Timesharing-tracking Framework for Decentralized Reinforcement Learning in Fully Cooperative Multi-agent System
2014-02-07XinChenBoFuYongHeMinWu
Xin Chen Bo Fu Yong He Min Wu
I.INTRODUCTION
REINFORCEMENT learning(RL)is a paradigm of machine learning(ML)in which rewards and punishments guide the learning process.The central idea is learning by interactions with the environment so that the agents can be led to a better state.It is viewed as an effective way to solve strategy optimization for multiple agents[1],and is widely applied in multi-agent systems(MASs),such as the control of robots[2,3],preventing traffic jams[4],air traffic flow management[5],as well as optimization of production[6].We particularly focus on the learning algorithms in cooperative multi-agent RL(MARL).
There are lots of papers discussing the challenges in MARL,such as“the curse of dimensionality”,nonstationarity,the exploration-exploitation trade off,and communication and coordination[7].Nonstationarity caused by simultaneous learning was concerned mostly in the last decade.The presence of multiple concurrent learners makes the environment nonstationary from a single agent perspective,which is a commonly cited cause of difficulties in MASs,so that the environment is not longer Markovian[8,9].Besides,a fundamental issue faced by agents working together is how to efficiently coordinate their own results with a coherent joint behavior[10].
As the size of state-action space quickly becomes too large for classical RL[11],we investigate the case that agents which learn their own behavior in a decentralized way.One of the earliest algorithms applied to decentralized multi-agent environments is Q-learning for independent learners(ILs)[12].In decentralized Q-learning,no coordination problems are explicitly addressed.Except policy search[13],greedy in the limit with infinite exploration(GLIE)[14],such asε-greedy or Boltzmann distribution,is a popular single-agent method that decreases the exploration frequency over time so that each agent converges to a constant policy.Besides ILs,various decentralized RL algorithms have been reported in the literature for MAS.In this framework,most authors focus on learning algorithms in fully cooperative MAS.In such environments,the agents share common interests and the same reward function,the individual satisfaction is also the satisfaction of the group[15].The win-or-learn fast policy hill climbing(WoLF-PHC)algorithm works by applying the winor-learn fast(WoLF)principle to the policy hill climbing(PHC)algorithm[16],in which agents′strategies are saved as Q-table.Frequency maximum Q-value(FMQ)[17]works only on the repeated game,in which the Q-value of an action in the Boltzmann exploration strategy is changed by a heuristic value.Hysteretic Q-learning[18]is proposed to avoid the overestimation Q-value in stochastic games.
In order to develop a coordinate mechanism for decentralized learning,while avoiding non-stationary induced by simultaneous learning,we concentrate on a popular scenario of MARL,where the agents share common interests and the same reward function.We propose a decentralized RL algorithm,based on which we develop a learning framework for cooperative policy learning.The definition of even discounted reward(EDR)is proposed firstly.Then,we propose a new learning framework,timesharing-tracking framework(TTF),in order to improve EDR to get the optimal cooperative policy.Unlike some aforementioned works,the state space is split into many one states in TTF.There is only one learning agent in a certain state,while the learning agents may not be the same in different states.From the perspective of the whole state space,all agents are entitled to learning simultaneously.Next,the best-response Q-learning(BRQ-learning)is proposed to make the agents alternatively learn.The improvement of EDR with TTF has been verified,and a practical algorithm,BRQ-learning with timesharing-tracking(BRQL-TT)is completely built with the proposed switching principle.
The remainder of this paper is organized as follows.In Section II,TTF will be proposed and BRQ-learning will be given,and the performance of TTF with BRQ-learning will be discussed.The switching principle of TTF will be proposed to complete TTF in Section III.In Section IV,we will test our algorithm with experiments,and finally draw the conclusions in Section V.
II.TTFFORMARL
Firstly,some denotations involved in the paper are introduced as follows.Discrete joint state combining agent 1 toNis denoted bysss=[s1,s2,···,sN],and discrete joint action executed by agent 1 to agentNis denoted byaaa=[a1,a2,···,aN].The transition probability of joint statesssbeing transited to joint statesss′as the joint actionaaais executed is denoted byp(sss′| sss, aaa),and the policy of agentiat joint statesss,i.e.,the probability of actionaibeing selected by agenti,isπ(ai| sss).The immediate global reward w.r.t.joint-state-jointaction isr(sss, aaa).
In practice,agents in the cooperative MAS always act as a group,so that the following assumptions are reasonable and will serve as the foundations for the decentralized learning method.And we address this system in this context,namely repeated game.
Assumption 1.Agents have common interests.In common interest games,the agents′rewards are drawn from the same distribution.
Assumption 2.As a group,agents are always able to observe the others′state transitions,which means joint state of MAS is observable.
One of the critical challenges is introducing credit assignment,in order to divide payoff w.r.t.individual agents.But for the fully cooperative MAS,all agents receive the same rewards shown as Assumption 1.
Even if agents are able to get the others′time-varying policies by Assumption 2,concurrent learning is still regarded as a major problem,because the transition of states w.r.t.individuals is unstable.Thus the model-free learning based on stochastic approximation,which is widely used in reinforcement learning,can hardly ensure convergence theoretically,although many experiments show its feasibility in decentralized learning.
This is the basic motivation to optimize the cooperative policy.However,there are some key issues to be solved.The first is the Definition of common value functionV,which describes effects brought by agent actions.Another problem seems more critical that the value ofVis unknown before optimization.Thus the cooperative optimization consists of two parts simultaneously,the learning of value function and policy searching which are coupled compactly,because the results of policy searching may change the actual value function during learning,and vice versa.
The well-defined value function is the key to cooperative learning.To develop it,we first introduce the immediate reward of learning agent based on payoff which is fed back from the environment.
Definition 1.The expected immediate reward(EIR)r(sss,ai)w.r.t.agentiis de fined as

whereai∈Ai,andAiis the set of available actions w.r.t.agenti.
Based on EIR,a common expectation of infinite discounted reward for all agents is then developed.
Definition 2.The even discounted reward(EDR)is defined as
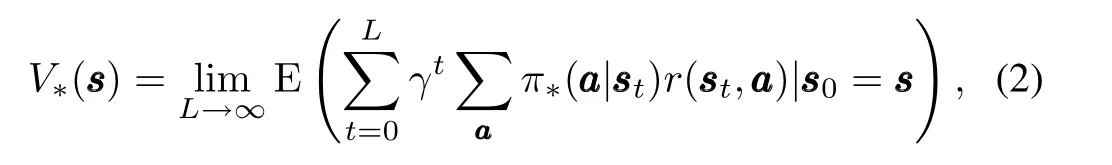

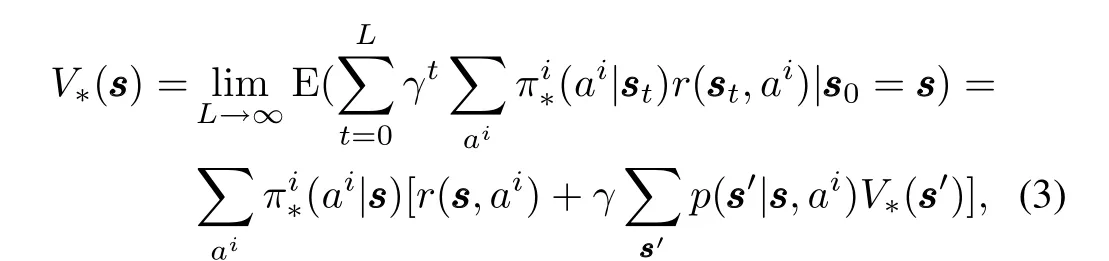
Definition 3.De fining functionQ∗(sss,ai)to be the expression afterπ∗i(ai| sss)on the right-hand side of(3)as

we have the fellowing relation from(3)and(4):

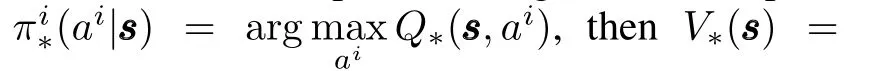
In other words,if all agents execute the best action at a state,(3)will be transformed to the traditional Bellman′s function with infinite discounted reward,which is fixed and not changed by any exploration-exploitation mechanism during learning.Hence,EDR under pure individual strategies can serve as“the common value function”in cooperative optimization.
Notice that the only difference between traditional Q-learning and the dimension-reduced reward Q-learning above is the immediate reward,which reflects companions′policies in MARL.
A.TTF
Based on EDR,we have TTF learning.At an arbitrary joint statesss,the alternate learning mode is executed.And at any instant,only one agent learns EDR to get the best response to the other agents who keep the steady policy.If the period of agenti′s learning is named as episodei,TTF at joint statessscan be illustrated in Fig.1.

Property 1.Combination with value approximation and policy search.In each episode of TTF,the learning agent not only learns Q-value,but also finds out the best response in term of pure policy,so that the EDR is of the same term for all agents in different episodes.
Property 2.Dimension-reduced Q-learning.Although EDR is defined over the joint state-action space,only Q-value defined over the joint-state single-action space is used in reinforcement learning.Thus the computation and memory cost will be reduced significantly,especially when the action space is huge.
Property 3.Macroscopic simultaneous learning.From the perspective of single state,only a single agent executes Q-learning and views its companions as part of the environment.Thus the decentralized learning is simplified into the single Q-learning.But at different states,the learning agents may be different,because it depends on which agent gets the learning privilege.Hence from the perspective of the whole state space,all agents are entitled to learning simultaneously.
According to the definition of EDR and Property 1 of TTF,the stationary of transition probability in Q-learning is easily ensured,so that the single Q-learning can be applied to TTF with joint state considered.
B.BRQ-learning
Since in most MASs with common interest,with Definition 1,the learning agent′s immediate reward is the same as the global rewardr(sss, aaa),while its companions′strategies are pure and steady.In order to introduce a reasonable learning way into TTF,BRQ-learning and its convergence will be proposed.
Theorem 1.For fully cooperative MAS,if the following assumptions are given:
1)All agents share the same immediate individual rewardr(sss,ai);
2)The strategies of all agents except agentiare stationary;
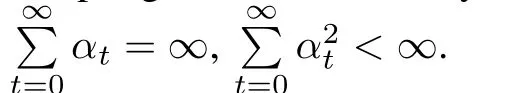
ThenQt(sss,ai)for agenticonverges toQ∗(s,ai)w.p.1(with probability 1)under the iteration rule as follows,

Since the conditions of Theorem 1 is the same as the singleagent Q-learning[19],the conclusion is correct obviously.
Theorem 1 presents that BRQ-learning is able to learn a dimension-reduced Q-value,based on which the agent gets the best response to its companies.Now we analyze the alternate learning in order to verify that the performance of MAS will be enhanced under TTF.The key of the analysis is the common value functionV(sss).
C.Performance of TTF
Taking BRQ-learning into TTF,named BRQL-TT,implies that,the learning agent always tries to find the best response to its companions in each episode.And more importantly,its policy will affect other agents′learning in posterior episodes.Agents try to track others′behavior to promote their policies

Fig.1.Timesharing-tracking framework for one joint state.
in an alternative way.
Theorem 2.Assume that MAS applies TTF,where the agents take turns to learn the pure optimal tracking policy with BRQ-learning.Thus∀ sss∈S,the sequence{Vj(sss),j=1,2,···}is a non-decreasing Cauchy sequence.
Proof.Firstly,we assume the initial policies of agents areπ∗1(a1| sss),π∗2(a2| sss),···,π∗N(aN| sss).Let-ijrepresent the label of agents.From Definition 1,EIR of agentijis

We assume that in thejth episode,agentijuses BRQ-learning to learn the value function.From Theorem 1,it is known that the EDR after thejth learning episode is
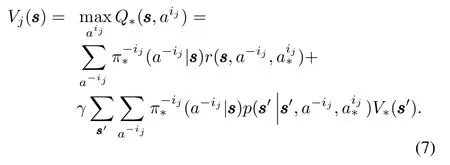

Similarly,in episodej+1,after agentij+1learning,the EDR is expressed as

And in episodej+1,agentijexecutesπ∗(aij|s ss),the item-ij+1changes to-(ij,ij+1),then the itema-ij+1changes toa-(ij,ij+1),to which the function valueVj+1(s ss)relates.To simplify(8),we denote the item after“max”asf(a-(ij,ij+1)),thus,

Letting itema-ijchanges toa-(ij,ij+1),we rewrite(7)as

Comparing(10)with(9),we have

It means the sequence{Vj(sss),j=1,2,···}is non-decreasing.
Because the individual reward is bounded andγ∈[0,1),Vj(sss)is always bounded.Thus{Vj(sss),j=1,2,···}is nondecreasing Cauchy sequence. □
Theorem 2 implies that,in each episode,the learning agent always tries to find the best response to its companions.EDR will increase and converge with learning episode increasing.It means the cooperative policy of MAS will be improved by BRQL-TT.
As we notice that BRQ-learning in Theorem 1 finally results in a pure optimal policy for the learning agent,the EDR in the form of(2)will be finally transformed into
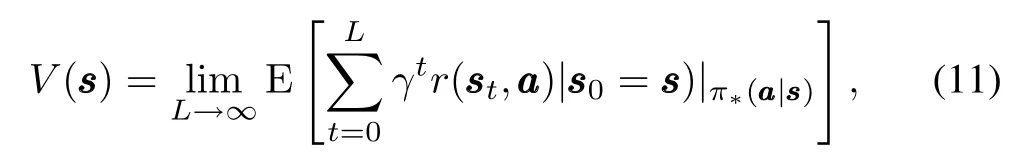
whereπ∗(aaa| sss)denotes the combination of all the policies learnt by agents.
This means that MAS will find a cooperative policy to maximize the discounted reward involved in joint state-action space,although Theorem 2 cannot ensure(11)to reach the global optimum.
III.THE COMPLETION OFTTF
In Theorem 1,only whent→∞,Q(sss,ai)will converge toQ∗,and after convergence the system can switch to another agent′s learning.Obviously,there needs a practical switching principle to substitute“t→∞”in order to realize alternate learning in implementations.To solve this problem,it looks reasonable to predetermine an index to estimate how sufficiently an agent has learnt in an episode.If this index is smaller than a given threshold,the privilege of learning shall be passed on to another agent.
We assume that at statesss,in episodej,agentijis now learning.It is possible for agentijto compute the weighted average of temporal difference(TD)errors over its action set,which is in the form of

Ijmeasures how sufficiently agentijlearns in episodejwith exploration strategyπij(aij|s ss).Obviously,given a proper threshold,denoted byδ,we have the following principle.IfIj<δ,agentijgives up learning,and episodej+1 starts with another agent learning.
In the end,the multi-agent reinforcement learning BRQLTT is depicted in Algorithm 1.

IV.EXPERIMENTS
In order to test the performance of BRQL-TT,we set up the simulation of box-pushing[20].Besides BRQL-TT,other two classical and recent algorithms are selected for comparison.One is WoLF-PHC,in which the learning principle is“learn quickly while losing,slowly while winning”.The other is Hysteretic-Q,which is proposed to avoid the overestimation of Q-value.We run the experiment 50 times,and the agents learn till finishing the task with the above algorithms in the 300000 steps every time.
A.Setup of Experiment
In Fig.2,a rectangular environment is assumed.Several fixed obstacles are distributed randomly in the environment.In addition,in order to alleviate programming burden,the object is simplified as a square box in the lower left corner.There are four agents(robots)around the square,denoted by circles in the environment.It is assumed that the box is sufficiently big and heavy so that any individual robot cannot handle it without the help of the peer robots.The agents and the box share the same state space,which is divided into grids of 10×15 for creating Q-tables.And the actions of agents include the force and its direction angle.

Fig.2.The box-pushing problem and the definition of action:force and direction.
The valid actions include force×direction.Scale of this space is linspace(0,1,5)×linspace(0,2π,10).The parameters of RL are set asγ=0.95,αt=1/(t+1)0.018.We use theε-greedy for decision making,and setε=0.2 initially which is decreased slowly.And the individual reward is 1 when the agents push the box to the goal,otherwise,-1 as penalty.And the initial Q-value for all agents is-50.In addition to the basic parameters which is the same as BRQL-TT,the parameters of WoLF-PHC areδwin=0.03,δlose=0.06,and those of Hysteretic-Q areα=0.3,β=0.03[15].
B.Dynamic Process of BRQL-TT
We focus on one state.Fig.3 shows the order of learning agents over the first 1000 times of visiting state[14,8].Initially,agent 3(marked by cross),is assigned as the first learning agent.After nearly 400 steps,agent 3 obtains the best response to the others,and lets agent 2(marked by star)take its place of learning according to the switching rule,then agent 4,agent 2,and agent 3 repeatedly.Finally,because EDR of[14,8]almost converges,the switch of learning agents becomes more and more quickly.
Since the state space of box-pushing problem is 2D,the V-values(maximum of Q-value over agents′actions)of all joint states with respect to four agents can be mapped to a 3D plot as shown in Fig.4.Theorem 1 implies that,according to the definition of EDR,the cooperative learning with TTF will result in the same V-values map for all agents.Fig.4 shows this property,where the goal of box-pushing is set to be the state[14,9].
To investigate this property in details,we map the 2D states into linear horizon axis according to the in dices assigned to them,and depict all V-values with respect to the four agents in Fig.5.Clearly,for the states close to the goal,which are indicated by relatively higher V-values,their V-values are more identical.It implies that the states around the goal are exploited more thoroughly than others.
C.Comparison of Three Algorithms
In this subsection,some results and comparison between our algorithm BRQL-TT and other algorithms(WoLF-PHC and Hysteretic-Q)will be discussed.Figs.6 and 7 show the average steps and average reward obtained by agents over 50 times of the experiment.Table 1 shows the detail learning results about memory cost and converged steps.

Fig.3. The learning order of agents sampled from the state[14,8].
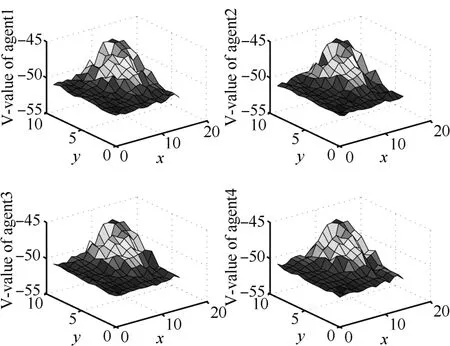
Fig.4 V-values over 2D-state space w.r.t.four agents.
The curves marked by circles in Figs.6 and 7 show the evolution of average steps and rewards with BRQL-TT as the learning steps increase till 300000.The low average steps and the high average reward indicate efficiency of our algorithm.The curves marked by diamonds which results from Hysteretic-Q shows that it can hardly converge in the same number of steps,while the learning with WoLF-PHC,denoted by the curves marked by squares,shows the best converging ability.Thus roughly speaking,the proposed algorithm always outperforms Hysteretic-Q,and is close to WoLF-PHC in converging ability.More properties of dynamics are summarized as follows.
Firstly,Figs.6 and 7 show the learning performance from the beginning to the end.Due to the fewer steps needed in one trail,BRQL-TT learns with less exploration cost than the other two algorithms in the first half period of the experiment.Although the learning using WoLF-PHC is more effective than BRQL-TT after 200000 steps,BRQL-TT looks more steady in the whole learning process.These comparisons tell that,if we take the learning algorithms into applications that cannot afford the high price of exploration,BRQL-TT is a good choice among the three.
Secondly,although TTF makes agents learn in a serial way,but not in a parallel way,the alternate learning does not prolong the learning process significantly.And such alternate learning drives MAS to maintain strong exploration behavior for a long period.That may be the reason for better performance.
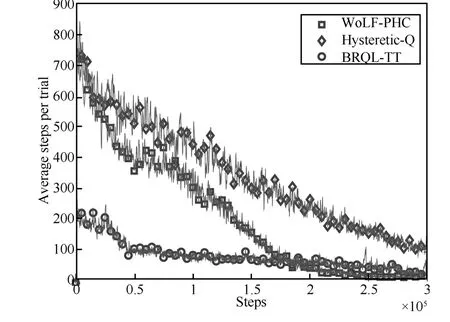
Fig.6. Average steps required to complete a trial.

Fig.5 V-values corresponding to the states indexed in linear axis.
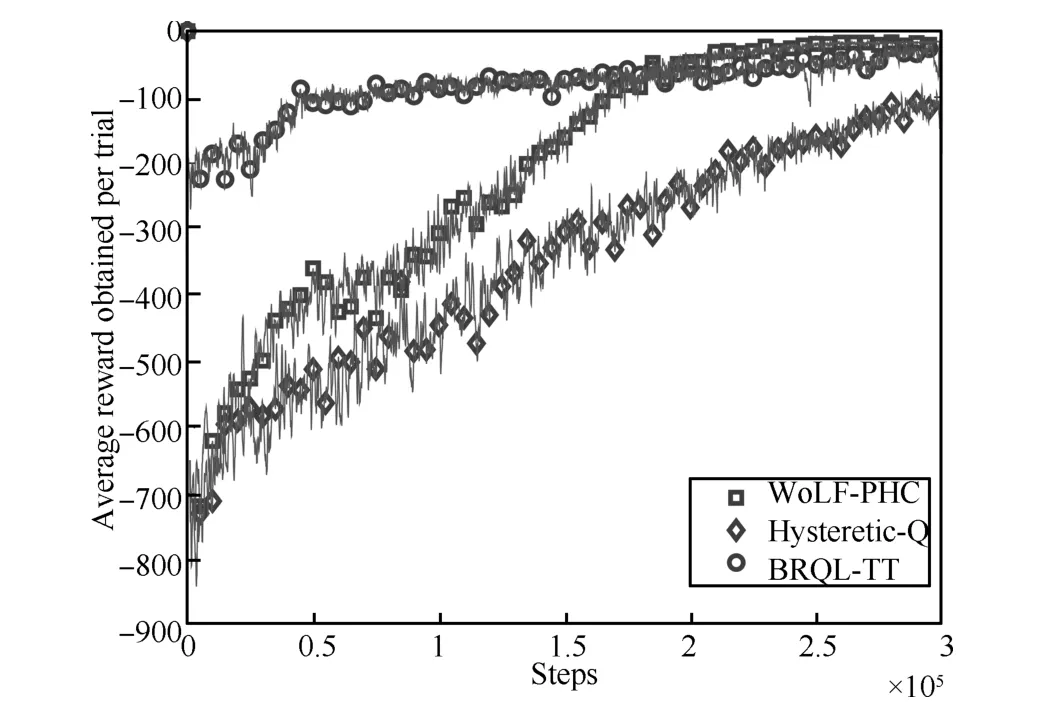
Fig.7.Average reward obtained in every trial.
Finally,it is easy to investigate that the space cost of the proposed algorithm isN·|S|·|A|,which is the same as Hysteretic-Q.However,the space required by WoLF-PHC is doubled,since the agents must build the table for their strategies such as Q-value.All data is shown in Table I.On the other hand,as only one agent learns in each state when using BRQL-TT,the computational cost will be much less than those of the other two algorithms.

TABLE ICOMPARISON IN THE SPACE COST AND CONVERGED STEPS
Above all,the simulation results show feasibility of TTF and high efficiency of BRQL-TT in cooperative reinforcement learning.In addition,in the aspects of applicable conditions,exploration cost,reproducibility of dynamics,BRQL-TT shows its special characteristics and superiorities.
V.CONCLUSIONS AND FUTURE WORK
To tackle cooperative multi-agent learning without knowledge about companions′policies in priori,this paper firstly gives two assumptions to analyze what is brought by individual learning to group policy.Based on the common EIR,EDR is proposed to measure effectiveness of cooperation under the pure policies taken by agents.Then,TTF is proposed to make individual agents have chances to develop EDR in every joint state.To decrease the dimension of action and enhance efficiency of individual learning,BRQ-learning is developed to entitle agents to get the best responses to their companions,or in other words,track its companion′s behavior.Finally,with BRQL-TT applied with TTF,the EDR under the cooperative policy of MAS increases consistently and converges finally.Due to significant decrease in the dimension of action space,the algorithm speeds up the learning process,and reduces computation complexity.It is attractive for the implementation of cooperative MAS.
EDR defined in this paper can be viewed as a general expression about the discounted reward of MAS,so that the discounted reward based on joint-state joint-action will be regarded as a special EDR resulting from all agents executing the pure policies.Thus,the cooperative learning is transformed into a kind of EDR optimization,which consists of individual learning and coordinate optimization of EDR.So the convergence theorem on the simultaneous learning in the decentralized way will be our main work in the future.
[1]Gao Yang,Chen Shi-Fu,Lu Xin.Research on reinforcement learning technology:a review.Acta Automatica Sinica,2004,30(1):86-100(in Chinese)
[2]Busoniu L,Babuska R,Schutter B D.Decentralized reinforcement learning control of a robotic manipulator.In:Proceedings of the 9th International Conference on Control,Automation,Robotics and Vision.Singapore,Singapore:IEEE,2006.1347-1352
[3]Maravall D,De Lope J,Douminguez R.Coordination of communication in robot teams by reinforcement learning.Robotics and Autonomous Systems,2013,61(7):661-666
[4]Gabel T,Riedmiller M.The cooperative driver:multi-agent learning for preventing traffic jams.International Journal of Traffic and Transportation Engineering,2013,1(4):67-76
[5]Tumer K,Agogino A K.Distributed agent-based air traffic flow management.In:Proceedings of the 6th International Joint Conference on Autonomous Agents and multi-agent Systems.Honolulu,Hawaii,USA:ACM,2007.330-337
[6]Tang Hao,Wan Hai-Feng,Han Jiang-Hong,Zhou Lei.Coordinated lookahead control of multiple CSPS system by multi-agent reinforcement learning.Acta Automatica Sinica,2010,36(2):330-337(in Chinese)
[7]Busoniu L,Babuska R,De Schutter B.A comprehensive survey of multi-agent reinforcement learning.IEEE Transactions on Systems,Man,and Cybernetics-Part C:Applications and Reviews,2008,38(2):156-172
[8]Abdallah S,Lesser V.A multi-agent reinforcement learning algorithm with non-linear dynamics.Journal of Artificial Intelligence Research,2008,33:521-549
[9]Xu Xin,Shen Dong,Gao Yan-Qing,Wang Kai.Learning control of dynamical systems based on Markov decision processes:research frontiers and outlooks.Acta Automatica Sinica,2012,38(5):673-687(in Chinese)
[10]Fulda N,Ventura D.Predicting and preventing coordination problems in cooperative Q-learning systems.In:Proceedings of the 20th International Joint Conference on Artificial Intelligence.San Francisco,CA,USA:Morgan Kaufmann Publishers Inc,2007.780-785
[11]Chen X,Chen G,Cao W H,Wu M.Cooperative learning with joint state value approximation for multi-agent systems.Journal of Control Theory and Applications,2013,11(2):149-155
[12]Wang Y,de Silva C W.Multi-robot box-pushing:single-agent Q-learning vs.team Q-learning.In:Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems.Beijing,China:IEEE,2006.3694-3699
[13]Cheng Yu-Hu,Feng Huan-Ting,Wang Xue-Song.Expectation-maximization policy search with parameter-based exploration.Acta Automatica Sinica,2012,38(1):38-45(in Chinese)
[14]Teboul O,Kokkinos I,Simon L,Koutsourakis P,Paragios N.Parsing facades with shape grammars and reinforcement learning.IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(7):1744-1756
[15]Matignon L,Laurent G J,Fort-Piat N L.Independent reinforcement learners in cooperative Markov games:a survey regarding coordination problems.The Knowledge Engineering Review,2012,27:1-31
[16]Bowling M,Veloso M.multi-agent learning using a variable learning rate.Artificial Intelligence,2002,136(2):215-250
[17]Kapetanakis S,Kudenko D.Reinforcement learning of coordination in heterogeneous cooperative multi-agent systems.In:Proceedings of the Third International Joint Conference an Autonomous Agents and multi-agent System.New York,USA:IEEE,2004.1258-1259
[18]Matignon L,Laurent G J,Fort-Piat N L.Hysteretic Q-learning:an algorithm for decentralized reinforcement learning in cooperative multi-agent teams.In:Proceedings of IEEE/RSJ International Conference on Intelligent Robots and System.San Diego,California,USA:IEEE,2007.64-69
[19]Tsitsiklis J N.On the convergence of optimistic policy iteration.The Journal of Machine Learning Research,2003,3:59-72
[20]Wang Y,de Silva C W.A machine-learning approach to multi-robot coordination.Engineering Applications of Artificial Intelligence,2008,21(3):470-484
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Modeling and Hybrid Optimization of Batching Planning System for steel making-continuous Casting Process
- Containment Control of General Linear Multi-agent Systems with Multiple Dynamic Leaders:a Fast Sliding Mode Based Approach
- Bilateral Teleoperation of Multiple Agents with Formation Control
- Distributed Sparse Signal Estimation in Sensor Networks UsingH∞HH-Consensus Filtering
- Adaptive Nonsingular Terminal Sliding Mode Control Design for Near Space Hypersonic Vehicles
- Distributed Consensus of Multiple Nonholonomic Mobile Robots