改进的最小生成树自适应分层聚类算法
2014-08-04徐晨凯高茂庭
徐晨凯,高茂庭
上海海事大学信息工程学院,上海 201306
改进的最小生成树自适应分层聚类算法
徐晨凯,高茂庭
上海海事大学信息工程学院,上海 201306
1 引言
聚类是将物理或者抽象的集合分组成为由类似的对象组成的多个类的过程[1],其中最小生成树聚类方法已被广泛地研究[2-12],而如何快速准确地确定不一致边是一个关键问题。文[2]中使用全局静态阈值确定不一致边,当聚类簇密度相差较大时,聚类效果并不理想;文[3]中使用相对阈值来确定不一致边,但是往往受到不同边的相互干扰,从而使聚类结果不准确;文[4]使用影响域来确定不一致边,但是计算量稍大;文[9]结合了密度的方法来加强聚类的准确度;文[11]添加控制点及优先级的方法来优化聚类结果,但增加控制点需要更多的先验知识;文[12]结合网格的方法增强抵抗噪声的能力。
本文通过分析最小生成树边集内边的关系,提出一种改进的最小生成树自适应分层聚类算法,根据最近邻关系划分最小生成树的边集,为每个聚类簇自动生成合适的相对阈值来确定不一致边;通过多次迭代去除不同边的相互干扰;同时该算法能够自适应生成聚类数目,无需事先给定。在迭代过程中,因为最近邻关系不再改变,所以大大加快了计算速度。实验验证了这种方法的有效性。
2 基本概念
2.1 最小生成树聚类算法
传统最小生成树聚类算法[13]是一种基于图论的全局聚类算法,一般算法如下:将全局数据看成是一个完全图,将数据作为结点,将数据与数据的距离作为权值,则根据最小生成树算法得到一棵最小生成树,再将这棵最小生成树中权重大于阈值的边删除,剩余连通结点作为一类,即得聚类结果。
2.21 -NN分类算法
1-NN分类算法就是k-NN算法当k=1的情况,所以1-NN算法的算法思想和k-NN算法思想是一样的,即在训练样本中找到最近样本的k个最近邻。所谓最近邻,即为到该点距离最小的点称为该点的最近邻。对于距离[12]计算方法有很多,常见的如欧氏距离、曼哈顿距离、余弦距离等,本文使用的是欧氏距离,以下简称距离。
对于两个结点,若这两个结点互为最近邻关系,则称连接这两个结点的边为双向最近邻边;若只存在某个结点是另一结点的最近邻关系,则称连接这两个结点的边为单向最近邻边;若这两个结点不存在最近邻关系则称连接这两个结点的边为非最近邻边。
2.3 最小生成树性质
性质1以某个端点为顶点的所有边中,定有一条的另一个端点是该端点的最近邻。
证明:假设v1是v2的最近邻,则e(v1,v2)比e(v1,vn)都小,而v1,v2在其最小生成树T内却没有边,则v2显然定在最小生成树T内,故一定存在e(vk,v2)(k≠1),则先将T中e(vk,v2)移除,添加e(v1,v2),则显然所得也是一棵生成树,且其权值和小于T的权值和,这与T是最小生成树矛盾[3]。
性质2所得到的最小生成树定有度为1的结点。
证明:结点数为n的图的最小生成树边数为n-1,而度为边数的2倍,则该图的度为2n-1,若所有结点的度大于1,则该图的度至少为2n矛盾,即可证明。
性质3度为1的结点v1与所连接边的另一个端点v2,则定有v2是v1的最近邻。
证明:由性质1,由于其相连接的点是唯一的,则该点定是其最近邻结点。
2.4 最小生成树聚类算法与1-NN分类算法的关系
由上述几个性质可得,若每次都将度为1的点移除,若最后出现两个点一条边的情况,则任意移除一个点,即可得一个以最近邻为关系的序列,由于结点数为n,边数为n-1,定能留下一个结点,然后以该结点为起始点,反向使用前面所得的最近邻序列,可以发现,其实际上就是1-NN算法的步骤。所以,可以这样近似地认为,最小生成树全局聚类算法就是1-NN分类算法在聚类上的实现,最小生成树算法思想中包含最近邻规则。而从关系的角度,可以发现,最小生成树是1-NN关系图的一个子图,所以最小生成树是最近邻关系的一个简化。
3 基于最小生成树的自适应分层聚类算法
基于最小生成树的自适应分层聚类算法,以下简称TDMST,通过最近邻边关系,动态地计算每个聚类簇的阈值,从而获得较好的聚类结果。
3.1 基本概念
定义1计算实体两两之间的距离可以得到一个完全图G(V,E),其中V为G的点集,E为G的边集,一条边e的权重用W(e)表示,则对于G所对应的权值和最小的生成树称为该图的最小生成树[14],用MSTobjs表示。其中objs为实体集合,即

其中EMST是最小生成树中的边集。
定义2对于一棵树Tsub,若其结点集合是MSTobjs结点集的子集,其边集也是MSTobjs边集的子集,则称该树为MSTobjs的子树,使用MSTsubobjs表示,其结点集用Vsub表示,边集用EsubMST表示。即

显然MSTobjs是一棵MSTsubobjs。
定义3若一个集合内的所有元素都是同一个MSTobjs的MSTsubobjs,并且所有MSTsubobjs的点集相交为空,则称该集合为MSTobjs的子树集,使用SubMSTSet表示,即

定义4对于一棵MSTsubobjs,使用矩估计方法来估计其边e的均值,计算方式:

则根据一个控制参数ρ>0,按计算方式:

所得值Θ作为这棵MSTsubobjs阈值,用Θsubobjs表示。
定义5对于一棵MSTsubobjs,若其所有边都小于等于其阈值,则称为稳定子树,用MSTfinal表示,即

定义6若一个SubMSTSet集合内的所有MSTsubobjs均为MSTfinal,则称该子树集为聚类簇集,用ClusterSet表示,即

3.2 基本性质
性质4按双向最近邻边、单向最近邻边、无最近邻关系区分最小生成树的边集EMST中的边,所得集合为最小生成树的边集EMST的一个集合划分。
证明:根据定义可得,对于一条边,要么存在最近邻关系,要么不存在最近邻关系,当存在最近邻关系时,要么是单向的,要么是双向的,又因为双向最近邻边、单向最近邻边、无最近邻的前件是相互排斥的,所以不存在一条同时满足两个或两个以上边的条件,故最小生成树的每一条边存在且仅存在一个关系集合当中。
性质5若顶点v∈V,设以v作为顶点的边有e1,e2,…,en,其中ed(1≤d≤n)为双向最近邻边,则有以下关系:

证明:假设存在ei(1≤i≤n),W(ei)<W(ed),则ed的另一个端点不是v的最近邻,这与ed是双向最近邻边矛盾。
性质6若顶点v∈V,设以v作为顶点的边有e1,e2,…,en,其中es(1≤s≤n)是单向最近邻边,并且该边表示为v的最近邻,则有以下关系:

证明:假设存在ei(1≤i≤n),W(ei)<W(es),则ed的另一个端点不是v的最近邻,这与es是单向向最近邻边矛盾。
3.3 算法思想
由上述定义可得,求数据集的聚类过程,实际上就是求解一个聚类簇集的过程,其中每一个MSTfinal对应一个聚类簇。对于每一个MSTsubobjs均存在一个阈值Θsubobjs,则可以根据其阈值Θsubobjs判断其是否稳定。而根据最小树性质3中的证明,在MSTobjs中,以v为顶点的边中,定有边enear与其最近邻相连,故对于任意一个顶点,定满足性质5或者性质6的情况发生。为了保持最近邻关系,所以应该优先去除非最近邻边,其次去除单向最近邻边,无需去除双向最近邻边,根据以上优先次序,当一个MSTsubobjs的边集要删除一条双向最近邻边时,其边集内定所有的边均已是双向最近邻边,而根据定理5,则此时所有边权值定相等,则定不会大于阈值,故无需删除双向最近邻边,而对于一个MSTsubobjs的边数总是有限的,故算法定可以收敛。
3.4 算法步骤
3.4.1 TDMST算法
TDMST算法需要调用子树分裂算法,通过子树分裂算法将MSTsubobjs中超过阈值Θsubobjs的边去除,分裂成若干个新的MSTsubobjs。算法分成以下几个步骤:
(1)初始化,将用来存放最终聚类结果的集合ClusterSet置为空,使用一个队列QueueMST用来存放待检测的MSTsubobjs是否为MSTfinal,置空QueueMST。
(2)计算实体间的距离,构成关系完全图G(V,E,W),使用最小生成树算法得到G的一个MSTobjs,将其作为起始的MSTsubobjs加入到队列QueueMST。
(3)若队列QueueMST为空,则执行(6),否则执行(4)。
(4)取出队列QueueMST中的队首MSTsubobjs,根据MSTsubobjs计算其阈值Θsubobjs,检查该MSTsubobjs是否稳定,若稳定则将此MSTsubobjs作为MSTfinal放入到聚类结果集SetCluster中,执行(3),否则执行(5)。
(5)将MSTsubobjs作为参数传给子树分裂算法,后将子树分裂算法返回的SubMSTSet中所有的MSTsubobjs放入到队列QueueMST中,执行(3)。
(6)将集合SetCluster作为结果返回,算法结束。
3.4.2 子树分裂算法
子树分裂算法是将一个MSTsubobjs变成若干个MSTsubobjs的方法,具体步骤如下:
(1)SubMSTSet置为空。
(2)根据所得MSTsubobjs计算其阈值Θsubobjs,根据优先级别去掉超过阈值的边。
(3)重新遍历一次MSTsubobjs,相互连接的结点作为新的MSTsubobjs,加入到SubMSTSet。
(4)返回SubMSTSet。
3.5 算法复杂度分析
对于初始MSTobjs的计算必须涉及关系完全图G(V,E),则设V的个数为N,则由于是完全图,所以所需要计算的E的个数是N(N-1)/2;而对于最小生成树算法,若使用Prim算法[14]的复杂度为O(N2),使用Kruskal算法[14]的度为O(N2lbN);对于计算阈值的复杂度为O(N),而对于是否超过阈值也需要O(N)的复杂度;对于子树分裂算法的复杂估计如下,因为一棵树最多为N-1条边,删去这些边的算法复杂度至多为O(N),后寻找连通的点的复杂度至多为O(N),得分裂算法的复杂度至多为O(N);而TDMST算法最多调用2K次分裂算法,其中K为聚类簇数,所以TDMST的算法复杂度为O(NK)。
4 实验与分析
4.1 实验设计思路
本文设计了三个对照实验,将本文算法与传统最小生成树MST算法[2]、k-means算法[15]、DBSCAN算法[16]进行比较,从而验证本文算法在聚类密度相差较大时依然可以有效聚类;同时对于传统基于最小生成树算法适用的情况本文算法同样适用。实验一主要验证在聚类密度相差较大时本文算法依然可以得到较好的聚类结果,而其他传统聚类算法无法适应;实验二验证本文算法和其他部分传统聚类算法一样可以区分任意形状;实验三验证本文算法能够在一定的噪声影响下,取得较理想的聚类结果。
4.2 实验数据
实验设置采用二维点集,具体见描述表1,数据分布可视化显示见图1、图2、图3。
表1 实验数据集

图1 Set1数据分布

图2 Set2数据分布
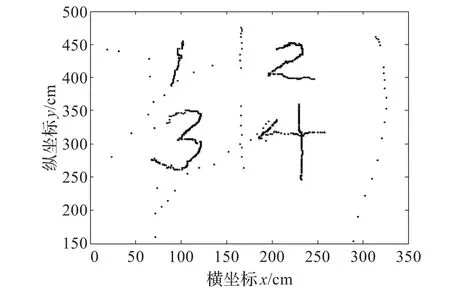
图3 Set3数据分布
由图可较为直观地得到Set1中共4个类别,其中类别1较为稀疏;类别2和类别3较为紧密,并且类间距离较小;类别4是一些孤立点。Set2中共有5个类别,其中类别1和类别2呈螺旋状;类3较为分散;类4较为紧密;类5是一个孤立点。Set3共有4类,其中类1,类2,类3,类4分别代表图形数字1,2,3,4,并有其他离散点作为噪声,随机分布在该4类点集周围。
4.3 实验准确度测量方法
对于实验数据的聚类准确度计算方法使用方法采用常见的查准率(Precision)[17],使用p表示。查准率能够较为直观地反映出聚类结果和实际真实结果之间的差异,计算方法如下:
p=聚类簇正确数据点数/实际该类数据点总数
4.4 实验结果
各聚类算法实验最佳聚类结果见表2,同时本文还可视化了TDMST对各类数据的聚类结果,详见图4、图5、图6。

表2 各算法对实验数据的最佳聚类准确度

图4 TDMST对Set1的聚类结果
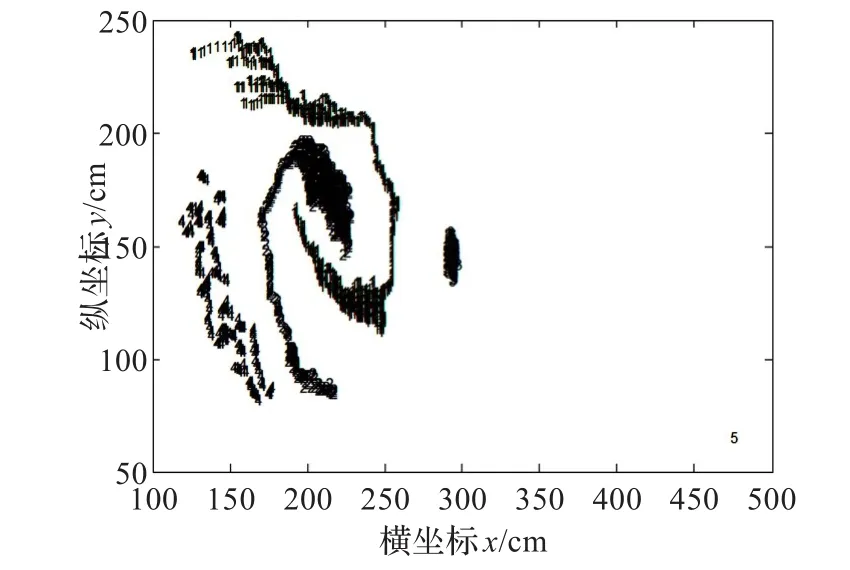
图5 TDMST对Set2的聚类结果

图6 TDMST对Set2的聚类结果
对于Set1数据集,与MST算法、DBSCAN算法相比,TDMST算法与k-means算法更能够对Set1数据集进行较为准确的聚类,并且TDMST算法准确度为100%。对于DBSCAN而言,由于类1的密度要小于类2和类3合并后的密度,所以导致若要合并类1,则类2和类3定合并,若要分开类2和类3,则类1也定被拆分成多个类;对于传统的最小生成树MST算法,由于简单地使用一个全局阈值,类1的类内距离大于类2和类3间的距离,从而导致与DBSCAN算法一样的情况;但是实际上,类1与类2、类3的类间距离要远远大于类1的类内距离,其类边界非常明显,而正是因为使用了全局阈值才会导致算法对类1、类2及类3无法准确区分的现象发生。虽然k-means算法的准确度非常高,但是由于k-means非常依赖初始位置[17],所以其要取得如此高的准确度要求较高。
对于Set2数据集,k-means算法只适合区分凸形状的聚类簇[17],所以在这个实验集上准确度较低,而TDMST算法和DBSCAN算法都适合区分任意形状的聚类簇,所以准确度达到100%,同样,虽然MST也可以区分任意形状的聚类簇,但是由于其使用全局的阈值,所以造成了一些数据点的误分。
对于Set3数据集,由于k-means算法对于噪声点敏感[15],所以在这个实验集上准确度依然不高;DBSCAN算法由于噪声的影响,会导致密度的改变[16],从而影响聚类结果。
对于TDMST而言,其表现最重要的还是阈值的选取,阈值的大小决定了聚类的灵敏度,阈值较小时,不满足的阈值边就多,导致聚类簇的数目的增加。
4.5 实验结论
由实验结果可知:
(1)TDMST算法的聚类效果要好于传统最小生成树MST算法,在大部分情况下优于DBSCAN,在不同形状的聚类上,其聚类结果比k-means算法更优。并且TDMST算法的控制参数只有一个,在使用上比需要设置两个参数的DBSCAN更为方便,并且不受初始值的影响。
(2)虽然TDMST算法对于阈值的选取更多是凭借经验,但是实际中是借用了统计学上的显著性的概念,所以具有一定的数学意义[3]。
(3)由于TDMST采用的是距离判断,所以TDMST能够很好地适应空间数据分布不均的现象,可以发现任意形状的聚类簇。
(4)由于TDMST算法本质上采用的是最近邻思想,即“一个数据点与其最近邻同属于一个类别”,算法建立在该假设基础上,这就注定了其算法本身更适合低维空间。
5 结束语
本文提出了一种基于最小生成树的自适应阈值自顶向下分层聚类算法,该算法基于最小生成树,简化最近邻关系,并且统计当前最小生成树边集的均值及方差来计算得出阈值,有效地获取了聚类结果。一方面,由于最近邻思想在高维数据无法有效地应用,所以对高维数据而言,聚类之前应该先做一个合适的降维过程,以减少维数对于算法的影响,同时有效地降低算法计算量;另一方面,TDMST算法的优势在于能够自动确定阈值,是否可以结合一些有效的聚类模型从而进行高维的聚类,将是下一步的工作。
[1]Han J W,Kamber M.Data mining:concepts and techniques[M]. San Francisco:Morgan Kaufmann,2000.
[2]Gygorash O,Zhou Yan,Jorgensen Z.Minimum spanning tree based clustering algorithms[C]//18th IEEE International Conference on Tools with Artificial Intelligence,2006:73-81.
[3]Zahn C T.Graph-theoretical methods for detecting and describing gestalt clusters[J].IEEE Transactions on Computers,1971,20(1):68-86.
[4]叶青,唐鹏举.一种改进的基于MST的聚类算法[J].计算机与现代化,2011(8):17-22.
[5]王小乐,刘青宝,陆昌辉.一种最小生成树聚类算法[J].小型微型计算机系统,2009,30(5):877-882.
[6]陈新泉.一种基于MST的自适应优化相异性度量的半监督聚类方法[J].计算机工程与科学,2011,33(10):154-158.
[7]李密青,郑金华,罗彪.一种基于最小生成树的多目标进化算法[J].计算机研究与发展,2009,46(5):803-813.
[8]毛韶阳,李肯立,王志和.最小生成树聚类方法研究[J].怀化学院学报,2007,26(5):38-39.
[9]崔光照,曹玲芝,张勋才,等.基于密度的最小生成树聚类算法研究[J].计算机工程与应用,2006(5):156-158.
[10]金欣,王晶,沈奇威.分布式最小生成树聚类的设计与实现[J].计算机系统应用,2011,20(7):69-75.
[11]汪闽,周成虎,裴韬,等.一种带控制节点的最小生成树聚类算法[J].中国图象图形学报,2002,8(7):765-770.
[12]欧阳浩,肖建华.基于网格的最小生成树聚类算法[J].计算机与现代化,2006(12):81-83.
[13]Jain A,Murty M,Flynn P.Data clustering:A review[J]. ACM Computing Surveys,1999,31(3):264-323.
[14]Graham R L,Hell Pavol.On the History of the Minimum SpanningTreeProblem[J].AnnalsoftheHistoryof Computing,1985,7(1):43-57.
[15]Macqueen J.Some methods for classification and analysis of multivariate observations[C]//Proceedings of the 5th BerkeleySymposiumonMathematicalStatisticsand Probability,1967:281-297.
[16]Ester M,Kriegel H P,Sander J,et al.A density-based algorithm for discovering clusters in large spatial databases with noise[C]//Proceeding the 2nd International Conference on Knowledge Discovery and Data Mining(KDD),Portland,1996:226-231.
[17]孙吉贵,刘杰,赵连宇.聚类算法研究[J].软件学报,2008,19(1):48-61.
XU Chenkai,GAO Maoting
College of Information Engineering,Shanghai Maritime University,Shanghai 201306,China
Classical clustering algorithm based on the minimum spanning tree often needs to know the number of clusters beforehand and use static global threshold to cluster,which leads to the performance of the algorithm low and the computation complex for the uneven distributed data.An improved adaptive hierarchical clustering algorithm based on minimum spanning tree is proposed,which automatically generates different thresholds for every cluster to adapt for the uneven distributed data according to the nearest neighbor relationship and adaptively determines the number of clusters.Experiments demonstrate that this algorithm has good performance,especially could cluster effectively for the uneven distributed data. Key words:nearest neighbor;adaptive clustering;minimum spanning tree;clustering analysis
针对传统最小生成树聚类算法需要事先知道聚类数目和使用静态全局分类依据,导致聚类密度相差较大时,算法有效性下降,计算复杂度大等问题,提出一种改进的最小生成树自适应分层聚类算法,根据最近邻关系,自动为每个聚类簇设定独立的阈值,使之适应分布密度相差较大的情况,并能自动确定聚类数目。实验表明,算法具有较好的性能,尤其对数据密度分布不均匀的情况也能得到较好的聚类结果。
最近邻;自适应聚类;最小生成树;聚类分析
A
TP311
10.3778/j.issn.1002-8331.1212-0253
XU Chenkai,GAO Maoting.Improved adaptive hierarchical clustering algorithm based on minimum spanning tree.Computer Engineering and Applications,2014,50(22):149-153.
上海市科委科技创新项目(No.12595810200);上海海事大学科研项目。
徐晨凯(1989—),男,硕士研究生,CCF学生会员,主要研究领域为数据挖掘;高茂庭(1963—),男,博士,教授,系统分析员,CCF高级会员,主要研究领域为数据挖掘,数据库与信息系统。E-mail:kk9265w@gmail.com
2012-12-21
2013-04-01
1002-8331(2014)22-0149-05
CNKI网络优先出版:2013-04-18,http://www.cnki.net/kcms/detail/11.2127.TP.20130418.1618.021.html
