一种动态特征选取方法及其在故障诊断中的应用
2014-06-07蔡斌斌金炜东
蔡斌斌,蒋 鹏,金炜东,秦 娜
(西南交通大学电气工程学院,成都610031)
一种动态特征选取方法及其在故障诊断中的应用
蔡斌斌,蒋 鹏,金炜东,秦 娜
(西南交通大学电气工程学院,成都610031)
针对高铁故障数据的特点,以高速列车走行部(主要指转向架)常见故障的实测数据为研究对象,提出一种动态特征选取方法。通过结合Fisher比率和模糊熵方法对其特征空间进行评估,有效去除冗余特征,利用加权平均方法选取优化的特征子集,从而实现故障分类。实验结果表明,与Fisher比率方法、模糊熵方法相比,该方法能提高不同列车速度下高铁故障的分类准确度及低速时的分类稳定性;与原特征空间方法相比,使用该方法提取最优特征空间后各列车速度下的分类准确率平均提高了5.2%。
特征选取;模糊熵;Fisher比率;故障分类;相似性分类器;鲁棒性
1 概述
特征评估和特征选取是模式识别中一个重要的研究内容,在模式识别中往往会提取多个特征,但是在众多的特征中哪些特征起到的作用大、哪些是无用的特征是研究的重点和难点,同时也引起了国内外研究者的关注。目前有多种特征选取方法。特征选择是从原始特征集中选取特征子集的过程,适当的特征选择可有效去除不相关和冗余特征,提升算法学习效率[1-3]。特征选择方法可以分为:嵌入,过滤和包裹等方法。国内外许多学者提出多种特征评价准则,取得了明显效果。然而,单一的特征评价准则往往只从不同侧面评价特征,无法全面评价特征子集的好坏,从而造成特征选择的普适性较差、分类精度较低。目前,针对特征评估指标的研究已经较成熟。但是单从一个指标难以全面评估特征的优劣,因此多准则、多尺度特征评估方法是目前研究的主要内容。例如,文献[4]提出多准则特征评估方法融合MCF-RFE算法不仅能有效提高分类精度而且具有较好的稳定性,优于基准算法SVM-RFE。文献[5]提出轮询式多准则思想,从根本上突破了目前各评价准则的局限性,能较快地进行特征选择。文献[6]提出MCFR多准则特征排序方案,该方案能够智能地利用各准则得到鲁棒性较好的特征排序。由此可见,多准则特征评估方法优于单一特征评估方法。但是将多个特征评估方法融合起来,是目前研究的重点和难点问题。如何针对特定数据选取合适的特征评估指标以及如何将不同的评估指标融合起来是目前尚未解决的问题。
由于高速铁路走行部(主要指转向架)故障检测往往采用多路振动或者位移传感器同时采集振动数据,并将时域数据变换到频域以增加检测稳定性。另外,多路传感器采集的数据常常伴有较强的噪声,而且数据的不一致性也较强。Fisher比率方法计算简单、稳定性高,非常适合处理高维特征数据。针对高铁故障数据的特点,本文以高速列车走行部常见故障的实测数据为研究对象,提出一种基于Fisher比率和模糊熵的动态特征选取方法,先采用Fisher比率和模糊熵方法分别对特征进行排序,并利用一种加权平均方法选取优化的特征集合。
2 方法理论与特征评价
2.1 模糊熵方法
熵是信息论中一个非常基本并且重要的概念,它度量了一个系统或一段信息的不确定性,描述了一个模糊集的模糊性程度。本文采用文献[7]中的基于相似性测度的模糊熵方法。
2.1.1 相似性测度
相似性测度一个基本的计算方法为:首先计算样本集x=(x(f1),x(f2),…,x(ft)),第i类样本集xi的幂均值得到一个能够较好地代表第i类理想的特征向量vi=(vi(fi),…,vi(ft)),然后计算待分类样本x与理想特征向量 v之间的相似度值 S(x,v),最后根据S(x,v)的大小判断x属于哪一类。在理想情况下,如果x属于第i类则得到S(x,v)=1,反之S(x,v)=0。
2.1.2 基于相似性测度的模糊熵方法
模糊熵的定义很多,考虑到模糊集合的概念在克劳德·艾尔伍德·香农(Shannon C E)概率熵的基础上提出模糊熵的公式:

其中,μA(xj)(0≤μA(xj)≤1)表示模糊数。引入相似性测度,令μA(xj)等于xj与理想特征向量中第j个特征vj之间的相似度S(xj,vj),如果相似度值越接近1/2,模糊熵值越大;相反,如果相似度值越大(或越小),模糊熵值越小。将每一个特征所有样本的模糊熵值相加得到每一个特征的模糊熵值。模糊熵值越大说明该特征包含的信息量越少,可以适当去除。
2.2 Fisher比率方法
Fisher比率方法用于估计某一特征的有效性,作为一个品质因数在声音识别领域和特征选择方面得到广泛应用。Fisher比率定义为类间均值的方差与类内平均方差的比值,该方法选出的特征类间差距大,类内差距小[8-11]。Fisher比率计算方法如下[8]:
设共有K类,第j类中特征向量个数为Nj,则第i个特征的Fisher比率值定义为:

其中,Bi为类间方差;Wi为第i个特征总的类内方差。两者在数学上的定义如下:

其中,μij和Wij分别为第j类中第i个特征的均值和方差;μi是第i个特征总的均值。具体计算方法如下:

其中,xijn是第j类、第n个特征向量中的第i个特征。
2.3 特征评价
由式(1)~式(7)可分别求得基于模糊熵、Fisher比率准则的特征排序,取一定的权值得到两方法结合后的特征排序。
基于模糊熵和Fisher比率方法分别对原始特征空间每个通道的各个特征进行评价。由于特征的模糊熵权值越小该特征对分类的作用越大,而特征的Fisher比率权值越大该特征对分类的作用越大,为了使两者对应将特征的模糊熵值按从小到大顺序排序、Fisher比率值从大到小排序,最后得到排序后每个特征对应的序号,分别记为:

基于2种不同的准则得到αen和αFr2种不同的排序,将2种排序线性求和,得到基于2种不同准则的特征的综合排序序号,记为:

其中,x(i)=axen(i)+bxFr(i),本文取a∶b=1∶1。对α按从小到大顺序排列得到特征排序,根据特征排序选择最优特征空间。
3 实验结果与分析
为验证本文方法的有效性和优越性,对标准测试数据集和高速列车的实测故障数据分别进行实验。
3.1 标准数据集实验
3.1.1 实验设计
基于本文方法首先对标准数据集Ionosphere,Pima Indians Diabetes进行仿真验证。数据集Ionosphere, Pima Indians Diabetes可在UCI数据库中获得。表1是对标准数据集Ionosphere,Pima Indians Diabetes的简单描述。
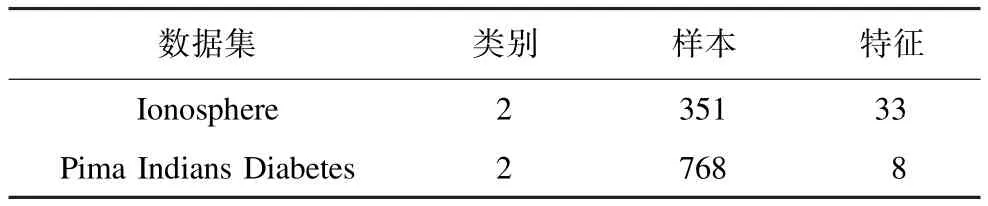
表1 标准数据集
在实验中,采用相似性分类器进行分类,具体如下:首先得到能够较好地代表各类的理想特征向量,然后将待分类样本及理想特征向量归一化,计算待分类样本与每一类理想特征向量的相似度,根据相似度大小判断该样本属于哪一类。在理想情况下,如果待分类样本属于某一类,那么它与该类理想特征向量的相似度值为1,否则为0。因此,待分类样本与哪一类理想向量的相似度值最大,那么该样本就属于哪一类。
3.1.2 结果分析
图1表示数据集Ionosphere基于3种方法在每次去掉一个冗余特征的过程中得到的各特征空间的分类准确率,表2、表3分别表示两数据集基于3种方法得到的最优特征空间及分类准确率。

图1 Ionosphere数据集中不同特征空间的分类准确率

表2 Ionosphere数据集的分类准确率

表3 PimaIndians Diadetes数据集的分类准确率
首先从总体上看,与Fisher比率、模糊熵方法相比,在对两数据集选取最优特征空间的过程中,本文方法能更稳定、高效地选取最优特征,并得到较好的分类准确率。由图1和表2可知,模糊熵方法选取21个特征时得到的最高分类准确率81.196 6%,低于原特征空间分类准确率84.900 3%。Fisher比率方法选取 9个特征时,最高分类准确率达到86.039 9%,本文方法只需选择4个特征,最高分类准确率达到84.900 3%。同样选取前4个特征,模糊熵方法的分类准确率只有74.928 8%,Fisher比率方法为80.057 0%。本文方法在保持和Fisher比率方法准确率相近的情况下,有效地选取了最优特征空间,使计算量大大降低。由表3可知,与原特征空间相比3种方法都能去除冗余特征、提高分类准确率。原特征空间分类准确率为73.3073%,而本文方法只需选取 4个特征得到最高分类准确率74.218 8%,模糊熵方法选取7个特征时得到最高分类准确率74.088 5%,Fisher比率方法选取6个特征时得到最高分类准确率74.218 8%,而同样取4个特征,模糊熵方法准确率只有71.614 6%,Fisher比率方法分类准确率只有62.369 8%。表2和表3中各空间的平均分类准确率也表明了本文方法的鲁棒性和优异性。
3.2 高铁实测数据实验
3.2.1 实验设计
为验证本文方法在高铁故障实测数据中的有效性,对某型高速列车实测数据进行仿真验证。分别提取高速列车4种工况实测数据小波系数的均值、方差及快速傅里叶变换的均值、方差8维特征,每种工况得到20组样本,4种工况总共80组样本。首先运用3种方法对所有样本的特征进行评估,去除冗余特征,然后从4种工况中分别选出一组作为训练数据,剩余76组作为测试数据,将每组测试数据分别与4个训练数据进行比较,由于单个传感器得到的信息不完整、错误率高,DS[12-13]数据融合算法能够将不完整的信息加以综合,形成相对完整、一致的感知描述,从而实现更加准确的识别和判断功能。因此,本文选取通道11,13,14,15,20,22,采用相似性分类器与DS数据融合的分类方法,首先计算待分类样本与各类理想特征向量的相似度得到相似度向量,相似度向量归一化作为分类证据,根据DS合成规则将6个通道得到的证据融合得到一个综合的证据,设定阈值p=0.5,当样本属于某种工况的概率大于p,则认为该样本属于该工况。
3.2.2 结果分析
表4~表7分别表示原特征空间及运用模糊熵、Fisher比率、模糊熵与Fisher比率结合(本文方法) 3种方法提取最优特征空间后各速度下的分类准确率。表8为不同特征空间下5种速度的平均分类准确率。图2表示各速度下基于3种方法提取的最优特征空间分类准确率对比。

表4 基于原特征空间的分类准确率

表5 基于模糊熵方法的分类准确率
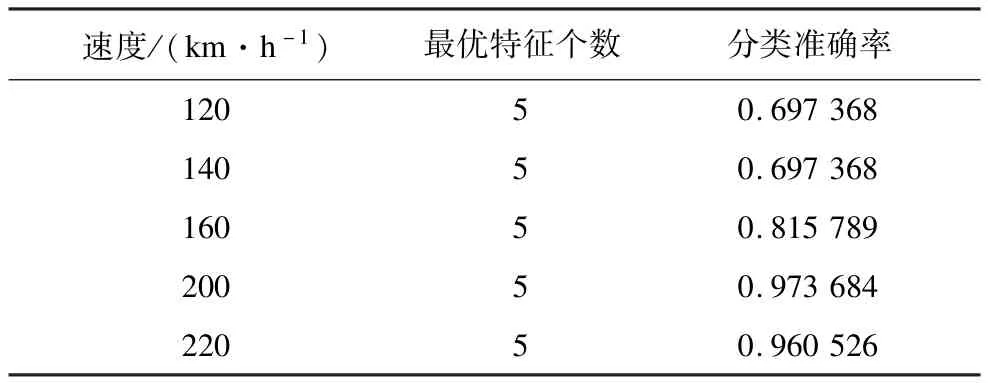
表6 基于Fisher比率方法的分类准确率

表7 基于本文方法的分类准确率

表8 不同特征空间下的平均分类准确率

图2 3种方法的分类准确率对比
由表4、表5可得,应用模糊熵提取各速度下的最优特征均为前7个特征。与原特征空间分类准确率相比,速度为120 km/h,160 km/h分类准确率不变,速度为140 km/h时有显著提高,准确率提高22%左右,速度为220 km/h准确率虽有提高但并不明显仅有1%左右,速度为200 km/h时准确率下降2%。由此可得,模糊熵方法只对速度为140 km/h的分类准确率有提高,而其他速度下的准确率不变甚至下降,说明模糊熵方法对于特征评价不稳定。
由表4、表6可得,Fisher比率方法提取各速度下的最优特征空间均为前5个特征。各个速度下的准确率均有提高,较为明显的是140 km/h时提高6%,160 km/h,220 km/h时准确率提高4%左右,平均精度提高3.4%。表明Fisher比率方法不仅能够有效地降低特征维数而且能够提高分类精度。
由于表7为Fisher比率与模糊熵结合的方法提取各速度下的最优特征个数及分类准确率。由表4、表7可得,Fisher比率与模糊熵结合的方法有效地简化了特征空间,除了120 km/h识别率提高1%,其他速度下均有明显提高。140 km/h时识别率提高最明显,高达12%;160 km/h,200 km/h时提高4%左右,200 km/h识别率达到100%;220 km/h时准确率提高5%。
由表5~表7及图2可得,速度为200 km/h, 220 km/h方法的识别率在Fisher比率及模糊熵方法的基础上又有提高;速度为140 km/h时保持了两方法中识别率较高者;120 km/h,140 km/h时识别率在两方法的基础上折中。可见,本文方法具有较好的鲁棒性,能够有效地提高分类准确度,平均分类准确率提高5.2%。
4 结束语
本文针对高铁故障数据的特点,提出模糊熵和Fisher比率相结合的方法对其特征空间进行评估,并以高速列车的故障数据作为研究对象进行验证。实验结果证明,该方法能够提高高铁多种故障分类的准确度,针对标准测试数据集的实验也证明了该方法的鲁棒性和优异性。
[1] Liu Huan,Yu Lei.Toward Integrating Feature Selection Algorithms for Classification and Clustering[J].IEEE Transactions on Knowledge and Data Engineering,2005, 17(3):491-502.
[2] Guyon I,Elissee A.An Introduction to Variable and FeatureSelection[J].JournalofMachine Learning Research,2003,3(3):1157-1182.
[3] 杨 艺,韩德强,韩崇昭.基于排序融合的特征选择[J].控制与决策,2011,26(3):397-401.
[4] Feng Yang,Mao K Z.RobustFeatureSelection for Microarray Data Based on Multicriterion Fusion[J].ACM Transactions on Computational Biology and Bioinformatics,2011,8(4):1080-1092.
[5] 李勇明,张素娟,曾孝平,等.轮询式多准则特征选择算法的研究[J].系统仿真学报,2009,21(7):2010-2017.
[6] Yan Weizhong.Fusion in Multi-criterion Feature Ranking[C]//Proceedings of the 10th International Conference on Information Fusion.Quebec,Canada:[s.n.],2007:1-6.
[7] Luukka P.Feature Selection Using Fuzzy Entropy Measures with Similarity Classifier[J].ExpertSystemswith Application,2011,38(4):4600-4607.
[8] Zabidi A,MansorW.TheEffectofF-ratio in the Classification of Asphyxiated Infant Cries Using Multilayer Perception Neural Network[C]//Proceedings of EMBS Conference on Biomedical Engineering & Science.Kuala Lumpur,Malaysia:IEEE Press,2010:126-129.
[9] Saha G,Senapati S,Chakroborty S.An F-ratio Based Optimization on Noisy Data for Speaker Recognition Application[C]//Proceedings of INDICON'05.[S.l.]: IEEE Press,2005:352-355.
[10] Abdulla W H,Kasbov N.Reduced Feature-setBased ParallelCHMM Speech Recognition Systems[J].Information Sciences,2003,156(1/2):21-38.
[11] Liu Donghui,Liang Youngchun,Li Aihua,et al.The Study of Improved Fisher Ratio for Default Diagnosis of Power Transformer[C]//Proceedings of the 7th World Congress on Intelligent Control and Automation.Chongqing,China:[s.n.],2008:6867-6870.
[12] 徐从富,耿卫东,潘云鹤.面向数据融合的DS方法综述[J].电子学报,2001,29(3):393-396.
[13] 权 文,王晓丹,王 坚,等.一种基于局部冲突分配的DST组合规则[J].电子学报,2012,40(9):1180-1184.
编辑 陆燕菲
A Dynamic Feature Selection Approach and Its Application in Fault Diagnosis
CAI Binbin,JIANG Peng,JIN Weidong,QIN Na
(School of Electrical Engineering,Southwest Jiaotong University,Chengdu 610031,China)
According to the characteristic of fault data of high-speed train,a dynamic feature selecting algorithm is proposed to research the measured data of the running gear(referring mainly to bogie)of high-speed train.The approach combines the advantages of Fisher ratio and fuzzy entropy dynamically,which manages to evaluate features more accurately and removes the redundant features effectively to obtain superior feature subset by weighted average method.The new approach can improve classification accuracy.Experimental results for fault data of high-speed train show that the proposed approach not only improves the classification accuracies significantly,but also strengthens the stability in low speed.The overall-precise improvement is 5.2%after extracting the optimal feature space in average compared with that of the original feature space.
feature selection;fuzzy entropy;Fisher ratio;fault classification;similarity classifier;robustness
1000-3428(2014)11-0139-04
A
TP391
10.3969/j.issn.1000-3428.2014.11.028
国家自然科学基金资助重点项目(61134002)。
蔡斌斌(1989-),女,硕士研究生,主研方向:数据融合,信息处理;蒋 鹏,讲师、博士;金炜东,教授、博士;秦 娜,博士研究生。
2013-10-14
2013-12-25E-mail:caibinbin0320@126.com
中文引用格式:蔡斌斌,蒋 鹏,金炜东,等.一种动态特征选取方法及其在故障诊断中的应用[J].计算机工程, 2014,40(11):139-142.
英文引用格式:Cai Binbin,Jiang Peng,Jin Weidong,et al.A Dynamic Feature Selection Approach and Its Application in Fault Diagnosis[J].Computer Engineering,2014,40(11):139-142.
