基于FPGA的反投影算法并行化实现
2014-08-05鲁亚楠鲁恒亚潘红兵何书专
鲁亚楠,鲁恒亚,2,潘红兵,2,李 丽,2,何书专,2,沙 金,2,李 伟,2
(1. 南京大学电子科学与工程学院微电子设计研究所,南京 210 093;2. 江苏省光电信息功能材料重点实验室,南京 210 093)
基于FPGA的反投影算法并行化实现
鲁亚楠1,鲁恒亚1,2,潘红兵1,2,李 丽1,2,何书专1,2,沙 金1,2,李 伟1,2
(1. 南京大学电子科学与工程学院微电子设计研究所,南京 210 093;2. 江苏省光电信息功能材料重点实验室,南京 210 093)
反投影算法是一种基于时域处理的雷达成像算法。针对该算法运算效率低、处理速度慢的问题,通过分析反投影算法的原理及其运算过程,提出一种算法并行化加速方法,即基于现场可编程门阵列,将算法中的反投影运算单元设计成专用的反投影运算硬件加速模块,并通过模块内的流水线处理及多个模块间的并行计算提高该算法的运算效率。运用该方法对2 048×4 096大小的目标网格点进行反投影成像,成像时间为139 s,平均单点成像时间是基于GPU加速方法的3倍,并且成像结果和计算机成像结果误差极小。实验结果表明,该并行化方法可有效提高反投影算法的运算效率。
反投影算法;反投影运算模块;合成孔径雷达;批处理;并行化;现场可编程门阵列
1 概述
反投影(Back P rojection, BP)算法是一种基于时域处理的合成孔径雷达(Synthetic Aperture Radar, SAR)成像算法,其基本原理是将雷达回波数据反向投影到成像区域的每个像素点,像素的值可通过计算雷达回波在雷达天线和图像像素之间距离的延时累加来确定。该算法用时延代替了相位的概念,故与频率无关,适用于载机任意运动的SAR成像,具有重要的研究价值[1-2]。尽管BP算法可以不加任何近似地应用在SAR成像中,但是它最大的缺点是计算量大、计算效率低,因此,如何快速地实现BP算法成了当前研究的热点[3-4]。
对于运算量大的算法,可以从以下3个方面入手提高其运算效率:(1)通过改进算法本身降低算法的运算复杂度;(2)设计先进的运算架构;(3)并行化处理。文献[5-6]从不同方面对算法进行改进,使算法的运算量从传统BP的N3减小到N2lbN,降低了算法的复杂度,但均需特定的条件。文献[7]基于多核,从系统架构和并行化的角度提高算法的运算效率,但消耗较多资源。文献[8]基于图像处理器(Graphic Processing Un it, GPU)将BP算法进行并行化处理,提高了算法的运算效率,减少了运算时间。
鉴于BP算法中各像素点的计算过程相同且相互独立,对该算法进行并行化处理是一种非常有效的提高运算效率的方法。本文以提高算法运算速度为出发点,提出模块内流水并行处理、模块间流水线架构的并行化实现方案,即基于现场可编程门阵列(Field P rogrammable Ga te Arra y, FPGA),设计专用的反投影运算模块,通过多个反投影运算模块的并行以及模块内部的流水并行实现算法的加速。
本文对BP算法的原理进行简要介绍,根据算法的特点设计硬件模块,详细阐述该硬件设计的思想,介绍多个模块并行处理的运算架构,测试了该方案,并对实验结果予以分析。
2 BP算法分析

其中,t为快时间;n为慢时间;A0为幅度;w(n)为窗函数;K0=4πf0/C ;f0为载频;总斜距R可表示为:
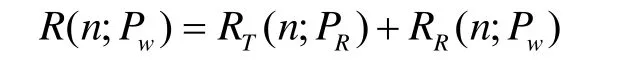
图1 移变双基地SAR的几何模型
对每一个目标成像点,BP算法首先计算它到收发平台的双程时延,将对应时域回波信号沿孔径方向进行相干累加,使来自该像素点的回波信号同相,从而得到加强,而来自其他点的回波信号则由于相位不同,叠加结果趋于零。
算法的关键步骤如下:
(1)距离向匹配滤波;
(2)插值并重采样;
(3)反投影:
1)计算各成像点的双程时延,找到相应的回波信号;
2)对该信号进行多普勒相位补偿;
3)叠加到原像素点;
(4)重复步骤(1)~步骤(3)直到所有回波数据均反投影完。
由上述分析可见,各像素点之间的反投影计算相互独立,使该算法非常适合并行化。接下来详细介绍反投影运算部分的并行化实现过程。
3 BP运算模块内流水并行
反投影运算模块是该算法的核心模块也是基本模块,计算过程基本上都在本模块实现。其基本结构如图2所示,距离计算模块从存储器中读入初始坐标及目标图像的分辨率,然后计算其距离;相位补偿模块和延时模块计算相位补偿参数及读取相应的回波数据,将两者相乘,将其累加到原像素点上,最后将结果存入相应的存储器中。

图2 BP运算模块结构示意图
本文通过以下2种方式实现算法的优化:(1)由于计算延时模块和计算相位补偿系数模块相互独立,因此将延时计算和相位补偿参数计算并行处理来缩短运算时间;(2)在设计中引入批处理的概念[9],即在BP运算前按顺序(行或者列)将反投影前的像素点存储在存储器中,待运算开始时,相干累加模块中的地址生成单元读取像素点存放的首地址,然后每经一个时钟周期后,依次产生后续每个像素点的存储地址。而对于每种给定的运算,执行所需要的时钟周期数是一定的,因此,按照指令流水级,从第一个像素点反投影运算完成后,每经一个时钟周期,依次完成后续每个像素点的反投影运算。
对于反投影运算模块,采用批处理的方式,其优点在于,可充分利用每一个时钟周期,最大限度减少各子模块空闲等待时间,减少了不必要的时间和资源开销,从而提高了运算效率。本模块中流水建立的时间为132个周期,当一次批处理4 096个像素点时,其加速比可达128,具有显著的加速效果。
经ISE综合,该模块时钟频率可达126 MHz,占用LUT 共7 188个,寄存器10 331个,占用资源也很少。
4 BP运算模块间的流水并行
在BP算法中,每一个像素点均需进行多次反投影运算,且各次反投影运算顺序进行,适合采用流水并行的方式实现。以像素块为单位(如4 09 6×1),通过多个BP运算模块的流水并行实现算法的进一步加速。考虑到大规模成像时,像素点太多,为节省片上存储资源,可将像素点存储在片外,需要进行某一个像素块BP运算时,再读取到片上存储器进行运算。图3给出了各模块间流水的基本原理。

图3 反投影运算模块间流水示意图
存储器中存放的是像素块值,第k次BP运算时,每个BP模块从各自的源存储器中读取像素数据,并将反投影后的像素值存储在相应的目的存储器中。当所有像素点都完成BP运算后,通过顶层软件的控制,切换各模块的源存储器、目的存储器地址,然后进行下一次的BP运算。这样,前一个BP模块的运算结果可直接为后一个BP模块所利用,通过这种简单的地址切换,可有效避免数据搬运的时间消耗;另外,由于每个BP运算模块处理点数相同,运算时间也相同,因此各BP模块之间相互同步,从而实现各级流水线的无缝对接,获到较高的数据吞吐率,有效地实现了算法的并行化。
5 实验结果与分析
本实验以ARM946[10]和Xilinx公司的Virtex-6 FPGA[11]芯片为测试平台。
考虑到算法还涉及到距离压缩等其他运算,本文将ARM作为主控核,以自主研发的片上系统为实验平台对该方案进行测试,系统架构如图4所示[12]。
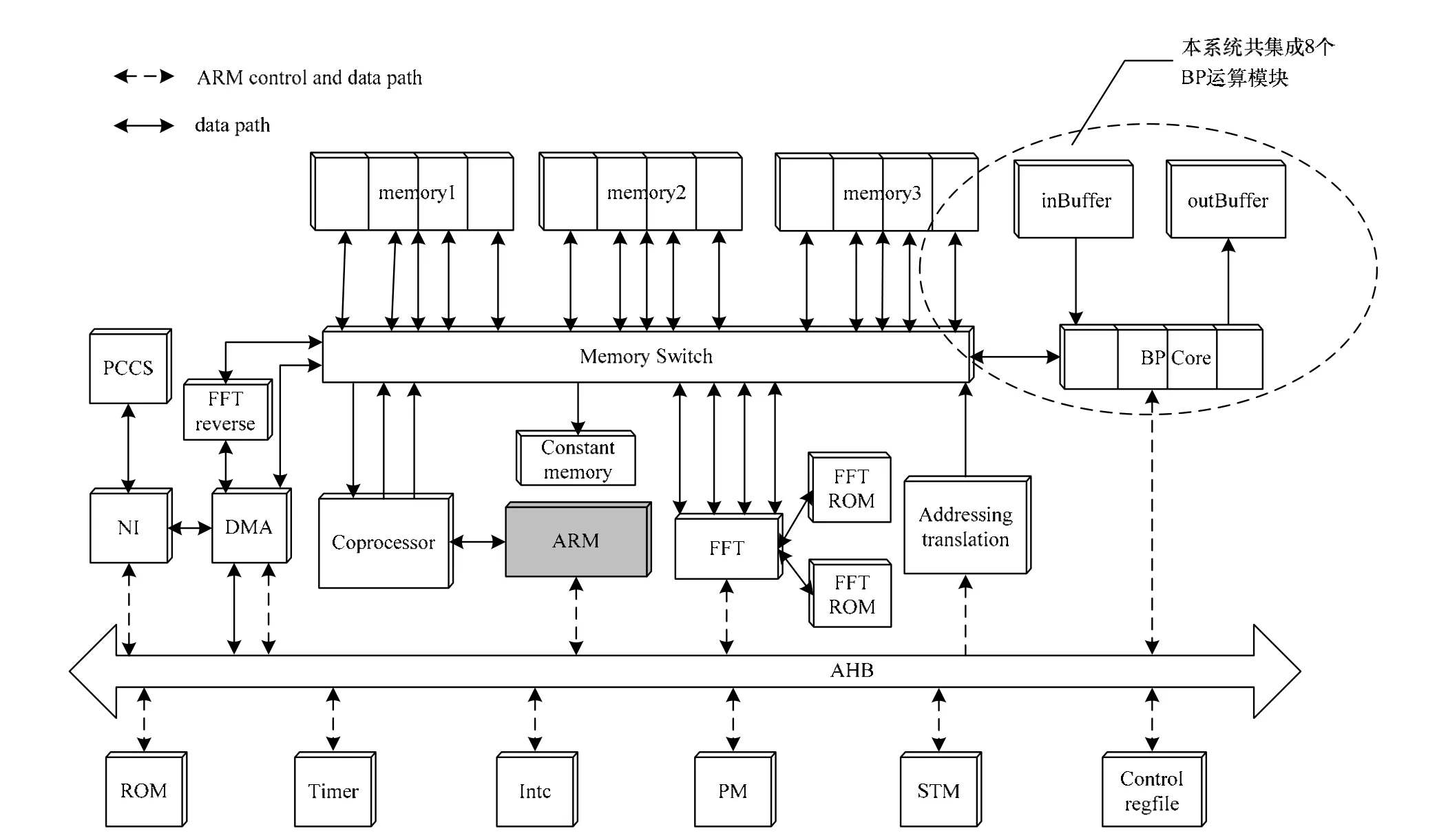
图4 实验系统架构
考虑到FPGA中有限的存储资源,本次实验仅集成8个BP模块,若采用更高系列的FPGA,可集成更多的BP模块。ARM通过AHB总线实现对协处理器、FFT及BP模块的控制,完成算法中的相应运算。协处理器和FFT协同完成算法中的距离压缩和插值部分,BP-core则完成反投影运算部分。
目标成像区域网格点大小为2 048(A)×4 096(R)。本文实验集成8个BP反投影模块进行测试,其中,每个BP模块每次处理4 096个像素点。对多点目标进行BP算法成像仿真,系统参数为:R=3 000 m,V=110.0 m/s,Theta=65.5°,Tp=10 µs,B=180 MH z,Fs=200 MH z,PRF=1 00 0,F0= 9.6 GHz。最终结果如图5所示。

图5 成像结果
由图5可见,并行化方案反投影成像效果非常好。实验最终成像时间为182 s,平均每点反投影时间为21.69e–6 s。文献[8]基于GPU的加速方法,实现1 500×1 500大小网格点反投影的时间为139 s,则平均每点的反投影时间为61.77e–6 s。
由此可见,本文实现方法的加速效果明显。且将该成图与计算机计算结果相比,成像质量基本一致,相似度达99%以上。
本文实验平台以ARM作为主控核,时钟频率上限不超过100 MH z。若采用更高性能的主控核,或者将该模块封装为IP核,独立于ARM,则运算速度会进一步提高。另外,本文实验仅集成8个BP模块流水并行,若采用更高性能的FPGA,则可集成更多的BP运算模块,并行度更高。
6 结束语
本文基于FPGA,提出一种BP算法的并行化方法。实验结果表明,本文方法在计算速度和成像效果上都取得了令人满意的结果,且在单个像素点的处理速度上优于基于GPU的并行化方法。但是,该方法消耗片上存储资源较多,减少片上存储资源的使用及进一步提高算法的并行度,是下一步需要改进之处。
[1] 粟 毅, 匡纲要, 陆仲良. 反向投影成像算法的理论分析及目标特征恢复[J]. 系统工程与电子技术, 2000, 22(2): 70-72.
[2] Yu Ding. A Fast Back-proj ection Algorithm for Bistatic SA R Imaging[C]//Proc. of Internation al Confere nce on Image Processing. Rochester, USA: IEEE Press, 2002: 449- 452.
[3] Y egulalp A F. Fast Bac kprojection Algorithm for Synthetic Aperture Ra dar[C]//Proc. of Radar Conferenc e. Waltham, USA: IEEE Press, 1999: 60-65.
[4] Ulander L M H, Froelind P O, Anders G, et al. Fast Factorized Back-projection for Bistatic SAR Processing[C]//Proc. of the 8th Europea n Conference on Synthetic Apert ure Radar. Aachen, Germany: IEEE Press, 2010: 1-4.
[5] Li Yanguan, Wang Yuming, Jin Tian, et al. Fast Back Projection Imaging for Arbitrary Aperture[J]. Systems Engine ering and Electronics, 2011, 33(7): 1443-1448.
[6] Liu Guangping, Liang Dia nnong. A F ast Back-projection Algorithm for the SAR with Lar ge Scene and High Resolution[J]. Systems Engin eering and Electro nics, 2003, 25(5): 346-349.
[7] Park J, Tang P T P, Sm elyanskiy M, et al. Efficient
Backprojection-based Synthetic Aperture Radar Computation with Many-core Processors[C]//Proc. of International Conference on High P erformance Computing, Networking, Storage and Analysis. Salt Lake City, USA: IEEE Press, 2012: 1-11.
[8] Zhang Xin, Zhang Xiaoling, Shi Jun, et al. GPU-based Parallel Back Projection A lgorithm for the Translational V ariant BiSAR Imaging[C]//Proc. of IEEE International Geoscience and Remote Sen sing Symposium. Vancouver, Canada: IEEE Press, 2011: 2841-2844.
[9] 韩正飞, 李劲松, 潘红兵. 基于FPGA的浮点向量协处理器设计[J]. 计算机工程, 2012, 38(5): 251-254.
[10] ARM Inc.. ARM946E-S(Rev1)System-on-Chip DSP Enhanced Processor Pro duct Overview[EB/OL]. (2010-05-1 5). http:// www.arm.com/products/processors/classic/arm9/arm946.ph.
[11] X ilinx Inc.. V irtex-6 Family[EB/OL]. (2010-01-12). http:// www. xilinx.com/products/virtex6.
[12] 黄晓林, 潘红兵, 易 伟. 基于多FPGA的NoC多核处理器验证平台设计[J]. 计算机工程与设计, 2012, 33(1): 180-185.
编辑 顾逸斐
Parallelization Implementation of Back Projection Algorithm Based on FPGA
LU Ya-nan1, LU Heng-ya1,2, PAN Hong-bing1,2, LI Li1,2, HE Shu-zhuan1,2, SHA Jin1,2, LI Wei1,2
(1. Institute of Microelectronic Design, School of Electronic Science and Engineering, Nanjing University, Nanjing 210093, China; 2. Jiangsu Provincial Key Laboratory of Photonic and Electronic Materials Science and Technolgy, Nanjing 210093, China)
The Back Projection(B P) algorithm is a radar imaging algorithm bas ed on time-domain processing. Aiming at the low computing efficiency and slow processing speed of BP algorithm, this paper proposes a parallel method after analyzing its princ iple and operation process. It an alyzes the parallelization feasibility of the BP algorithm, an d designs a dedicated BP operation module based on Field Programmable Gate Array(FPGA). To achieve the paralleliza tion of the algori thm water treatment w ithin a module and parall el processing between modules are adopted to speed up computations. It consumes 139 s to complete the computing of 2 048×4 096 target grid points using this method. The average time for a single-point is 3 times faster than the method based on GPU, and the imaging quality is as good as the resu lts of computer imaging. Experimental result show s that the p arallel method can ef fectively improve the op eration efficiency of the BP algorithm.
Back Projection(BP) algorithm; BP calculation module; Synthetic Aperture Radar(SAR); batch processing; parallelization; Field Programmable Gate Array(FPGA)
10.3969/j.issn.1000-3428.2014.05.059
国家自然科学基金资助项目(61176024, 61006018);高等学校博士学科点专项科研基金资助项目(20120091110029);江苏高校优势学科建设工程基金资助项目。
鲁亚楠(1989-),女,硕士研究生,主研方向:基于多核处理器的软件设计;鲁恒亚,硕士研究生;潘红兵、李 丽,教授;何书专,工程师;沙 金,副教授;李 伟,工程师。
2013-03-05
2013-05-13E-mail:luyanan27@163.com
1000-3428(2014)05-0285-04
A
TP301.6
