们发表的评论总数大概有40条左右,满意度仅次于第二类簇。他们虽然在评论时使用的字数较简短,但是,他们是经过了对商品最长的考察期后,才对商品进行了评论。这类人群对待评论的态度谨慎。
人群特征推测如下:这类人对评论的态度谨慎,这一点也可以从他们的评论单位回复率得到佐证,他们会顾忌到自己的评论对他人造成的购物影响,他们是发表商品评论的中间力量。
第四类簇:评论发烧友的代表,他们不但发表了大量的评论并且最近一次评论距信息提取日的天数最近,评分均值在4.5分以上,然而,较高的评论热情并没有体现在书写评论字数的层面,他们大概在购买商品一个月后对商品进行评价,评论的态度也较为谨慎。
第五类簇:人群评分的均值在4.1分左右,仅高于第1类簇,并且最近一次评论距信息提取日天数的均值较大,仅低于第1类簇,发表评论在优、缺点的字数相对均衡,但是,很显然,他们在缺点的评论字数上仅次于第一类人群。
人群特征推测如下:虽然评论态度较第一类人群较为温和,但是,他们的流失风险仅次于第一类人群。
2.4 结合账户等级
在提取的19 887个帐号中,铜牌及以上的会员占到会员总量的22.71%,发表过评论的铜牌及以上会员占该类用户总数的70%以上。虽然营销理论中著名的“二八原则”未必在电商行业适用,但对发表过评论的铜牌及以上会员单独提取出来去察看上述5类簇在对应等级会员中的分布情况。图2给出已发表过评论的铜牌及以上会员属于各个簇的分布。
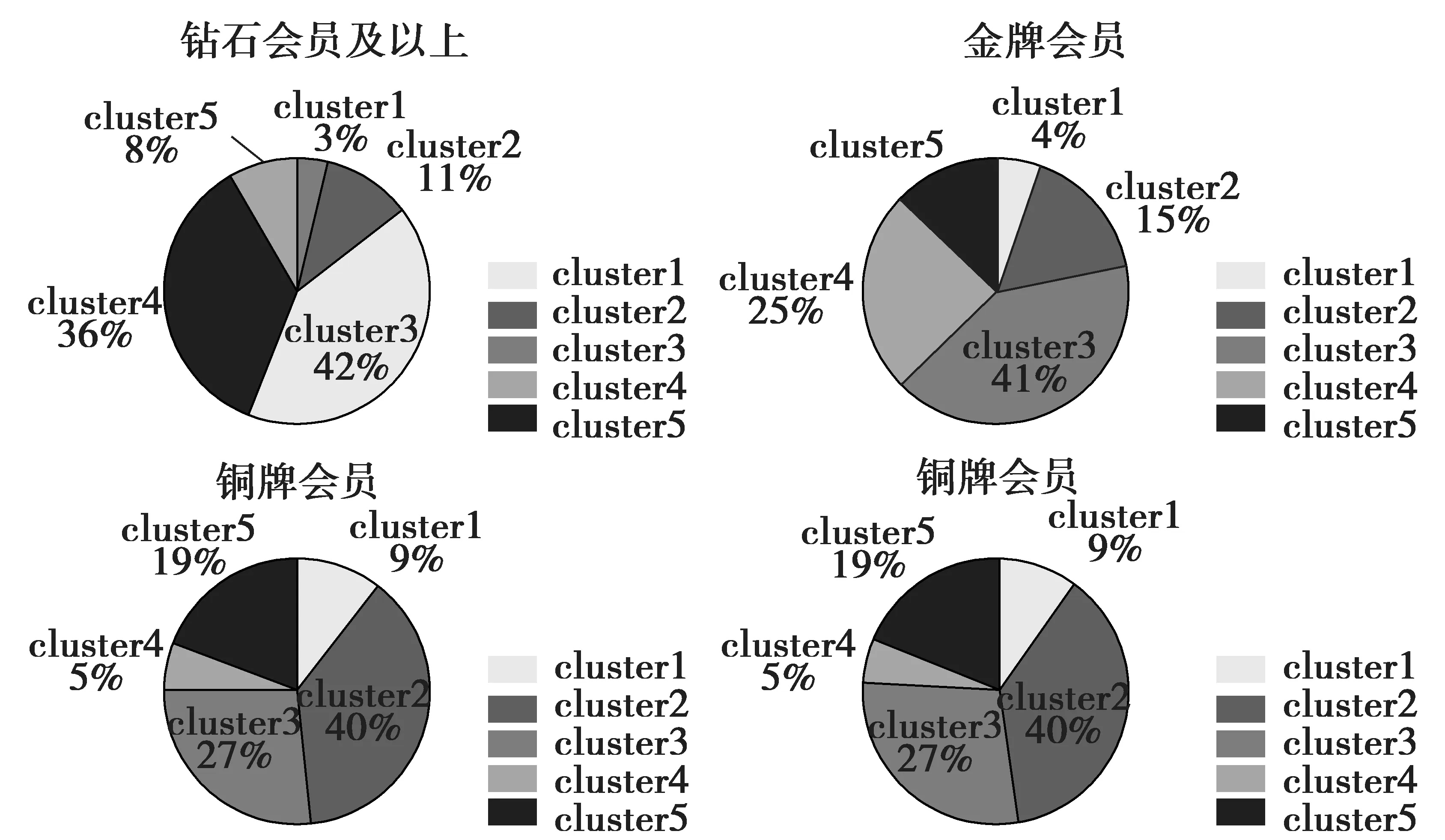
图2 结合账户等级饼图
3 结束语
(1) 站在帐号满意度层面,京东商城的运营状态基本良好。首先,第二、三、四类簇占比为76.2%。钻石及以上会员和金牌会员分别属于第一类簇和第五类簇的比例为16%和11%,占比偏低;钻石及以上会员和金牌会员潜在的流失比列在16%和11%左右;应该对这类人群予以特别的挽留,同时,也反映出京东商城也存在相当比例高级客户流失风险。
(2) 根据查金详[8]的研究,得推论:发表评论意味着账户会将更多的感情投入到电子商务网站,会提高账户对电子商务网站的忠诚度。在已发表过评论的金牌会员和钻石及以上会员中,25%的金牌用户以及36%的钻石以上会员都是评论发烧友。从这一点可以发现,京东商城正在培育出一批忠诚度高、消费能力旺盛的客户群。而在不同等级的会员中,发烧友占比随会员等级的下降而下降,这一点再次验证了上述推论的正确性。
(3) 在发表商品评论时,那些字数很长并且针对缺点的评论受到了购物人群广泛的关注;虽然针对缺点的评论会在短期内一定程度上压抑消费者购买商品的可能性,但是,从长期来看,运用一种积极、主动的方式对待这类评论对客户忠诚度的构建应该是正面的。特别是,对高等级客户发表的负面评论,要给予足够的重视。
参考文献:
[1] 严建援. 电子商务中的在线评论内容对评论有用性影响的实证研究[J]. 情报科学,2012,30(5):714-716
[2] ZHANG Z.Weighingstar:Aggregating Online Product Reviews for Intelligent E-commerce Applications[J].Ieee Intelligent Systems,2008,23(5):42-49
[3] 施国良,程楠楠.Web环境下产品评论挖掘在企业竞争情报中的应用[J].情报杂志,2011,30(11):11-14
[4] 郑媛媛. 在线评论对消费者感知与购买行为影响的实证研究[D].哈尔滨:哈尔滨工业大学博士论文,2010
[5] 杨铭. 在线商品评论的效用分析研究[J]. 管理科学学报,2012,15(5):66-74
[6] 郑媛媛. 基于电影面板数据在线评论情感倾向对销售收入影响的实证研究[J].市场营销,2009,21(10):95-103
[7] MARK H,EIBE F,GEOFFREY H. The Weka Data Mining Software:An Update[J]. Sigkdd Explorations,2009(11):10-18
[8] 查金详. B2C电子商务顾客价值与顾客忠诚度的关系研究[D].郑州:浙江大学博士论文,2006
