TD-LTE系统中咬尾卷积码的DSP实现及性能测试*
2014-03-21陈发堂孙鹏代修文周凌云
陈发堂,孙鹏,代修文,周凌云
(1.重庆邮电大学移动通信协议重庆市重点实验室,重庆400065;2.重庆邮电大学通信与信息工程学院,重庆400065)
移动通信与宽带无线接入技术的融合成为通信发展的必然趋势。为此,3GPP启动了通用移动通信技术的长期演进项目。为了将系统带宽从5 M提高到20 M,LTE在下行传输中采用了正交频分多址、上行采用单载波频分多址的技术[1]。OFDM技术实质就是将串行的数据映射到并行的信道进行传输,符号的延续时间由此得以延长,从而对时延扩展有更高的包容性。为了满足LTE系统对更大的系统容量的需求,低成本支持更多的天线系统要求,在信道编码中采用了咬尾卷积编码和Turbo编码[2]。本文详细阐述了咬尾卷积编码的编码原理,通过Matlab仿真对咬尾卷积编码在不同信道环境下的性能进行了探究,重点阐述了一种咬尾卷积编码的DSP实现方法,最后,选取一种可靠的译码方式在接收端完成咬尾卷积译码。
1 咬尾卷积编码的实现原理
该信道编码的编码和译码复杂度低、处理时延小,适合小码块控制信息和对时延敏感的数据传输。
咬尾卷积是建立在卷积码编码器的起始状态,不需要全0状态,可以是任何其他状态。在LTE系统中,将咬尾卷积编码的约束长度设置为7,即配置了6个移位寄存器,采用速率为1/3进行编码。咬尾卷积编码的初始比特可以不为零,但起始状态和终止状态相同。因此不需要传输额外的比特,具有较高的编码效率。编码器的初始状态和最终状态由数据包的最后几个比特决定[3],也就是把一个数据包的最后6 bit用来初始化寄存器状态。其编码原理和实现框图如图1所示,对于输入数据流CK,编码后按3路输出,输出分别为得到的5路数据进行异或,产生最后的结果。
2 咬尾卷积编码性能测试
利用QPSK高斯信道、ETU、EVA、EPA四种信道对咬尾卷积编码的性能进行分析。仿真过程中,选取PBCH的MIB信息进行仿真测试,天线配置为4发4收,带宽为5 MB,载波频率为2 GHz,得到的仿真结果如图2所示。
通过图2不难看出,误码率为10-4时,咬尾卷积编码的编码增益在7 dB左右,这一结果完全可以应用在综合仪表开发中。
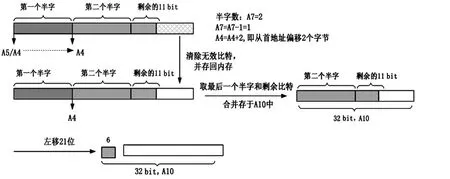
图3 寄存器初始化实现图
3 咬尾卷积编码的设计与实现
3.1 DSP处理器
采用了TI公司的C64x系列,该系列采用了取指令和执行指令可以并行运行的哈佛结构,程序总线和数据总线也是独立运行的。其中程序总线有256 bit,内存单次操作取8条指令,实现了高速运行的目的。基于C64芯片的高容量、运行速度快的特征,在综合测试仪表的开发中采用了该芯片[1]。

图1 咬尾卷积码的编码原理实现框图
3.2 编码与内存区设计
以TD-LTE为例,1个子帧有2个时隙,频域上的最大资源块数为110,1个资源块的大小为180 kHz,1个时隙有6个或者7个OFDM符号[1],因此对寄存器和内存的设计如表1所示,内存设计如下。


表1 寄存器内存设计
3.3 详细设计
咬尾卷积的DSP实现主要包括三个步骤:取数据包的最后6 bit进行寄存器初始化;根据移位寄存器的要求进行移位异或操作,完成编码;再对完成编码的数据进行比特字节化,为咬尾卷积编码的速率匹配做准备。
3.3.1 寄存器初始化完成
在进行寄存器初始化的实现中,要考虑有无剩余比特两种情况,计算出需要偏移地址的数A7。若有剩余比特,则取最后一个半字与剩余比特,把它们合并存放在一起,然后进行左移得到最后的6 bit,存于A10的高6位。左移的位数便是“剩余比特数+10”;若没有剩余比特,就取最后两个半字,通过左移26位得到后6 bit,存于A10的高6位。以数据流长度=43为例,具体实现如图3所示。
3.3.2 咬尾卷积编码实现
取每一轮参与编码的那一个半字,存于A7的低16位,左移10位,空出A7左端的6位与尾比特(6 bit)进行或操作,完成22 bit的拼接,存储于A10把数据流的最后6 bit与第一个半字构成22 bit,形成第一轮参与编码的数据。每一轮参与编码的22 bit,是上一轮的最后6 bit与这一轮的那一个半字。具体的实现如图4所示。
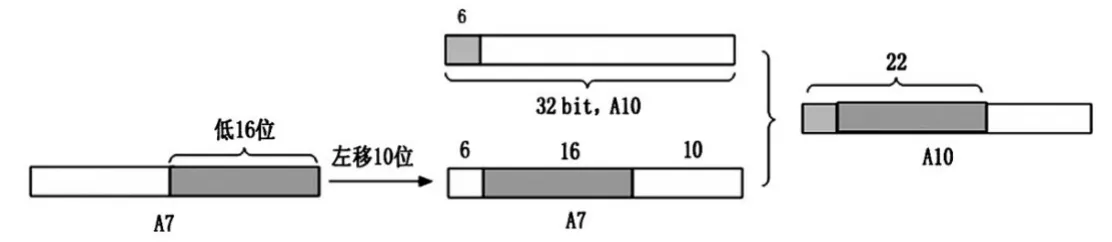
图4 咬尾卷积码编码实现图
3.3.3 比特字节化的实现
比特字节化,来为交织操作中的取数据做准备,取数据时地址的偏移是以字节为偏移单位进行的。环进行字节化,直至16 bit字节化完成,后6 bit不参与,将参与编码的比特数存于B0,每完成一次编码,对应的记录的寄存器减一。当还没进行到最后一部分时,就这样以22 bit为单位进行编码、字节化,第一轮时是数据流的最后6 bit与第一个半字结合的22 bit,第二轮是第一轮22 bit的后6 bit与第二个半字形成的22 bit。
在比特字节化时,最后的那一轮只字节化剩余比特数次,比如最后一轮的22 bit,以数据长度为31为例,字节化时只进行11次的字节化。具体流程如图5所示。
编码后的数据存储如图6所示。
3.4 DSP运行性能分析
DSP软件中的实现代码要尽量精简,减少执行的“NOP”数目,合理控制循环次数,本文通过对半字数及字数为单位的控制进行地址偏移,使得运算量尽量减少,减少运算的周期数目。当编码数据为4 200时,运行的cycles数如表2所示。

表2 程序结果表
TMS320C64DSP芯片,处理器的频率达到1 GHz,运行一个cycle的时间是1 ns,测试平台上,通过对GPIO口的控制,测量函数运行时间,运行时间可以满足对实时性的要求。
4 咬尾卷积译码方式性能测试
Viterbi译码的算法主要有循环维特比译码算法(CVA)[4]、M比特重复循环维特比译码算法(N+M-CVA)、有界循环维特比译码算法(BDD-CVA)[5]、环绕维特比译码算法(WAVA)、最大似然维特比译码算法(ML-VA)[6],其中L+Win-CVA,算法是一种基于循环Viterbi译码算法的改进,L3-WAVA算法是将码块重复三次的WAVA算法[7],ML-VA[8]算法是一种牺牲算法复杂度换取遍历的算法,算法复杂度极大,本文不作考虑。设定码块大小为200 bit时,用Matlab仿真各种译码算法的误比特率。得到的结果如图7所示[1]。
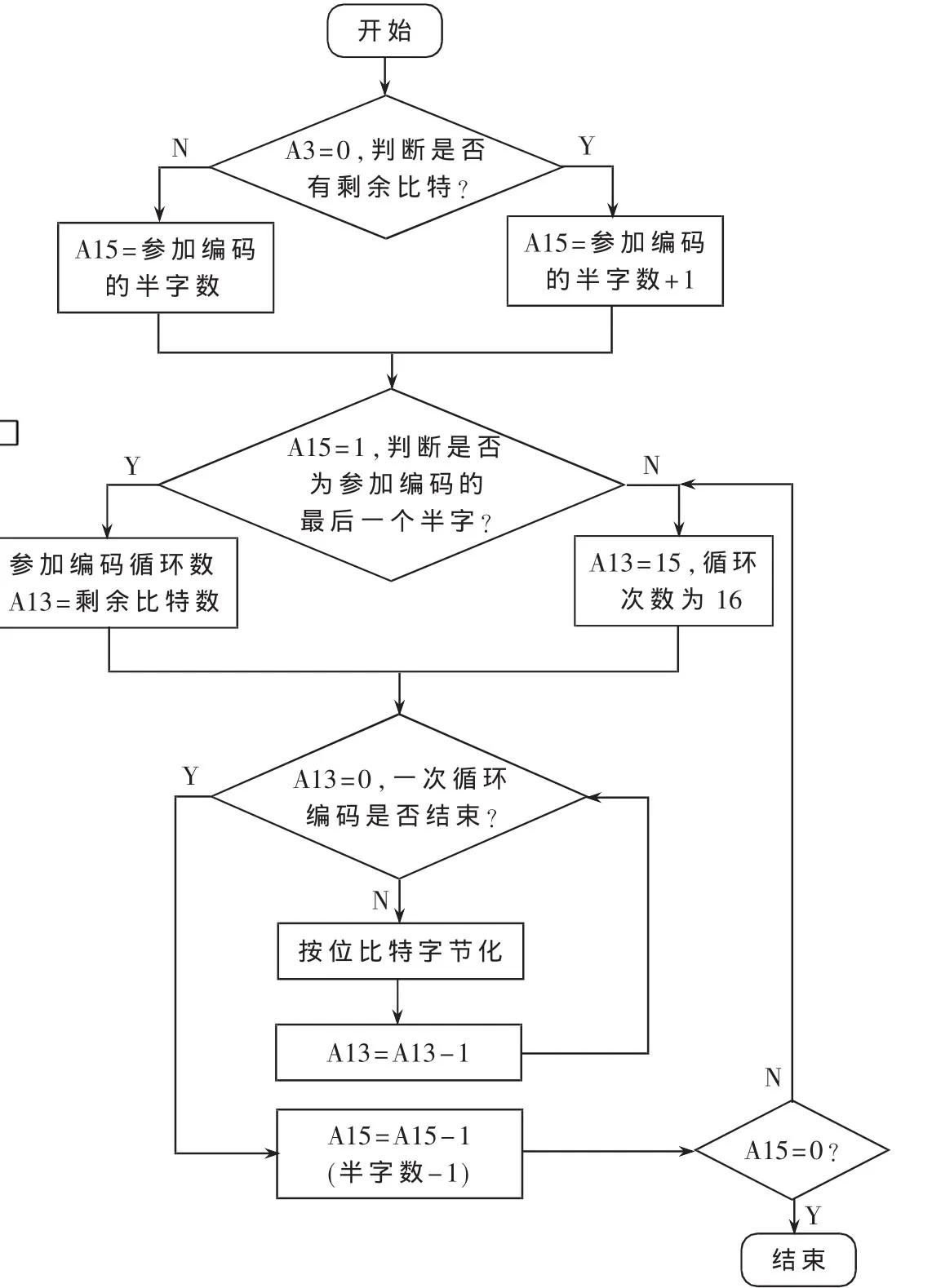
图5 比特字节化流程图

图6 编码数据存储图
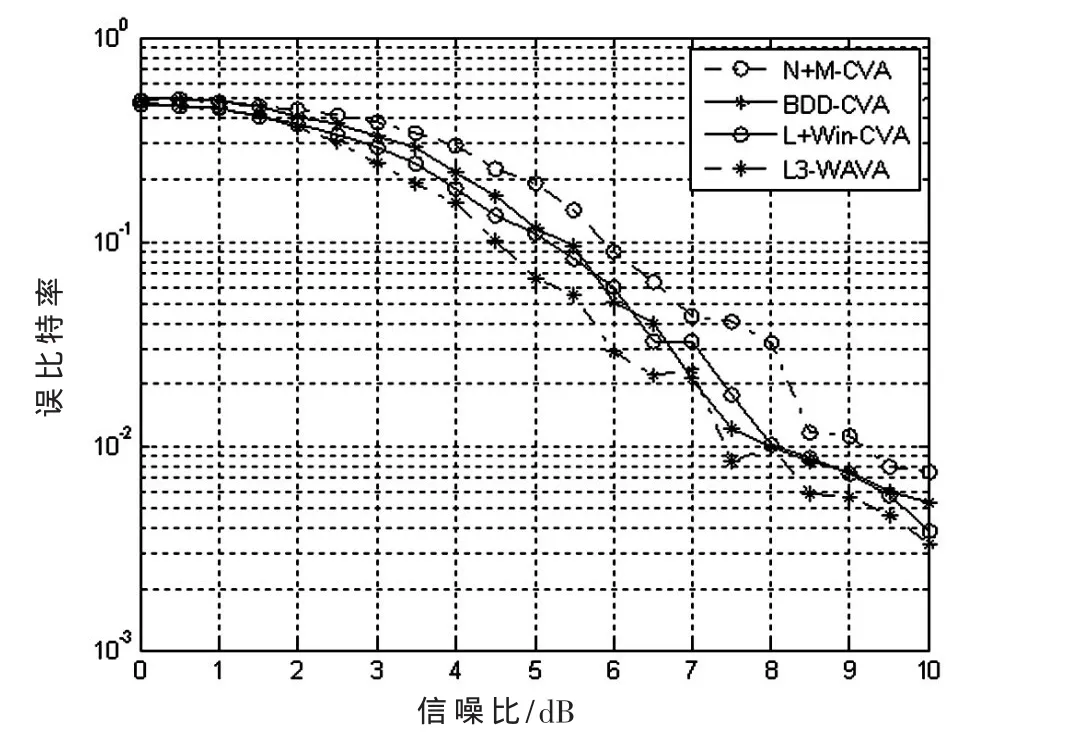
图7 译码性能仿真图
从仿真的结果不难看出,L3-WAVA算法性能最好,并且契合了“TD-LTE无线综合仪表测试开发”的性能和运算精度的要求,因此选取L3-WAVA算法作为咬尾卷积码的译码算法。
本文首先从LTE背景分析,阐述了LTE系统采用咬尾卷积编码的必要性。根据咬尾卷积编码技术的原理,模拟验证咬尾卷积编码在不同信道环境下的性能,提出一种DSP的实现方法,在TMS320C6000平台上实现并且对运行结果进行性能分析,选取L3-WAVA方法为咬尾卷积译码方式进行仿真。该方案已应用到LTE-TDD无线综合测试仪表的开发中。
[1]陈发堂,陶根林.LTE系统中咬尾卷积码的编译码算法仿真及性能分析[J].计算机应用研究,2010,27(9):
[2]王晓涛,钱骅,徐景,等.基于陷阱检测的咬尾卷积码译码算法[J].电子与信息学报,2011,33(10):2300-2305.
[3]林丹,李小文.TD-LTE系统中咬尾卷积码译码器的FPGA实现[J].电子测试,2010(3):57-61.
[4]MEHRABIAN M R,MOZAFARI S P,ZOLFAGHARI B.An approach to exploiting proper multiples of the generator polynomial in parallel CRC computation[C].2012 IEEE International Conference on Computer Science and Automation Engineering(CSAE 2012).in Zhangjiajie,China.2012.
[5]SESIA S,TOUFIK I,BAKER M.LTE-The UMTS long term evolution:from theory to practice SECOND EDITION[M].2009 John Wiley&Sons,Ltd.ISBN:978-0-470-69716-0.
[6]3GPP TS 36.211 v11.4:Evolved Universal Terrestrial Radio Access(E-UTRA);Physical channels and modulation.(Release 11)[S].2013-09.
[7]Wang Jun,Chen Hongyang,Li Shaoqian.Soft-output MMSE V-BLAST receiver with MMSE channel estimation under correlated Rician fading MIMO channels[J].Wirel.Commun.Mob.Comput.,2011,12(15):1363-1370.
[8]JOHN B.Anderson,MLADIK S M.An optimal circular viterbi decoder for the bounded distance criterion[J].IEEE Transactions on Communications,2002,50(11):1736-1742.
