基于特征变换的Tri-Training算法
2014-08-05赵文亮郭华平
赵文亮,郭华平,范 明
(郑州大学信息工程学院,郑州 450052)
基于特征变换的Tri-Training算法
赵文亮,郭华平,范 明
(郑州大学信息工程学院,郑州 450052)
提出一种基于特征变换的Tri-Training算法。通过特征变换将已标记实例集映射到新空间,得到有差异的训练集,从而构建准确又存在差异的基分类器,避免自助采样不能充分利用全部已标记实例集的问题。为充分利用数据类分布信息,设计基于Must-link和Cannot-link约束集合的特征变换方法(TMC),并将其用于基于特征变换的Tri-Training算法中。在UCI数据集上的实验结果表明,在不同未标记率下,与经典的Co-Training、Tri-Trainng算法相比,基于特征变换的Tri-Training算法可在多数数据集上得到更高的准确率。此外,与Tri-LDA和Tri-CP算法相比,基于TMC的Tri-Training算法具有更好的泛化性能。
特征变换;已标记实例集;差异;自助抽样;泛化能力
1 概述
在数据挖掘应用领域(如Web页面分类),可轻易收集大量未标记的实例,但标记这些实例却需要耗费大量的人力物力。因此,在有标记实例较少时,如何利用大量的未标记实例来改善学习性能已成为一个研究热点。其中,半监督学习是一种主流学习技术。目前已经提出了很多半监督算法,如Co-Training[1]、CoTrade[2]、SSCCM[3]等。文献[4]提出的Tri-Training是较受关注的该类型的算法之一。与Co-Training不同,Tri-Training试图在单个视图上学习3个有差异的分类器,进而有效地缓解Co-Training方法对视图正交的要求:在2个独立的视图上独立学习2个强分类器。同时,基于文献[5]的噪音理论,文献[4]又给出了确保Tri-Training有效的条件。
Tri-Training算法成功的关键因素是构建差异且准确的基分类器[6]。该算法通过对已标记实例进行重复采样获得差异的实例集进而获得有差异的基分类器,而自助采样并不能充分利用全部的已标记实例集,加之已标记实例本来就特别稀少,在特殊情况下可能导致采样的结果为单类实例集,进而导致训练失败。
基于以上问题,本文提出一种基于特征变换的Tri-Training算法。与传统的Tri-Training算法不同,该算法使用特征变换把训练实例集映射到新空间,得到有差异的训练集,从而避免了自助抽样带来的问题。此外,本文还设计基于Must-link和Cannot-link约束集合的特征变换方法(Transformation Based on Must-link Constrains and Cannotlink Constrains, TMC),并将其用于基于特征变换的Tri-Training算法中。
2 相关研究
与自助采样方法不同,特征变换方法通过处理实例集特征来构建训练集。这样做的另一个原因是:基于特征变换的方法更容易构建准确而又差异的基分类器[7]。例如,图1给出了使用bagging[8]和COPEN[7]在实例集ionosphere上分别构建包含50个基分类器的差异-错误图,其中横轴表示2个分类器的平均错误率,纵轴表示kappa度量的差异性[9],三角形重心指示出中心点。bagging使用自助抽样获得有差异训练实例集,COPEN使用约束投影(Constrain Projection)方法构建有差异实例集。图1显示,基于特征变换构建的基分类器和基于自助采样的方法具有相近的差异性,但比基于自助采样的方法具有更高的准确率。为此,本文提出一种TMC特征变换方法。

图1 在ionosphere实例集上的差异-错误图
文献[10]总结存在3种常用的建立准确而又有差异的基分类器方法:(1)使用不同的基分类器;(2)使用不同的特征子集;(3)使用不同的子数据集。本文主要关注于后两种方法,即通过操纵实例集(抽样或特征变换)构建准确且有差异的分类器。
对实例集进行抽样的方法有很多种,其中,bagging和boosting方法是最典型的2个代表。bagging使用有放回随机抽样的方法从训练实例集D中自助抽样得到多个有差异的实例集D1,D2,…,DM,并在每个训练实例集Dj上独立训练一个分类器hj。与bagging不同,boosting方法是一个迭代过程,每次迭代都自适应地改变训练实例的分布,进而使用加权抽样方法为每个分类器hj构建有差异的训练实例集Dj。
特征变换方法已经被广泛地应用于获得有差异的训练集,进而获得不同的分类器。例如,文献[9]将主成分分析应用于为分类器构建有差异的训练实例集,进而提出一种称作旋转森林的组合学习方法。文献[7]给出了一种基于成对约束的约束投影,利用must-link和cannot-link约束集合将实例集投影到新的特征空间,形成新的实例集描述,进而构建准确且有差异的分类器。文献[11]提出一种非陑性boosting映射方法,使用神经网络学习新特征,并将训练集映射到不同特征空间。
还有一些方法同时使用抽样和特征分析为每个分类器构建有差异的训练实例集,如随机森林将bagging和随机子空间结合,使用决策树构建有差异分类器。文献[12]同时使用随机抽样、特征子空间和参数控制学习不同的最近邻分类器。
不同于以上研究,本文将特征变换方法应用于Tri-Training算法中,以提高Tri-Training的泛化能力。
3 本文算法
基于特征变换的Tri-Training算法描述如下:
算法基于特征变换的Tri-Training算法

其中,DL:{xi| i =1, 2, …, N}(yi∈Y是与xi相关联的类标号)代表原始的已标记训练实例集合;Y表示类标号集合;Du代表原始的未标记训练实例集合。
本文算法首先使用特征变换方法初始化3个基分类器(行1~行4):在DL上学习不同的变换矩阵Wk(行2)、应用Wk到DL得到不同训练集DLk,进而学习相应的分类器hk。然后Tri-Training迭代地更新这3个分类器直到更新不再发生(行6~行24)。对于每次迭代,Tri-Training首先为每个分类器hk标记新的实例(行11),并根据如下条件确定是否更新hk(行12~行17)[4]:

在上述算法中,et(hk)表示第t次迭代其他2个分类器(除hk外)同时错误预测DL中实例的比例,|Dkt|是表示第t次迭代为分类器hk标记的实例数,即其他2个分类器(除hk)在Du上预测相同的实例数。为了防止|Dkt|过大,使用欠抽样方法减少Dkt中的实例(行15~行17)。最后,Tri-Training迭代更新每个分类器(行19~行23)。注意:算法中变量flagk(行4、行9和行22)目的是标记分类器hk是否已经被更新过,若未更新过则需将Du转换到新空间以便hk能够进行预测,否则直接使用hk预测Du中的实例。
如本文第2节所述,特征变换方法已经得到了广泛的研究,本文将这些变换引入到Tri-Training中。另外,本文构建一种新的基于Must-link和Cannot-link约束集合的特征变换(TMC)。该方法描述如下:给定已标记实例集DL,令Must-link约束集合Φm={(xi,xj)|xi∈DL,xj∈DL,yi=yj}和Cannotlink约束集合Φc={(xi,xj)|xi∈DL,xj∈DL,yi≠yj},笔者的目标是寻找一个变换矩阵W,使得在变换后的低维空间中(实例表示为zi=WTxi),类内实例距离尽量小而类间实例距离尽量大。搜索变换矩阵W,使得最大化目标函数J(W)且WWT=WTW=I,其中,I为单位矩阵。
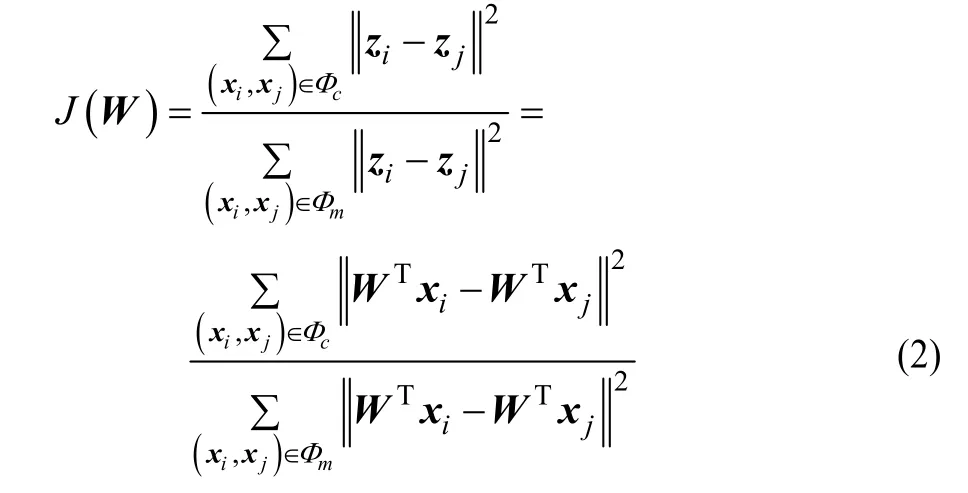
经过简单的代数运算,式(2)可用以下更简洁的方式来描述:

其中,trace(·)表示矩阵的迹;C和M分别表示Φc和Φm的散度矩阵(见式(4)),定义如下:

这里C和M分别相应于陑性判别分析(Linear Discriminant Analysis, LDA)[10]类间散度矩阵和类内散度矩阵。与LDA不同,本文采用成对实例约束构建散度矩阵。与约束投影不同,本文的目标函数无额外参数,这使得本文的变换方法更简单、简便。另外,最大化式(2)相当于最小化分母而最大化分子,进而使用式(2)求得的变换矩阵W能够使得在变换后的低维空间中,类内的实例距离尽量小而类间实例距离尽量大。
式(5)是一个典型的特征值问题,可以通过计算矩阵CM–1前d个最大的特征值对应的特征向量高效的解决。假定W=[W1, W2,…, Wd]作为式(5)的解决方案,矩阵中每一个特征向量对应的特征值为λ1≥λ2≥…≥λd,定义对角矩阵∧=diag(λ1, λ2, …, λd),那么:

注意:存在式(6)中的一个问题是M的行列式为0。事实上,由于C和M都是半正定的,M的行列式为0的情况很难出现,因此不那么严格地说,CM–1也是半正定的。为了支持算法1构建不同的变换矩阵,使用随机采样构建Φm和Φc使得|Φm|=|Φc|=|DL|,其中,|Q|表示集合Q的大小,DL表示已标记实例集(参见本文第3节算法)。
4 实验与结果分析
4.1 实验设置
12个实例集从UCI(http://archive.ics.uci.edu/ml/)库中随机选取。由于篇幅限制,本文省去了它们的信息描述。在每个数据集上,使用10折交叉验证分析算法的性能。为了评估基于特征变换的Tri-Training有效性,将它与Co-Training[1]和基于自助采样的Tri-Training[4]相比较,其中,将如下特征变换引入到Tri-Training中:TM,LDA和CP (Constraint Projections)。对应的算法分别记作Tri-TMC、Tri-LDA和Tri-CP。所有基分类器都使用C4.5[13]构建。对于Tri-TMC和Tri-CP,使用随机抽样构建Φm和Φc,使得它们的大小与已标记实例数相同。Tri-LDA使用随机抽样获得的已标记实例集构建类间和类内散度矩阵。
本文设计4个实验评估本文算法的有效性,其中,前3个实验测试给定未标号实例比例时算法的性能(未标记比率分别设置为训练实例的80%、60%和40%),最后一个实验测试了不同的未标记实例比率对算法性能的影响。所有的实验均使用开源数据挖掘工具洛阳铲(LySpoon)[14]完成。
4.2 实验结果
实验1测试了未标记率为80%时本文算法的性能。相关结果如表1所示,其中粗体表示相应的算法在相应的数据集上准确率最高,最后一行给出了平均准确率。可以看出,由于使用特征变换的方法更易构建准确且差异的基分类器,基于变换的Tri-Training算法比基于抽样方法构建的Tri-Training算法表现出更好的泛化性能。Tri-TMC和Tri-LDA在绝大多数数据集上取得了最高的准确率,其他依次是Co-Training、Tri-CP和Tri-Training。同时Tri-TMC以77.95%的平均准确率最高,随后依次是Tri-LDA、Tri-CP、Tri-Training和Co-Training。

表1 UCI数据集80%%%%未标记率下对应的准确率及序
在多个数据集上比较2个或更多算法的一个合适的方法是根据他们在数据集上的序及平均序[15]:获得最高准确率的算法的序是1.0,获得次高准确率的算法的序是2.0,依次类推。当多个算法准确率一样时,它们获得一个平均序。表1的右半部分给出了算法在每个数据集合上的序。
表1中算法的序验证了本文结论:基于特征变换的Tri-Training算法比基于抽样方法构建Tri-Training的方法表现出更好的泛化性能。可以看出,Tri-LDA以2.33的平均序排名第一,紧随其后的依次是Tri-TMC、Tri-Training、Tri-CP 和Co-Training。
仔细观察表1关于准确率和序的结果可以发现,较之于其他特征变换,TMC同样对Tri-Training是有效的。因此,在未标记率为80%时,本文总结如下:(1)基于变换的Tri-Training算法较之于基于自助采样的Tri-Training算法具有更好的泛化能力;(2)较之于其他特征变化方法,TMC方法同样对Tri-Training算法有效;(3)在UCI数据集上,与Co-Training算法相比较,Tri-Training更优越。
实验2和实验3分别展示了当未标记类标号比例为60%和40%时,算法准确率和序的比较结果,相关结果如表2和表3所示,其中设置同表1。
表2和表中的结果进一步验证了本文结论:使用特征变换方法更容易构建准确且差异的基分类器,进而有效提升Tri-Training算法性能。具体地,当未标号实例比例为60%时,Tri-TMC在7个数据集上取得最高的准确率,其他依次是Tri-CP、Tri-Training、Tri-LDA和Co-Training。在平均准确率上,Tri-TMC以79.82%排名第一,紧随其后的依次是Tri-CP、Tri-LDA、Tri-Training和Co-Training。在序比较上,它们的排名依次是Tri-TMC、Tri-LDA、Tri-CP、Tri-Training和Co-Training。当未标号实例比例为40%时,平均准确率依次是Tri-CP、Tri-TMC、Tri- Training、Tri-LDA和Co-Training。平均序排名依次是Tri-TMC、Tri-CP、Tri-LDA、Tri-Training和Co-Training。

表2 UCI数据集60%%%%未标记率下对应的准确率及序
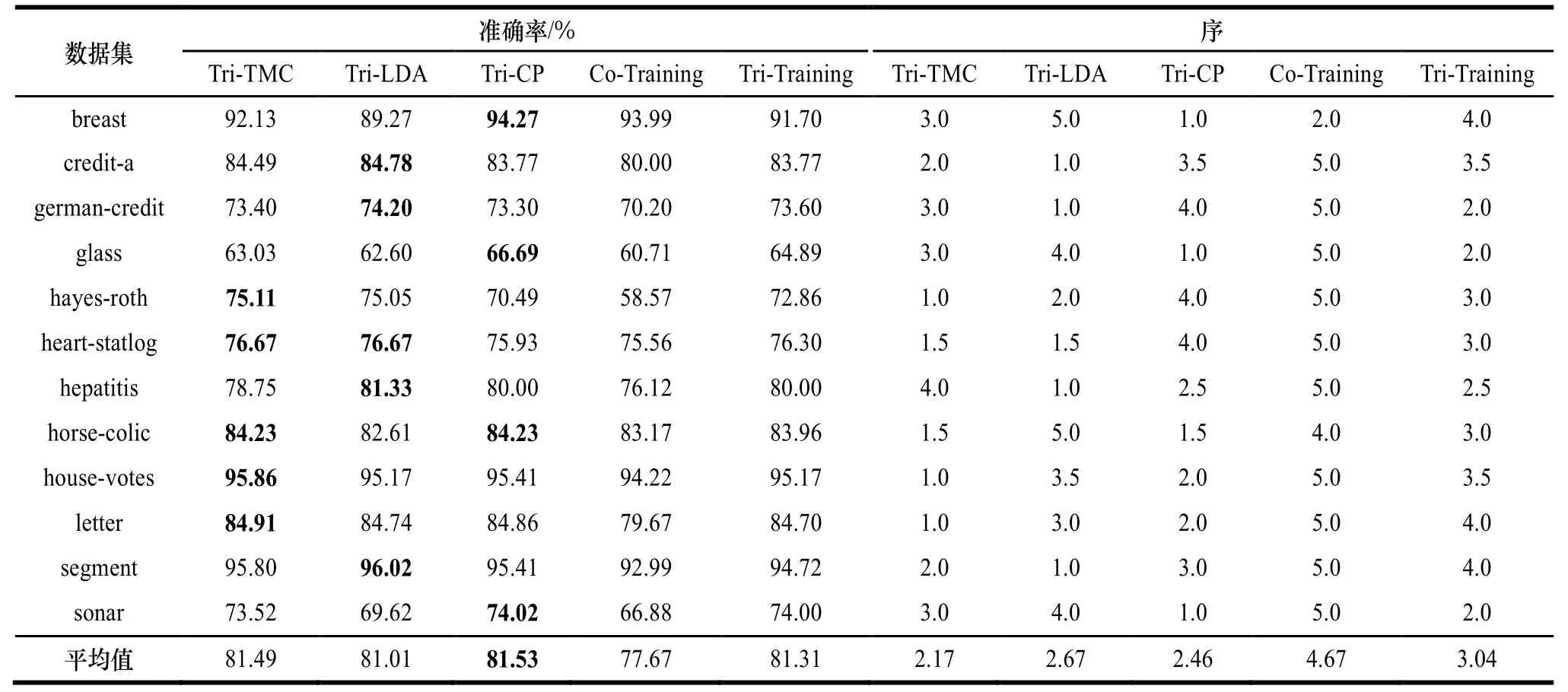
表3 UCI数据集40%%%%未标记率下对应的准确率及序
实验4测试了不同算法在不同的未标记率下的准确率,选取letter和sonar作为代表测试未标记率对算法性能的影响,结果如图2所示。可以看出,随着未标记实例的比例升高,较之于基于抽样的Tri-Training算法,基于变换的Tri-Training算法性能优势越来越明显。另外,3种特征变换方法对Tri-Training的效果是相当的。
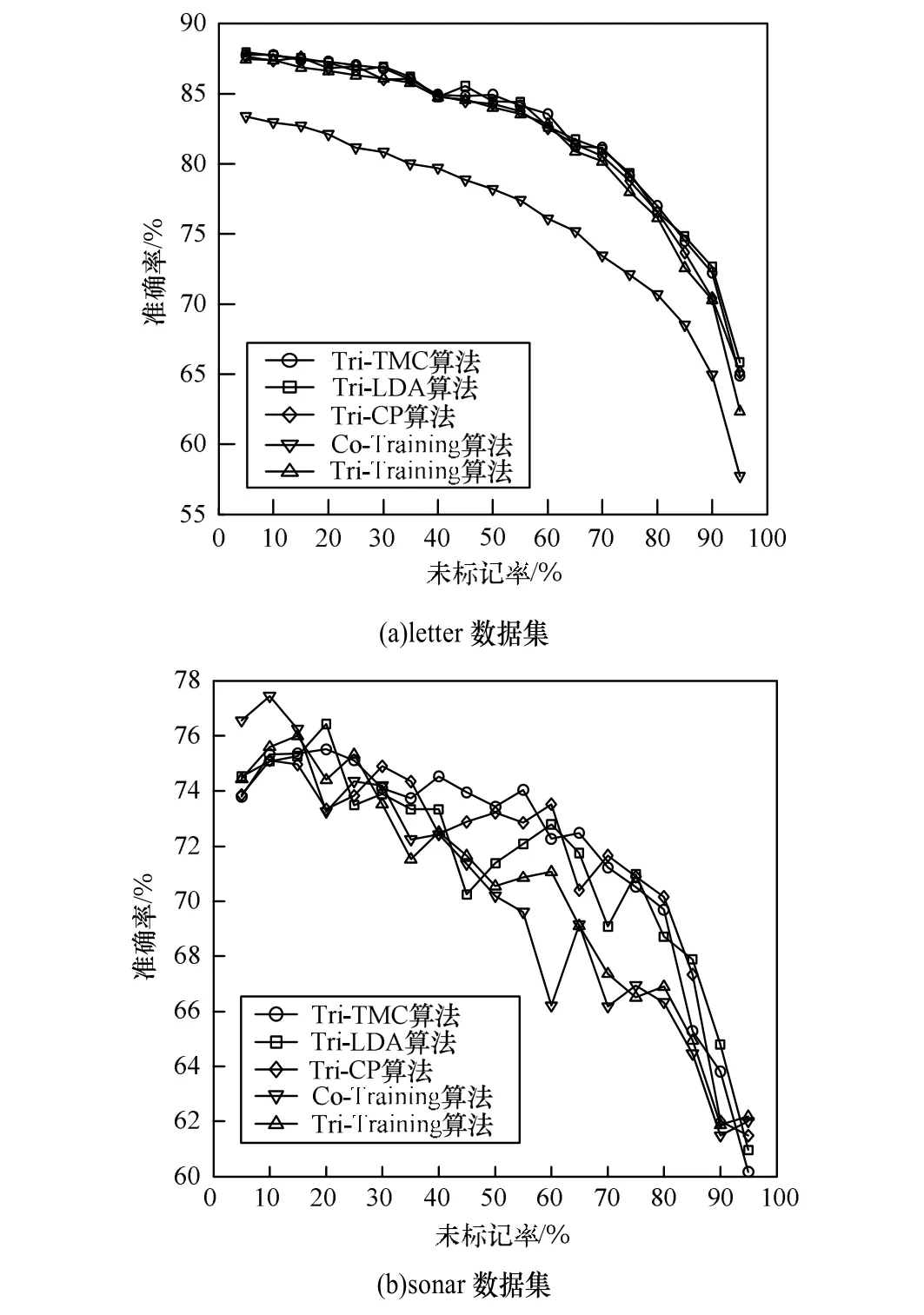
图2 算法准确率的变化趋势
根据以上结果,总结得到以下结论:(1)基于特征变换的Tri-Training算法具有更好的泛化能力;(2)与基于LDA 和CP一样,基于TMC对Tri-Training同样可取得较好的效果;(3)随着未标记率的升高,基于特征变换的Tri-Training算法性能优势越来越明显。
5 结束语
本文将特征变换方法应用到Tri-Training中。较之于传统Tri-Training算法,利用该方法构建的基分类器在保持相当的差异性同时具有更高的分类器准确率,进而可有效地提高Tri-Training的泛化能力。此外,本文提出了基于Mustlink和Cannot-link约束集合的特征变换方法(TMC)。实验结果表明,较之于随机抽样,特征变换能更有效用于Tri-Training算法中;较之于其他变换,本文提出的TMC方法同样是有效的。TMC方法可以很容易地扩展到其他Co-Training类型算法,因此,下一步的研究工作是将特征变换应用到其他协同学习方法中,同时对TMC方法进行深入的理论分析,将其用于其他领域。
[1] Blum A, Mitchell T. Combining Labeled and Unlabeled Data with Co-training[C]//Proc. of the 11th Annual Conference on Computational Learning Theory. Madison, USA: [s. n.], 1998: 92-100.
[2] Zhang Minling, Zhou Zhihua. CoTrade: Confident Co-training with Data Editing[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part B, 2011, 41(6): 1612-1626.
[3] Wang Yunyun, Chen Songcan, Zhou Zhihua. New Semisupervised Classification Method Based on Modified Cluster Assumption[J]. IEEE Transactions on Neural Networks and Learning Systems, 2012, 23(5): 689-702.
[4] Zhou Zhih ua, Li Ming. Tri-training: Explo iting Unlabeled Data Using Three Classifier s[J]. IEEE Transactions on Knowledge and Data Engineering, 2005, 17(11): 1529-1541.
[5] Angluin D, Laird P. Learning from Noisy Examples[J]. Machine Learning, 1988, 2(4): 343-370.
[6] W ang Wei, Zh ou Zhihua. Analyzing Co-tr aining S tyle Algorithms[C]//Proc. of the 18th Europea n Conference on Machine Learning. Warsaw, Poland: [s. n.], 2007: 454-465.
[7] Zhang Da oqiang, Chen Songcan, Zhou Zhih ua, et al. Constraint Proj ections for Ensemble Learning[C]//Proc. of the 23rd AAAI Conference on A rtificial Intelligence. C hicago, USA: AAAI Press, 2008: 758-763.
[8] Breiman L. Bag ging Predictors[J]. Machine Learning, 1996, 24(2): 123-140.
[9] Rodriguez J J, Kuncheva L I, Alonso C J. Rotation Forest: A New Classifier Ensemble Metho d[J]. IEEE Transactions on Pattern A nalysis and M achine I ntelligence, 2006, 28(10): 1619-1630.
[10] Kuncheva L. Combining P attern Classifiers: Methods and Algorithms[M]. [S. l.]: John Wiley and Sons, 2004.
[11] García-Pedrajas N, G arcía-Osorio C, Fyfe C. N onlinear Boosting Projections for Ensemble Construction[J]. Journal of Machine Learning Research, 2007, 8: 1-33.
[12] Zhou Zhihu a, Yu Yang. Ensembling Local L earners Through Multimodal Perturbation[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part B, 2005, 35(4): 725-735.
[13] Quinlan J R. C4.5: Progra ms for Machine Learning[M]. New York, USA: Morgan-Kaufmann, 1993.
[14] 郭华平. LySpoon[EB/OL]. (2012-10-10). http://nlp.zzu.edu.cn/ LySpoon.asp.
[15] Demsar J. Statistical Comparisons of Classifiers over Multiple Data Sets[J]. Journal of M achine Le arning Research, 2006, 7(1): 1-30.
编辑 金胡考
Tri-Training Algorithm Based on Feature Transformation
ZHAO Wen-liang, GUO Hua-ping, FAN Ming
(School of Information Engineering, Zhengzhou University, Zhengzhou 450052, China)
This paper proposes a new Tri-Training algorithm based on feature transformation. It employs feature transformation to transform labeled instances into new space to obtain new training sets, and constructs accurate and diverse classifiers. In this way, it avoids the weakness of bootstrap sampling which only adopts training data samples to train base classifiers. In order to make full use of the data distribution information, this paper introduces a new transformation method called Transformation Based on Must-link Constrains and Cannot-link Constrains(TMC), and uses it to this new Tri-Training algorithm. Experimental results on UCI data sets show that, in different unlabeled rate, compared with the classic Co-Training and Tri-Training algorithm, the proposed algorithm based on feature transformation gets the highest accuracy in most data sets. In addition, compared with the Tri-LDA and Tri-CP algorithm, the Tri-Training algorithm based on TMC has better generalization ability.
feature transformation; labeled instances set; difference; bootstrap sampling; generalization ability
10.3969/j.issn.1000----3428.2014.05.038
赵文亮(1989-),男,硕士研究生,主研方向:数据挖掘,机器学习;郭华平,博士研究生;范 明,教授。
2013-04-22
2013-08-07E-mail:wlzhao.gm@gmail.com
1000-3428(2014)05-0183-05
A
TP18
