Parzen窗核密度估计的模式分类隐私保护方法
2014-07-07张友能王德兵汪伟
张友能,王德兵,汪伟
(安徽工贸职业技术学院,安徽淮南 232001)
Parzen窗核密度估计的模式分类隐私保护方法
张友能,王德兵,汪伟
(安徽工贸职业技术学院,安徽淮南 232001)
针对大规模数据集上的模式分类任务,提出了一种基于Parzen窗核密度估计的模式分类隐私保护算法。该算法首先利用Parzen窗算法对原始大规模训练集服从的概率密度进行估计,然后根据估计的概率密度函数构造la个替换训练样本,其中l为原始样本的数目,a通过10折交叉验证方式确定。最后发布替换训练样本进行模式分类,以实现原始数据上的隐私保护。在Adult数据集上的仿真实验充分验证了该算法的有效性。
parzen窗;核密度估计;数据发布;隐私保护
数据挖掘①Han J W,Kamber,Data Mining Concepts and Techniques,北京:机械工业出版社,2001年,第257-259页。技术的发展极大地促进了人们对海量数据的利用,同时也引起了数据隐私的泄露。为了进行隐私保护②周水庚,李丰,陶宇飞,肖小奎:《面向数据库应用的隐私保护研究综述》,《计算机学报》2009年第5期,第847-861页。,同时又能对数据中隐藏的有用信息进行挖掘,面向隐私保护的数据挖掘应运而生。本文针对大规模数据集上的模式分类任务,提出了一种基于Parzen窗③周恩策,刘纯平,张玲燕,龚声蓉,刘全:《基于时间窗的自适应核密度估计运动检测方法》,《通信学报》2011年第2期,第106-114,124页。核密度估计的模式分类隐私保护算法,避免了原始数据上的隐私泄露。
模式分类就是指对表征事物或现象的各种形式的信息进行处理和分析,以对事物或现象进行描述、辨认、分类和解释的过程,是人类以及动物的最基本的智能表现。随着人类收集和存储数据能力的不断增长以及计算机运算能力的飞速发展,利用计算机来分析数据进行模式分类的要求越来越广泛,越来越迫切。近些年随着研究人员的深入研究,出现了许多优秀的分类算法。如人工神经网络(Artificial Neural Network,ANN)④Yang J,Yu X,Xie Z Q,A novel virtual sample generation method based on Gaussian distribution,Knowledge-Based Systems,2011,24(6).pp.740-748.,支持向量机(Support Vector Machines,SVMs)⑤Cortes C,Vapnik V.Support vector networks,Machine Learning,1995,20(8).pp.273-297.和决策树(Decision Tree,DT)⑥Quinlan J R,C4.5:Programs for Machine Learning,San Mateo,CA:Morgan Kaufmann,1993.等。这些算法的出现极大促进了模式分类技术在生活中各领域的应用。
训练样本数据的获取是模式分类工作的基础,所以模式分类任务很容易造成一些敏感数据的泄露。为了保护用来分类的训练数据,同时又尽可能不影响模式分类算法的性能,本文提出了一种基于Parzen窗核密度估计的模式分类隐私保护算法。该算法的主要思想是通过核密度估计方法估计原始数据的概率密度分布,然后根据这一密度函数生成一定数目的新样本,最后用这些新样本替换原始样本进行训练,实现原始数据的隐藏。因为本文算法针对的是大规模数据集,所以通过Parzen窗核密度估计算法可以较为准确地对原始数据集服从的密度函数进行估计,从而保障了分类器在替换数据集上的学习性能。
1 核密度估计介绍
核密度估计是在概率论中用来估计未知的密度函数,属于非参数检验方法之一,由国外学者Rosenblatt和Parzen提出。该方法又被叫做Parzen窗方法。核密度估计的主要思想是通过某范围内各点密度的均值对总体密度函数进行估计,该方法能够较好地描述多维数据的分布状态。
一个向量x落在区域R中的概率P为:

因此,可以通过统计概率P来估计概率密度函数p(x)。假设N个样本的集合X={x1,…,xN}是根据概率密度函数为p(x)的分布独立抽取得到的。那么,有k个样本落在区域R中的概率服从二项式定理:

假设p(x)是连续的,且R足够小使得p(x)在R内几乎没有变化。令R是包含样本点x的一个区域,其体积为V,设有N个训练样本,其中有k落在区域R中,则可对概率密度作出一个估计:

当样本数量N固定时,体积V的大小对估计的效果影响很大。过大则平滑过多,不够精确;过小则可能导致在此区域内无样本点,k=0。
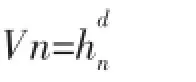
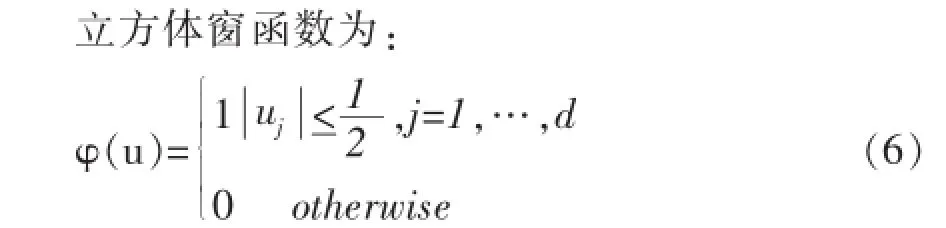

落入以X为中心的立方体区域的样本数为:Parzen窗估计过程是一个内插过程,样本xi距离x越近,对概率密度估计的贡献越大,越远贡献越小。
只要满足如下条件,就可以作为窗函数:

常见的窗函数如下:

2 算法设计
模式分类中的训练数据通常包括很多属性,其中有很多涉及到个人的隐私信息,如收入和信用级别等,所以原始数据的公开很容易造成个人隐私的泄露。如何在不泄露原始训练数据的情况下得到满意的分类决策标准,就成了亟需解决的问题,具有很高的研究价值。
本文提出一种基于Parzen窗核密度估计的模式分类隐私保护算法(A pattern Classification Privacy Preserve algorithm based on Parzen Window kernel density estimation,下文简称CPPPW算法)。该算法首先利用Parzen窗核密度估计算法对原始训练样本所服从的数据分布进行密度估计,然后根据该密度函数生成一定数目的替换样本。综合考虑在替换样本集上分类算法的分类性能和运行效率,本文算法设定生成la个替换样本,其中l为原始训练样本的个数,a是一个百分数且a∈[1,2]。即生成替换样本的个数不少于原始样本的个数,同时不多于原始样本数目的两倍。本实验根据10折交叉验证方式确定最合理的a值。最后用这些新样本替换原始样本进行分类学习。以二分类模式分类为例,本文算法的伪码实现如下:
基于核密度估计原始数据替换的数据分类隐私保护算法:
算法1:CPPPW算法
输入:原始样本集合

基分类器M,核函数φ(u)
输出:分类决策函数F
方法:

3.f=PWKDE(T,φ(u));//对训练集T利用parzen窗核密度估计方法估计密度函数f。
4.RS=Sample_Generation(f,la);//根据密度函数f生成la个替换训练样本,得到替换样本集RS,其中根据交叉验证方式确定最合理的a数值。
5.F=M(RS);//利用分类器M对替换样本集RS进行学习,获得分类决策函数F。
由于本算法针对的是大规模数据集,概率密度函数可以得到较为准确的估计,从而使得分类器在替换数据集的分类性能得到有效的保障。同时该算法利用替换样本集RS进行分类学习,有效地避免了原始样本数据信息的泄露。写为R)作为本实验分类的性能评价指标。具体计算公式如下:
3 实验
3.1 数据来源及处理
本实验选用UCI标准机器学习数据库中的Adult数据集进行实验。该数据集的目的是根据人们的统计数据来预测收入是否超过50K。该数据集共包含48842个样本,其中3620个样本包含缺失数据。数据集有14个属性,其中6个为连续属性,8个为标称属性。本实验首先对数据集进行预处理,将具有缺失属性的数据记录删除,然后从处理后的数据中选取了9000个元组进行实验,其中6000个元组作为训练样本,3000个元组作为测试样本。由于数据集包括age、work class、education、maritalstatus、occupation等明显涉及到个人隐私的属性,很容易在分类的同时造成个人隐私的泄露。
3.2 分类性能评价指标
为了更精确地对算法的性能进行评价,本实验并不采用传统的分类准确率作为评价指标,而是选择正确率(precision,简写为P)和召回率(recall,简

其中n1表示事实属于此类且被分类正确的样本数目,n2表示被判为此类的样本数,n3表示属于此类的总样本数。很明显可以看出,只有算法的正确率和召回率都较高时,算法的性能才更优越。
3.3 实验方法
本实验的实验平台为Intel Core2 Duo CPU T6500,2.10GHz,2.00GB RAM,Windows 7操作系统,选择matlab7.0软件进行实验。本实验分别在原始训练集合上和替换数据集合上进行分类学习,其中替换数据利用本文算法生成。生成的替换样本个数为la,具体的,生成n0a个第一类样本,n1a个第二类样本,l=n0+n1。当a=1时表示生成与原始样本数目一致的替换样本,当a=2时表示生成的替换样本数目是原始样本数目的两倍。本实验采用10折交叉验证方式确定最合理的a数值。
为了说明,本文提出的CPPPW算法是一种通用的模式分类隐私保护算法(即对各种不同的分类器均有效),本文采取当前最为经典的三种分类器作为实验的基分类器,即人工神经网络分类器、决策树分类器和支持向量机分类器。其中人工神经网络采用BP算法,并设定神经网络结构为3层。决策树使用C4.5决策树算法。支持向量机采用CSVM分类算法,并使用如下高斯核函数作为分类核函数:
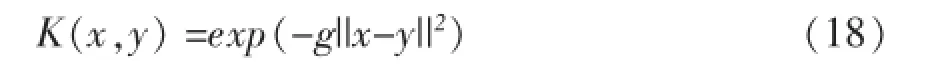
其中g与C(惩罚因子)为可调参数,本文同样通过10折交叉验证来求得最合适的g和C值。
3.4 实验结果与分析
由于本文算法使用新生成的样本替换原始样本进行学习,所以本文算法隐私保护的效果是显然的,下面图1到图6仅给出在替换数据集和原始数据集上,各种分类算法的分类性能。

图1 两种数据集上C4.5算法分类准确率对比
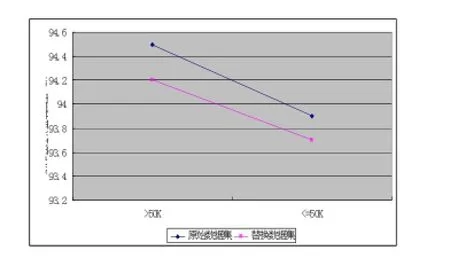
图2 两种数据集上C4.5算法分类召回率对比

图3 两种数据集上SVM算法分类准确率对比

图4 两种数据集上SVM算法分类召回率对比

图5 两种数据集上BP算法分类准确率对比
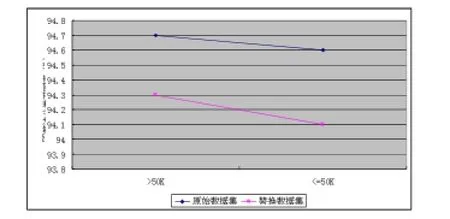
图6 两种数据集上BP算法分类召回率对比
从图1到图6可以看出,三种经典的分类算法在替换数据集上同样可以取得较好的分类性能。这主要是因为大规模数据集使得Parzen窗算法能够较好地对样本的分布函数进行估计,从而保障了替换数据集的质量。又考虑到本文算法使用替换数据集代替原始数据集,避免了用户隐私数据的泄露,所以本文算法是一种有效的面向隐私保护的数据分类算法。注意到图3和图4,分类器在替换数据集上取得了更好的分类性能,这可能是由于分类器在替换样本集上的分类学习一定程度上避免了过学习。本实验也充分说明本文算法是一种独立于分类器的模式分类隐私保护算法,可以与经典分类器结合,构建不同分类器算法下的隐私保护模型。
4 结论
针对大规模数据集,本文提出了一种基于Parzen窗核密度估计的模式分类隐私保护算法。充足的训练样本使得Parzen窗核密度估计算法可以较准确的估计密度函数,保障了替换数据集的质量。在替换数据集进行分类学习,有效的避免了原始数据上的隐私泄露。本文算法有效地前提是数据集包含大量的样本,研究在小样本数据集上有效的模式分类隐私保护算法将是进一步的研究内容。
The use of pattern classification for preserving privacy based on Parzen window kernel density estimation
ZHANG Youneng,WANG Debing,WANG Wei
In this paper,we proposed a pattern classification privacy preserve algorithm based on Parzen window kernel density estimation on large scale dataset.Firstly,the probability density followed by the original large scale training set is estimated.Then we can construct replacement training samples by the estimated probability.Finally,the replacement training samples are published for pattern classification training.Thus the privacy on the original training set can be protected effectively.The simulation experiments on Adult datasets fully verify the effectiveness of the proposed algorithm.
Parzen window;kernel density estimation;data publish;privacy preserving
TP309.2
A
1009-9530(2014)05-0093-04
2014-05-25
安徽省高校省级自然科学研究项目(KJ2013B037);安徽省高校省级自然科学研究项目(KJ2014A239)
张友能(1973-),男,安徽工贸职业技术学院电气与信息工程系副教授,硕士,主要研究方向为微机测控技术和物联网技术。
