基于关联关系和MapReduce的僵尸网络检测
2014-08-05邵秀丽蒋鸿玲耿梅洁李耀芳
邵秀丽,蒋鸿玲,耿梅洁,李耀芳
(1. 南开大学信息技术科学学院,天津 3 00071;2. 天津城建大学计算机与信息工程学院,天津 30038 4)
基于关联关系和MapReduce的僵尸网络检测
邵秀丽1,蒋鸿玲1,耿梅洁1,李耀芳2
(1. 南开大学信息技术科学学院,天津 3 00071;2. 天津城建大学计算机与信息工程学院,天津 30038 4)
现有僵尸网络检测方法的计算量较大,导致检测效率低,而云计算的强大数据处理和分析能力为僵尸网络的检测提供了新的思路和解决方案。为此,设计并实现一种基于MapReduce模型的并行僵尸网络检测算法,基于云协同和流间关联关系对僵尸网络进行检测。提取流间关联关系,将具有关联关系的流聚集到同一个集合中,计算主机的分数,若分数大于阈值则判断为可疑的僵尸主机。实验结果表明,该算法对P2P僵尸网络的检测率能够达到90%以上,误报率控制在4%以下,并且随着云服务器端计算节点的增多,其处理云客户端上传数据及检测僵尸网络的效率更高。
僵尸网络;云计算;关联关系;MapReduce模型;Hadoop云平台
1 概述
僵尸网络的日益健壮和隐蔽导致对其检测难度加大,而网速的加速则造成流量数据越来越多,导致检测僵尸网络方法的计算量不断增大。云计算具有强大的数据分析和处理能力,可为僵尸网络检测提供高效的解决方案。
目前,学术界对僵尸网络检测的研究成果主要有:文献[1]描述了P2P技术在僵尸网络中的应用并说明未来僵尸网络的发展方向;文献[2]提出了一种利用云计算检测僵尸网络的方法;文献[3]利用云计算建立和处理大规模图数据以检测出发送垃圾邮件的僵尸网络;文献[4]利用云计算设计了并行PageRank算法检测僵尸网络。一些安全公司利用云计算提供安全服务,如瑞星提出了“云安全”方案。瑞星客户端监控计算机发现有可疑程序运行时,就将其上传到瑞星云服务器端。服务器端收集了各个客户端的可疑程序样本,在云服务器端进行各种分析处理[5]。目前,国内外各大安全厂商提出的基于云计算的病毒检测方案一般由大量云客户端和云服务端构成。云客户端上传可疑的软件样本等到云服务器端,云服务器端对收集到的恶意软件样本进行分析处理,判断是否是病毒,并对各个客户端发布病毒处理的解决方案[6]。
针对僵尸网络检测问题,本文提出一种MapReduce并行关联关系算法,使客户端不上传可疑程序,而是上传自身的网络访问流量信息到云服务器端,并利用Hadoop机制对流量进行分析处理[7]。
2 僵尸网络云检测方法
僵尸网络云检测方法的架构如图1所示,该方法由云客户端和云服务器端及Hadoop协同完成对网络访问流量信息中的僵尸网络行为的检测。
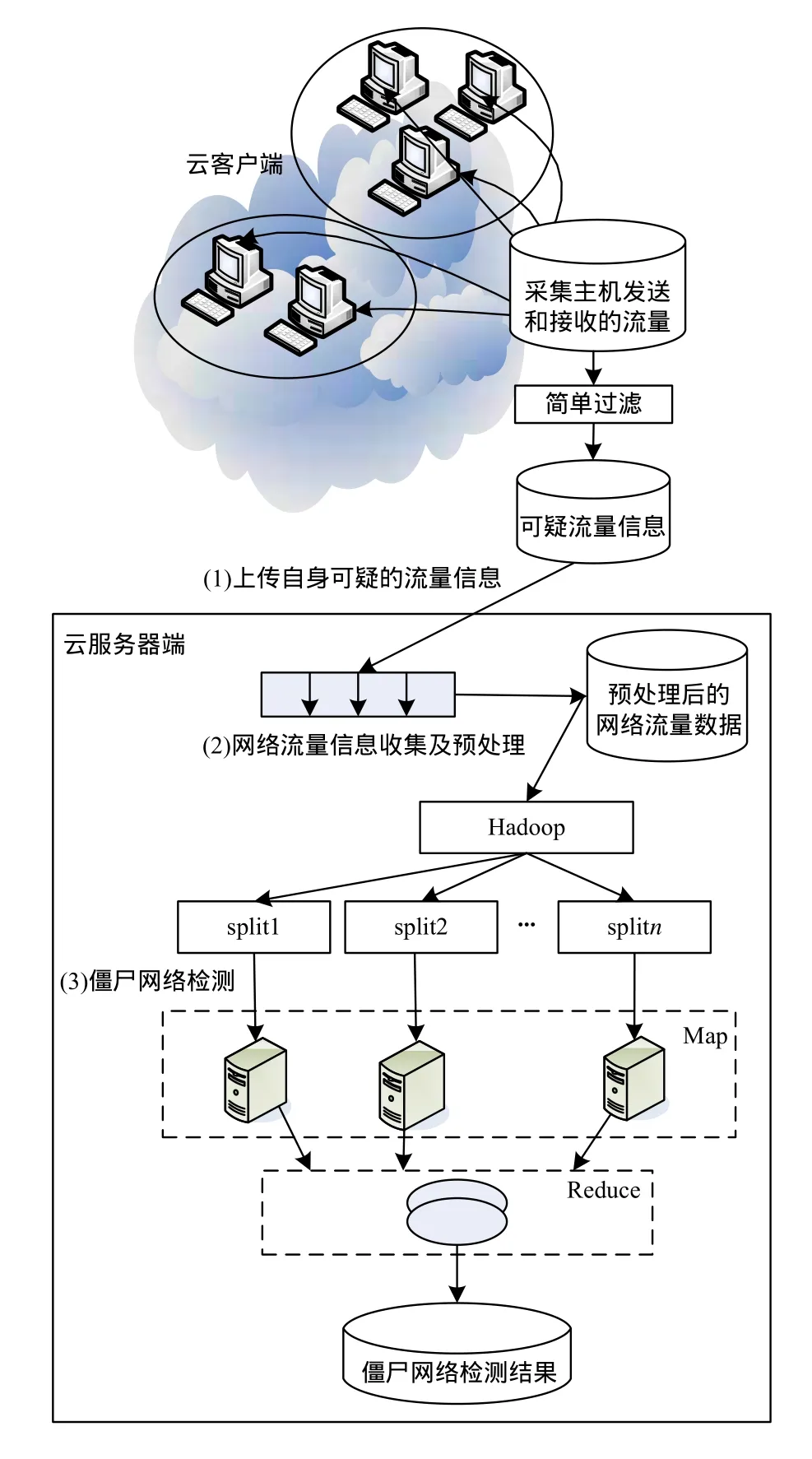
图1 僵尸网络云检测方法架构
本文云检测僵尸网络方法的执行流程如下:
(1)上传流量信息
云客户端运行流量信息采集和上传数据功能的程序,记录主机发送和接收的流量,并对其收发的数据包转换为流,然后统计流的信息,如流的持续时间、数据包个数、流的字节数等。僵尸网络具有以下主要特点:
1)僵尸主机要与控制端或其他僵尸主机之间交互信息,获取命令并上报攻击结果或者维持整个僵尸网络。
2)僵尸主机间的通信流量通常传递的是控制信息,不需传递大量的数据,故僵尸网络产生的流通常持续时间较短,且流中数据包个数较少[8-9]。
针对上述特点,本文设计云客户端把具有上述特征的可疑流量信息过滤掉,余下的信息上传到云服务器端,这样既可以减少网络传输的数据量,又可以降低云服务器端的计算量。
(2)网络流量信息收集及预处理
云服务器端首先收集所有客户端上传的网络流量信息,然后对流量预处理统计流的持续时间、数据包大小、个数等信息。
(3)僵尸网络的检测
将预处理后的网络流量数据上传至Hadoop,云服务器端利用MapReduce基于上述步骤的信息进行计算,以有效检测僵尸网络。
3 基于MapReduce的检测算法
对于预处理后的可信流信息,本文设计MapReduce对流间关联关系的并行算法,以实现对僵尸网络的检测。
3.1 基于流间关联关系的检测算法
僵尸主机通常维护一个邻居节点列表,且频繁依次访问列表中的节点,这一访问形成的流具有关联关系,而正常主机行为的访问流间不具有关联关系,因此,本文算法基于流间关联关系来检测僵尸网络[10]。然而,僵尸主机为逃避这种检测而故意不依次访问邻居列表中的节点,采取随机的方式遍历邻居列表中的节点,即每次访问邻居列表中节点的顺序不一样。如果僵尸主机采用随机的方式访问,则其形成的流会存在二级关联关系,但不一定存在多级关联关系。这样做是因为僵尸主机以随机的方式访问邻居列表中的节点时,虽然访问各个节点的流每次不会以相同的顺序出现,但这些流每次出现的时间间隔都很小,并且总是集中在一起出现,如果将这些流聚集到一个集合中,则该集合中的流都有关联。如僵尸主机H维护一个邻居节点列表,列表中有1~5个节点,H频繁访问列表中的节点以获取命令或者更新,但僵尸主机为逃避检测每次访问列表中节点的顺序不一样,H访问这些节点形成的流Fi(i为H邻居列表中的节点)两两之间会有二级关联关系,如F2在F3前出现,记为F2→F3,同理则有F3→F4、F4→F1、F2→F4、F2→F5等。将这些流聚集到一个集合中s1中,如图2所示。图中每个节点表示主机H访问其他主机形成的流,边表示2个流间的二级关联关系,如F1到F5有边,表示存在二级关联关系F1→F5、F5→F1。僵尸主机H访问其邻居列表中的节点形成的流F1~F5形成一个集合s1,同时,主机H的用户进行正常的网络访问形成的流F6~F8形成一个集合s2,F9和F10形成一个集合s3。
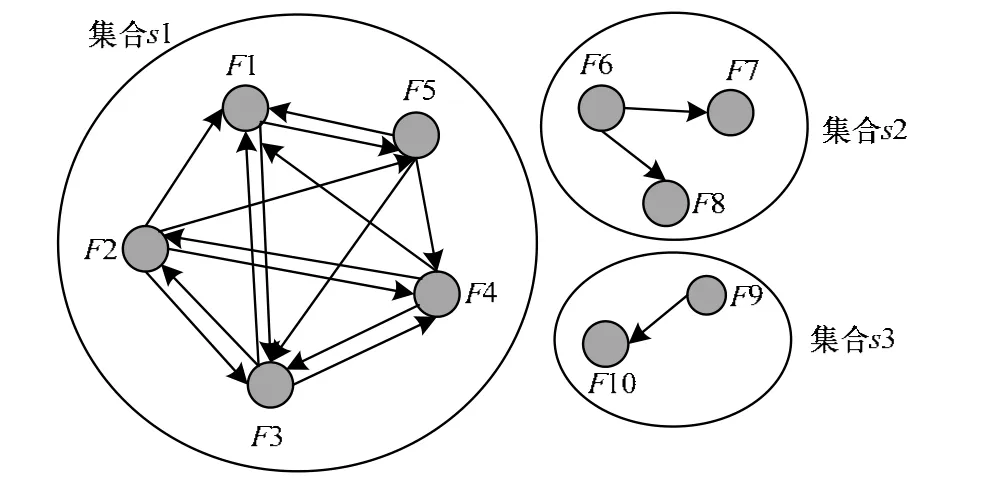
图2 僵尸主机H的流集合
在僵尸网络相关流F1~F5形成的集合s1中,各个节点的连接程度较紧密,而在合法流F6~F10形成的集合s2和s3中,各个节点的连接程度较松散,并且合法流形成的集合通常节点个数较少。为有效识别僵尸网络的流的集合,本文采用式(1)计算每个集合k的分数SCk:

本文提出的检测算法首先提取出每个云客户端的二级关联关系,再将二级关联关系的流划分到不同集合中,然后根据式(1)计算各个集合的分数,最后根据式(2)计算每个云客户端的分数:

其中,m为该云客户端的流所形成的集合总数。这里只考虑集合中元素个数nk大于nTh的集合,因为正常主机如果有两两相继出现的流,它们只会形成如图2中s2和s3这样小的集合,通常不会存在多个两两相继出现的流之间联系紧密的情况,而僵尸主机由于频繁访问邻居列表中的节点,访问不同节点形成的流之间,任意2个都会相继出现,因而僵尸主机的流的集合中元素个数较多,所以,式(2)中只考虑集合元素个数大于nTh的。如果SH较大,则该云客户端为可疑的僵尸客户端,本文设置一个阈值sTh,如果SH大于sTh,则认为该主机是僵尸客户端。
3.2 用于检测僵尸网络的MapReduce并行算法
该并行算法首先提取流间二级关联关系,然后再计算云客户端的分数。图3是本文僵尸网络检测的MapReduce任务过程。分3个任务Job1、Job2和Job3提取二级关联关系,Job4则计算云客户端的分数,这4个任务串行工作,前一个任务的输出是后一个任务的输入[11]。
图3中的流表示由云客户端上传给云服务器端预处理后的可信的流。其中,srcIP表示流的源IP地址;desIP表示流的目的IP地址;time表示流的开始时间,即第一个数据包到达的时间;split是Hadoop自动对输入文件的分块,每块默认大小为64 MB[12]。每个MapReduce任务都被初始化为一个任务,每个任务由Map阶段和Reduce阶段构成。分别用2个函数来表示,即Map函数和Reduce函数。Map函数接收一个<Key, Value>形式的输入,然后产生以<Key, Value>形式的输出。Hadoop会对Map的输出按关键字排序,并将关键字Key相同的Value集合传递给Reduce函数。Reduce函数接收一个形如<Key, list(Value)>形式的输入,然后对这个Value集合进行处理,最终Reduce的输出也是<Key, Value>形式[13]。
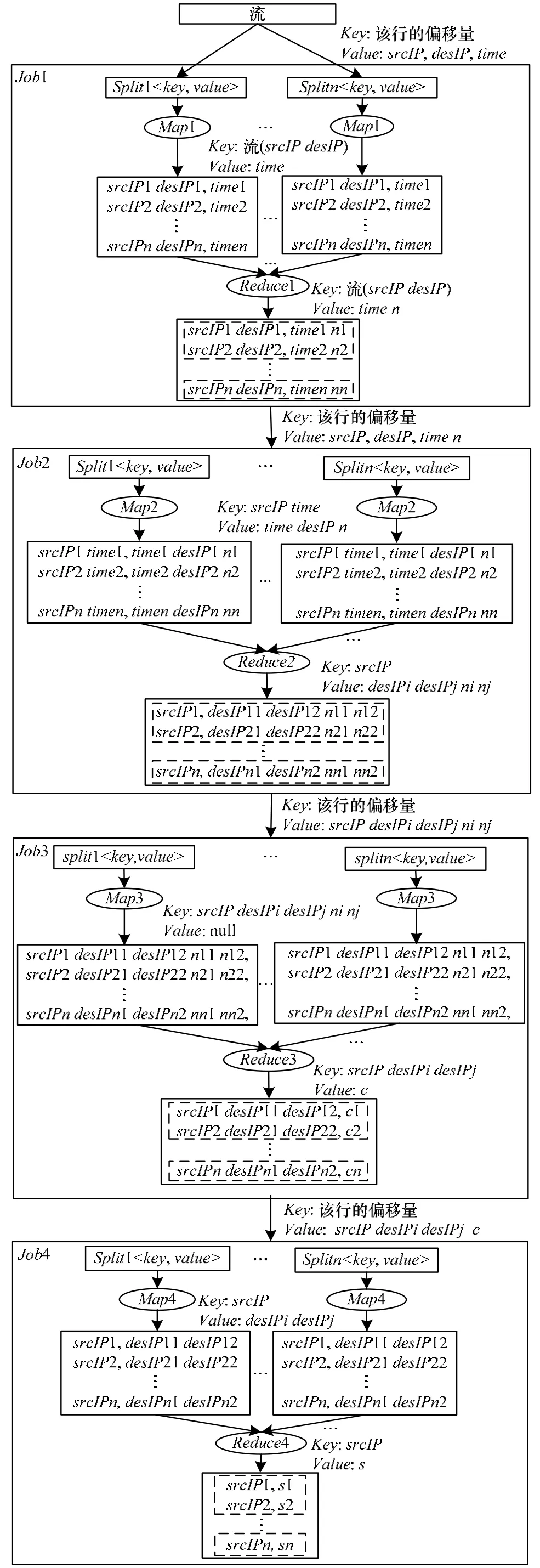
图3 用于僵尸网络检测的MapReduce任务过程
下面分别介绍各个任务:
(1)Job1计算流出现的次数
如果2个流总是相继出现,那么在同一个时间窗口内,这2个流出现的次数相差很小,因此,只考察在相同时间段内出现次数之差小于阈值nTh的流。提取关联关系时只需考虑流的3个属性:srcIP,desIP,time,用这3个属性标识一个流。Map1的输出将(srcIP desIP)作为键Key,将开始时间作为值Value,使相同的(srcIP desIP)分到同一个Reduce任务中。Reduce1读取Map1的中间结果,计算每对(srcIP desIP)的出现次数n。
(2)Job2提取候选二级关联关系
先按源IP地址对流进行分组,使每组内的源IP地址相同。对每个云客户端H,形成以H为源IP地址的一组流GH={fi}i=1,2,…,m。将GH中的流按照开始时间time排序,然后依次扫描每一个流,找出在当前流后出现,并且与当前流的时间间隔小于tTh的所有后续流。如果这些后续流的出现次数和当前流相差小于nTh,则这些流和当前流可能具有关联关系。假设找出x个满足上述2个条件的后续流,则分别将这x个后续流与当前流作为一对流记录下来,形成x个候选二级关联关系。
(3)Job3提取可信的二级关联关系
Job3从Job2读取候选二级关联关系,计算每个关联关系的置信度,如果置信度大于阈值,则认为该关联关系是可信的。Map3输入的Key为该行的偏移量,Value为Job2的输出,即候选二级关联关系。Map3输出的Key为候选二级关联关系,值为空则以候选二级关联关系作为键。Reduce3统计相同候选二级关联关系出现的次数,并计算置信度,最后输出置信度大于阈值的二级关联关系,从而找出可信的二级关联关系。Reduce3的输入为Map3的输出,Reduce3的输出为可信的二级关联关系,格式为(srcIP desIP1 desIP2, c),其中,c为二级关联关系的置信度,只输出置信度大于阈值的。
(4)Job4计算云客户端的分数
Map4输入的是Job3的输出,即置信度大于阈值的二级关联关系。由于每个云客户端的分数SH可以并行计算,因此Map4输出的Key是srcIP,Value是(desIP1 desIP2),即二级关联关系中的目的IP地址。Reduce4的工作就是将每个srcIP对应的具有二级关联关系的流划分到不同集合中,使每个流与所在集合中至少一个流有关联关系,然后计算各个集合的分数SC和云客户端的分数SH。Reduce4的输入为Map4的输出,Reduce4的输出是云客户端的分数,格式为(srcIP, S)。
4 实验及结果分析
本文实验环境配置为9台双核计算机,2.9 GHz CPU, 4 GB内存。基于Oracle VM VirtualBox4.1.12的虚拟化平台,每台虚拟机安装Ubuntu 10.10操作系统,Hadoop云平台的版本为Hadoop 0.20.2,代码编译版本为JDK1.6.0_22。整个Hadoop集群有1个Master节点、8个Slave节点。各个虚拟机之间采用桥接的网络方式连接。Hadoop环境配置如下:数据块大小设为64 MB,每个节点可以同时执行的最大Map任务数和最大Reduce任务数均设为3。
本文参考模拟生成启发的数据集。实验模拟了云服务器端收集到的流量,包括合法流量和僵尸网络流量。合法流量以某校园网内的流量为基础,模拟了云客户端之间通信的流量,并将其作为背景流量。模拟的背景流量中主机个数为36 323个,流个数为1 191 368个。模拟的僵尸网络模型根据大量文献总结得到,即僵尸主机维护一个节点列表并频繁访问列表中的节点以获取命令或者更新。本文实验模拟的僵尸网络中每个僵尸主机维护一个节点列表,列表中节点个数最大值为15,最小个数为10。每个僵尸主机间隔一个295 s~395 s范围内的随机时间访问列表中的节点,访问列表中前后2个节点的时间间隔的最小值为0.1 s,最大值为1 s。实验中模拟的僵尸主机总数为100个。
实验1 分析本文检测算法的检测率和误报率随主机分数阈值sTh增大而变化的情况,结果如表1所示。可以看出,随着sTh的增大,检测率降低,误报率降低。这是因为当sTh增大时,一些僵尸客户端的SH分数小于sTh而未能被检测出来,因而检测率DR减小。随着sTh的增大,SH大于sTh的正常客户端个数减少,因而误报率降低。因此,sTh取0.6或0.7效果较好。

表1 sTh变化时的检测率和误报率 %
实验2 分析云服务器端中计算节点个数增大时基于MapReduce的僵尸网络算法的运行时间和加速比的变化情况。为分析算法处理不同规模网络流量数据时的运行时间和加速比,实验中模拟了包括数据集、运行客户端个数和文件大小数据集信息:(D1, 312 250, 85.97 MB),(D2, 624 500, 373.13 MB),(D3, 1 249 000, 759.02 MB)。加速比speedup是指数据集固定,不断增大计算节点个数时算法并行的性能,其计算如式(3)所示:

其中,p是计算节点个数;T1是一个节点时的运行时间;Tp是p个节点时的运行时间。
分别取数据集D1、D2和D3进行实验,Tp取3次实验的平均值。
节点数增大时本文算法的运行时间如图4所示,可以看出,随着计算节点个数的增大,处理相同数据集算法的运行时间不断减少,并且数据集越大所需的运行时间越小。
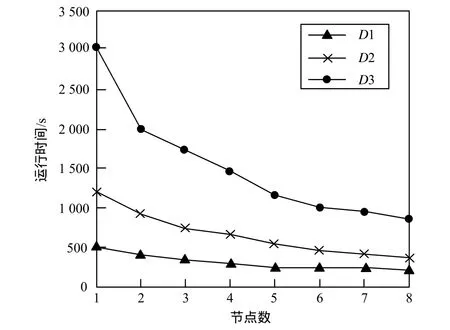
图4 运行时间
本文算法的加速比如图5所示。在理想情况下,并行算法的加速比是呈线性的,即一个节点的运行时间是p个节点的p倍,但实际的加速比要低于理想状态。由该图可以看出,数据集D1的加速比最小,D3的加速比最大,这是因为数据量较小时,部分节点处于空闲状态,随着数据规模的增大,加速比更接近线性,但没有达到线性是因为节点间通信,任务启动、调度等开销。由此可见,云服务器端计算节点增大时,能更高效地处理云客户端上传的数据,并且适合于处理云客户端规模较大的情况。
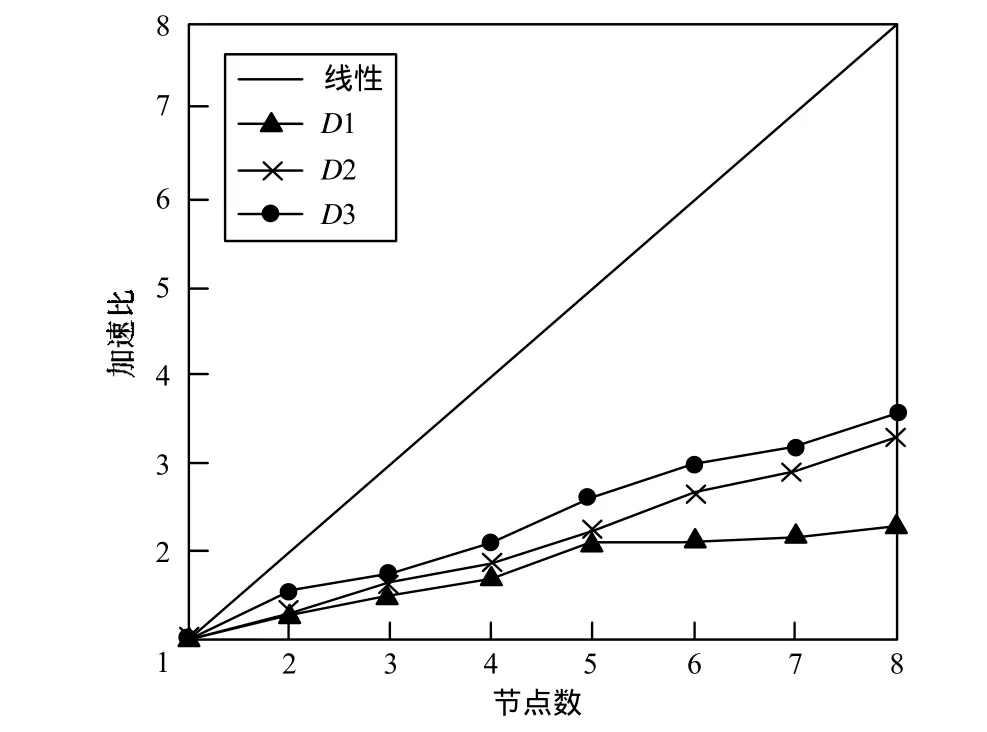
图5 加速比
5 结束语
本文提出的算法基于关联关系在云环境下完成了对僵尸网络的检测,使云客户端上传自身可疑的流量信息到云服务器端,云服务器端收集上传的流量信息,并对流量进行汇总处理,然后利用基于MapReduce的并行算法实现僵尸网络的检测。实验结果表明,该算法可得到较高的检测率和较低的误报率,并能提高检测效率。下一步工作将改进基于云计算的僵尸网络检测算法,实现在线检测。
[1] 李鹤帅, 朱俊虎, 周天阳, 等. P2P技术在僵尸网络中的应用研究[J]. 计算机工程, 2012, 38(14): 1-4.
[2] Yu Xiaocong, Dong Xiaomei, Yu Ge, et al. Online Botnet Detection Based on Incremental Discrete Fourier Transform[J]. Journal of Networks, 2010, 5(5): 568-575.
[3] 于 戈, 谷 峪, 鲍玉斌, 等. 云计算环境下的大规模图数据处理技术[J]. 计算机学报, 2011, 34(10): 1753-1767.
[4] 黄德才, 戚华春. PageRank算法研究[J]. 计算机工程, 2006, 32(4): 145-162.
[5] 冯登国, 张 敏, 张 妍, 等. 云计算安全研究[J]. 软件学报, 2011, 22(1): 71-83.
[6] 陈丹伟, 黄秀丽, 任勋益. 云计算及安全分析[J]. 计算机技术与发展, 2010, 20(2): 99-103.
[7] Shoham S. Robust Clustering by Deterministic Agglomeration EM of Mixtures of Multivariatet——Distributions[J]. Pattern Recognition, 2002, 35(5): 1127-1142.
[8] 吴兆峰, 周海刚, 余哲赋, 等. 基于TCP 会话的僵尸流量特征分析与检测[J]. 军事通信技术, 2012, 33(1): 23-26.
[9] 王劲松, 刘 帆, 张 健. 基于组特征过滤器的僵尸主机检测方法的研究[J]. 通信学报, 2010, 31(2): 29-35.
[10] 张国强, 张国清. Internet 网络的关联性研究[J]. 软件学报, 2006, 17(3): 490-497.
[11] 覃雄派, 王会举, 杜小勇, 等. 大数据分析——RDBMS 与MapReduce的竞争与共生[J]. 软件学报, 2012, 23(1): 32-45.
[12] 栾亚建, 黄翀民, 龚高晟, 等. Ha doop 平台的性能优化研究[J]. 计算机工程, 2010, 36(14): 262-263, 266.
[13] 李成华, 张新访, 金 海, 等. MapRe duce: 新型的分布式并行计算编程模型[J]. 计算机工程与科学, 20 11, 33(3): 129-135.
编辑 金胡考
Botnet Detection Based on Correlation Relation and MapReduce
SHAO Xiu-li1, JIANG Hong-ling1, GENG Mei-jie1, LI Yao-fang2
(1. College of Information Technical Science, Nankai University, Tianjin 300071, China; 2. College of Computer and Information, Tianjin Chengjian University, Tianjin 300384, China)
Existing botnet detection methods ge nerally have lar ge amount of computation, which r esults in low det ection efficiency. Cloud computing provides new ideas and solutions for the detection of botnets because of its power capacity of data processing and analysis capabilities. Therefore, this paper designs and implements a para llel botnet detection algorithm ba sed on MapR educe model, which uses cloud collaboration and flo w correlation relation to detect botnets. It extracts the relationship between flows, gathers the fl ows having relationship, and calculates the scores of hosts. The hosts whose score is greater than a threshold are suspicious bots. Experimental results show that this algorithm is effective for detecting botnet. The detection rate of P2P botnet can reach more than 90%, and the false alarm rate belows 4%. With the cloud server-side computing nodes increasing, the process of cloud client to upload data and botnet detection is more efficient.
botnet; cloud computing; correlation relation; MapReduce model; Hadoop cloud platform
10.3969/j.issn.1000-3428.2014.05.024
国家科技支撑计划基金资助项目(2012BAF12B00);天津市重点基金资助项目(11JCZDJC28100, 12ZCDZGX46700)。
邵秀丽(1963-),女,教授、博士生导师,主研方向:网络安全,云计算,软件工程;蒋鸿玲,博士研究生;耿梅洁,硕士研究生;李耀芳,讲师。
2013-04-02
2013-05-29E-mail:shaoxl@nankai.edu.cn
1000-3428(2014)05-0115-05
A
TP309
