基于数值模拟与试验运行数据的电站锅炉燃烧系统复合建模
2014-08-03牛玉广康俊杰
牛玉广,沙 超,康俊杰
(华北电力大学新能源电力系统国家重点实验室,北京102206)
机理建模是由基本物理定律,即利用各个专门学科领域提出的物质和能量的守恒性和连续性原理以及系统(或设备)的结构数据推导出模型的.这种方法得到的数学模型称为机理模型,建立模型的方法称为解析法.Fluent软件属于计算流体软件,可用于流体传热和燃烧过程的数值模拟.利用该软件来完成炉膛内完整的煤粉燃烧过程的数值模拟,得到炉膛内的流场和温度场以及O2体积分数和NOx排放质量浓度等分布,进而得到锅炉效率.但是这种数值模拟模型的计算速度很慢,无法直接应用到锅炉燃烧优化中.
机器学习建模最小二乘支持向量机(LS-SVM)对非线性系统具有很强的逼近能力,以等式约束代替不等式约束,将模型的训练转化为线性方程组的求解,简化了计算并缩短了训练时间,非常适合于根据试验数据建立模型[1-4].但是这种黑箱辨识方法无法反映锅炉内部机理,建模精度受建模时训练样本数据的影响较大,好的样本数据对LS-SVM 模型非常重要[5-6].
电站锅炉燃烧过程是个复杂的物理化学过程,涉及到燃烧学、流体力学、热力学和传热传质学等学科领域.目前,用于电站锅炉燃烧优化的模型多为神经网络和支持向量机等机器学习模型,建模数据只是锅炉试验数据,数据来源过于单一且无法涉及所有工况,这样会极大地影响机器学习模型的精度.
笔者首先建立锅炉燃烧系统的数值模拟模型,然后通过模型计算出LS-SVM 建模所需的初始训练样本,得到燃烧系统的初始LS-SVM 模型,再利用现场热态试验数据对初始LS-SVM 模型进行修正,最后根据实际运行数据对模型进行实时更新,以保证模型能够很好地跟踪锅炉燃烧系统当前的特性,为燃烧优化打好基础[7-8].模型的修正与更新是一种基于LS-SVM 的模型更新算法[9],相比于重新建模,它可以有效地减少计算量,从而提高模型更新速度.
1 数值模拟模型
目标煤粉锅炉的数值模拟模型如下:气固两相间的湍流计算采用RNGk-ε湍流模型,煤粉颗粒的轨迹场采用基于拉格朗日的随机颗粒轨道方法,辐射传热计算采用离散传播法,煤粉挥发分的释放采用双平行反应模型,气相混合燃烧采用混合分数模型,焦炭燃烧采用扩散动力学模型,燃烧生成NOx机理采用De'Soete提出的模型,热力型NOx的计算基于Zeldovich 提出的机理.最后采用Spalding 和Patankar建立的数值方法进行计算,其中计算区域的离散化采用正交非均匀交错网格,使用控制容积法推导差分方程,差分方程的求解采用压力-速度校正的Simpler方法,颗粒相计算采用拉氏方法[10].
确定输入变量后,利用正交法给定训练样本数据组数和各输入变量的值,再利用建立的数值模拟模型计算每组输入对应的输出,得到变量列表,作为初始LS-SVM 模型的训练样本.
电站锅炉实际运行中很多工况都无法实现,如过量空气系数和一次风压力超出合理范围以及各次风门全开等情况.但对于利用LS-SVM 建立的电站锅炉燃烧系统模型,这些工况相当于各个变量取值的边界.对于初始LS-SVM 模型来说,超出模型边界会导致模型预测的失效,而且在电厂分散控制系统(DCS)的海量运行数据中寻找期望的工况也相当繁琐.所以利用数值模拟模型为初始LS-SVM 模型提供建模的数据是十分必要的.数值模拟模型所计算出的工况基本反映了实际情况,但是有些工况在实际试验数据与历史数据中难以出现,因此数值模拟模型所得的数据能使建模所需样本更全面.
2 初始LS-SVM 模型更新算法
2.1 基本理论
根据LS-SVM 算法,初始LS-SVM 模型的表达式为
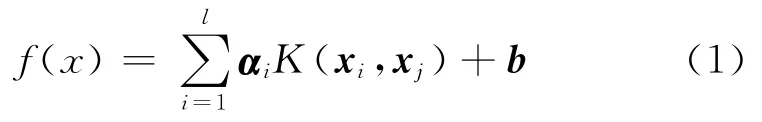
式中:xi为支持向量;K(xi,xj)为核函数,是满足Mercer条件的对称函数;ai为支持变量;b为偏差.
对于初始训练集(xk,yk),k=1,…,l,支持向量机建模学习过程由式(2)得到.通过式(3)可得到模型参数和偏差b.根据初始LS-SVM 模型建模机理及常规核函数的定义可知,对于一个输入x,模型的输出受支持向量集中与x距离最近的样本的影响较大,该距离是指输入向量与样本向量的欧氏距离.因此,当模型预测输出与实际输出的偏差较大时,可以使用新的输入代替与之距离最近的样本或直接将其添加到样本集中,同时更新相应的模型参数和b,以便模型可以适应新的输入.
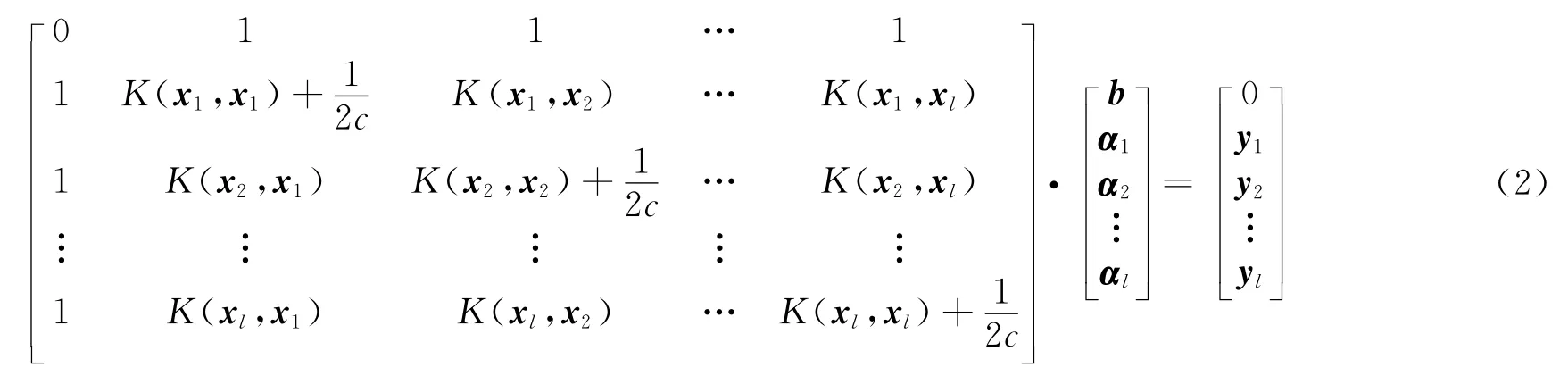
式中:c为正规化参数,由选择的模型决定.
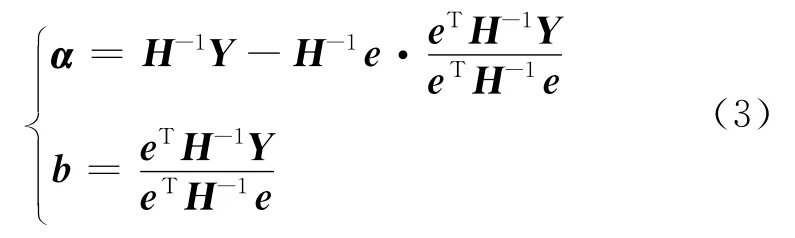
式中:H为模型特征矩阵;Y为模型的输出向量,Y=[y1,…,yi,…,yl];eT=[1,…,1]1×l.

2.2 模型更新算法
模型更新算法分为样本的添加算法和替换算法.对于初始训练集(xk,yk),k=1,…,l,首先对输入向量进行归一化处理,将变量归一化到[-1,1],归一化公式如下:
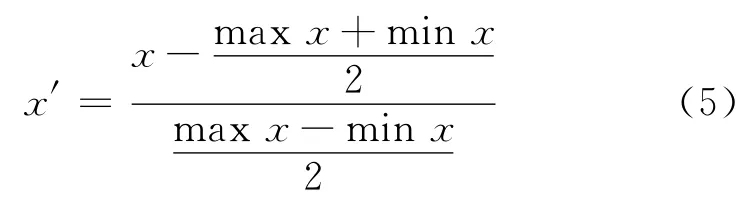
对于新的输入xj,比较模型的预测输出Yj与对象的实际输出yj,通过式(6)计算模型预测输出的相对误差δ.若δ≤δs(δs为允许的最大误差),则说明模型对新输入有效;若δ>δs,则模型失效,需要对模型进行更新.
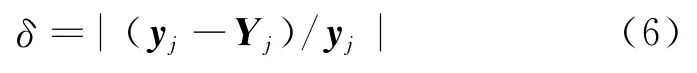
当模型失效时,计算新样本xj与每一个支持向量xk之间的欧氏距离,其中与第i个样本的距离最近为d,若d≤ds(ds为归一化后欧氏距离设定值,是替换算法与添加算法的判定标准,其取值范围为[0,2]),说明新样本与原支持向量集中第i个样本特性相似,则进行替换算法;若d>ds,说明新样本与原支持向量集特性偏差较大,则进行添加算法.
在替换算法中假设支持向量集中第i个样本(xi,yi)与新样本(xj,yj)的距离最近,则第i个样本被替换.根据式(7),将模型特征矩阵H的第i行用gr代替,第i列用代替,第i行第i列的元素用代替,得到新的特征矩阵Hr.
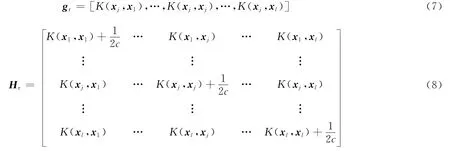
将模型输出向量Y=[y1,…,yi,…,yl]中第i个元素用yj替换,得到新的模型输出向量Yr=[y1,…,yj,…,yl].最后通过式(9)计算得到新的模型参数αr和br.

在添加算法中假设需要添加的新样本为(xj,yj),根据式(10),将ga和添加到特征矩阵的最后,得到新的特征矩阵Ha.
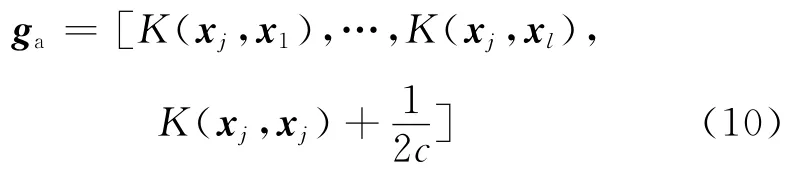
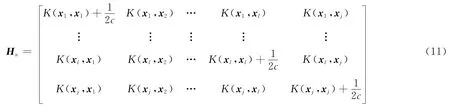
将yj添加到输出向量Y=[y1,…,yl]的最后,得到新的模型输出向量Ya=[y1,…,yl,yj].通过式(12)计算出模型参数αa和ba.
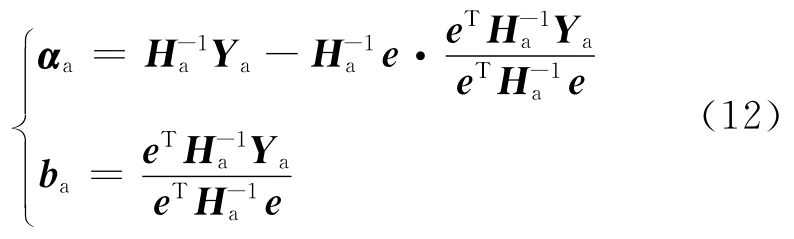
不同的模型在计算欧氏距离时会有很大差异,但通过式(5)可以将所有模型的所有变量都归一化到[-1,1],则变量之间的距离的取值范围为[0,2],从而使得不同模型之间的距离d具有可比性.假设一个n维模型,当距离阈值为ds时,对于新的输入变量,如果d>ds,采用添加算法将新输入变量加入到建模变量中,则经过添加算法后模型的训练样本规模最大可达到([2/ds]+1)n,此处“[]”为取整符号.因此,当模型维数较大时,通过模型更新算法会生成巨大的建模样本,导致模型的计算量增大.根据以上分析,为了使模型更新后的训练样本集不至于过大,同时又能满足提高模型精度的要求,ds应根据具体模型视情况而定.图1给出了初始LSSVM 模型更新算法的总体流程.
2.3 NOx 排放质量浓度的模型更新算法仿真
在某电厂600 MW 机组稳态工况下的DCS中选取历史运行数据进行仿真实验.历史运行数据的时间为2013-10-17—11-17,采样间隔为1min,共计45 307个工况.以工况间的相似度为依据,选取最具代表性的70个工况作为初始LS-SVM 模型的训练样本,再选取75个工况作为测试样本,用来检验模型与模型更新.
实验数据的变量分别为:负荷,总燃料质量流量(qm),一次风压力p,二次风A~F层挡板开度k1~k6,前、后墙燃尽风挡板开度k7和k8及烟气中氧体积分数φ(O2).输出为NOx排放质量浓度ρ(NOx).
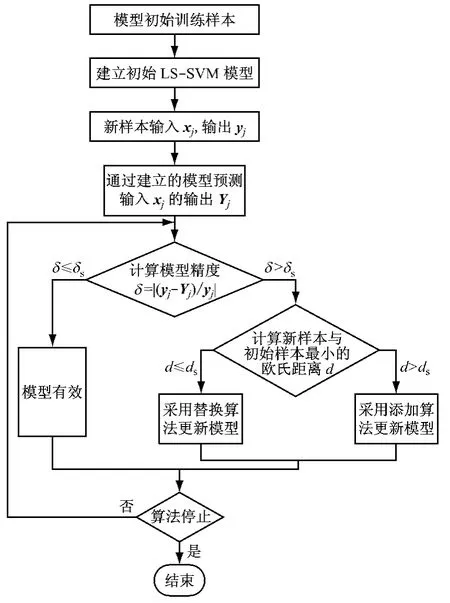
图1 初始LS-SVM 模型更新算法的流程图Fig.1 Flowchart of updated LS-SVM algorithm
在模型训练前,首先将模型训练样本的输入变量通过式(5)归一化到[-1,1],然后利用选取的53个训练样本建立NOx排放质量浓度的初始LSSVM 模型.在利用初始LS-SVM 模型对测试样本进行预测前,首先计算测试样本集与训练样本集的最小欧氏距离d,然后将测试样本按d从小到大排列.为了确保d的同一性,这里的d是将样本归一化后计算得到的.图2给出了初始LS-SVM 模型对105个工况预测的结果,其中左边为训练样本预测,右边为按d从小到大排列的测试样本预测.由图2可以看出,对于d较大的工况,初始LS-SVM 模型预测值与测量值存在很大误差.表1 给出了初始LS-SVM 模型对各工况下NOx排放质量浓度预测的平均相对误差和平均绝对误差e,其中d=0的为训练样本,测试样本分为4个部分.由表1可以看出,随着d的增大,模型的预测能力下降,当d>1.5时,模型已经基本失效.

表1 初始LS-SVM 模型的预测能力Tab.1 Prediction ability of original LS-SVM model
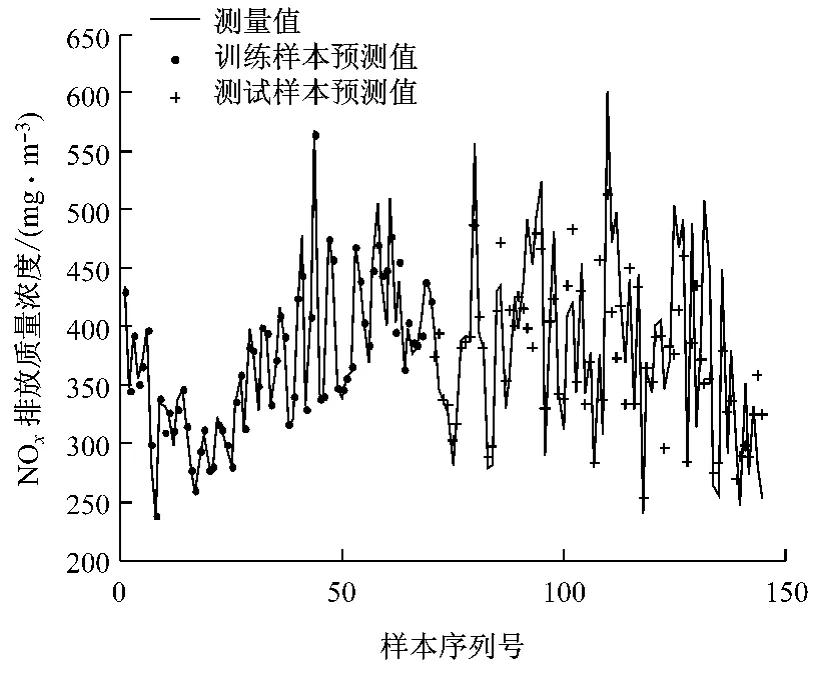
图2 初始LS-SVM 模型对NOx 排放质量浓度的预测结果Fig.2 NOxemission predicted by original LS-SVM model
根据以上建立NOx排放质量浓度初始LSSVM 模型,通过测试样本对模型预测能力的检验可知,当d>1时模型的失效率已接近100%,且d>1的测试样本个数占总测试样本个数的20%.考虑到锅炉燃烧系统模型的特殊性,模型输入不可能覆盖取值范围内所有值,这里最小欧氏距离阈值ds取1,可以避免更新后由于模型训练样本集过大而导致模型计算效率下降的问题.通过模型更新算法解决固定模型存在的问题,计算中δs取3%.图3给出了初始LS-SVM 模型更新后对105 个工况的预测结果.由图3可以看出,相比模型更新前,更新后的模型精度有了显著的提升.表2给出了初始LS-SVM模型更新后对不同距离d中NOx排放质量浓度预测的平均相对误差ˉδ和模型更新率,其中模型更新率为一个距离范围内的更新次数与该范围内工况个数的比值.由表2可以看出,随着d的增大,模型更新率增大.模型的平均相对误差控制在3%以下,相比初始LS-SVM 模型显著降低,说明初始LS-SVM模型更新算法能够较好地预测各工况下的NOx排放质量浓度.
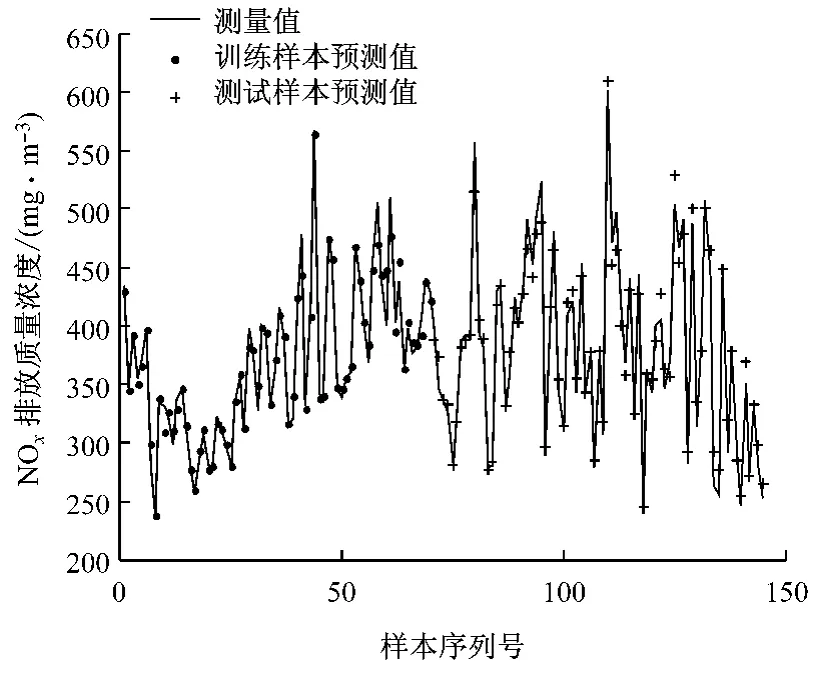
图3 初始LS-SVM 模型更新后对NOx 排放质量浓度的预测结果Fig.3 NOxemission predicted by updated LS-SVM model

表2 初始LS-SVM 模型更新后的预测能力Tab.2 Prediction ability of updated LS-SVM model
3 燃烧系统复合建模
3.1 复合建模主要步骤
燃烧系统复合建模方法的总体流程(见图4)如下:(1)选用可用于流体传热和燃烧过程的数值模拟软件Fluent对目标锅炉的煤粉燃烧过程进行建模;(2)确定输入变量,利用正交法给定训练样本数据个数和各输入变量的值,通过数值模拟模型计算每个输入变量对应的输出值,得到变量列表;(3)将变量列表作为训练样本集,建立初始LS-SVM 模型;(4)采集并整合目标锅炉的燃烧调整试验数据,利用最小欧氏距离法修正初始LS-SVM 模型;(5)以δs为基准,利用锅炉的实时运行数据对初始LS-SVM 模型进行实时更新.

图4 燃烧系统复合建模方法的流程图Fig.4 Flowchart of hybrid modeling for boiler combustion system
3.2 复合建模实例仿真
数值模拟建模对象为DG2090/25.4-II7型600 MW 超临界参数变压直流锅炉,通过数值模拟模型得出500个不同工况下的数据,根据各工况精度和多样性,选取其中99 个数据作为复合建模初始样本,其中部分工况的数据见表3.由于建模之前对训练样本进行特性选择至关重要,在建模之前首先用序列前向选择(SFS)对模型变量进行选择,然后进行LS-SVM 建模.根据表3,基于LS-SVM-SFS建立NOx排放质量浓度的模型,然后对建模锅炉进行热态试验,提取试验数据,再从DCS中提取历史运行数据,利用试验数据和历史运行数据修正初始LSSVM 模型,并通过实时运行数据对所建模型进行验证和更新.实时运行数据选取的时间段为2013-12-07 T 0:00—23:59,采样间隔为1min,在此段时间内锅炉负荷波动较大,所选数据具有代表性.
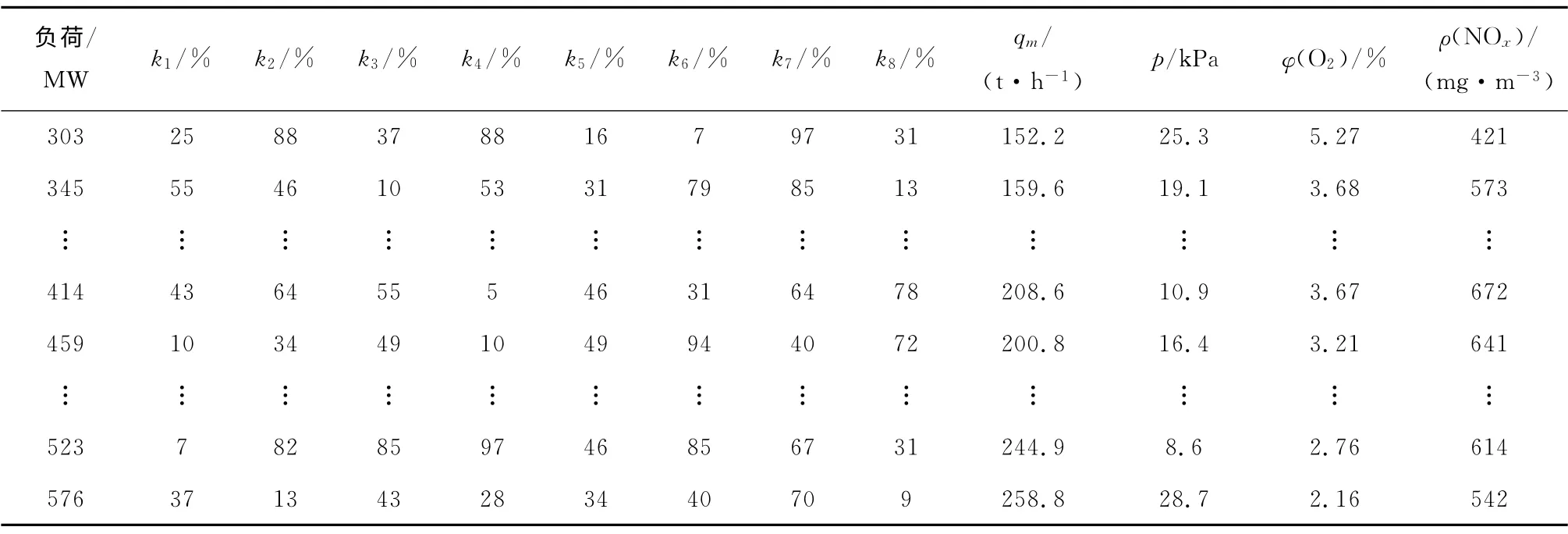
表3 复合建模的部分初始样本数据Tab.3 Initial sample data for hybrid modeling
首先,通过历史运行数据基于初始LS-SVM 模型对NOx排放质量浓度进行预测,预测结果见图5.由图5可知,由初始LS-SVM 模型得到的NOx排放质量浓度预测值与测量值的平均相对误差为4.76%.利用复合建模方法得到的NOx排放质量浓度预测值与测量值的对比见图6.由图6可知,由复合建模方法得到的NOx排放质量浓度预测值与测量值的平均相对误差为1.92%.对比图5 与图6 可知,复合建模方法相比于初始LS-SVM 模型的预测效果更好.通过模型更新算法可以有效地跟踪当前机组特性,使模型始终保持较高的精度,为燃烧优化打下良好的基础.
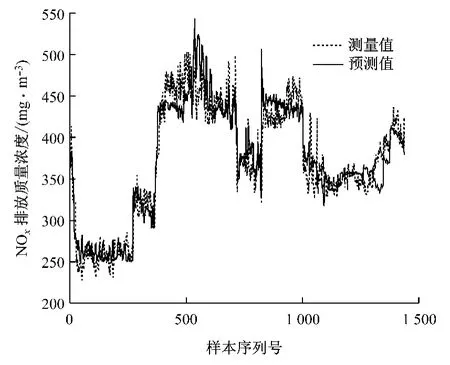
图5 初始LS-SVM 模型对NOx 排放质量浓度预测值与测量值的对比Fig.5 Comparison of NOxemission between prediction results by original LS-SVM model and actual measurements
4 结 论
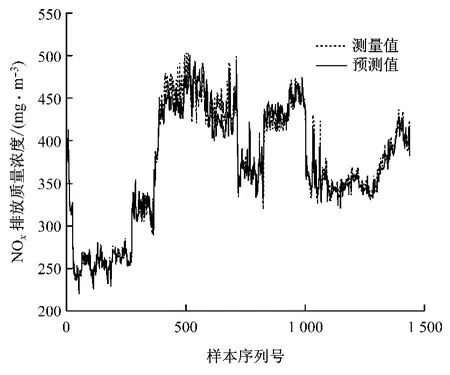
图6 利用复合建模方法得到的NOx 排放质量浓度预测值与测量值的对比Fig.6 Comparison of NOxemission between prediction results by hybrid modeling method and actual measurements
初始LS-SVM 模型能够快速、有效地跟踪预测模型,但该模型受初始训练样本的影响较大,单纯的试验数据无法满足建模需求.通过建立锅炉燃烧系统的数值模拟模型,为LS-SVM 建模提供初始训练样本,然后利用试验数据修正模型.利用初始LSSVM 模型的更新算法和锅炉实时运行数据来更新模型可以有效地跟踪当前机组特性,进一步提高了模型精度.
[1]顾燕萍,赵文杰,吴占松.基于最小二乘支持向量机的电站锅炉燃烧优化[J].中国电机工程学报,2010,30(17):91-97.
GU Yanping,ZHAO Wenjie,WU Zhansong.Combustion optimization for utility boiler based on least square-support vector machine[J].Proceedings of the CSEE,2010,30(17):91-97.
[2]王春林,周昊,李国能,等.基于遗传算法和支持向量机的低NOx燃烧优化[J].中国电机工程学报,2007,27(11):40-44.
WANG Chunlin,ZHOU Hao,LI Guoneng,etal.Support vector machine and genetic algorithms to optimize combustion for low NOxemission[J].Proceedings of the CSEE,2007,27(11):40-44.
[3]王春林,周昊,周樟华,等.基于支持向量机的大型电厂锅炉飞灰含碳量建模[J].中国电机工程学报,2005,25(20):72-76.
WANG Chunlin,ZHOU Hao,ZHOU Zhanghua,et al.Support vector machine modeling on the unburned carbon fly ash[J].Proceedings of the CSEE,2005,25(20):72-76.
[4]高芳,翟永杰,卓越,等.基于共享最小二乘支持向量机模型的电站锅炉燃烧系统的优化[J].动力工程学报,2012,32(12):928-933.
GAO Fang,ZHAI Yongjie,ZHUO Yue,etal.Combustion optimization for utility boilers based on sharing LSSVM model[J].Journal of Chinese Society of Power Engineering,2012,32(12):928-933.
[5]王晓丹,王积勤.支持向量机训练和实现算法综述[J].计算机工程与应用,2004,40(13):75-80.
WANG Xiaodan,WANG Jiqin.A survey on support vector machines training and testing algorithms[J].Computer Engineering and Applications,2004,40(13):75-80.
[6]SUYKENS J A K,BRABANTER J D,LUKAS L,etal.Weighted least squares support vector machines:robustness and sparse approximation[J].Neurocomputing,2002,48(1/2/3/4):85-105.
[7]张毅.电站锅炉燃烧优化控制理论[D].北京:清华大学,2006.
[8]顾燕萍,赵文杰,吴占松.采用最优MVs决策模型的电站锅炉燃烧优化[J].中国电机工程学报,2012,32(2):39-44.
GU Yanping,ZHAO Wenjie,WU Zhansong.An optimal MVs decision-model for boiler combustion optimization[J].Proceedings of the CSEE,2012,32(2):39-44.
[9]GU Yanping,ZHAO Wenjie,WU Zhansong.Online adaptive least squares support vector machine and its application in utility boiler combustion optimization systems[J].Journal of Process Control,2011,21(7):1040-1048.
[10]贾东坡,刘忠,钟晓晖,等.分离式热管换热器蒸发段倾角参数研究[J].电站系统工程,2012,28(5):8-10.
JIA Dongpo,LIU Zhong,ZHONG Xiaohui,etal.Research on the evaporator section inclination parameters of separate type heat pipe exchanger[J].Power System Engineering,2012,28(5):8-10.
