一种具有容错机制的MapReduce模型研究与实现
2014-01-17史椸耿晨齐勇
史椸,耿晨,齐勇
(1.西安交通大学电子与信息工程学院,710049,西安;2.中航工业西安飞行自动控制研究所,710065,西安)
MapReduce[1]编程模型在任务处理的过程中,个别节点容易出现错误,出错节点对整个系统性能的影响较大。传统MapReduce模型的容错机制较为简单,对错误的处理容易产生重复计算,造成计算资源的浪费。在容错时如果使用传统的进程检查点机制,则开销较大并且难以保证恢复数据的安全性。
随着多核技术[2-3]的发展,多核资源越来越丰富,且呈现分布式的趋势。如何能够充分利用多核服务器的计算能力和硬件资源是一个随之而来的问题。现代操作系统通过不断增加系统的复杂性[4-5]来适应持续发展的硬件资源,虚拟化技术的出现在一定程度上解决了现有系统众多影响计算机性能的问题。虚拟化技术可以提高服务器资源利用率,同时减少服务器数量,以降低管理和维护的开销,降低能源消耗[6]。同时,虚拟化技术提供了很好的隔离性,使得虚拟机之间互不干扰,提高了系统的安全性和可靠性。
基于上述问题,本文通过分析现有MapReduce的实现方式,将多核平台与虚拟机技术相结合,提出了一种基于多核虚拟机的MapReduce模型(Virtual Machine Based Fault-Tolerant Mechanism,VMBFTM)。
1 任务分配模型
1.1 系统状态模型与分析
基于多核虚拟机的具有容错机制的MapReduce,其系统状态模型如图1所示。
通过虚拟机监控器的虚拟化,在多核服务器上形成多个操作系统。其中一个操作系统叫做控制域,这个控制域把必要的接口暴露给用户,以便用户进行编程和数据处理。服务器管理员通过这个控制域对整个多核服务器进行维护,提交计算任务,调节整个系统负载,并对安全问题进行处理。其他操作系统受到控制域的监控,对网络或者外设的访问需要受到控制节点的限制。MapReduce模型中调度节点Master进程运行在控制域OS0。首先,用户在控制节点提交需要处理的数据,Master进程对数据进行Split分割操作,划分成N个数据块。数据块的个数和整个多核服务器中Worker工作节点个数相同。然后Master和每个操作系统中的守护进程监控者进行通信,发出启动 Worker的命令。监控者收到命令之后,启动 Worker,然后每个 Worker创建指定个数的线程,对分配给它的数据进行Map映射操作。Map操作处理待处理数据中每个记录,产生中间结果的键值对<key,value>,然后在相同key的结果上执行Reduce操作。在执行Map操作的过程中,根据用户指定或者系统默认的策略,进行检查点的设置。设置检查点时,需要陷入虚拟机,把Map当前的中间结果保存在虚拟机维护的Map结果存储区中,并记录相关控制信息,例如当前节点已经完成的任务量等。设置完检查点之后,返回操作系统,继续进行 Map操作。完成Map任务之后,Map产生的全部中间结果保存在共享内存中,接着关闭Worker进程,监控者通知 Master本阶段完成,请求进行Reduce化简阶段的处理。Master收到这个消息之后,重复上面的过程,进入Reduce阶段。Reduce过程中,每个Worker需要读取Map的结果作为自己的输入。每个Worker通过访问共享内存中Map结果存储区,读取属于自己节点的数据进行Reduce操作,通过共享内存减少了传递大量中间结果带来的时间开销。在Reduce过程中,Reduce的结果也被不断保存,以便在发生错误之后通过这些保存的数据进行恢复。
错误恢复模型如图2所示。接收到Master向监控者发出的命令之后,启动本节点内的Worker,Worker会创建多个线程进行Map或者Reduce操作。在此过程中,根据一定策略进行检查点的设置,通过增量方式把当前Map或者Reduce执行的任务保存在由虚拟机维护的内存区域内。如果Worker检测到错误发生则会通知监控者,监控者随即关闭本节点内的Worker,并向Master发送消息,请求在本节点内重新启动一个Worker。当Master发出启动命令之后,监控者重启Worker,先从虚拟机维护的内存中读取已经做好的中间结果和原始分配的任务以及相应的控制信息等,然后对Worker进行初始化操作,完成错误恢复。系统就像没有发生错误一样,继续执行Map或者Reduce操作。如果本节点内分配的任务已经做完,监控者关闭Worker。

图2 错误恢复过程模型
1.2 错误恢复开销研究
基于多核虚拟机的具有容错机制的MapReduce在Worker运行时通过对中间结果设置检查点达到错误恢复的效果。假设在 Worker运行中,检查点是均匀分布的,设每个检查点间隔计算任务消耗的时间为ti,并且由于(key,val)的处理过程,每个检查点之间的计算任务消耗的时间大致相等,即ti=TPA,TPA表示每两个检查点间隔计算任务消耗时间的平均值,TSA表示第1个检查点,即单位时间内保存中间结果的时间,且TPA≈TSA,TRA表示对单位时间内生成的中间结果进行恢复需要的时间。FK是第K 次发生错误,n表示程序运行完成过程中需要建立n个检查点。因此不设检查点的Map或者Reduce的执行时间为

设置检查点后,程序执行时间为

式中:TE表示每次进行检查点时陷入和返回虚拟机的时间,每次都相等,共有n次;TiS表示每次保存中间结果所需要的时间。
不设检查点出错之后,程序直接终止,所消耗的时间为

不设检查点出错后进行恢复时,出错节点需要从头开始计算,由于可能在运行过程中多次产生错误,设每次错误之后运行到tFi,因此整个过程消耗的时间为

式中:当i>j时,Fi>Fj。进行检查后,在F处出错之后整个进程消耗时间为

检查点出错后进行恢复时,发生错误次数为K,错误发生点为tFi,每次只要从最近的检查点继续执行即可,从最近检查点进行恢复的时间为TFiR,所消耗时间为

式中:TFiR表示从最近的检查点进行恢复数据所需要的时间,TFiR和保存最近检查点的数据所花费的时间大致相等。
为了比较不设置检查点和设置检查点之后恢复的效果,比较TNFR和TCFR,即

如前所述,ti=TPA,且每次检查点保存和恢复的时间随着中间结果的增长而线性增加,因此TiS=iTSA,所以可以进一步得出

由于是轻量级虚拟机,虚拟机每次陷入和返回的时间和较短,因此nTE可以忽略。而且对使用MapReduce模型进行处理的应用来说,计算产生中间结果花费的时间远远大于把这些中间结果保存在内存中花费的时间,即TPA≫TSA。进一步分析式(8)后,发现当n不太大的时候,TPA/TSA<5即可保证TNFR>TCFR成立,即本文设计的容错机制相比传统的MapReduce容错机制更有优势。
2 系统的设计与实现
本文所设计的系统需要3个部分支持:具有容错机制的MapReduce引擎、用户定制程序以及虚拟化的多核服务器。三者关系如图3所示。前两者是软件支持,第3个是硬件平台支持。具有容错机制的MapReduce引擎是对MapReduce过程进行统一管理,对底层硬件平台进行抽象,提供良好的通信机制和数据管理能力,包括Master端、Worker端以及监控者程序。用户定制程序是用户自己编写的对不同的应用案例进行特定处理的程序,主要是用户自定义的Split,Map和Reduce函数。虚拟化的多核服务器是运行系统的硬件平台,为具有容错功能的MapReduce系统提供硬件支持,这里是通过轻量级虚拟机监控器对多核服务器进行虚拟化,把多个隔离的操作系统作为隔离的节点,运行一个Master或若干Worker。为完成系统功能要求,需要解决3个问题:一是如何进行数据处理;二是任务调度和通信效率;三是容错机制的建立。
2.1 数据处理过程
数据处理的前提是建立域间共享内存,它是整个系统的核心,也是其他模块运行的基础和前提条件。共享内存为多核系统SMM[7]提供简单编程模型,并且可以兼容大部分当前已有的应用程序和操作系统。共享内存系统[8]可使各个模块平等地访问系统中的物理内存。

图3 基于多核虚拟机的具有容错机制的MapReduce
在OS内核中需要建立共享内存到内核空间的映射,然后建立用户地址空间和内核地址空间的映射,这样OS中的Master和Worker进程就可以自由地使用共享内存在不同OS之间通信。
数据处理模块把系统的控制信息等敏感数据保存在共享内存中;任务调度模块根据共享内存中的控制进行任务调度;节点通信模块使用共享内存进行节点之间的通信和交互;检查点模块把恢复数据保存在各个节点都能访问到的共享内存中,便于在出错后使用错误恢复模块进行恢复。
在数据输入阶段,对于Master节点,计算任务的数据一般以文件的形式提供,先存放在Master节点硬盘中。数据处理模块需要把计算任务文件读入内存,然后根据一定的规则进行分割,把这些数据存放在虚拟机维护的内存区域中。对于Worker节点,每个节点的输入数据是本节点需要处理的数据,由虚拟机调用。通过虚拟机维护的共享内存,Worker进程可以对本节点的数据进行操作。由于每个节点只映射自己所要处理的数据的内存,不会对其他节点的数据进行影响和破坏。Map阶段和Reduce阶段类似,从共享内存中读入本节点需要处理的数据,通过任务调度分发给每个线程,进行计算后输出到共享内存中,中途需要根据一定策略对中间结果进行必要的保存。
2.2 任务调度和通信
任务调度模块是在系统运行时,完成任务调度和负载均衡的功能。任务调度的过程包括监控者开启和关闭Worker进程,Worker进程开创多个线程进行Map或者Reduce操作,操作完毕之后通知完成工作。通过使用进程和线程结合的方式,在每个子域的操作系统上运行一个 Worker,然后每个Worker又创建多个线程,每个线程处理一块数据。这样能够很好的利用多进程和多线程的优势。
节点通信模块主要负责节点之间的通信,保证Master能够准确地控制Worker节点的执行,并在Worker节点的任务执行的过程中和完成任务之后,Master节点能够及时了解此Worker节点的任务状态信息。
Master进程直接和子域中的监控者进程进行通信。监控者是守护进程,一直运行在子域中,负责监听Master信号,在收到Master发过来的启动命令之后,启动本节点中Worker进程。在节点内部多线程执行任务的过程中,如果发生错误,Worker进程崩溃,监控者进程发现Worker崩溃后,需要在全局任务控制表中属于本节点的表项中注明错误发生,同时Master进程会不断扫描全局任务控制表项。由于全局任务控制表是存放在各个域之间的共享内存中,因此Master通过定时扫描就可以及时发现状态的改变,并有效地对 Worker进行监控和管理。
2.3 建立容错机制
本文给出的MapReduce的容错机制包括两方面:检查点设置和错误恢复。
在检查点时刻把当前线程的计算结果保存在虚拟机指定的隔离内存空间,出错之后在出错节点重新启动Worker进程,从最近的检查点读取中间结果数据和本节点任务的进度信息继续运行。由于(key,val)的特点,key和产生它的进程以及所在的节点无关,因此可以由任意的线程继续对它进行处理。
这些恢复数据存放在由VMM指定内存中,OS系统是无法感知和访问的,这样就形成了隔离屏障,保证当Worker进程甚至整个OS异常终止或者崩溃之后,这些恢复数据不会受到破坏和影响。VMM接受虚拟机调用之后,在虚拟机里把线程已经处理好的数据保存在指定的专门存放中间结果的内存中,这块内存通过资源的隔离性保证了恢复数据的安全性。
在恢复的过程中,通过读取存放在全局任务控制表中的任务进度信息,Worker进程创建线程并读取任务进度信息从而使每个线程恢复到设置检查点时的状态。由于(key,val)和线程状态无关,因此新的线程可以继续执行出错前任意一个线程的任务。由于检查点时刻的任务都保存在VMM维护的隔离内存中,因此需要陷入虚拟机,用保存的中间结果恢复OS中的所有线程共同操作的中间结果池。
3 实验结果与分析
测试的硬件平台是基于SUN的32核、主频为2.38GHz、内存为128GB的服务器。硬件之上运行着本课题组设计实现的虚拟机监控器OSV。相比于传统的虚拟机监控器,我们设计的OSV虚拟机监控器是轻量级的,易于维护,并且性能更高。虚拟机监控器对其上的操作系统分配资源,并且阻止其他操作系统未授权的访问,形成了资源的隔离。节点之间可以通过一般的TCP/IP进行通信,而对于大量的数据,通过虚拟机维护的共享内存进行数据交流在一定程度上提高了数据交互的性能。为了降低虚拟化对系统带来性能上的影响,虚拟机只是对资源进行访问控制,而没有对资源进行虚拟化。由于VMM在OS运行时处于挂起状态,并且OS对授权的硬件资源直接进行访问,因此相比于没有虚拟机的多核服务器,性能损耗很小。
3.1 MapReduce应用性能测试
wordcount应用是用来测试MapReduce性能的一个比较普遍的测试用例,其功能是对一个存放英文单词的大文件进行处理,统计其中的英文单词出现的频率,得出出现单词的种类和各个单词出现的次数。使用wordcount应用对基于多核虚拟机的具有容错机制的MapReduce在多核平台上进行测试,并和两种不同模式的多线程实现方式以及Phoenix系统进行对比。
斯坦福大学在多核服务器上实现了Phoenix[9]系统,直接运行在多核服务器上的一个操作系统,它是基于共享内存的MapReduce,使用多个线程完成Worker的任务。
第一种多线程方式运行在多核服务器上唯一的操作系统中,这个操作系统完全掌控所有的硬件资源,即单操作系统多线程方式,通过使用Pthread多线程进行wordcount应用的处理。第二种多线程方式是在多核平台上使用虚拟机监控器进行资源隔离,运行多个操作系统,每个操作系统上运行一个Worker进程,每个 Worker进程创建4个线程,即多操作系统多线程方式。每个操作系统相当于分布式环境下单独的一个计算节点,借助MapReduce思想进行wordcount处理。
对4线程、8线程、12线程、16线程4种情况测试1GB大小的wordcount文件的计算时间,结果如图4所示。可以看出,Pheonix性能略高,而单操作系统多线程方式和基于多核的具有容错机制的MapReduce性能类似,并且性能与Pheonix相差不大,而多操作系统多线程方式的性能最差。
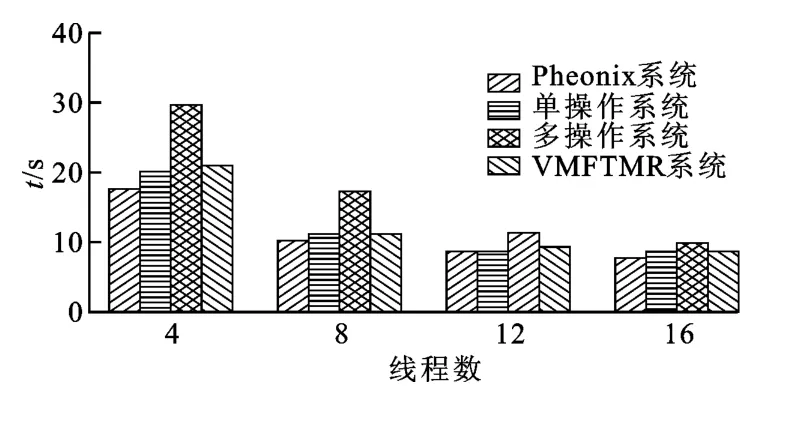
图4 4种方式进行wordcount计算的执行时间
基于多核虚拟机的具有容错机制的MapReduce和Phoenix性能差距较小。由于通过使用节点之间的共享内存进行数据传递比通过网络传输速度更快,而且作为Reduce输入数据的中间结果保存在节点之间的共享内存中,执行Reduce的Worker可以直接对这块内存进行操作,避免了对硬盘访问带来的开销。
3.2 错误恢复测试与评价
由图5可见,当错误发生之后,监控者进程迅速发现Worker进程出错,提示出错 Worker进程的PID,并重启 Worker进程继续执行;如果 Worker进程发生多次错误,每次出错之后监控者进程可以立即感知,启动新的Worker进程继续计算,直到完成整个任务。相比发生一次错误的情况,出现两次错误的执行过程所耗费的时间没有明显增加。

图5 错误恢复过程
图6为不同出错次数情况下各种并行计算方式出错后重启并完成计算所耗费的时间。

图6 不同出错次数的恢复时间比较
基于多核虚拟机的具有容错机制的MapReduce在出错之后可以立即重启并继续执行,已完成的结果没有丢失,不会造成计算任务的浪费。由图6可见,多次恢复之后,本模型相对于其他3种方式,完成计算任务的时间最短,性能最优。
3.3 安全隔离功能测试与评价
通过对中间结果进行检查点设置,可以在错误恢复的过程中通过读取保存的数据进行恢复。传统使用检查点的保存方式是把数据保存在内存或者磁盘中,恢复的时候启动恢复策略将已经保存的数据恢复出来,然而由于操作系统受到攻击或者其他恶意程序,保存的数据受到污染,因此恢复之后的结果是错误的,如图7a所示,而基于多核虚拟机的具有容错机制的MapReduce系统可以进行正确的恢复,如图7b所示。

图7 恢复数据区对比图
虚拟机监控器可以完全控制和管理多核平台的内存,使操作系统无法直接访问隔离的内存,因此需要恢复的数据不会受到操作系统内部各种错误的影响,保证了恢复数据的安全性。
4 结 论
本文充分利用了多核服务器架构和虚拟化技术的特点,设计并实现了基于多核虚拟机的具有容错机制的MapReduce,通过虚拟机监控器进行安全数据隔离和恢复,对中间结果进行保存以提高错误恢复的性能,降低了节点之间的数据传输开销。测试了系统的性能、错误恢复的能力以及安全数据隔离的效果,并与其他并行程序的性能进行相应的对比。结果表明,本文所提出的改进的MapReduce模型提高了错误恢复的性能,保证了恢复数据的安全性。下一步将优化检查点策略,完善错误感知机制,减小保存和恢复过程中的性能损耗。
[1] DEAN J,GHEMAWAT S.MapReduce:a flexible data processing tool [J].Communications of the ACM,2010,53(1):72-77.
[2] MOHANTY R P,TURUK A K,SAHOO B.Analysing the performance of multi-core architecture[C]∥Proceedings of the first International Conference on Computing,Communication and Sensor Networks.New York,USA:IJCA,2013:28-33.
[3] MERRITT R.CPU designers debate multi-core future[EB/OL].(2008-02-06)[2012-10-02].http:∥www.eetimes.com/document.asp?doc_id=1167932.
[4] DESNOYERS M,MCKENNEY P E,STEM A S,et al.User-level implementations of read-copy update[J].IEEE Transactions on Parallel and Distributed Systems,2012,23(2):375-382.
[5] Receive-side scaling enhancements in windows server[EB/OL].(2008-11-05)[2012-10-15].http:∥www.microsoft.com/whdc/device/network/ndis_rss.mspx.
[6] MATTHEWS J N,DOW E M,DESHANE T,et al.Running Xen:a hands-on guide to the art of virtualization[M].New Jersey,USA:Prentice Hall,2008:56-59.
[7] CHAPMAN M.HEISER G.vNUMA:a virtual sharedmemory multiprocessor[C]∥Proceedings of the 2009 USENIX Annual Technical Conference.San Diego,USA:USENIX Association,2009:349-362.
[8] GULATI A,MERCHANT A,VARMAN P J.MClock:handling throughput variability for hypervisor I/O scheduling[C]∥Proceedings of the 9th USENIX Conference on Operating Systems Design and Implementation.Berkeley,CA,USA:USENIX Association,2010:1-7.
[9] TALBOT J,YOO R M,KOZYRAKIS C.Phoenix++:modular MapReduce for shared-memory systems [C]∥Proceedings of the Second International Workshop on MapReduce and Its Applications.New York,USA:ACM,2011:9-16.
