两种PETS计算机自适应序列测试框架比较研究
2013-11-08关丹丹刘庆思
关丹丹 刘庆思
1 引言
全国英语等级考试(Public English Tests System,PETS)是国内目前唯一进行严格题目试测并有现代化题库支持的大规模社会性考试,所有客观题都经过试测和校准,采用的是Rasch测量模型。PETS多级别标准的系统描述处于世界先进之列,5个级别对考生所掌握语言知识和语言能力的要求具有极强的系统性,较高级别涵盖较低级别的要求,并在较低级别的基础上有所拓宽和加深;同时,各级别对考生语言能力的要求建立在同一能力量表之上,他们之间在统计上具有较强的可比性(刘庆思,2006)。
计算机自适应序列测试(Computer-Adaptive Sequential Testing,CAST)是一种既能保持计算机自适应测试的优点,又能坚持专家智慧的设计(Wainer&Kiely,1987;Luech&Nungester,1998),正在成为考试改革的风向标。CAST允许学科专家对考试内容的均衡性、科学性进行把控,有利于提高考试质量;使考生能够继续沿用参加纸笔考试时所采用的答题策略;同时,还使对题池的维护更为方便,能够适当减轻网络和服务器的工作负担(关丹丹& 刘庆思,2010)。
PETS试图在CAST领域进行探索,并开发出相应的测试系统(PETS-CAST),以便为考生提供优质的服务(关丹丹,刘庆思,莫春晖,2011)。那么,适合PETS特点的“最佳”CAST框架是什么?多少个阶段,每个阶段多少个模块,每个模块多少试题,如何计分,以及如何实现适应性选择才能保障对英语水平跨度极大的5个级别进行相对准确的测量?
模拟研究是一种在计算机上进行实验的数学技术,被广泛应用于参数估计、认知诊断、CAT等各个领域,通过模拟研究,可预先获知参数的真实值,然后根据参数估计方法得到其估计值,通过比较不同条件或者不同方法下的估计值与真实值的差异或者其他评价指标,可以检验和比较所开发系统的稳定性与精确度。
为了比较不同PETS-CAST测试框架的效果,研究者根据PETS考试特点设计了两个测试框架,并通过模拟研究对比两种CAST框架的基本性能,检验测试的准确性和可靠性,以期为PETS实现CAST设计奠定坚实的理论基础。
2 PETS-CAST设计
PETS-CAST将对考生在英语语言知识掌握方面和听、读方面的能力进行考查,采用的题型为较适合自适应测试需要的选择题。因写作目前尚无法即时计分,暂时排除适应性过程。研究者按照自适应序列测试理念,将PETS笔试的听力、完形填空和阅读理解三部分作为测试内容,提出PETS-CAST测试的设想,即按测试内容(听力、英语知识运用和阅读理解)分多个阶段测试,每个阶段结束后,适应性地选择下一阶段适合考生水平的试题内容。构成每个阶段的不同模块的题量大小与PETS纸笔测试中该级别该部分的题量保持一致,从而实现对考生在听力、英语知识运用和阅读理解方面的能力进行准确、个性化考查的目的。
根据PETS考试的特点,经语言测量学专家、PETS考试设计者和心理测量学家的讨论,最终提出了两种CAST设计方案:一是采用1-3-5三阶段自适应序列测试框架,二是采用1-2-5-5四阶段自适应序列测试框架,见图1和图2。在1-3-5框架中,每个模板由9个模块构成,组成9条路径。在1-2-5-5框架中,每个模板由13个模块构成,组成13条路径。
PETS-CAST系统会对考生解答每一阶段试题的情况进行分析,估算出其大致的语言能力,然后按照图1或图2所示的测试框架为其投放相应难度(级别)的下一阶段的试题。试题难度恰当与否是根据考生能力确定的。根据PETS各级别合格标准,PETS-CAST为每个阶段结束后确定了选择下一阶段的能力区间,从而为各阶段不同难度(级别)试题的选择奠定了基础,即建立了路径规则。
两种设计的相同点是,在初期的标准确定阶段,所有考生都接受中等难度的PETS三级完形填空模块,都作答完形填空、听力和阅读理解,从而确保英语考查内容的平衡。两种设计的不同点为,除了由于阶段不同、模块数量不同所带来的路径不同外,在能力估计上也做了不同考虑。对于1-3-5设计而言,无论考生最终接受的是哪一路径的测试,其PETS三级完形填空的作答成绩都作为考生初始能力参与后续的能力估计。而对于1-2-5-5设计,PETS三级完形填空作答结束后,若考生的能力判断为在三级范围内,直接进入PETS三级听力模块,且该阶段的能力估计作为初始值参与后续的能力估计;若考生的能力判断低于三级或者高于三级,系统会自动为其抛出PETS二级完形填空或PETS四级完形填空。考虑到初始阶段对考生能力估计的不稳定性,会导致对考生能力估计值向正向或负向推得很远(Rulison&Loken,2009;张华华,2002),因此只将三级完形填空的成绩作为第二阶段的选题依据,不作为初试能力值参与后续的能力估计过程。

图2 1-2-5-5四阶段CAST框架
3 模拟研究设计
为了检验PETS-CAST的基本性能,本研究根据CAST模型的要求编制了相应的模拟程序。
3.1 模型选择
本研究采用Rasch模型。所有试题来自PETS题库,由命题专家组建模块和模板,试题难度参数已知,所有试题均为0/1计分。根据研究需要,组建了两套试题(panel#1和panel#2),模拟过程以panel#1为主,仅在模拟复本重测信度和分类一致性时使用panel#2。
3.2 自适应序列框架
本研究分别采用1-3-5三阶段和1-2-5-5四阶段自适应序列测试框架。
3.3 模拟研究的程序设计
研究采用蒙特卡罗模拟法进行(余嘉元,汪存友,2007)。为此编写了考生能力真值生成程序、自适应序列测试的模拟测试程序和考生能力估算程序。模拟过程如下:首先模拟生成一批考生能力真值,并读入各模块中所有试题的参数;然后,启动自适应序列测试的模拟测试程序,根据既定的路径规则,在相应模块作答结束后,调用适合考生水平的下一阶段的模块,同时根据模拟产生的作答数据采用条件极大似然法不断估算考生能力值,直至考生做完阅读理解模块,测试终止。测试中采用均匀生成随机数的方法来确定考生得分,具体做法是先依据考生能力真值θ和试题难度参数,根据公式算考生 j在试题 i上的答对概率Pji,产生一个RAND(0,1)的随机数Rji,j=1,2,3…N;i=1,2,3…M。如果Pji>Rji,则认为该考生在试题i上的作答正确,令 Xji=1,否则Xji=0。据此,生成考生在每一阶段试题上的做答反应。根据每一阶段结束后考生的能力值、自适应路径和PETS各级别能力范围标准,确定下一阶段投放给考生的试题模块,考生完成阅读理解模块后测试结束。
3.4 模拟数据结构
考生能力水平参数θ服从平均数μ=0,标准差σ=1的标准正态分布。4个样本的模拟能力情况见表1。

表1 考生模拟能力分布
3.5 评价能力估算精度的指标设计
评价能力估算精度的指标有很多,本研究重点关注六个:一是考生估计能力与真实能力的相关,相关系数越高,表明能力估计越可靠。二是能力估算的标准误SE(θ),考生能力估算的标准误平均数小于0.3,即表明测验提供了足够的信息量,整体估算的标准误较为理想。三是测量偏差(Bias),计算公式为利用真实能力值θ与估算能力值̂的平均误差来衡量自适应序列测试系统对考生能力估算的准确性。四是绝对测量偏差(ABS),计算公式为实能力值θ与估算能力值θ̂的误差取绝对值后的平均数来衡量自适应序列测试系统对考生能力估算的准确性;ABS可以排除测量偏差可能有正有负而带来的累加抵消现象。五是均方根误差(RMSE),计算公式为RMSE=利用真实能力值θ与估算能力值θ̂的均方根误差(Root Mean Squared Error,RMSE)评估自适应序列测试系统对考生能力估算的准确度;RMSE利用对测量偏差进行平方处理的原理也同样排除了测量偏差可能有正有负而带来的累加抵消现象。六是分类决策一致性系数(Kappa),对于水平性考试而言,对考生的分类决策准确性和一致性比相关系数更有意义;由于PETS-CAST考试的分类结果有六类:不合格、一级合格、二级合格、三级合格、四级合格和五级合格,需要使用Kappa系数作为决策一致性和准确性的指标。表观察一致率;称为期望一致率。Landis和Koch(1977)将Kappa系数的大小划分了6个区段:K<0,一致性强度极差;0.0~0.2,微弱;0.21~0.40,弱;0.41~0.60,中度;0.61~0.80,高度;0.81~1.00,极强。
4 模拟研究结果与讨论
4.1 模拟能力与估计能力的相关
计算每个阶段结束后考生的能力估计值与其模拟能力值之间的相关,见表2。
由表2可知,随着阶段的增加,考生能力估计值与其模拟能力值之间的相关逐渐增高;样本大小对相关系数没有明显影响。从相关分析来看,1-2-5-5四阶段设计因多一个阶段,最终的能力估计值与模拟能力值之间的相关(平均为0.968)要高于1-3-5三阶段设计(平均为0.961)。
4.2 能力估计标准误
计算每个阶段结束后考生能力估计的标准误,见表3。
由表3可知,随着阶段的增加,考生能力估计值的标准误逐渐减小,样本大小对估计标准误没有明显影响。不同样本下,1-2-5-5四阶段设计最终的能力估计标准误都小于0.180,好于1-3-5三阶段设计(测量标准误平均为0.202)。
4.3 测量偏差、绝对测量偏差与均方根误差
计算能力估计的测量偏差、绝对测量偏差与均方根误差,见表4。
由表4可知,样本大小对测量偏差、绝对测量偏差与均方根误差没有明显影响。就绝对测量偏差和均方根误差而言,1-2-5-5四阶段设计好于1-3-5三阶段设计,准确性更高。
4.4 重测信度与复本重测信度
根据最初生成的四个样本量大小不同的考生群体的能力真值,利用蒙特卡罗模拟方法,再次模拟考生在两种CAST框架(1-3-5和1-2-5-5)上的作答反应,两次能力估计的相关即为重测信度。
另外,原考生群体能力真值不变,换一套试题(panel#2)后,利用蒙特卡洛模拟方法,生成考生在两种CAST框架(1-3-5和1-2-5-5)上的作答反应,两次能力估计的相关即为复本重测信度,见表5。
由表5可知,样本大小对重测信度与复本重测信度没有明显影响。就重测信度而言,1-2-5-5四阶段设计好于1-3-5三阶段设计,可靠性更高;两种设计的复本重测信度基本相当。
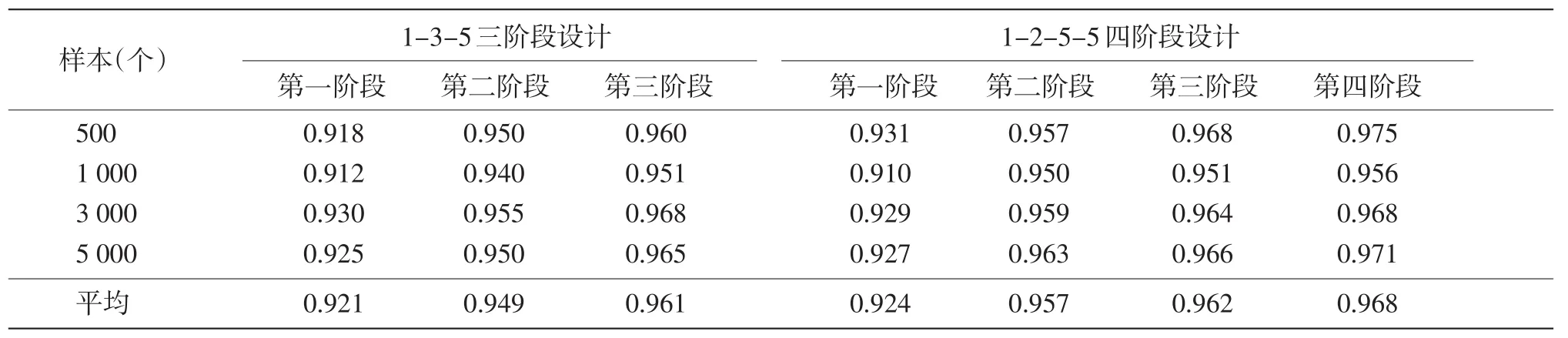
表2 各阶段能力估计值与模拟能力值相关
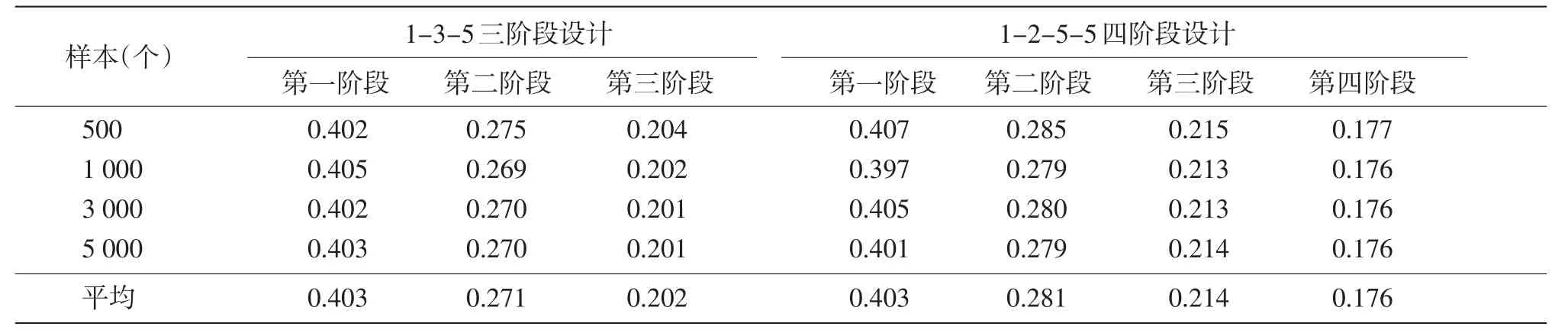
表3 各阶段能力估计的标准误
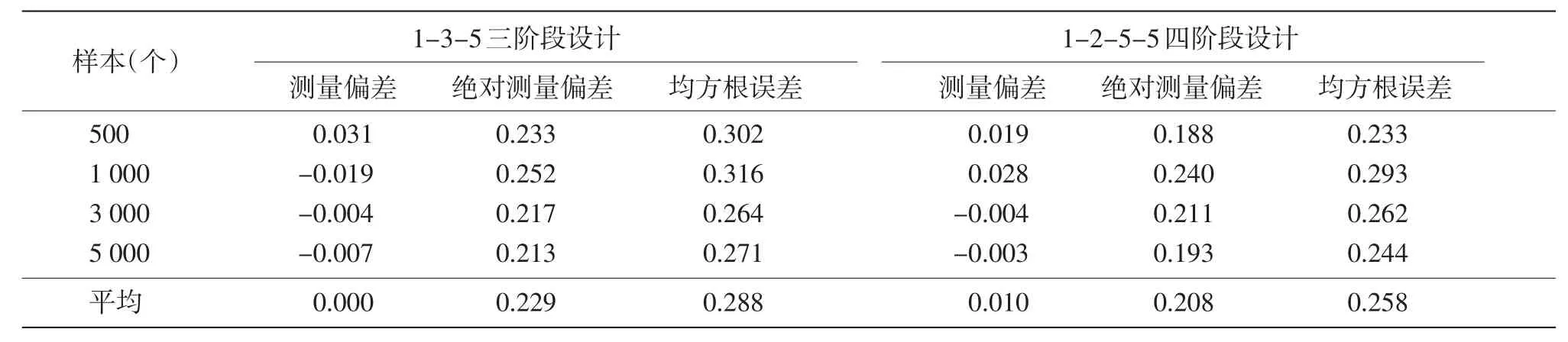
表4 测量偏差、绝对测量偏差与均方根误差
4.5 分类准确性与一致性
根据考生的模拟能力值与估计能力值分别对考生的英语水平进行分类后(0/1/2/3/4/5),可以计算Kappa系数,作为CAST测试对考生的分类准确性指标;另外,根据对同一批考生模拟的复本重测情况,基于两次测试的估计值对考生的英语水平进行分类(0/1/2/3/4/5),可以计算Kappa系数,作为两次测试对考生的分类一致性指标,见表6。
由表6可知,样本大小对分类准确性与一致性没有明显影响。就Kappa系数而言,两个框架的决策准确性均在0.6以上,准确度较高;但两次测试的分类一致性则在0.50以上,属于中度一致。
5 总结
模拟研究结果表明,无论是哪种测试框架,PETS-CAST测试随着阶段的增加,都提供了更多的测验信息,能力估计的标准误逐渐减小,模拟能力与估计能力呈现出高相关。而且,能力估计的测量偏差、绝对测量偏差和均方根误差均比较小,显示了PETS实现CAST设计的准确性较高。另外,模拟研究还显示,PETS-CAST的重测信度和复本重测信度很高,均在0.90以上。依据PETS-CAST成绩对考生的英语水平进行分类的准确性在0.6以上,两次测试的分类一致性在0.50以上,说明基于PETS-CAST测试对考生进行分类比较准确、可靠。样本量大小对模拟效果影响不大。这说明在选择真实考生试测时,只要样本分布合理,不必选择过大样本量就可获得可靠的结果。
就两种PETS计算机自适应序列测试框架比较而言,从测量指标来看,1-2-5-5框架因增加了一个阶段,提供了更多的测验信息量,对考生能力估计及分类决策的准确性更高,结果更为可靠;从对两端考生的测量精度考虑,尽管1-3-5测试框架也能提供比较好的测量结果,但考虑到PETS考试跨度极大,研究者认为对两端考生的测量(路径345和路径321)从内容契合性上不如1-2-5-5框架(路径3455和路径3211)适应性强。从考试的适应性和考试的高利害性来看,PETS考试属于高利害考试,1-2-5-5框架适应性更强,对考生的测量更准确,更符合高利害考试的诉求。
综上,研究者认为,相对于1-3-5三阶段测试框架,PETS-CAST采用1-2-5-5四阶段测试框架更为合理。下一步将在真实考生中对PETS-CAST测试系统进行反复试验,以进一步检验其测试性能。
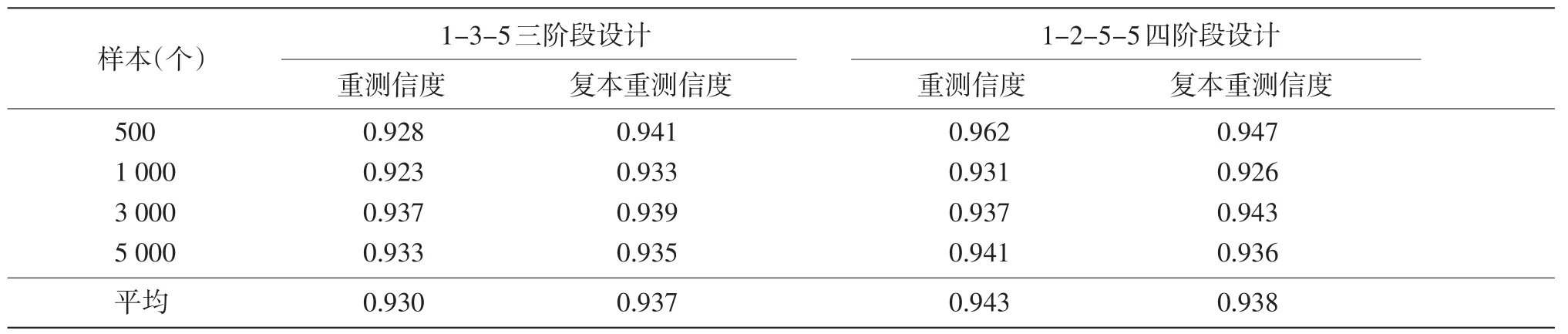
表5 重测信度与复本重测信度
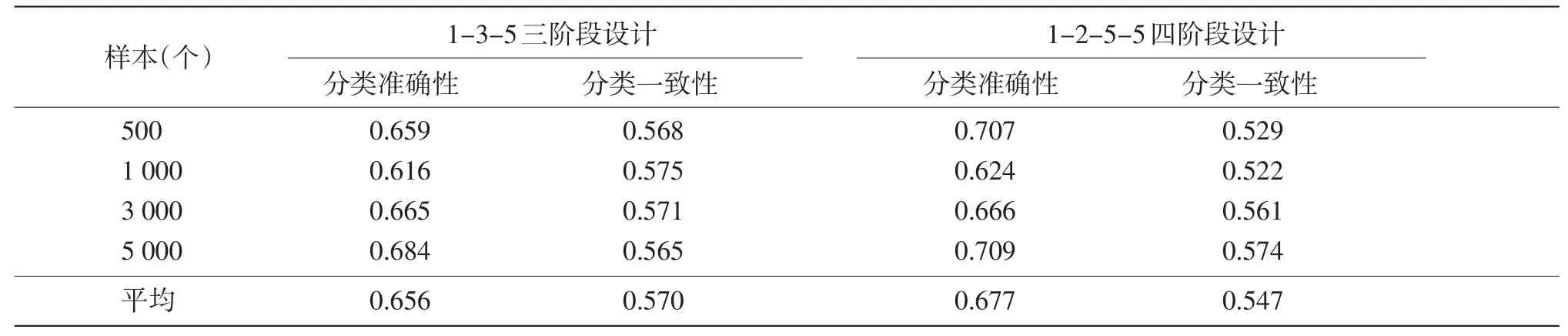
表6 分类准确性与一致性(Kappa系数)
[1]关丹丹,刘庆思.计算机自适应序列考试概述[J].中国考试,2010(1):29-35.
[2]关丹丹,刘庆思,莫春晖.PETS计算机自适应序列测试设计与模拟研究[J].心理学探新,2011,31(5):467-471.
[3]刘庆思.英语等级考试题库介绍[J].中国考试,2006(12):21-24.
[4]张华华.计算机自适应考试设计中的误区[J].考试研究,2002,第二辑:35-39.
[5]余嘉元,汪存友.项目反应理论参数估算研究中的蒙特卡罗方法[J].南京师大学报(社会科学版),2007(1):87-91.
[6]Landis J.R.&Koch G.G.The measurement of observer agreement for Categorical data.Biometrics,1977,33,159-174.
[7]Luecht,R.M.,Nungester,R.J.Some practical examples of computer-adaptive sequential testing.Journal of Educational Measurement,1998(35):229-249.
[8]Wainer H.,Dorans N.,Eignor D.,Flaugher R.,Green B.,Misley R.,Steinberg L.&Thissen D.Computerized adaptive testing:A primer[M].Hillsdale,N.J.:Lawrence Erlbaum,2nd ,2000,166.
[9]Rulison,K.,&Loken,E.I’ve fallen and I can’t get up:can high-ability students recover from early mistakes in CAT?Applied Psychological Measurement,2009,33(2),83–101.
