基于CUDA的热传导GPU并行算法研究
2014-08-05孟小华黄丛珊朱丽莎
孟小华,黄丛珊,朱丽莎
(暨南大学 a. 计算机科学系;b. 天体测量、动力学与空间科学中法联合实验室,广州 5 10632)
基于CUDA的热传导GPU并行算法研究
孟小华a,b,黄丛珊a,朱丽莎a,b
(暨南大学 a. 计算机科学系;b. 天体测量、动力学与空间科学中法联合实验室,广州 5 10632)
在热传导算法中,使用传统的CPU串行算法或MPI并行算法处理大批量粒子时,存在执行效率低、处理时间长的问题。而图形处理单元(GPU)具有大数据量并行运算的优势,为此,在统一计算设备架构(CUDA)并行编程环境下,采用CPU和GPU协同合作的模式,提出并实现一个基于CUDA的热传导GPU并行算法。根据GPU硬件配置设定Block和Grid的大小,将粒子划分为若干个block,粒子输入到GPU显卡中并行计算,每一个线程执行一个粒子计算,并将结果传回CPU主存,由CPU计算出每个粒子的平均热流。实验结果表明,与CPU串行算法在时间效率方面进行对比,该算法在粒子数到达16 000时,加速比提高近900倍,并且加速比随着粒子数的增加而加速提高。
热传导算法;图形处理单元;统一计算设备架构;并行计算;时间效率;加速比
1 概述
热传导算法可以运用于很多领域,如建筑工程对各种材料的研究和选择,以及地质勘探研究等方面,几乎所有的材料成形模拟过程都涉及热传导,但是国内的材料成形模拟大多仍停留在单机串行求解问题的水平上。随着模拟工程的规模不断增长,工程应用对材料成形模拟软件的性能要求不断提高。为了满足实际需求,需要实现并行化,以提高性能和求解大型问题的能力[1],因此如何提高算法的执行效率已经成为当前的一个重要的研究课题。在最近十年中,传统的单CPU串行算法或者MPI并行算法被广泛用来计算热传导中粒子的平均热流和平均温度,当粒子的数量太大时,这2种算法的执行时间太长。虽然图形处理单元(Graphic Processing Unit, GPU)原本只用在图形处理方面,但是现在它们已经越来越多地用于通用的科学和工程计算[2],尽管如此,关于热传导的GPU并行处理的研究仍然不多。文献[3]利用GPU的强大浮点运算能力来求解有关线形热传导和各向异性扩散的有限元方程。文献[1]研究了二维热传导GPU并行化处理方案,总结出一个最优策略:将整个粒子计算域划分成恰当数量的网格块,每个网格块粒子的计算由GPU并行执行,粒子处理效率将会提高。
本文通过参考已有的研究,即利用GPU强大的并行处理和浮点运算能力,以有效地提高热传导算法的执行效率,并基于CUDA编程环境提出一种热传导GPU并行算法。
2 热传导CPU串行计算研究
2.1 热传导算法的理论背景
热传导指的是,由大量物质的分子热运动互相撞击,温度较高的分子(粒子)与相邻的温度较低的分子碰撞,而使能量从物体的高温部分传至低温部分,或由高温物体传给低温物体,直到温度(热流)平衡的过程[4]。
由热的基础理论知道,热和物体的内能总是有密切的关系,在热力学中,物体的内能是属于物质内分子和原子的取向以及与运动有关的能量。因此,物体的热传导本质上和组成物体的微观粒子的作用力、运动位移、运动速度等密切相关。本文热传导系统中的研究对象是分子结构(粒子)。
2.2 C PU串行算法的实现
CPU串行算法是过去解决热传导问题常用的算法,根据热传导的理论的计算特点,本文用一维分子结构系统来模拟一维热传导的过程,算法的流程如图1所示。
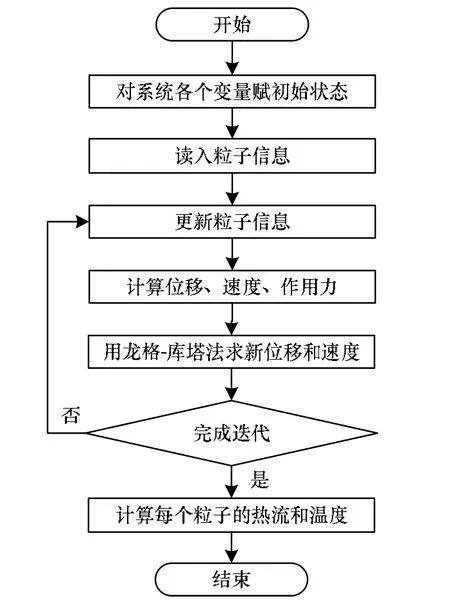
图1 C PU串行算法流程
CPU串行算法主要步骤如下:
(1)先初始化速度、作用力、位移、热流、温度等数组。
(2)读入所用到的初始变量值,时间间隔dt=0.01,质量m=1.0,系数k=1.0,kb=1.0,第一个粒子的初始温度T1=2,最后一个粒子的初始温度T2=1。
(3)分步计算每个粒子的位移、速度、相互作用力,以及温度和热流;由于龙格-库塔(Runge-Kutta)方法可以提高算法的精确度[5],因此采用龙格-库塔法求粒子的位移和速度。
(4)计算每个粒子的平均热流和平均温度。
3 GPU并行计算
3.1 GP U与CPU架构
随着计算机技术的不断发展,人们尝试在每个计算节点装备多路CPU,而在每个CPU芯片中也开始采用多核技术来提升CPU芯片的整体计算效率。CPU和GPU都是具有运算能力的芯片,但两者功能的侧重点不同,CPU是一个计算机的核心部件,它既执行指令运算又可以进行数值运算。GPU是目前使用很广泛的显卡的图形处理器,已经成为强大的通用并行处理单元,它是显卡的核心,专注于浮点运算、并行数值计算等方面。图2说明了CPU和GPU在架构上的区别[6]。

图2 C PU和GPU的架构区别
从图2中看出,CPU进行串行运算,负责处理一条一条的数据,控制单元、逻辑单元和存储单元三大部分相互协调,进行分析、判断、运算并控制计算机各部分协调工作。GPU使用更多的单元进行并行数值计算,从收到数据到完成所有处理的全过程都可以完全独立的并行处理。因此,对于大规模运算平行处理,GPU相对CPU具有优势[7]。
CUDA是NVIDIA推出的通用并行计算架构,广泛应用在Windows、Linux等不同的应用环境。CUDA采用C语言作为编程语言,且提供大量高性能计算指令的开发能力,可在GPU强大计算能力的基础上建立一种效率更高的密集数据计算解决方案[8]。CUDA使得GPU对科学应用来说完全可编程并对高级语言(如C、C++、Fortran等)加以支持。CUDA将GPU作为数据并行计算设备,操作系统的多任务机制负责管理多个并发运行的CUDA和图像应用程序对GPU的访问,应用程序中精深复杂的计算和图形部分运行在GPU上,而简单的、连续的部分运行在CPU上。
3.2 GP U-CPU并行计算
GPU-CPU协作计算模式已成为普通PC机所拥有的强大、高效的计算模式。根据NVIDIA公司最近的测试结果显示:利用GPU-CPU模式进行傅里叶变换、排序等科学计算比单独用CPU计算的速度提高了19倍[9]。但是GPU-CPU协同模式也存在很多未解决的问题。虽然GPU在通用计算中有了很大的发展,但是和真正通用的CPU在结构、指令流处理等方面差别还较大。其次,用GPU-CPU模式进行并行计算缺少统一的编程模型。
4 热传导并行算法
4.1 M PI——一种典型的热传导并行算法
在GPU通用计算未普及之前,MPI并行算法是最常用的热传导算法。MPI并行算法是基于消息传递模式的并行计算方法。在MPI这种模式下,使用一个或多个进程间的通信调用库函数发送、接收消息从而完成并行计算。消息传递模式使用通信协同的方式,源进程调用库函数发送数据,目的进程调用相应的库函数接收数据[10]。
MPI的优点在于可在任何并行机上运行,并且用户可以显式地操作并行程序的存储;但是热传导MPI并行算法也很明显:(1)消息传递接口的不同有时对算法产生很大的影响;(2)实际消息传递中的带宽、延迟以及计算于通信的重叠会极大地影响并行算法性能;(3)MPI算法对硬件的要求比较高,而一般热传导算法在应用上可能用不到那么高要求的硬件。
根据以上分析知道,热传导MPI并行算法的不足是由MPI并行计算的特点决定,因此在MPI机制下无法改进。为了提高算法运行的可靠性及降低对硬件的要求,本文提出一个新的并行计算的方法——GPU并行算法。
4.2 热传导GPU并行算法
在本文提出的GPU并行算法[11]中,GPU并行是指GPU硬件上的并行,CPU负责控制程序的主流程,由GPU负责并行计算。该算法能弥补MPI并行算法存在的缺陷,解决以往热传导算法存在的问题,同时在较小的硬件开销下大大提高算法的运行效率。
要进行GPU并行计算,必须具备以下的3个条件:
(1)一台具备GPU并行计算平台的计算机,该计算机具有支持CUDA编程的显卡。
(2)并行的算法必须具备可并行性,可以找出可并行执行的子任务。
(3)在上述2个条件满足的前提下,在GPU并行计算机上编写GPU并行程序,并且运行该程序。
4.2.1 算法原理
本文针对GPU的计算特点及热传导粒子间相互作用关系的特点,设计一种GPU并行程序采用元胞单元法来组织数据。元胞单元法是将模拟计算区域划分为一系列线程网格Grid,每个线程网格中包含多个粒子;由于粒子的状态只和相邻的2个粒子状态有关,它具有近程性,因此与一个粒子有关的粒子只需要在同一个线程网格或是相邻的线程网格中寻找即可,而不需要在整个计算区域里寻找[12]。
考虑到如果粒子在不同的线程网格中,它的状态计算会使对应的内存开销以及粒子状态传递的操作数增多,因此,本文算法将所有的粒子划分在一个线程网格Grid中,一个粒子的计算对应一个线程。多个线程组成一个Block(块),Block(块)数目和每个Block中的Thread数目可根据粒子的具体数目进行调整,以达到最好的算法效率。算法设计在GPU中将粒子按照数目规模划分为若干个网格,每执行一步共享内存中数据同步一次。200 000步后计算结果数据传回CPU,计算出每个粒子的平均热流量。
考虑到本文所设计的GPU并行算法要求在同一个线程网格内进行操作,可将对粒子信息的存储用预先固定大小的数组存储线程网格内粒子的状态信息,这种方式可以很好地避免上一种方案的缺陷,还可以连续、并行地访问内存。但是这些数组的大小必须够大,可以存储所有粒子的所有状态信息。这必然导致这些数组占用的内存信息较大。
上述设计得到GPU并行算法的内核函数执行时的线程块、线程于计算粒子间的对应关系如图3所示。
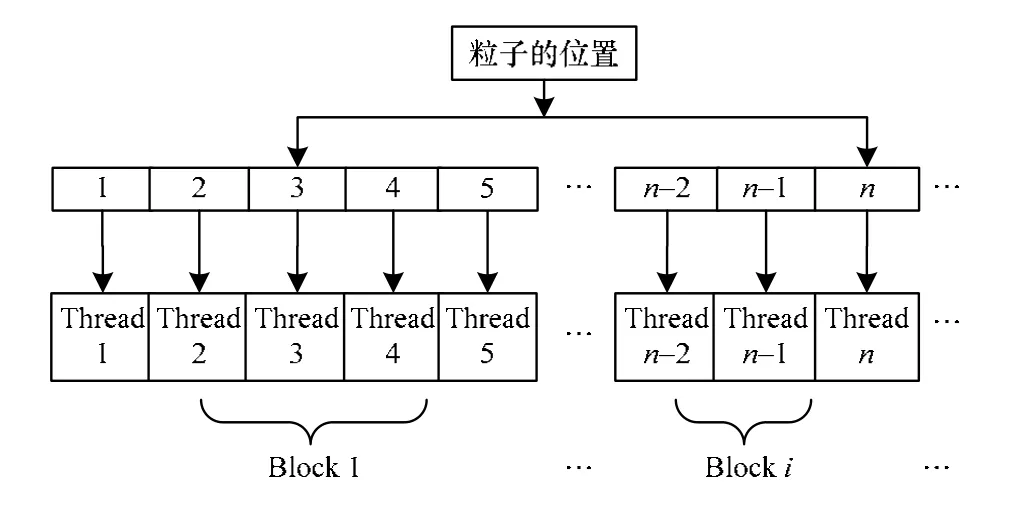
图3 内核函数执行时的线程块、线程与粒子间的对应关系
基于上述理论,可以把整个热传导GPU并行算法的执行过程描述如下:(1)初始化及粒子状态信息读入;(2)建立粒子到线程网格的映射;(3)在具体的每个步中计算粒子的状态。设计的热传导GPU并行算法的算法流程如图4所示。
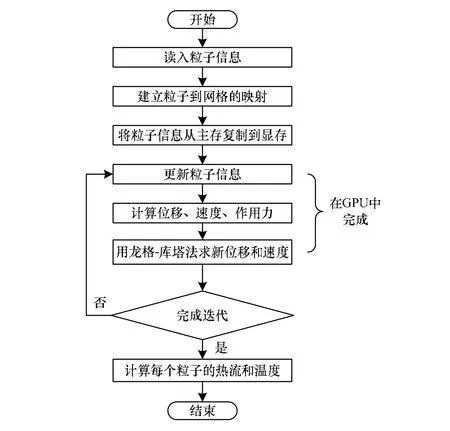
图4 热传导GPU并行算法流程
在此算法的3个主要部分中,计算粒子的状态是整个算法中耗时最长的部分,约占据整个算法的80%,这部分由GPU完成,而其他部分由CPU完成,这正好体现了GPU程序设计的初衷:将并行部分放在GPU上执行,串行主线部分放在CPU上执行。由于GPU不能直接访问主储存器,而CPU不能直接访问显存,因此计算完粒子状态后,需要将显存中的数据信息传到CPU中,以便CPU完成接下来的操作。为了避免每个时间步都进行CPU到GPU及GPU 到CPU的2次数据交换操作,CPU在开始计算前读入所有参与计算的粒子状态信息,再将这些信息映射到相应的线程块,传递给GPU,由GPU处理完算法中的所有模块。
4.2.2 线程分配的设计
在CUDA中所用到的线程只是轻量级的线程,因此可以有上千个线程同时在执行。在GPU并行算法中,对于相同的粒子数目,每个线程网格内的粒子数越多,相应的线程块数越少,则计算的时间越少。在GPU中,每个线程网格Grid中的线程块Block数最多有65 535×65 535个,每个线程块中的线程个数最大限制为512个。根据上述GPU特性,本文算法设计线程网格数为1,线程块数也尽量少。每个粒子各占一个线程,这样使得GPU中的资源可以实现最大化的并行计算。
5 实验结果与分析
5.1 实验结果
实验环境为联想S20的图形工作站;CPU:Intel(R) Xeon(R) CPU W3550@3.07 GHz 3.06 GHz;GPU:NVIDIA Quadro FX 1800。在同一个实验平台下分别对本文所涉及的2种算法——热传导CPU串行程序及热传导GPU并行程序进行测试及对比。
对于CPU串行算法,主要测试它在不同粒子数时的时间性能。粒子数取值分别是16、160、1 600、16 000、160 000,测试结果如表1所示。
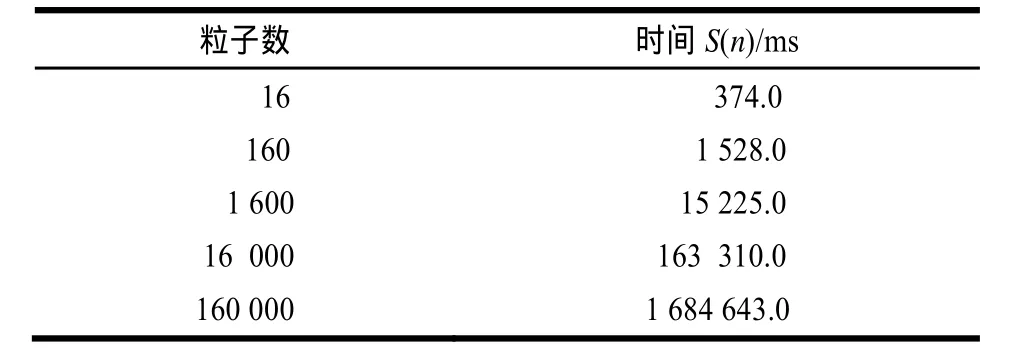
表1 C PU串行算法的时间性能测试结果
对于GPU并行算法,主要测试它在不同粒子数时的总时间性能、通信协同时间及GPU上的并行计算时间。粒子数取值同CPU串行算法一致,所得测试结果如表2所示。

表2 G PU并行算法的时间性能测试结果
5.2 串行和并行算法在时间效率上的比较
根据5.1节的实验数据比较2种算法的时间效率,如图5所示,粒子的个数分别为16×10、16×100、16×1 000、 16×10 000、16×100 000。从图中容易看出,当系统中粒子数目不大时,并行算法没有较明显的优势,但随着粒子数目成指数倍地增长时,GPU并行算法处理粒子的效率远高于CPU串行算法。

图5 2种算法的时间效率比较
5.3 GP U并行算法的性能分析
GPU并行算法的性能优劣主要由加速比及并行算法的伸缩性决定,因此,本文实验重点测试并比较这2个因素。
(1)加速比
加速比的公式为:C(n)=S(n)/P(n),其中,S(n)是CPU串行算法的运行时间;P(n)是GPU并行算法的运行时间。
根据5.2节的实验数据,得到加速比如表3所示。

表3 G PU并行算法在不同粒子数下的加速比
由表3可知,随着粒子数的增加,GPU并行算法的加速比大幅增加,因此可以得出,在有较大规模粒子数时,GPU并行算法能更好地发挥其优势。
(2)并行算法的伸缩性
当处理器数目一定时,算法规模越大,加速比越高,则称此并行算法具有良好的伸缩性。从实验结果上很容易看出,本文的热传导GPU并行算法具有伸缩性。
6 结束语
本文提出一个GPU并行算法,并基于CUDA的编程环境使用C语言实现了一维体系热传导算法。通过对一维分子结构体系模型进行研究,引入龙格库塔法,运用它求出每一个粒子的速度、力、位移,最后计算出每个粒子的平均热流量。通过实验对比分析,结果表明,在大批量处理粒子数时,相对于传统CPU串行算法,GPU并行算法在加速比方面可以提高近900倍,并且加速比随着粒子数的增加而加速提高。这充分证明了GPU的并行处理能力的优势。
GPU的发展势头异常迅猛,随着时间的推移,以及人们对计算机并行处理能力要求的进一步提高,通过基于CUDA的GPU并行处理热问题会越来越多,因此,如何提高GPU的并行计算能力将是未来学者们的一个重要研究课题。相信随着硬件的不断发展,GPU的处理能力也将进一步提高。虽然本文提出的一维热传导GPU并行算法较之前的CPU串行算法在时间效率上提高了几百倍,但这还远没有发挥出GPU并行计算的优势。若将此算法扩展为GPU集群上的并行算法,那么计算能力会比单GPU的算法能力强得多,下一步将研究工作环境更高的加速比。
[1] 王 梁. 二维稳态热传导问题CPU/GPU并行求解[EB/OL]. [2013-05-13]. http://tech.it168.com/a2010/0722/1081/0000010 81200.shtml.
[2] Frezzotti A, Ghiroldi G P. Solving the Boltzmann Equation on GPUs[EB/OL]. (2010-05-28). http://arxiv.org/abs/1005.5405.
[3] Rumpf M, Strzodka R. Usin g Graphics Cards for Quantized FEM Computations[C]//Proceedings of VIIP’01. Marbella, Spain: [s. n.], 2001: 98-107.
[4] 百度百科. 热传导[EB/OL]. [2013-05-13]. http://baike.baidu. com/view/348360.htm.
[5] 李夏云, 陈传淼. 用龙格-库塔法求解非线性方程组[J].数学理论与应用, 2008, 28(2): 62-65.
[6] 林 茂, 董玉敏, 邹 杰. GPGPU编程技术初探[J]. 软件开发与设计, 2010, (2): 15-17, 23.
[7] 孙敏杰. C PU架构和技术的演变看GPU未来发展[EB/OL]. [2013-05-13]. http://www.pcpop.com/doc/0/521/521832_all.sh tml.
[8] 孟小华, 刘坚强,区业祥. 基于CUDA的拉普拉斯边缘检测算法[J]. 计算机工程, 2012, 38(18): 190-193.
[9] 李 超. 论GPU-CPU协作计算模式的应用研究[J]. 电子商务, 2010, (11): 54.
[10] 郁志辉. 高性能计算并行编程技术-MPI并行程序设计[M].北京: 清华大学出版社, 2001.
[11] 朱丽莎. 基于GPU的一维体系热传导算法研究[D]. 广州:暨南大学, 2011.
[12] 朱宗柏. 多重网格方法的并行化及其在传热数值分析中的应用[J]. 武汉交通科技大学学报, 2000, 24(4): 351-354.
编辑 任吉慧
Research on GPU Parallel Algorithm of Heat Conduction Based on CUDA
MENG Xiao-huaa,b, HUANG Cong-shana, ZHU Li-shaa,b
(a. Department of Computer Science; b. Sino-France Joint Laboratory for Astrometry, Dynamics and Space Science, Jinan University, Guangzhou 510632, China)
For real applications processing lar ge volume of particles in one-dimensional heat conduction problem, the response time of CPU serial algorithm and MPI parallel algorithm is too long. Considering Grap hic Processing Unit(GPU) of fers powerful paral lel processing capabilities, it implements a GPU parallel heat conduction algorithm on Compute Unifie d Device Architecture(CUDA) parallel programming environment using CPU and GPU collaborative mode. The algorithm sets the block and grid size based on GPU hardware configuration. Particles are divided into a plurality of blocks, the particle is into the GPU graphics for parallel computing, and one thread performs a calculation of a particle. It retrieves the processed data to CPU main me mory and calculates the average heat flow o f each particle. Experimental results sho w that, compared with CPU serial algorithm, GPU parallel algorithm has a great advantage in t ime efficiency, the speedup is close to 900, and speedup can improve as the particle number size increases.
heat con duction algorithm; Graph ic Processing Unit(GPU); C ompute U nified D evice A rchitecture(CUDA); parallel computing; time efficiency; speedup ratio
10.3969/j.issn.1000-3428.2014.05.009
国家自然科学基金资助项目(61073064)。
孟小华(1965-),男,副教授、硕士,主研方向:并行分布式系统;黄丛珊,硕士研究生;朱丽莎,硕士。
2013-02-26
2013-05-21E-mail:xhmeng@163.com
1000-3428(2014)05-0041-04
A
TP399
