基于随机主元分析算法的BBS情感分类研究
2014-08-05刘三女牙
刘 林,刘三女牙,刘 智,铁 璐
(华中师范大学国家数字化学习工程技术研究中心,武汉430079)
基于随机主元分析算法的BBS情感分类研究
刘 林,刘三女牙,刘 智,铁 璐
(华中师范大学国家数字化学习工程技术研究中心,武汉430079)
针对论坛(BBS)中文本的情感分类问题,提出一种改进的随机子空间算法。挖掘特征空间中的分类信息,在生成子空间的过程中,利用权重函数对特征进行分类能力评估,以较大概率选择分类能力较好的特征维度,保证分类精度;扩大选择的子空间维度,选择具有分类能力的特征,通过主元分析对子空间进行降维,保证算法效率和子空间多样性。实验结果表明,该算法分类精度达到91.3%,比基准算法具有更好的性能稳定性。
情感分析;集成学习;随机子空间方法;主元分析;支持向量机;基分类器
1 概述
网络的迅速发展,给人们提供了新的交流方式和互动空间,极大地影响和改变着人们的生活。论坛(Bulletin Board System, BBS)作为互联网上最著名的服务项目之一,它以其独特的信息交流和互动方式,拥有庞大的用户群体。目前,随着互联网的迅扩张和蔓延,国内外对BBS的研究也与日俱增。在国内众多对BBS的研究中,大部分集中在对BBS技术、应用以及影响等方面,较少关注于BBS情感的研究。国外对BBS的直接研究也很少,而且这些研究仅关注于特定的话题或内容,如流产、枪支管制等;间接研究主要集中在对网络社会、虚拟社区、网络安全方面(如Dark Web project)。如何利用丰富的BBS资源,对用户表达的主观情感进行研究,成为新的研究问题。
与普通的网络文本一样,BBS文本亦具有口语化、碎片化、非结构化等特点;同时又有话题宽泛、互动性强等特点,这与局限于特定领域的(例如新闻舆论、商品评价、影视评价等)的文本情感分类有些不同。简单地说,文本情感分类通常是指辨识文本中表现出的立场、观点、看法、情绪等主观信息,对文本的情感倾向做出类别判断[1-2]。从20世纪90年代开始,文本情感研究在国内外受到了普遍的关注,并逐渐成为自然语言处理领域中的一个研究热点。其中基于机器学习的研究比较成熟,也很好地应用于文本情感分类,具有代表性的算法有支持向量机(Support Vector Machine, SVM)、K-近邻法(K-Nearest Neighbor, KNN)、朴素贝叶斯(Naive Bayesian, NB)等。文献[3-4]分别在英文、中文语言环境下进行比较研究表明,SVM被认为是稳定性和分类效果较好的算法。但是,这些研究基本都以单分类器方法为主,较少采用集成学习的方法。在通常情况下,集成学习通过多个分类器的有效组合,获得比单分类器更好性能。
综上原因,本文选择用集成学习的算法对BBS进行情感分类研究,通过辨识BBS文本中的情感倾向,分析用户情绪变化。
2 RSM算法
为提高分类效果,希望分类器能尽可能充分利于所有的具有分类能力的特征,但是在文本分类中,维度灾难是不可忽视的问题,过高的特征维度会花费成倍的时间和空间代价。如何在特征维度和效率之间进行平衡,随机子空间方法(Random Subspace M ethod, RSM)[5-10]是一种较好的方法。它从高维特征空间随机选取生成低维的子空间RS来分别构建基分类器(Base Classifier, BC),最后通过一定的组合规则将各基分类器结果进行集成,能有效地提升分类精度。RSM不仅受维数灾难的影响较小,还能充分利用高维度特征带来的分类能力提高,且能避免小样本问题的发生[5],在多种分类任务中都显著提高了学习系统的泛化能力,是一种非常有效的集成学习方法。
在随机子空间中,子空间的维度(m)和基分类器个数(n) 是2个主要的参数。文献[9-10]都对这2个参数进行了研究,表示适当的m值和较小的n值即可获得较优的效果。Kuncheva还认为学者在RSM对弱分类器的集成研究较多,而对强分类器的研究还不普遍;然而,与SVM等强分类器的集成不仅可以很好地提高分类精度,还可以解决较高特征维度的问题。
3 随机主元分析算法
在RSM中,子空间生成过程是随机选择的,即所有特征都是相同的概率被选中。考虑最差的情况,如果生成子空间时选中的大部分是分类能力较差的特征,在此基础上进行训练和集成,可能需要较长的时间和较多的基分器才能获得理想的较果。如果能在选择的过程中,实施某种策略,将具有良好分类能力的特征优先选择,较差的特征以较小的概率被选中,效果将会更好。受文献[11]启发,提出一种将RSM与主元分析相融合的算法,即随机主元分析(Random Principal Component Analysis, RPCA)算法。其主要思想是选择一种权重算法,对特征的分类能力进行评估,将结果作为特征被选中的概率。在子空间生成中,尽可能多地选择具有分类能力的原始特征,保持足够的分类能力和多样性;为减少增加的子空间维度带来的训练时间和存储空间的开销,选择主元分析(PCA)对子空间进行降维处理,RPCA算法描述如下:
输入 数据集D,特征集T,特征维度p,子空间维度m,子空间数目n
输出 十折交叉分类结果
Step1根据十折交叉验证,划分训练集和测试集。
Step2用权重函数对特征tk(k=1,2,…,p)分类能力进行计算,记为wk,对W (wk∈W)进行从大到小排序。
Step3循环生成n个子空间RS,每个子空间生成过程如下:

(2)产生一个[0,1)范围内随机数r;

(4)设定wk=0;
(5)循环步骤(1)~步骤(4),直至m个特征全部选择完成。
Step4用PCA算法对RSi进行特征压缩,选择贡献率总和大于99%以上特征形成子空间RSi’。
Step5对RSi’训练一个基分类器BCi并进行分类。
Step6用多数投票法对分类结果进行集成。
Step7循环完成十折过程,统计识别精度。
4 实验结果与分析
4.1 实验数据集与预处理
本文实验数据集来自华中师范大学校园BBS——华大博雅。该论坛拥有独特稳定的大学生用户群体,实名用户66 00 0多人,帖子数450多万条,对研究大学生心理健康发展有重大的意义。经过分析整理,选择正面和负面情感样本集各338个,数据集的预处理包括统一BBS标签字符、特殊HTML代码替换、繁简转换、缩略指代还原等。最终得到的数据集信息如表1所示。

表1 实验数据集相关信息
从表1可以得知,负面数据集在字数和词汇方面都比正面数据集丰富,这与实际的用户群体相关,一方面喜好发贴交流或情感表达;另一方面在表达负面情感时,更具有文饰性和爆发性,较难捉摸。
4.2 实验流程与设置
进行情感分类之前,首先需要把数据集中的文本表示成特征,可以采用反映文本语言学特征的元素来表示特征,如使用词、ngram、词组和概念等[4]。其中,ngram具有预处理简单、语种无关、蕴含细粒度特征和部分高层语法信息,被广泛采用。接着,通过特征选择,去除不相关或冗余的特征,实现特征降维,提高效率和分类精度。特征选择结果直接影响分类器的精度和泛化性能,文献[4]研究表明,信息增益(IG)在中文语境下具有较好的效果。实验中将联合ngram(n分别取1,2,3,4)4种特征表示,通过信息增益选择各排在前1 5 00位的特征进行融合作为初始特征集,然后通过RPCA算法进行分类实验,实验流程如图1所示。
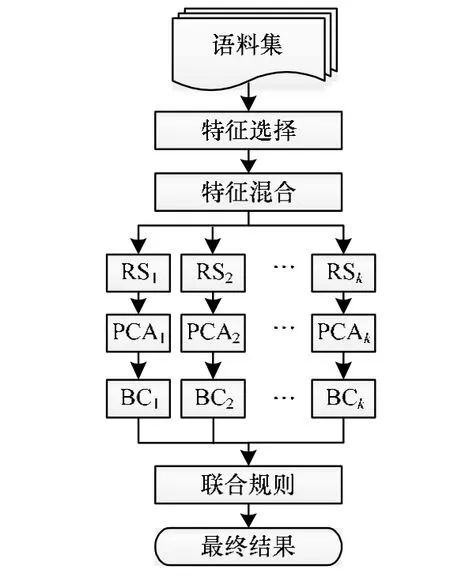
图1 实验流程
为验证RSM和RPCA算法的有效性,实验设计如下:实验1考察RSM集成算法与具有代表性单分类器算法(SVM、KNN、NB)进行比较;实验2将RPCA与RSM集成算法进行对比。实验中采用识别精度作为比较指标,即测试集中被正确分类的样本占测试集样本总量的比例。集成实验中基分类器算法选用的是台湾大学林智仁教授的Libsvm[12],主要参数是:s=1,d=2,c=1.5。RPCA中对特征tk分类能力计算采用文献[2]的Fisher准则:

其中,a,b表示为数据集中正面、负面文档数;a1,b1表示包含特征tk的正面、负面文档数;dP,i(tk)表示特征tk是否出现在正面第i个文档中,出现则值为1,否则为0;同样,dN,j(tk)表示表示特征tk是否出现在负面第j个文档中。
4.3 实验结果与分析
为避免初始特征集中分类能力过低的特征对单分类器的影响,实验1中对初始特征集成行二次选择,选择前3 000维进行KNN,NB,SVM单分类器实验;对于集成实验,参数为m=3 000、n=50。实验分别进行5次,取最好精度作为最后结果,如表2所示。

表2 不同分类算法精度比较 %
从表2中可以看出,在3种单分类器算法中,SVM精度明显高于其他2种算法;在集成算法中,分类精度都有所提高。其中,对KNN提高最大,有近4.4%。而SVM最小,仅有略大于0.9%。原因在于,SVM本身是一个强分类器,在文本情感分类任务中效果较好,且分类精度在超过89%的情况下,精度提升的空间有限。实验1同时也表明RSM是一种有效的集成学习算法。实验2集中对比RSM 与RPCA的集成效果,其中参数中m=4 200,将实验过程中获得的单个分类器各自的精度和集成精度如图2所示。
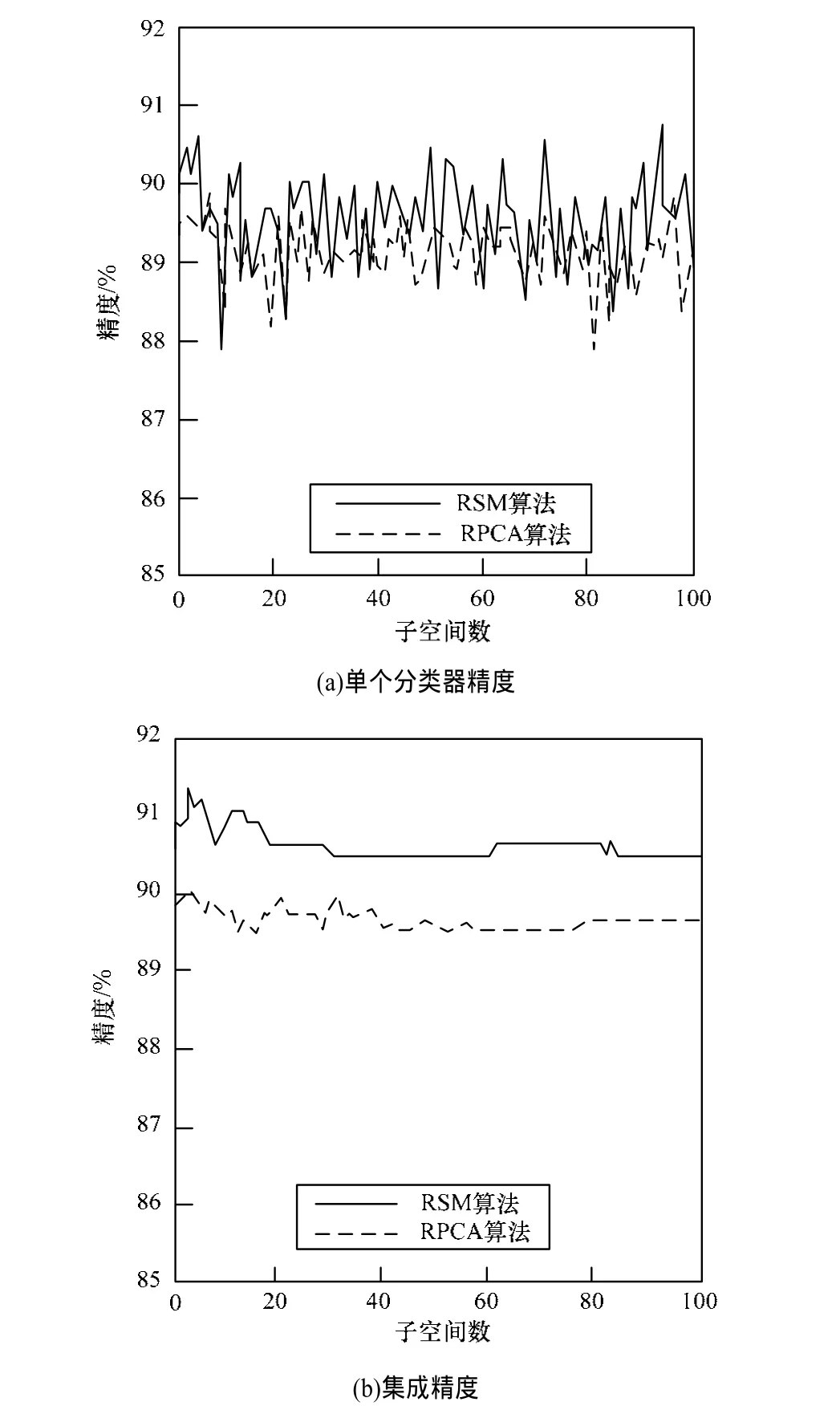
图2 R SM与RPCA精度比较
从图2可以看出,RSM和RPCA算法都能有效地提高分类精度,同时增加分类的稳定性;随着子空间数目的增加,集成精度逐渐趋于稳定,仅在小范围内波动。在RSM中,由于m值的变大引入了较多分类能力较低的特征,使得表现出的分类效果较实验1的最好效果差一点,而RPCA算法中由于进行了子空间选择和PCA降维,提高算法执行速度,同时单个分类器的精度相应有所提高;在基分类器个数大于20的时候,即获得比较稳定的效果,而RSM方法在基分类器数接近60时,才较为稳定;但受限于本例中较小样本数和投票法集成策略,在某些时刻,集成精度都有小范围的突变,进一步的工作中考虑改进集成策略(如加权投票法等)来消除或减小突变的影响。
5 结束语
针对BBS中文本的情感分类问题,本文提出一种改进的随机子空间算法,实验结果表明,RPCA算法对本文BBS数据集情感分类有较好的效果,能有效地提高分类精度和稳定性。同时,注意到本文虽然使用的是真实标注语料,但数据集规模较小,实验的结果也仅能作为特殊个体甄别的参考。在特征表示的过程中,还有较多的BBS风格特征没有充分利用(例如BBS标签、表情、字号字色等),而此部分信息在情感表达上比较重要。在对识别错误的语料分析看出,本文方法对含幽默和反语等表达手法的语料识别还存在不足。在下一步的工作中尝试加入风格特征,借鉴语义的方法,以获得更好的识别效果。
[1] Pang B, Lee L. Opinion Mining and Sentiment A nalysis[J]. Foundations and Trends in Information Retrieval, 2008, 2(1): 1-135.
[2] 王素格. 基于Web的评论文本情感分类问题研究[D]. 上海:上海大学, 2008.
[3] Pang B, Lee L, V aithyanathan S. Thumbs up? Sentiment Classification Using Machine Learning Techniques[C]//Proc. of ACL’02. Morristown, USA: [s. n.], 2002: 222-228.
[4] 唐慧丰, 谭松波, 程学旗. 基于监督学习的中文情感分类技术比较研究[J]. 中文信息学报, 2007, 21(6): 88-94.
[5] Kam H T, Labs B, Hill M. The Random Subspace Method for Constructing Decision Forests[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1998, 20(8): 832-843.
[6] Xia Rui, Zong Chengqing, Li Shoushan. Ensemble of Feature Sets and C lassification A lgorithms for Sentiment C lassification[J]. Information Sciences, 2011, 181(6): 1138-1152.
[7] 黎冬媛, 刘 智, 刘三女牙. 采用半随机特征采样算法的中文书写纹识别研究[J]. 计算机科学, 2013, 40(2): 120-123.
[8] Liu Zhi, Yang Zongkai, Liu Sanya. A Novel Random Subspace Method for Online W riteprint Identification[J]. Journal of Computers, 2012, 12(7): 2997-3004.
[9] Gangeh M J, Kamel M S, Duin P W. Ra ndom Subspa ce Method in T ext Categorization[C]//Proc. of the 20th International Co nference o n P attern Reco gnition. Istanbul, Turkey: [s. n.], 2010: 478-486.
[10] Kuncheva L I, Rodriguez J J, Plumpton C O. Random Subspace Ense mbles for fMRI Classification[J]. IEEE Transactions on Medical Imaging, 2010, 29(2): 531-542.
[11] Yang Jinnmin, Kuo Borchen, Yu Paota. A Dynamic Subspace Method for Hyperspectral Image Classication[J]. IEEE Transactions on Geoscience and Remote Sensing, 2010, 48(7): 2840-2853.
[12] Chang Chih-Chung, Lin Chih-Jen. LI BSVM: A Library for Support Vector Machines[J]. ACM Transactions on Intelligent Systems and Technology, 2011, 2(3): 1-27.
编辑 索书志
Study on BBS Sentiment Classification Based on Random Principal Component Analysis Algorithm
LIU Lin, LIU San-ya, LIU Zhi, TIE Lu
(National Engineering Research Center for E-Learning, Central China Normal University, Wuhan 430079, China)
For Bulletin Board System(BBS) sentiment classification issues, an improved Random Subspace Method(RSM) is proposed. This method tries to make full us e of the discriminative informa tion in the high dimensional feature space. In the process of g enerating subspaces, on the one hand, a weighting function is used to evaluate classification abilities of the features, and better ones are chosen to ensure accuracy of classification with a higher pr obability, on th e other hand, the size of the subspa ce is enlar ged, principal component analysis is used to reduce the dimension of the sub space, and they ensure the efficiency and diversity. Experimental results show that the proposed algorithm obtains the best accuracy of 91.3% , which is higher than the conventional Random Subspace Method(RSM).
sentiment analysis; ensemble learni ng; Random Subspace Method(RSM); principal c omponent analysis; Support Vector Machine(SVM); Base Classifier(BC)
10.3969/j.issn.1000-3428.2014.05.039
国家“十二五”科技支撑计划基金资助项目(2011BAK08B03);新世纪优秀人才支持计划基金资助项目(NCET-11-0654);“核高基”重大专项(2010ZX01045-001-005);华中师范大学中央高校基本科研业务费专项基金资助项目(CCNU09A02006)。
刘 林(1983-),男,博士研究生,主研方向:情感识别,数据挖掘;刘三女牙,教授、博士;刘 智,博士研究生;铁 璐,硕士研究生。
2013-03-04
2013-05-24E-mail:liulinhere@163.com
1000-3428(2014)05-0188-04
A
TP18
