基于共振峰谐波特征和支持向量机的VDR人声检测方法
2013-12-02李正友李天伟
李正友,李天伟,黄 谦
(1.大连舰艇学院 航海系,辽宁大连116018; 2.中国人民解放军69029 部队,新疆 乌鲁木齐830011)
0 引 言
船舶航行数据记录仪(voyage data recorder,VDR)是现代船舶的必备设备。安装VDR 的目的是“为了以一种安全和可恢复的方式,保存有关船舶发生事故前后一段时间的船舶位置、动态、物理状况、命令和操纵的信息”[1],在船舶事故原因调查中能够发挥重要作用。由于存储容量限制,VDR 采用由新数据覆盖旧数据的循环存储方式[2]。这要求VDR 主机必须能在第一时间准确判断事故是否已经发生并及时关闭,以保留事故发生前后存储的宝贵数据。检测20 min 内有无人声是目前最常用的VDR 主机停机条件之一。由于驾驶室环境是各种人声(不同的说话人、说话内容、语言类型等)和各种非人声(如海浪声、风声等)的混合声音,因此VDR 人声检测的目的在于判断一段声音是否是语音,或者判断其中是否含有语音。
目前,国内外在声音识别领域的研究包括识别不同说话人特征的说话人识别及识别不同语义特征的语音识别、识别不同情感状态特征的情感识别等。它们的共性是在已知该声音是语音的前提下,研究语音的某一方面特征,而VDR 人声检测则是需要判断一段声音是否是语音或者判断其中是否含有语音。由于语音和环境的多变性,说话人识别、语音识别或情感识别中应用广泛的特征参数(如MFCC、LPCC 等),在人声检测中应用效果并不理想。本文从语音的产生机理出发,结合驾驶室环境下各种声音的特点,提出采用共振峰谐波特征(formant-consonance characteristic,FCC)来进行人声检测。在分类方法方面选择了泛化能力较强的支持向量机(support vector machines,SVM)分类方法。
1 共振峰谐波特征提取
语音的产生主要是声门激励和声道调制的结果,这是语音区别于其他任何声音的本质特征。声道可以看成是1 个具有某种谐振特性的腔体,其一组谐振点称为共振峰,共振峰的位置及各个峰的宽度决定了声道的频谱特性[3]。由于声门激励不同,产生了浊音、清音、爆破音等不同类型的语音,其中浊音占据了大部分语音能量和时长。浊音的声门激励是准周期的脉冲序列,它有丰富的谐波成分[3],反映了声门激励特征。因此共振峰和谐波特征可以有效区分驾驶室环境下人声和非人声。
共振峰信息包含在频谱包络之中,频谱包络的极大值就是共振峰[4]。图1(a)和图1(c)实线所示为人声和海浪声的频谱,虚线所示为各自的谱包络;图1(b)和图1(d)所示分别为去除共振峰信息后剩余信号的频谱。从图1(a)实线所示语音信号频谱图中可以明显地看出共振峰和谐波,计算图1(a)虚线所示的频谱包络后,共振峰更加明显,语音信号去除共振峰信息后剩余的信号频谱如图1(b)所示,谐波特征非常明显,而且其谐波频率与原始语音频谱的谐波频率相等;图1(c)和图1(d)所示的海浪声频谱则不具备语音信号的上述特征。
共振峰提取方法已经提出了多种,目前主要有2 类:倒谱法和线性预测分析(linear prediction analysis,LPA)法[4-6]。倒谱法是对原始语音信号进行傅立叶变换的对数幅度谱进行逼近,然后进行反傅立叶变换得到时域的倒谱系数。倒谱系数的低时部分携带了声道的信息,可以通过倒谱系数表示的频谱包络来估计共振峰频率,但是存在倒谱系数的长度不确定的问题,并且在频域中处理计算的复杂度较高[5]。线性预测法是共振峰检测领域的主流算法,它首先求出线性预测系数,然后用线性预测系数估计声道的谱包络,再用峰值检出法算出共振峰频率[6]。本文采用线性预测法检测共振峰,用线性预测残差信号检测谐波。图2所示为采用线性预测法分别对语音和非语音信号进行检测的结果。
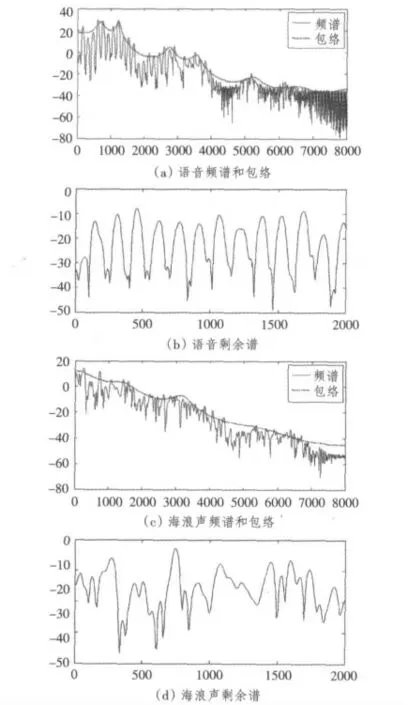
图1 语音信号和关门声信号频谱对比Fig.1 Spectrum comparison of speech signal and the sound of closing door
从大量语音信号和非语音信号的检测结果来看,浊音语音信号的共振峰频率和带宽与音素及说话人有关。同一说话人发同一个浊音,其共振峰频率和带宽基本不变;不同说话人发同一个浊音,其共振峰频率和带宽相差不大;同时语音浊音音素的个数有限,其共振峰频率和带宽在一定范围内变化;而非语音信号频谱包络的峰值频率和带宽十分不稳定。对语音信号进行线性预测残差分析后,都能得到相对稳定的谐波,其残差频谱峰值较少,峰值之间的间隔相差不大。因此本文采用声音信号LPA 谱前3个峰的频率F1~F3、LPA 残差信号谱的0 ~2 000 Hz 范围内波峰的个数Nr和相邻波峰频率间隔的方差Sr等参数作为VDR 人声检测的主要特征参数。
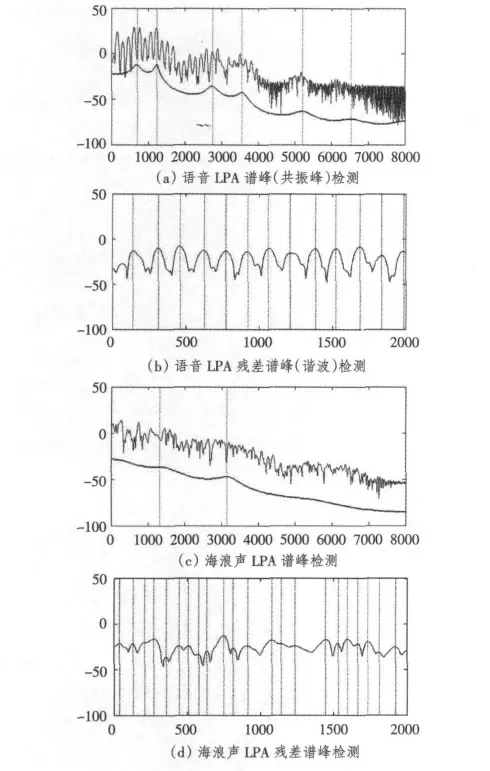
图2 语音信号和非语音信号共振峰谐波对比Fig.2 Formants and resonances comparison of speech and non-speech signals
2 基于SVM 的人声检测
支持向量机(support vector machine,SVM)以统计学习理论作为坚实的理论依据,具有简洁的数学形式、直观的几何解释和良好的泛化能力,避免了局部最优,有效克服了“维数灾难”,能够较好地解决线性不可分问题。近年来,它在实践方面取得了比传统分类器更优的分类性能[7]。基于SVM 的VDR 人声检测实际上是提取信号的某些声学特征、利用SVM 解决语音和非语音的2 类分类问题。
在SVM 的训练阶段,给定训练样本集{xi,ti},i=1,2,…,N,xi为n 维特征向量,ti∈{-1,+1}(ti=1 表示语音,ti=-1 表示非语音),求解高维映射空间内分类间隔最大的最优超平分类面(w,b)。约束条件为
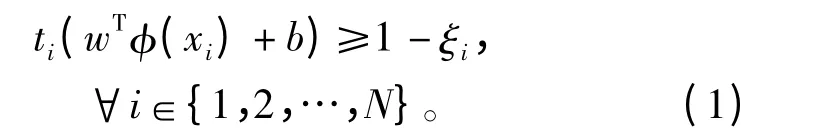
求解下列函数:
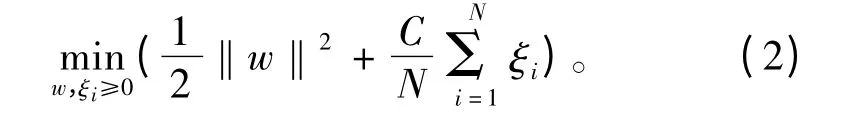
式中:φ(·)为非线性映射函数;ξi为松弛变量;C为用于平衡错分样本比例与算法复杂度的常量。
在SVM 测试阶段,其最优分类函数为
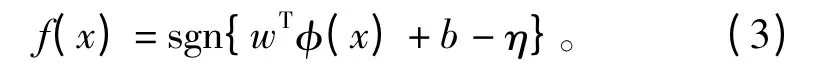
式中:η 为判决门限;sgn(·)为符号函数;f(x)=1 表示观测量x 是语音,反之为非语音。
3 实验结果及分析
语音与非语音的范围非常广泛,但VDR 人声检测仅仅需要区分驾驶室环境下少数人的语音和环境噪声即可。以在海上实际采集的海浪声、风声、海鸟叫声、船笛声、船舶主机工作声、驾驶室内部分设备工作声等非语音以及典型10 名话者语音构成语料库。
在获得训练样本时,对于语音信号,需要先进行语音能量检测及清浊判别,每个语音信号可以得到多个浊音段。对每个浊音段分帧,再采用LPC 方法对每一帧数据提取共振峰谐波特征参数。对于非语音信号,经过能量检测后,直接分帧,对每帧信号提取特征参数。将语音和非语音信号提取的特征参数组合到一起,构成SVM 的训练样本,其中部分训练样本如表1所示。在进行人声识别测试时,无论是语音还是非语音信号,都经过能量检测后直接分帧,再提取特征参数,输入SVM 进行分类。如果一个声音信号有连续多帧被SVM 判别为语音,则该声音为语音信号。
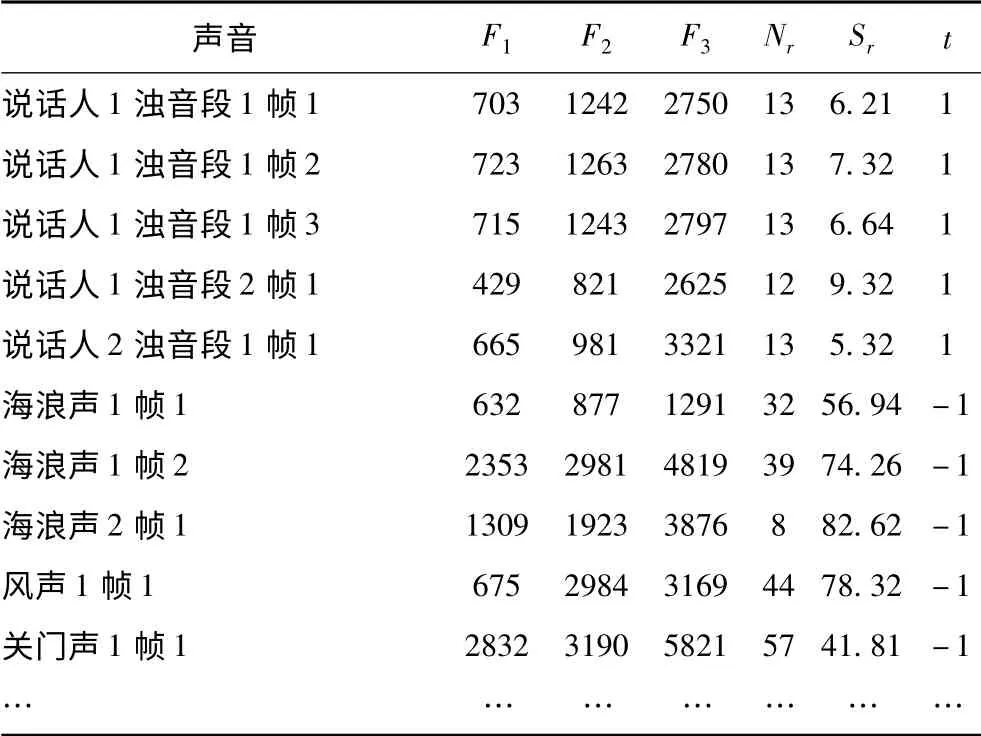
表1 部分训练样本Tab.1 Part of training samples

表2 人声检测正确率(%)比较Tab.2 Comparison of speech detection accuracy rate (%)
本文开展了2 个实验。实验1 从不同说话人对同一浊音音素的发音中提取特征参数;实验2 从不同说话人对不同浊音音素的发音中提取特征参数,再加上从各种非语音中提取的特征参数,构成训练样本和测试样本。实验结果如表2所示,从检测正确率上可以看出,如果仅考虑对不同说话人的同一个浊音音素进行检测,采用MFCC 参数和FCC 参数都获得了较高的正确率;但如果考虑对不同说话人的不同浊音音素进行检测,则采用MFCC 参数和SVM 的人声检测正确率下降到67.4%,而采用FRC参数和SVM 的人声检测正确率虽然有所下降,但仍高达92.6%。
4 结 语
VDR 人声检测需要对语音和其他声音进行区分,它并不像一般的语音识别研究那样在已知该声音是语音的前提下研究语音的某一方面特征,而是要研究语音区别于其他声音的特征。语音有规律的谐波成分和共振峰是人类发音的一个显著特点。本文从语音的共振峰和谐波中提取特征参数,并利用SVM 分类器进行二元分类判别,获得了较好的检测效果。
[1]GDXXX-2001 船载航行数据记录仪检验指南[S].中国船级社,2001.
GDXXXX-2011 Testing guide for shipborne voyage data recorder[S].Chinese Maritime Office,2001.
[2]IEC61996:2000 (E).Shipborne voyage data recorder(VDR)-performance requirements-methods of testing and required test results[S].IEC,2000.
[3]鲍长春.数字语音编码原理[M].西安:西安电子科技大学出版社,2007.13-16.
BAO Chang-chun.Principles of digital speech coding[M].Xi′an:Xi′an Electronic Technology University Press,2007.13-16.
[4]赵力.语音信号处理[M].北京:机械工业出版社,2005.76-80.
ZHAO Li.Processing of speech signals[M].Beijing:Mechanism Industry Press,2005.76-80.
[5]王晓亚.倒谱在语音的基音和共振峰提取中的应用[J].无线电工程,2004,34(1):57-59.
WANG Xiao-ya.Cepstrum usage for pitch and formant detection[J].Radio Engineering of China,2004,34(1):57-59.
[6]成新民.情感语音信息中共振峰参数的提取方法[J].湖州师范学院学报,2003,25(6):76-80.
CHENG Xin-min.The method analysis of formant parameters picked-up in sensibility speech communication[J].Journal of Huzhou Techers Colloge,2003,25(6):76-80.
[7]张晓雷.基于支持向量机与多观测复合特征矢量的语音端点检测[J].清华大学学报(自然科学版),2011,51(9):1209-1214.
ZHANG Xiao-lei.Support vector machine based VAD using the multiple observation compound feature[J].Journal of Tsinghua University(Science and Techonology),2011,51(9):1209-1214.
