指数平滑方法和VAR模型的预测效果的探讨
2014-03-26周智敏
周智敏
摘要:预测是计量经济学中重要的内容,关于一些重要的经济指标诸如:GDP,通胀,股价,汇率,失业率等我们如何预测呢?本文将通过对一个实例研究曾经相当流行的预测方法:指数平滑法及目前仍旧流行的VAR方法的预测效果。总地来说,基于时间序列数据进行经济预测的方法有五种:单方程回归模型;联立方程回归模型;ARIMA模型;VAR模型及指数平滑法,当然这些预测方法均基于所用的时间序列平稳这一前提(至少通过适当变换可使之平稳)。
关键词:计量经济学;预测;时间序列
本文将简介双指数平滑方法Holt-winter方法及VAR模型,并且将重点以一个数值例子:加拿大的货币供给量,来直对比观展示双指数平滑方法,holt-winter和VAR模型的预测效果。
指数平滑法:
指数平滑法(Exponential Smoothing,ES)是一项既可以用于对时间序列数据进行平滑处理,又可以用于对其预测的技术手段。时间序列数据本身就是一系列的观察数值。被观测到的现象既可以是随机过程也可以是有序的噪音过程。在移动平均平滑法中,过去的观测值被赋予相同的权重,而指数平滑法则依时间远近对其赋予逐渐递增的权重。指数平滑法常用于金融市场和经济数据,但它也可以用于任何离散重复的测量当中。最简单的指数平滑方法只能被用于没有任何系统性趋势或者季节因素的数据。
单指数平滑法。平滑值公式:
y(1)t=αyt+(1-α)yt-1(1)
其中α为平滑系数且α∈[0-1]
预测值公式:
y∧t+1=αyt+(1-α)y∧t
实践中α可取多个值,分别计算其预测误差,然后再选择误差相对而言最小的那个,在eviews实践操作中,软件会自动给定一个合适值。另外可以使用第一期的观察值作为初始值,或用前2-3期观测值的品均值亦或由软件本身生成。
双指数平滑法则基于单指数平滑法,其预测公式为:
y∧t-T=at+btT
参数估计公式为:
a1=2y(1)t-y(2)t
bt=α1-α(y(1)t-y(2)t)
Holter-Winter-无季节趋势(双参数)
此法适用于具有线性时间趋势却没有因季节趋势导致的变差的情形。它和双指数平滑法均以线性趋势无季节成分进行预测。不同的是,双指数平滑法只用单个参数,而HW方法则用到双参数。平滑后的序列由下式给出:
y∧t+k=at+btk
参数估计式:
at=αyt+(1-α)(at-1-bt-1)
bt=β(at-at-1)+(1-β)bt-1
其中初始值公式:
a0=y1b0=(y2-y1)+(y4-y3)2
它的系数的确定过程与平滑系数方法基本相同
向量自回归(VAR)模型:
向量自回归模型(vector autoregressive model)是一种计量经济学模型,它被用于获取多个时间序列间的线性相关性。VAR模型通过包含多个变量将单变量回归方程一般化。在一个VAR模型中,所有的变量被对称地进行结构性处理。尽管估计系数通常不同。每个变量都有一个方程解释之,解释变量为它自己的滞后项和其各他变量的滞后项。VAR的建模不像结构方程一样,它不依赖于其他具有影响因素的变量。VAR模型唯一重要的信息就是一系列的变量,它们被假设成相互之间具有内部影响。
VAR模型的形式为(N个变量,滞后k期的)
Yt=μ+Π1Yt-1+Π2Yt-2+…+ΠkYt-k+ut,ut~IID(0,Ω)
其中:
Yt=(y1,ty2,t…yN,t)′
μ=(μ1μ2…μN)′
Πj=π11,jπ12,j…π1N,j
π21,jπ22,j…π2N,j
πN1,jπN2,j…πNN,j,j=1,2,…,k
ut=(u1tu2,t…uNt)′
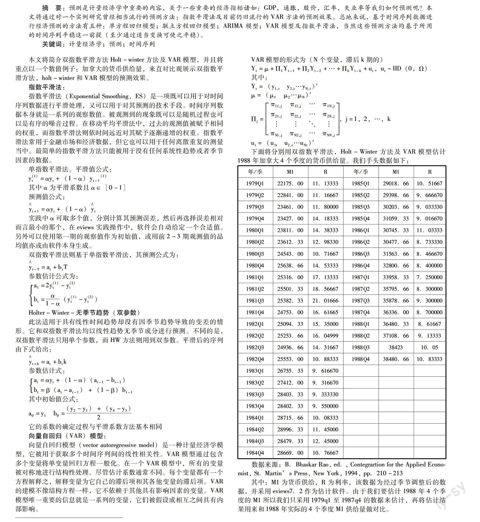
下面将分别用双指数平滑法,Holt-Winter 方法及VAR模型估计1988年加拿大4个季度的货币供给量。我们手头数据如下:
年/季M1R年/季M1R
1979Q122175.0011.133331985Q129018.6610.51667
1979Q222841.0011.166671985Q229398.669.666670
1979Q323461.0011.800001985Q330203.669.033330
1979Q423427.0014.183331985Q431059.339.016670
1980Q123811.0014.383331986Q130745.3311.03333
1980Q223612.3312.983301986Q230477.668.733330
1980Q324543.0010.716671986Q331563.668.466670
1980Q425638.6614.533331986Q432800.668.400000
1981Q125316.0017.133331987Q133958.337.250000
1981Q225501.3318.566671987Q235795.668.300000
1981Q325382.3321.016661987Q335878.669.300000
1981Q424753.0016.616651987Q436336.008.700000
1982Q125094.3315.350001988Q136480.338.61667
1982Q225253.6616.049991988Q237108.669.13333
1982Q324936.6614.316671988Q33842310.05
1982Q425553.0010.883331988Q438480.6610.83333
1983Q126755.339.616670
1983Q227412.009.316670
1983Q328403.339.333330
1983Q428402.339.550000
1984Q128715.6610.08333
1984Q228996.3311.45000
1984Q328479.3312.45000
1984Q428669.0010.76667
数据来源:B.Bhaskar Rao, ed. , Contegrartion for the Applied Economist, St. Martins Press, New York, 1994, pp.210-213
其中:M1为货币供给,R为利率,该数据为经过季节调整后的数据,并采用eviews7.2作为估计软件。由于我们要估计1988年4个季度的M1所以我们只采用1979q1至1987q4的数据来估计,再将估计结果用来和1988年实际的4个季度M1供给量做对比。
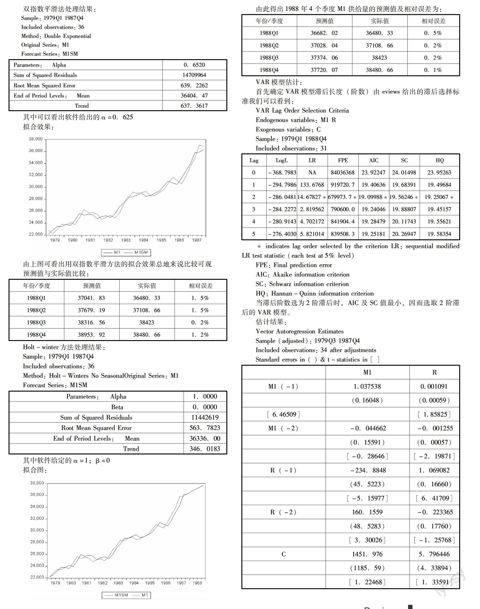
双指数平滑法处理结果:
Sample: 1979Q1 1987Q4
Included observations: 36
Method: Double Exponential
Original Series: M1
Forecast Series: M1SM
Parameters:Alpha0.6520
Sum of Squared Residuals14709964
Root Mean Squared Error639.2262
End of Period Levels:Mean36404.47
Trend637.3617
其中可以看出软件给出的α=0.625
拟合效果:
由上图可看出用双指数平滑方法的拟合效果总地来说比较可观
预测值与实际值比较:
年份/季度预测值实际值相对误差
1988Q137041.8336480.331.5%
1988Q237679.1937108.661.5%
1988Q338316.56384230.2%
1988Q438953.9238480.661.2%
Holt-winter方法处理结果:
Sample: 1979Q1 1987Q4
Included observations: 36
Method: Holt-Winters No SeasonalOriginal Series: M1
Forecast Series: M1SM
Parameters:Alpha1.0000
Beta0.0000
Sum of Squared Residuals11442619
Root Mean Squared Error563.7823
End of Period Levels:Mean36336.00
Trend346.0183
其中软件给定的α=1;β=0
拟合图:
由此得出1988年4个季度M1供给量的预测值及相对误差为:
年份/季度预测值实际值相对误差
1988Q136682.0236480.330.5%
1988Q237028.0437108.660.2%
1988Q337374.06384230.2%
1988Q437720.0738480.660.1%
VAR模型估计:
首先确定VAR模型滞后长度(阶数)由eviews给出的滞后选择标准我们可以看到:
VAR Lag Order Selection Criteria
Endogenous variables: M1 R
Exogenous variables: C
Sample: 1979Q1 1988Q4
Included observations: 31
LagLogLLRFPEAICSCHQ
0-3687983NA 84036368 2392247 2401498 2395263
1-2947986 1336768 9197207 1940636 1968391 1949684
2-2860481 1467827* 6799737* 1909988* 1956246* 1925067*
3-2842272 2819562 7906000 1924046 1988807 1945157
4-2809143 4702172 8419044 1928479 2011743 1955621
5-2764030 5821014 8395083 1925181 2026947 1958354
* indicates lag order selected by the criterion LR: sequential modified LR test statistic (each test at 5% level)
FPE: Final prediction error
AIC: Akaike information criterion
SC: Schwarz information criterion
HQ: Hannan-Quinn information criterion
当滞后阶数选为2阶滞后时,AIC及SC值最小,因而选取2阶滞后的VAR模型。
估计结果:
Vector Autoregression Estimates
Sample (adjusted): 1979Q3 1987Q4
Included observations: 34 after adjustments
Standard errors in ( ) & t-statistics in [ ]
M1R
M1(-1)10375380001091
(016048)(000059)
[ 646509][ 185825]
M1(-2)-0.044662-0.001255
(0.15591)(0.00057)
[-0.28646][-2.19871]
R(-1)-234.88481.069082
(45.5223)(0.16660)
[-5.15977][ 6.41709]
R(-2)160.1559-0.223365
(48.5283)(0.17760)
[ 3.30026][-1.25768]
C1451.9765.796446
(1185.59)(4.33894)
[ 1.22468][ 1.33591]
R-squared0.9881980.806661
Adj. R-squared0.9865710.779993
Sum sq. resids5373508.71.97045
S.E. equation430.45721.575354
F-statistic607.072330.24882
Log likelihood-251.7446-60.99213
Akaike AIC15.102633.881890
Schwarz SC15.327094.106355
Mean dependent28216.2611.75049
S.D. dependent3714.5073.358613
Determinant resid covariance (dof adj.)458484.8
Determinant resid covariance333551.7
Log likelihood-312.6862
Akaike information criterion18.98154
Schwarz criterion19.43047
由回归结果可看出R方及调整的R方均超过0.98因而,用来做预测效果会比较理想;F值显著;在我们所关注的方程:
M1 = C(1,1)*M1(-1) + C(1,2)*M1(-2) + C(1,3)*R(-1) + C(1,4)*R(-2) + C(1,5)
中除了M1(-2)前的系数t值告诉我们它不显著之外,其余系数均在5%的显著条件下显著。该VAR模型的具体形式为:
VAR Model - Substituted Coefficients:
===============================
M1 = 1.03753826655*M1(-1) - 0.0446620254822*M1(-2) - 234.884823236*R(-1) + 160.155900514*R(-2) + 1451.97612976
R = 0.00109139520558*M1(-1) - 0.0012545367784*M1(-2) + 1.06908165291*R(-1) - 0.22336505476*R(-2) + 5.79644632286
由此得出1988年4个季度M1供给量的预测值及相对误差为:
年份/季度预测值实际值相对误差
1988Q13699636480.331.4%
1988Q237584.337108.661.2%
1988Q338030.3384231%
1988Q438334.238480.660.3%
结论
由上的估计结果及分析我们可看出,在该例中Holter-Winter模型的预测效果明显较好,其相对预测误差均在0.5%的范围之内。而VAR及双指数平滑方法的预测效果不相仲伯,但它们的相对预测误差也均不超过1.5%.(作者单位:中南财经政法大学)
参考文献:
[1]Frank, C. R. Jr. , Statistics and Economics, Holt, Rinehart and Winston, New York, 1971
[2]Dhrymes, Phoebus J. , Introductory Economics, Spring-Verlag, New York, 1978
[3]Kmenta, Jan, Elements of Econometrics, 2d ed. , Macmillan, New York, 1986
[4]Rao, Potluri, and Roger LeRoy Miller, Applied Econometrics, Wadsworth, Belmont, CA. , 1971
[5]Cramer, J.S. , Empirical Econometrics, North-Holland, Amsterdam, 1969
