基于Lucene的全文检索系统研究与实现
2013-11-29钟锋
钟 锋
(浙江外国语学院科学技术学院,浙江杭州310012)
1 引言
信息与网络技术的飞速发展使得电子文档、网站、数据库等数字资源越来越呈现出海量特点.如何从海量信息中快速、准确地搜索用户感兴趣的信息,已成为当前信息领域研究的一个热点[1].全文检索技术可以高效地实现对海量文本数据的快速查询,大大提高了检索的效率[2].Lucene是Apache软件基金会的一个开源全文搜索引擎工具包,提供了完整的查询引擎、索引引擎及部分文本分析引擎.本文在详细研究Lucene源代码的基础上,针对其中文分析引擎的弱点,对中文分词算法进行了改进,并将其应用到全文检索系统中,取得了良好的效果.
2 全文检索系统体系架构
本文构建的是一个支持多文档格式的全文检索系统,系统主要有四个模块构成,自下而上分别为文档归一化模块、文本分析模块、数据存储模块和查询接口模块(见图1).

图1 支持多文档格式的全文检索系统架构
系统将待检索的每一篇文档的相关信息统一存储到数据库中并为其全文建立倒排索引.当用户要查找包含某一关键字的文档时,利用查询接口模块在建立好的索引和数据库中进行查询,得到相应结果.
2.1 文档归一化模块
文档归一化模块主要完成对待检索文档的预处理,主要有两个功能:一是支持将.pdf,.ppt,.doc等文本解码并转化为.txt文件;二是对文本内容进行过滤,取出可能存在的非法字符和乱码.
2.2 文本分析模块
文本分析模块主要实现对元文件文档附属信息的提取存储和通过文本分析器对中文内容的分析与构建倒排索引.文档相关附属信息(如作者、时间、单位、文件存放目录等)直接存储在数据库中;而对于摘要内容和正文内容信息,由于信息量较大,我们通过文本分析器实现中文自动分词,再利用Lucene的索引模块实现倒排索引的自动构建.Lucene自带有中文自动分词系统,但性能一般,为此我们将在下文给出了一种新的基于字典的中文分词方法用作文本分析.
2.3 数据存储模块
数据存储模块实现数据库信息和索引信息的存储.数据库采用开源的MySQL,索引的存储直接利用Lucene索引模块,该模块定义了一套以8位字节为基础的索引文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件.在传统全文检索引擎的倒排索引的基础上,实现了分块索引,能够针对新的文件建立小文件索引,提升索引速度.然后通过与原有索引的合并,达到优化的目的[3].
2.4 查询接口模块
查询接口模块负责实现用户的查询与反馈.查询接口支持两种查询模式:数据库查询和索引查询.索引查询使用Lucene自带的查询器,默认支持布尔查询、模糊查询和分组查询.
3 核心模块设计与实现
3.1 文本分析器模块实现
文本分析器的主要功能用来实现中文分词.中文分词主要是将连续的汉语字序列按照一定的规范重新组合成词序列的过程.成功进行中文分词,可以达到电脑自动识别语句含义的效果,为全文检索奠定良好的基础.Lucene系统自带的中文分词为单字成词算法,即不存在分词,每个字单独成为一个词.在本系统中,为了提高中文检索的效率,我们采用了基于字典的中文分词方法,并将该算法与Lucene框架进行整合应用到全文检索系统中去.
3.1.1 词库与字典数据结构设计与实现
本文采用的词库为Sougou词库,词库大小为1.60MB,即160万字节,相当于40万词左右的词汇容量[4].为了让其能适应我们的分词算法的字典需求,我们遵循词语的长度最小为2,最大为15的原则,按词长对Sougou词库进行分类.
根据词库划分,系统字典结构采用基于字长的顺序存储结构,在字典中使用List结构来维护字长为2~15的单词的SubDictionary,每个SubDictionary字长一致(见图2).
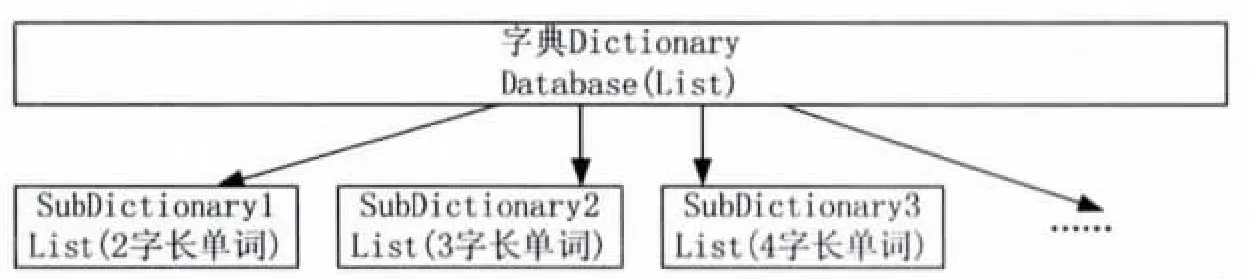
图2 字典数据结构
3.1.2 基于双向最大匹配的中文分词算法
基于字典的分词方法又叫机械分词算法,这种算法按照一定的策略将待分析的汉字串与一个“充分大”的机器词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功,识别出一个词[5].文中,我们提出的匹配算法是正向匹配与逆向匹配相结合的算法,算法流程如下:(1)导入待分词的文本,利用Sougou词库构建按字长构建字典数据结构.然后,将待分词文本按照不同类型(如普通中文字符、英文字符、阿拉伯数字、中文数字、中文日期等)进行分割分类,并放入不同字符块(Block)中.(2)获取当前的字符块进行处理,如果字符块为汉字字符串,则采用正向最大匹配和逆向最大匹配分别进行分词.(3)将正向最大匹配和逆向最大匹配结果进行比较,若返回子串切分数目不同,则采用切分数目较小的结果;若返回子串的切分数目相同,则找出各自切分后的最短子串,采用最短子串长度较短的结果;若最短子串长度相同,则采用逆向匹配的结果.若处理的字符块为非中文字符,则根据人工设定的启发式规则对其进行处理.(4)将分词结果保存到Result集合中,直到所有字符块执行完,打印输出分词的结果(见图3).
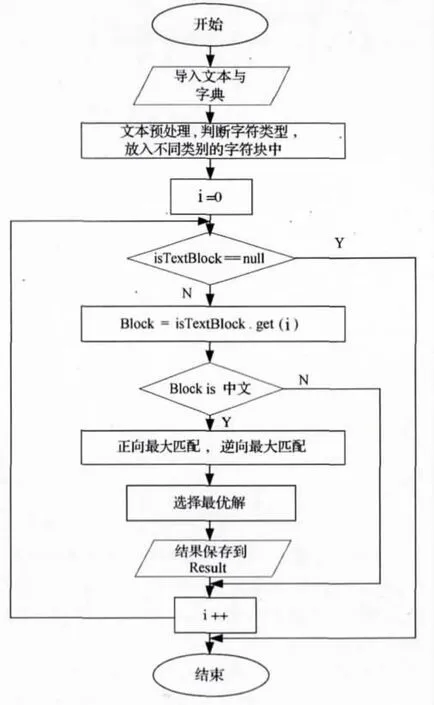
图3 基于双向最大匹配的中文分词算法
3.1.3 分词算法与Lucene的整合
在Lucene中,一个标准的分析器由两部分组成[6]:一部分是分词器 Tokenizer,另一部分是过滤器TokenFilter.一个分析器往往由一个分词器和多个过滤器组成.Lucene分析器中分词器的基类Tokenizer的构造函数接受的Reader对象,表示它直接从外部设备取得数据源.而TokenFilter的构造函数接受的是TokenStream的实例.我们通过可以继承该分析器的基类Analyze并覆盖其tokenStream()方法,从而实现分词器与Lucene的接口封装.
3.2 文档解析器的设计与实现
PDF文档的数据是一系列基本对象的集合:数组、布尔型、字典、数字、字符串和二进制流.开源PDFBox组件可以从PDF文档中抽取信息生成纯文本文档,而Apache开源POI项目则是针对Microsoft Office的多种格式文档实现了信息抽取[7-8].
文档归一化模块主要完成对待检索的多格式文档的预处理.而Lucene组件本身只支持对纯文本文档的开发与应用.针对全文检索系统对多文档格式的需求,我们利用开源PDFBox组件和POI组件对不同文档进行解析,首先转换为纯文本文档,再进一步利用Document接口转换为Lucene架构所能通用处理的Document对象进行处理(见图4).
4 结果与分析
4.1 评价方法及实验结果
我们选用了国际汉语分词评测Bakeoff 2005所提供的标准测试集合.这个集合给出了容量为7.12KB,共7293字节的文本文档和分词的标准结果[9-10].利用文中所设计的分词算法将文本文档进行分词,并和标准结果进行比较,便可知道分词优劣.
对分词的评测结果,我们重点关注P值、R值和F值,公式如下:
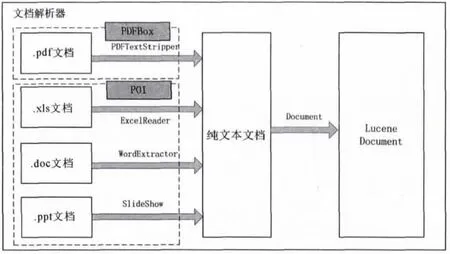
图4 文档解析器实现

其中,P值为准确率,R值为召回率,F值反映的是P值和R值的综合标准.Numc为正确切分词的数量,Numt为总切分词数量,Numh为人工标准结果词汇总量.实验结果如下:(1)最初使用最大匹配分词,不进行文本预处理时,P=74.5%、R=69%、F=71%;(2)重点针对标点符号、“的”字处理、地名处理等预处理过后,P=86.5%、R=84%、F=84%;(3)使用了Sogou词库作为算法字典来源,并加入成语词库及地名词库后,P=89.3%、R=86.7%、F=87.0%.通过对比,我们发现,词库的好坏与规模,对于基于字典的分词方法有决定性的作用,针对特殊词汇的文本预处理也会对分词的结果有一定的影响.通过基于Sougou词库的双向最大分词,我们取得了分词准确率和召回率较为均衡的分词结果,具有一定的使用价值.
4.2 总结与分析
Lucene是一个面向对象的全文索引引擎,文章针对其中文分词的不足,提出了一种基于双向最大匹配的中文分词算法并将其应用到检索系统中去,使全文检索具有较高的文本检索准确率和召回率.但系统依然有较大的改进空间,在后续的研究中,我们将进一步关注:(1)文中分词算法与国际上先进的分词算法相比,P值、R值和F值值依然有较大的提升空间;(2)当文档资源规模进一步扩大时,Lucene索引可以进一步优化,以更好地保证系统的运行效率与稳定性;(3)可以进一步改进对检索结果的排序算法,使用户更加满意结果的呈现.
[1]励子闰.基于Lucene搜索引擎的中文全文信息检索技术的研究[D].上海:华东师范大学,2009:4-6.
[2]岳莉.基于Lucene的全文检索系统的研究与应用[D].西安:西安电子科技大学,2010:5-7.
[3]Lucene Features[EB/OL].[2012-12-21].http://lucene.apache.org/core/.
[4]邱哲,符滔滔,王学松.开发自己的搜索引擎Lucene+Heritrix[M].2版.北京:人民邮电出版社,2010:135-140.
[5]车东.Lucene:基于 Java的全文检索引擎简介[EB/OL].(2011-11-11).http://www.chedong.com/tech/lucene.html.
[6]Gospodnetic O,Hatcher E.Lucene in Action[M].北京:电子工业出版社,2011:98-103.
[7]张盼,聂刚.基于Lucene的全文检索系统的设计与实现[J].电脑知识与技术,2010(1):93-95.
[8]申兵一,巩青歌.基于Lucene的PDF文档文本解析的实现[J].信息与电脑,2009(11):23-28.
[9]汪涛.论基于Java的全文检索实现和索引性能提高[J].湖北民族学院学报:自然科学版,2009(1):49-51.
[10]姚林涛.基于Lucene的Web搜索引擎实现[D].西安:西安电子科技大学,2008:45-48.
