基于NoC分布式多核系统中任务迁移的实现
2014-08-05付方发刘钊池来逢昌
王 良,付方发,刘钊池,来逢昌
(哈尔滨工业大学微电子中心,哈尔滨 1 50001)
基于NoC分布式多核系统中任务迁移的实现
王 良,付方发,刘钊池,来逢昌
(哈尔滨工业大学微电子中心,哈尔滨 1 50001)
为降低多核系统中任务迁移的开销,在片上网络分布式多核系统的基础上实现一种低开销的任务迁移方案。借助于多核消息传递接口模型中并行程序与任务映射无关的特点,采用更新任务映射表的方式完成任务的重新映射,通过在μC/OS-II操作系统中传递任务的堆栈以及任务控制块实现任务状态在多核节点间的传递,任务迁移到另一节点后能够恢复原来的状态继续执行,不需要传递任务代码,并且任务状态的保存不需要迁移点。实验结果证明,该任务迁移方案能够及时响应任务迁移请求,具有低开销的特点,可较好地满足系统中任务的实时性要求。
分布式多核系统;任务迁移;低开销;多核消息传递接口;任务映射表;迁移点
1 概述
片上系统(System on Chip, SoC)逐渐向多核化发展,构成了多处理器片上系统(Multiprocessor System o n Ch ip, MPSoC)[1]。为了能够有效地利用多核资源,最大程度地发挥多核的性能,需要对通信和计算资源进行有效的管理。任务迁移是一种有效的动态资源管理方法[2],它可以在系统运行过程中把一个任务或进程从当前运行的PE(Processing Element)转移到另外一个PE并且能够恢复执行。目前,MPSoC中任务迁移主要用于计算和通信的负载平衡[3-4]、容错[5]以及温度控制[6]等方面。任务迁移最开始出现在分布式计算机领域并取得了广泛的研究成果[7]。基于片上网络(Network on Chip, NoC)[8]的MPSoC充分借鉴了分布式计算机通信的特点,具有分布式的存储结构。与分布式计算机相比,基于NoC的MPSoC的通信资源以及各个节点的存储资源都非常有限,而任务迁移过程中整个任务通过NoC传输有着较大的通信开销,因此,在并行计算机中的任务迁移研究结果并不能直接移植到MPSoC中。
为了能够合理地评估任务迁移的开销并且提出相应的方案降低迁移开销,研究者通常在NoC模拟器模拟任务迁移或在多核平台实现任务迁移。文献[9]是在基于SystemC 的NoC模拟器中模拟任务迁移,使用拷贝模型作为任务迁移模型,该模型可以评估任务迁移传输数据和代码的时间以及功耗,但是没有真正地实现任务迁移。文献[10]是在MPARM多核仿真平台实现任务迁移,各个核运行µClinux操作系统,任务迁移是基于迁移点迁移方法,在程序中添加多个迁移点,任务执行过程中只有遇到迁移点才会检查是否收到迁移请求,如果是,那么保存并发送任务状态进行务迁移。文献[6]是在基于FPGA的多核仿真平台中实现任务迁移,每个核运行µClinux操作系统,迁移同样也采用迁移点方法实现,与文献[10]不同的是,该任务迁移方案不需要传递任务代码,因为各个核都有一份任务代码的复制,并且一个任务在同一时刻只能在一个核上执行,这样虽然需要较大的存储空间保存任务代码,但是却节省了迁移时传输代码和分配空间的时间。文献[11]在HeMPS多核仿真平台上实现任务迁移,操作系统为micro kernel,与文献[6]和文献[10]不同,任务迁移的实现不需要迁移点,但是迁移过程中不仅把任务的数据和上下文传递到目的节点,还需要传递任务的代码。
综上,基于迁移点方法的任务迁移需要频繁地检查是否收到任务迁移请求,导致任务正常执行时间增加,并且任务只有遇到迁移点才可能进行迁移,不能及时响应任务迁移请求。而文献[11]虽然不需要迁移点,但是与文献[10]相比,任务代码的传递增大了MPSoC的通信开销和任务的执行时间。因此,在基于NoC的MPSoC中亟需设计一种低开销的任务迁移机制,在完成任务迁移目的的同时,能够对系统性能的影响达到最小。
本文提出一种低开销的任务迁移方案,借助多核消息传递接口模型(MPSoC Message Passing Interface, MMPI)[12]中并行程序与任务映射无关的特点,采用更新任务映射表的方式完成任务的重新映射。针对基于NoC的 MP SoC提出一种低开销的任务迁移方案,通过在µC/OS-II操作系统中传递任务的堆栈以及任务控制块实现任务迁移,任务迁移到另一节点后能够恢复原来的状态继续执行。该迁移方案不需要传递任务代码,并且由于不需要在程序中添加迁移点,能够及时响应任务迁移请求。任务迁移在之前开发的NoC分布式多核系统[13]的基础上实现。
2 系统结构
2.1 任务迁移的内容
任务迁移即把任务从MPSoC中的一个节点迁移到另一个节点,并且能够恢复原来的状态继续执行。尽管任务迁移有许多种不同的实现方式,但是大都可以归纳为以下7个步骤[14]:
(1)发出迁移请求。迁移请求可以由迁移源节点发出,也可以由多核中主节点发出。
(2)在迁移源节点挂起任务,任务进入迁移状态。
(3)重新建立通信。迁移过程中新到来的消息暂时保存到消息队列,在任务迁移后再发送给任务,同时其他任务需要能够获悉该任务迁移后的新位置。
(4)提取任务状态,包括存储器内容、处理器状态(CPU寄存器),通信状态(消息通道)以及相关的内核信息。
(5)在目的节点创建任务。
(6)在迁移的源节点和目的节点间传递任务状态。
(7)把任务状态导入新创建的任务,恢复任务。删除源节点的任务。
在基于NoC的MPSoC中进行任务迁移,任务状态通过NoC传输会带来较大的通信迁移开销。本文提出的任务迁移方案借助于多核平台的MMPI编程模型对任务迁移的开销进行优化。下面首先介绍任务迁移实现所用的平台以及与任务迁移紧密相关的MMPI编程模型。
2.2 平台结构
本文在之前开发的NoC分布式多核系统[12]中实现了一种具体的任务迁移方案。该系统在文献[12]中有详细描述,这里只作简单介绍。该多核系统基于M5模拟器,整体结构如图1所示。

图1 多核系统整体结构
各个节点通过2D mesh网络结构的NoC互联,每个节点包含一个CPU、私有存储器、DMA-NI以及其他外设。网络中一个节点作为主控节点上负责统计和管理全局资源,进行任务映射以及发送迁移请求。其他节点作为运算节点负责运行并行任务。主控节点上运行嵌入式Linux操作系统,运算节点运行µC/OS-II操作系统。节点间的通信通过一套定制的、针对嵌入式应用的MMPI来完成。
2.3 M MPI消息传递机制
分布式多核系统中节点间的通信是采用消息传递的方式。不同节点的任务通过调用MMPI通信原语MPI_Send() 和MPI_Recv()完成消息的发送和接收。MPI_Send()是非阻塞发送,MPI_Recv()是阻塞接收。
一个应用包含多个有通信关系的任务,可以用任务图表示,图2是一个简单任务图的示例,任务图中每个任务可以看作拥有私有的消息队列,称作软FIFO。任务t1通过MPI_Send()把消息以非阻塞的方式发送到任务t2的软FIFO中,任务t2通过MPI_Recv()把私有软FIFO中的消息取出,完成一次任务间的消息传递。如果任务t2无法在软FIFO中找到对应的消息,那么任务t2阻塞,直接消息到来。

图2 任务图示例
MMPI消息传递的机制简化了任务迁移过程。任务在迁移的过程中,与之通信的任务不仅可以正常执行,而且还可以向正在迁移的任务发送消息,消息直接发送到迁移目的节点的消息队列,任务在迁移后能够在目的节点的消息队列找到相应消息而不会被阻塞。
2.4 M MPI并行任务
基于MMPI的并行程序在编写时不包含任务到节点的映射信息,即并行程序与任务映射无关。在MMPI程序执行前主控节点指定任务到节点的映射关系,MMPI程序在初始化MPI_Init()时获取任务映射表,在执行时根据任务映射执行MMPI程序的不同部分,从而实现了依据任务映射的结果,不同任务在不同节点上的并行执行。在这种机制下,当任务发生迁移时,主控节点只需要重新向各个运算节点发送任务映射,即可保证任务在迁移后仍能够与其他任务保持正确的通信。同时,由于各个运算节点保存同样的MMPI程序,因此任务迁移时可以不需要传递任务代码,降低了任务迁移的开销。
3 任务迁移的实现过程
本节对任务迁移的细节作具体描述。图3是任务迁移的流程。
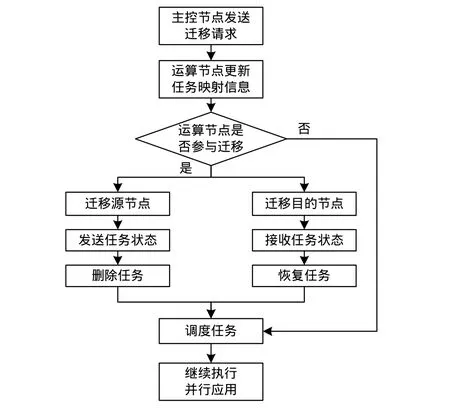
图3 任务迁移流程
任务迁移主要分为以下7个步骤:
(1)主控节点发送任务请求。本迁移方案中任务迁移请求由主控节点发出。首先,主控节点根据用户的需求运行任务迁移算法,算法的结果输出任务迁移的请求(本文只讨论任务迁移的过程,暂不考虑任务迁移算法)。任务迁移请求分为3个部分:需要迁移的任务m_task,迁移的源节点s_node和迁移的目的节点d_node。任务迁移的请求指定了一个任务如何重新映射到其他节点。主控节点产生迁移请求后,把任务迁移的请求广播到多核系统的各个节点。
图4表示了多核分布式系统中任务迁移实现的过程。整个系统从下到上划分为底层硬件、操作系统和应用软件3个层次。
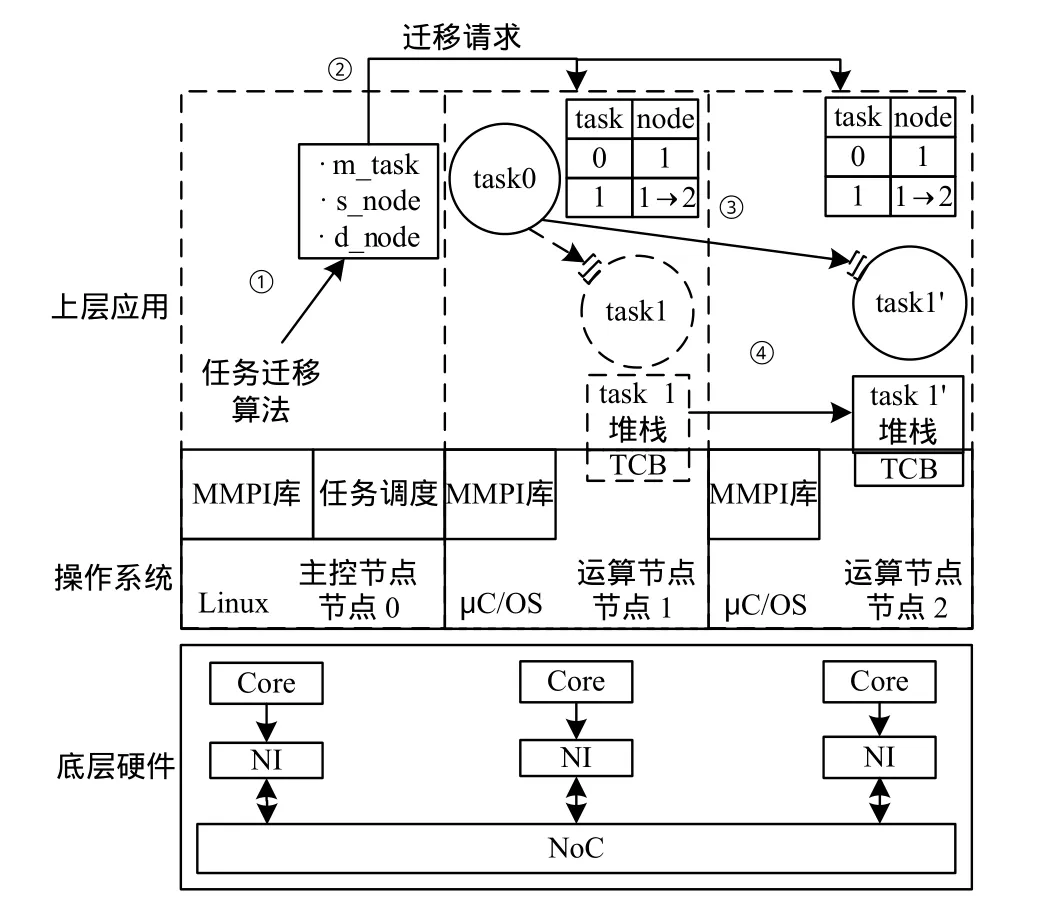
图4 多核分布式系统中的任务迁移实现
多核节点分为主控节点和运算节点,图中左侧为主控节点,中间和右侧为运算节点。MMPI库作为消息传递的函数库,可以看作是操作系统的扩展。主控节点负责任务调度以及发送任务迁移请求,①表示主控节点根据任务迁移算法产生迁移请求,②表示主控节点发送迁移请求到运算节点。
(2)更新任务映射表。与通常任务迁移方法不同的是,本文提出的任务迁移方案采用更新任务映射表的方式使其他任务获悉任务迁移后所在的节点。由于对于MMPI程序,不同的运算节点根据任务映射表执行不同的任务,当运算节点收到主控节点的迁移请求时,更新任务映射表,不仅可以完成任务的重新映射,而且还可以使得应用中的其他任务获知任务迁移后所处的节点,保证了任务在迁移后与其他任务间的消息仍能够正确地传递。在图4中,task1迁移至另一运算节点成为task1’,③表示任务task0通过更新映射表的方式与task1’重新建立通信。
由于主控节点向各个节点发送迁移请求并非同时发送,并且各个运算节点在NoC中位置不同,因此s_node和d_node无法同时收到迁移请求。为了保证s_node和d_node同时进行任务迁移的过程,s_node与d_node之间需要通过消息进行同步。
(3)源节点保存任务状态。通常在一个分布式的系统中进行任务迁移,传递任务的状态包括CPU寄存器、任务代码、任务数据以及操作系统内核维护的任务控制信息[15]。本文实现的任务迁移是在分布式多核系统的运算节点之间进行,根据2.2节可知,运算节点运行µC/OS-II操作系统。表1表示了任务迁移时需要传递的任务状态以及任务状态所在的位置。在µC/OS-II操作系统中,任务被切换时,任务对应的CPU寄存器信息自动保存到任务堆栈中,并且任务的数据也保存到任务堆栈。此外,µC/OS-II通过任务控制块(Task Control Block, TCB)维护着任务控制相关信息,主要记录了任务堆栈的当前指针等信息。同时各个运算节点保存同样的MMPI程序,仅通过修改任务映射表,即可实现任务的重新映射,因此,任务迁移时可以不需要传递任务代码,任务迁移的开销也由于免去传递任务代码而得到一定程度降低。综上,任务迁移时任务状态仅包括任务堆栈和任务控制块。

表1 M MPI并行任务的状态
(4)传递任务状态。任务迁移的源节点通过MMPI消息传递的方式把任务堆栈和任务控制块传送到目的节点。在图4中,④表示任务状态在迁移源节点和目的节点间的传递,其中任务状态包括任务堆栈和任务控制块。
除了任务状态需要传递,任务的软FIFO中的消息也需要传递。任务迁移时,任务的私有软FIFO中可能存在尚未通过MPI_Recv()接收的消息。因此,在任务状态传递后,还需检查迁移任务的软FIFO是否为空,若不为空,那么直接通过网络接口把该任务软FIFO中的消息发送到目的节点。这样可以避免任务迁移到目的节点后可能无法在软FIFO中找到消息而错误阻塞。
(5)目的节点恢复任务。目的节点根据迁移请求中m_ task的任务号分配优先级,并且根据优先级创建任务。加载接收的任务状态,使任务迁移到目的节点可以完全从原来被中断的状态恢复。
(6)源节点删除任务。源节点根据迁移请求中m_task的任务号查找该任务的优先级,并且根据任务优先级在µC/ OS-II中删除该任务。
(7)源节点和目的节点调度任务。
综上所述,本文实现的任务迁移方案与通常的任务迁移主要有以下4点不同:(1)迁移请求由主节点发出,运算节点采用更新任务映射表的方式完成任务重新映射,使得任务迁移后仍能与其他任务正确通信;(2)其他任务可以向正在迁移的任务发送消息;(3)任务状态包括任务堆栈和任务控制块,不包括任务代码;(4)在µC/OS-II操作系统中任务状态自动保存,不需要迁移点检查任务迁移请求,能够对迁移请求及时做出响应。
4 实验结果与分析
在基于M5模拟器的多核平台上实现了任务迁移,多核平台采用网络规模2×2、拓扑结构为2D mesh的NoC结构。多核各节点的处理器频率均为1 G Hz。网络中0号节点作为主控节点,1~3号节点为运算节点,主控节点运行Linux操作系统,运算节点运行µC/OS-II操作系统。MMPI并行任务是由一个矩阵乘法拆分成多个互相通信的任务,每个任务的运行时间均约为5 ms,堆栈大小为512 Byte。任务被分配到各个运算节点执行,任务到网络节点的映射关系以及任务迁移结果如表2所示,任务迁移分别把任务1从节点1迁移到节点3、把任务3从节点3迁移到节点2、把任务4从节点2迁移到节点1。
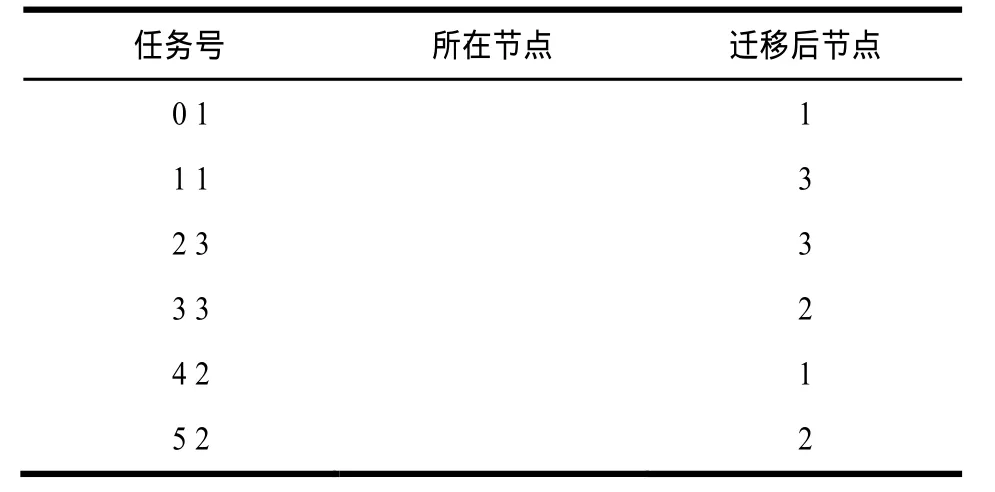
表2 任务映射
本文主要对任务迁移的时间开销进行评估。评估主要分为3个部分内容:
(1)测试了任务迁移不同阶段的时间。表3显示了测试案例中不同任务迁移的各个阶段的开销,时间单位为时钟周期。

表3 任务迁移各阶段开销 cycle
为了能够更直观地评估各个阶段的开销,将以上3个任务各阶段迁移开销取平均值,可以得到如图5所示任务迁移各个阶段所占的比重。可以看到,任务状态传递由于需要传输大量的数据,占迁移总开销的50%左右。任务迁移请求接收由于主控节点需要多次启动DMA-NI进行数据传输,因此达到了迁移总开销的36%左右。
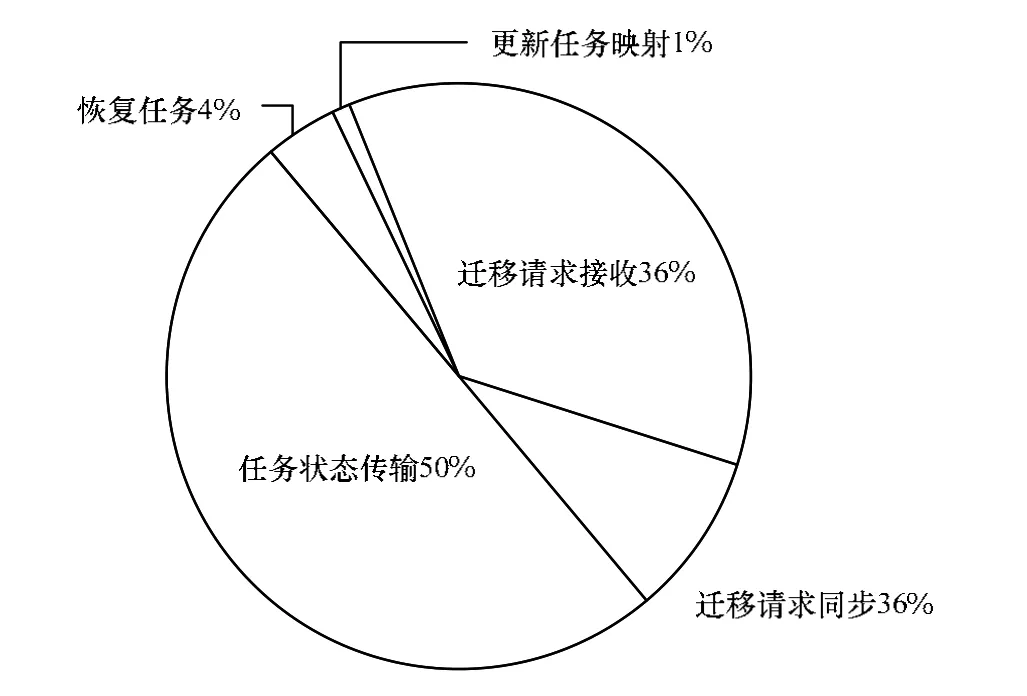
图5 任务迁移各个阶段的比重
(2)将本文的迁移方案与文献[11]的迁移方案进行对比。文献[11]提出的迁移方案同样不需要迁移点,但是迁移过程需要传递任务的代码。图6对比了任务迁移包括与不包括任务代码2种情况的任务迁移时间开销,分别包括任务状态传递的时间和迁移延时。
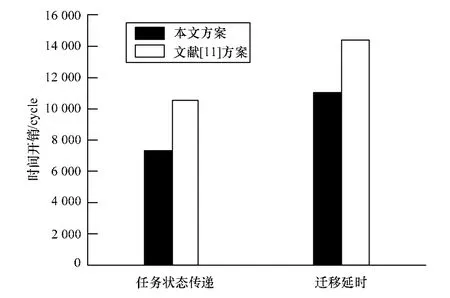
图6 迁移开销对比
其中,迁移延时表示任务的执行时间受任务迁移影响而增加的时间。经过测试,对于本测试案例,任务状态的传输时间为7 309个时钟周期,迁移延时为1 045时钟周期。由图6可见,迁移时不传递任务代码可以使得任务状态传递的时间降低约35%,迁移延时可以降低约28%。
(3)将本文的迁移方案与基于迁移点的迁移方案进行对比。为了能够在M5平台上模拟迁移点方法,创建一个较高优先级的任务,每隔一段时间检查是否收到任务迁移请求。将本文方案命名为方案1,迁移点的间隔分别为20 µs、50 µs、100 µs、200 µs,分别命名为方案2~方案5。其中,运行的MMPI任务的执行时间约为5 ms。图7是本文任务迁移方案与迁移点方法进行对比的结果,分别从任务迁移后执行时间增加和迁移请求响应时间进行对比。当迁移点间隔较小时,频繁地检查任务迁移请求使任务的正常执行时间增加;当迁移点间隔较大时,任务则不能及时响应任务迁移请求,响应时间与迁移点间隔成正比。可以看出,本文提出的任务迁移方案对任务执行时间影响很小,能够很好地满足实时系统中任务的实时性要求,同时本任务迁移方案能够及时响应主控节点任务迁移的请求。

图7 各方案迁移情况的对比结果
5 结束语
本文提出了一种低开销的任务迁移方案,并且在NoC分布式多核系统中实现。多核系统中的MMPI编程模型具有并行程序与任务映射无关的特点,同时运算节点采用µC/OS-II操作系统,使得任务迁移不需要传输任务代码,并且不需要迁移点,因此,该任务迁移方案具有较低的任务迁移开销。实验结果表明,任务状态的传输对任务迁移开销影响最大,并且当任务状态不包括任务代码时,迁移延时可以降低28%左右。同时,与基于迁移点的任务迁移相比,该任务迁移机制对任务执行时间影响很小,并且能及时响应任务迁移请求。下一步工作将在此基础上继续研究任务迁移算法相关的内容,把任务迁移应用于容错、负载平衡等方面。
[1] W olf W, J erraya A A, Martin G. Multiprocessor Systemon-Chip(MPSoC) T echnology[J]. IEE E T ransactions on Computer-aided Design of Integrated Circuits an d Systems, 2008, 27(1): 1701-1713.
[2] Nollet V, Marescaux T, Avasare P, et al. Centralized Run-time Resource Man agement in a Network-on-Chip Containing Reconfigurable Hard ware T iles[C]//Proc. of Co nference on Design, Automation and Test in Europe. Munich, Germany: [s. n.], 2005: 234-239.
[3] 张 苗, 张德贤. 基于异构感知静态调度与动态线程迁移的异构多核调度机制[J]. 计算机应用, 2011, 31(7): 1808- 1810.
[4] Yaghoubi H, Modarresi M, Sarbazi A H. A Distributed Task Migration Scheme for Mesh-based Chip-multiprocessors[C]// Proc. of the 12th International Conference on P arallel and Distributed Computing, Applications and Technologie. Gwangju, Korea: [s. n.], 2011: 24-29.
[5] Thilo S, Christian S, Christian H, et al. Dynamic Task Binding for Hardware/Software Reconfigurable Networks[C]//Proc. of the 19th Annual Symposium on Integrated Circuits and Systems Design. Ouro Preto, Brazil: [s. n.], 2006: 38-43.
[6] Cuesta D, Ayala J L, Hidalgo J I, et al. Adaptive Task Migration Policies for Thermal Control in M PSoCs[C]//Proc. of the IEEE Computer Society Annual Symposium on VLSI. Lixouri Kefalonia, Greece: [s. n.], 2010: 110-115.
[7] 李 毅. 基于PVM的研究任务迁移, C++对象分布并行及Capability实现[D]. 成都: 电子科技大学, 2001.
[8] Benini L, De M G. Networks on Chips: A New So C Paradigm[J]. Computer, 2002, 35(1): 70-78.
[9] Eduardo W B, Daniel B, W ronski F, et al. Impact of Task Migration in NoC-based MPSoC s for Soft Real-time Applications[C]//Proc. of International Co nference on Very Large Scale Integration. Atlanta, USA: [s. n.], 2007: 296-299.
[10] Bertozzi S, Acquaviva A, Be rtozzi D, et al. S upporting Task Migration in Multi-processor Syst ems-on-Chip: A Feasibility Study[C]//Proc. of Conference o n Design, Automation and Test in Europe. Leuven, Belgium: [s. n.], 2006: 1-6.
[11] Moraes F G, Madalozzo G A, Castilhos G M, et al. Prop osal and Evaluation o f a T ask Migration Protocol for NoC-based MPSoCs[C]//Proc. of IEEE International Symposium on Circuits and Systems. Seoul, Korea: [s. n.], 2012: 644-647.
[12] 孙思月. 基于NoC的分布式多核系统编程模型实现[D].哈尔滨: 哈尔滨工业大学, 2010.
[13] 胡新安, 付方发, 孙 俊, 等. 基于NoC的多核分布式操作系统[J]. 计算机工程, 2012, 38(5): 259-261.
[14] Dejan S, Fred D, Yves P, et al. Process Mig ration[J]. ACM Computing Surveys, 2000, 32(3): 241-299.
[15] Robinson J, Russ S H, Flachs B K, et al. A Task Migration Implementation of the M essage-passing Interface[C]//Proc. of the 5th I EEE International Symposium on High Performance Distributed Computing. Syracuse, Italy: [s. n.], 1996: 61-68.
编辑 顾逸斐
Implementation of Task Migration in Distributed Multi-core System Based on NoC
WANG Liang, FU Fang-fa, LIU Zhao-chi, LAI Feng-chang
(Microelectronics Center, Harbin Institute of Technology, Harbin 150001, China)
In order to decrease task migration overh ead in distributed multi-core system, a low-cost task migration scheme is implemented on the distributed multi-core system ba sed on Network on Chip(NoC). The task migration scheme depends on the distributed multi-core system message passing interface, in which program is independent of task mapping. Task is remapped by updating task mapping table. The task state including task stack and task control block in μC/OS-II operating system is transferred to another node, on which the migrated task restores execution. The task migration scheme needs not transfer task code, and task state saving does not use checkpoints. Experimental results show that in this migration scheme, the task m igration scheme has little influence on task executi on and i mmediate response to migration request. Therefore, the task migration scheme is low cost and can meet real-time requirements in system.
distributed multi-core system; task migration; low-cost; multi-core message passing interface; task mapping table; transfer point
10.3969/j.issn.1000-3428.2014.05.060
中央高校基本科研业务费专项基金资助项目(HIT.NSRIF.2014039);国防重点学科实验室开放基金资助项目。
王 良(1989-),男,硕士研究生,主研方向:多核通信,多核任务调度与迁移;付方发,讲师、博士;刘钊池,硕士研究生;来逢昌,副教授。
2013-04-15
2013-06-17E-mail:wl23189@163.com
1000-3428(2014)05-0289-06
A
TP391
book=294,ebook=299
