一种基于字典的快速分形图像编码方法
2013-09-29孙媛媛孔瑞卿
孙媛媛,孔瑞卿
(大连理工大学计算机科学与技术学院,辽宁 大连 116024)
1 概述
图像压缩技术是解决图像传输和存储的主要途径之一,利用图像压缩可减少图像在传输和存储中的网络负担,使图像可以在网络上快速传输和实时处理。目前有多种图像压缩方法,按照在编码过程中是否存在信息损耗可以将它们分为2类:无失真编码和限失真编码。无失真编码在实际应用中一般不能达到很高的压缩比,因此,在实际应用中一般采用限失真编码。一般的限失真编码主要包括DPCM、DCT、VQ等,这类方法一般是以独立的像素和图像块作为编码对象,没有考虑到图像本身的结构特点和频率分布特性[1]。
分形图像编码是根据现实图像具有自相似性来实现图像的一种有损编码方法。利用分形实现图像压缩的思想由 Barnsley于 1988年提出,并由其学生Jacquin提出可用于实际的编码方法[2]。分形图像编码有许多优点,如具有与分辨率无关的解码特性,编码过程简单,解码过程无需搜索,并突破以往熵压缩编码的界限。但同时分形图像编码也有自己的缺点,如编码时间过长,容易出现方块效应,压缩比通常在10左右,并不能达到分形理论上的压缩比,且压缩比率仅与值域块的大小有关。
由于分形编码本身是一种有损编码,因此在保持图像质量的前提下,尽量加快编码速度是分形编码研究的一个重要内容。近年来,许多专家和学者对分形图像压缩算法进行了研究和改进,并取得了一定的效果,如利用特征向量快速分形编码[3]、基于行列式的匹配查找算法[4]、与小波变换结合的算法[5]、基于子块特征分形编码[6]、基于四叉树查找算法编码[7]等,但这些算法均倾向于在原图中的定义域块内进行查找。
在采用字典进行分形编码的算法研究方面,文献[8]将量化的Julia曲线用于图像压缩编码。文献[9]利用复平面M集结合Logistic映射建立了常用压缩编码字典,图像的定义域块即取自字典。文献[10]提出一种基于 Julia-CK 集和 Logistic映射的非线性分形压缩算法,该算法通过对Julia-CK集图像块的圆盘变换,能得到更为丰富的压缩字典。上述编码算法均以M-J集为压缩字典,字典固定且数量较少,能够加速编码时间,但解码效果不如仿射变换(传统编码采用的方法)的效果好。影响解码效果的因素主要在于字典不够丰富,以及图像中的值域块直接由字典图像中的定义域块替代。
针对上述问题,本文提出一种新的编码方法,使用一种新的字典生成算法,生成一个合适的字典文件,以改进图像的编码效果和编码速度。
2 基本方法
本文主要是基于离散局部迭代函数系统(DLFS)进行图像编码,其基本思想如下:图像被分成大小2类子块,这些子块作为一个矩阵存储图像中的元素,并记大块为Di和小块为Ri,小块Ri互不重叠且覆盖整幅图像,一般称 R块为定义域块。大块 Di尺寸一般取Ri块的 2倍,且可以相互重叠,一般称 Di块为值域块。称 Di块的集合为码本,对每一个 Di块采取四邻域元素平均法得到的与 R块相同大小的像素块。
设有一个N×N的灰度图像,可以把一幅图像I看成一个灰度矩阵(Ii,j)N×N,其中 I(i,j)表示图像在(i, j)处的灰度值。假定有2个大小相同的图像XN×N、YN×N,定义 d是作为失真判据的完备度量,在 DLFS中称d为匹配范数,d的计算公式如下:

其中,s和o分别表示亮度调整和亮度偏移,因此,分形编码的过程主要是寻找最小匹配范数的过程。利用最小二乘法,可以计算出,当 s和 o满足式(2)和式(3)时,匹配范数d可以取到最小值。

解码过程是一个相对简单的迭代过程,每次迭代过程需要的码本是由上一次迭代的结果提供的,初始图像可以任意指定,迭代过程如下:
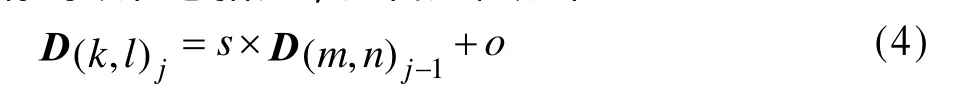
D(m,n)j代表在 j次迭代后产生的结果在点(m, n)处的像素值。一般进行 7次~8次迭代即可得到原图像。
3 基于字典的图像编码方法
传统的分形编码过程中主要有 2个过程比较耗时:(1)定义域块的生成,在每一次对图像进行编码时都要在原图的基础上重新生成定义域块,定义域的数量会随着图像的大小而加速增加。(2)查找编码块,对于用原图生成的定义域块,利用全搜索方法来查找合适的定义域块,这样搜索会大大增加其计算时间。而在解码的过程中,由于要采用迭代的方法,而计算机在保存数据时有精度丢失问题,在每次迭代的时候都会产生一定量精度损失问题,在多次迭代的过程中这些误差会累积,因此解码过程中就不可避免的产生迭代误差。考虑到分形解码过程中,初始图像与最终解码图像无关,可以在分形图像编码的过程中采用固定定义域池的方法,称这个固定定义域池为字典,在编码过程中,对于原图中每一个值域块,只需要在字典文件中查找具有最小匹配范数的定义域块,而不需要对每一幅图像生成一次定义域块集合。
同样在解码的过处程中无需迭代,只需要找到相应的定义域块,做一次运算即可完成解码过程,不会产生迭代误差,同时也加快了解码的速度。编解码系统如图1所示。
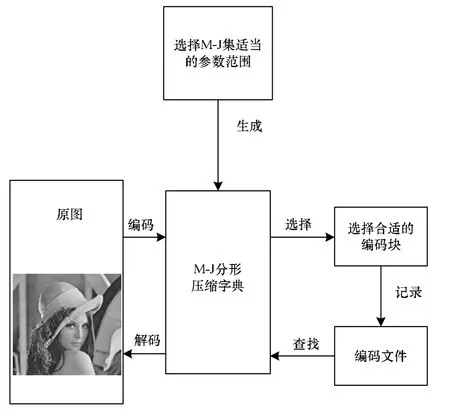
图1 编解码系统
3.1 字典生成算法
分形图像利用较少的参数集合,就可以生成纹理比较复杂的图像,因此,本文选取分形图像作为字典的生成图像。M集和 Julia集(简称 J集)是传统的分形图像。对于 J集来说,其生成参数都可以体现在M集中,利用M集可以方便的构造出多种生成参数下的J集,并且其可在不同的尺度上重复出现自身的结构。因此本文主要结合 Julia集生成字典图像,生成字典的过程中选取 M集上不同的点生成丰富多变的J集图像。算法步骤如下:
(1)生成参数:利用标准的 M集生成J集的生成参数集合,记为 ΦN,其中,N是选取的可生成 J集参数的个数。
(2)生成J集:利用逃逸时间算法,对每个参数生成一个M×M大小的J集图像,并在生成的过程中记录每个点的迭代次数,记为V(k,l),如下式所示:
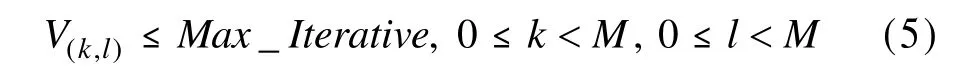
其中,Max_Iterative表示最大的迭代次数。
(3)量化分形图像:得到一幅M×M的J集图像后,对图像中每一个 V(k,l)值乘以一个整数值 H,可以得到一个J集图像,选取不同的H值,就可以得到多种不同的图像。因为实验只要求灰度图像,所以在计算中要对256求模。
(4)生成定义域块:对每一个图像采用四元素平均法,得到一组灰度图像,每一个灰度图像块称为定义域块,把所有定义域块存放到一个字典文件中。
本文在选取 J集参数时,只选择位于 M集边界的点,这样可以使得生成的图像中具有较多的纹理块。字典生成后,为保证字典的充分有效性,对字典进行以下优化:
(1)字典内定义域块的数量,字典内的定义域块数量必须达到一定的数量,这样才可以充分地保证字典对于尽可能多的图像值域块都可以找到合适定义域块。同时,图像的编码速度同和字典块的数量有正比例关系,因此,也要保证字典内定义域块的数量不可以太多,保证编码速度。
(2)冗余性改进,由于 M集图像自身相似性,因此在生成字典中,也存大一定数量的相似块,可以把它们认为是重复块,这时可以通过一定的方法来去除掉这些重复块,使得字典冗余度尽量降低。
(3)字典要尽量覆盖很多种类的图像。在速度可以得到保证的情况下,使得字典内的定义域块尽可能丰富,这样才可以保证对于任意图像都可以得到较好的编码文件。
3.2 编码算法
编码算法描述如下:
(1)加载字典:将在3.1节生成的字典中的每一个定义域块Ti加载到内存中,构成码本块池TN。
(2)分割图像:将待编码的图像划分成互不重叠的值域块Ri,构成值域块池R。
(3)获取分形码:对于 R池块中的码块,在码本池块中查找其最好的匹配块Tm(i),使这两块之间的匹配范数d(Rj,Tm(ij))最小,可以按以下步骤查找:
1)对于每一个Ti∈TN,计算Rj与Ti的对比因子 s和亮度o。
2)计算它们的匹配范数,如果匹配范数小于当前最小的匹配范数,则记录当前的匹配范数,与相应的编码参数,包括定义域块在字典文件中的位置,相应的对比因子s和亮度o。
3)输出具有最小匹配范数的分形码参数。
(4)对每个 Ri中的块进行编码,重复进行第(3)步,直到R中所有块均完成。
(5)输出分形编码参数,就可以得到分形编码文件。
3.3 解码算法
解码时需要读入分形编码参数文件,对记录的参数采用解码算法。因为字典固定,所以在解码过程只要迭代一次,即可完成解码的过程,解码算法描述如下:
(1)加载字典:图像文件中编码字典加载到内存中去,同样按8种仿射变换,对内存中的定义域块进行扩展。
(2)加载编码文件:读取编码文件中的编码参数,包括在字典文件中的偏移量,对比引子和高度。
(3)恢复原图:对于读入每一组参数,利用式(5)解码,把解码后的8×8值域块放到对应的位置。
(4)输出图像文件。
4 实验结果与分析
为验证上述算法的有效性,本文随机选择3幅大小分别为512×512像素和256×256像素2组图像进行实验,由于分形图像压缩率和值域块大小存在线性关系,对于大小相同值域块,其压缩率相差不大,因此本文把峰值信噪比和运行时间作为要的比较参数。峰值信噪比(Peak Signal to Noise Ratio, PSNR)定义如下:

本文实验选取的J集的映射公式如下:

本文在实验中选取的 3幅图,分别是 Lena、Peppers和 Elain,并使用传统的分形编码结果进行比较。
实验最后生成的字典具有定义域块数为3 086块,分别利用本文算法和传统算法对 512×512像素和256×256像素大小的图像进行实验得到结果如表1和表2所示。解码后的图像如图2所示。

表1 对512×512像素图像编码后的PSNR及时间
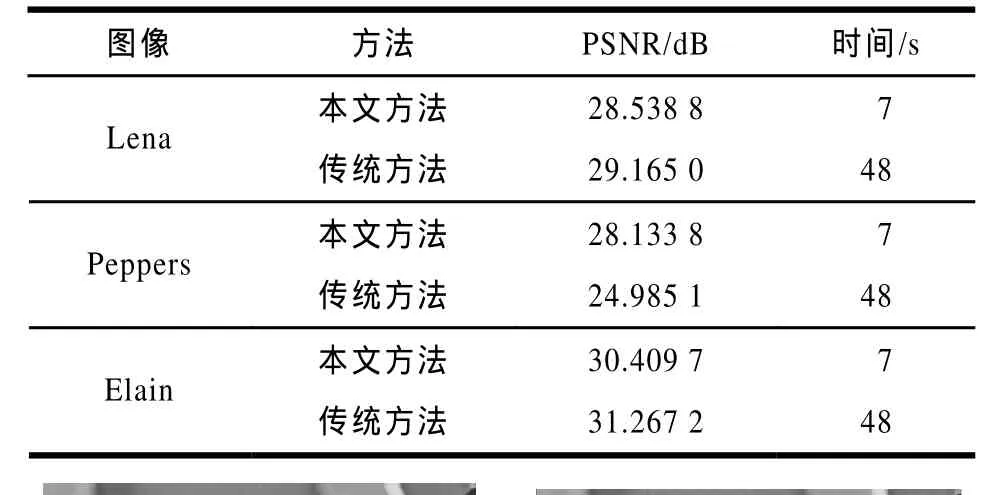
表2 对256×256像素图像编码后的PSNR及时间

图2 解码效果
由表1和表2的比较结果可以看出,在不降低图像质量的前提下,利用字典进行图像编码可以大幅降低运行时间,速度优势在图像尺寸较大的情况下更为明显。伴随图像尺寸的增大,编码时间增加的幅度也很小,而传统分形编码在图像大小增加的同时,也会大幅度增加编码时间。
5 结束语
本文提出了一种基于字典进行图像压缩编码的方法,该方法的优势在于利用固定的字典作为定义域块,改善了匹配进程,使得对不同图像可以使用同一个固定字典集。实验结果表明,利用字典作为图像的码本,在保证图像质量的情况下,可以大幅提高编码速度,减少编码时间,尤其对于大图片进行分形编码,更能显示出算法在时间上的优越性,因此,该算法的实用性较高。下一步工作是改进字典内的查找算法,进一步提高编码速度。
[1]李高平.分形法-图像压缩编码[M].成都: 西南交通大学出版社, 2010.
[2]Jacquin A E.Fractal Image Coding: A Review[J].Proceedings of the IEEE, 1993, 81(10): 1454-1461.
[3]刘 明, 叶正麟, 陈作平.基于二维特征向量的快速分形编码方法[J].计算机工程与应用, 2007, 43(8): 82-84.
[4]何传江, 刘维胜, 申小娜.基于行列式的快速分形图像编码算法[J].中国图象图形学报, 2008, 13(3): 435-439.
[5]Qu Xilong, Dai Mian, Li Zhenhui.Research and Implementation of Fast Image Fractal Coding Algorithm[J].Advanced Materials Research, 2010, (34-35): 1360-1364.
[6]吴晓燕, 刘希玉, 徐 庆.基于子块特征的快速分形图像压缩算法[J].计算机系统应用, 2010, 19(1): 176-179.
[7]Moreno J, Otazu X.Image Coder Based on Hilbert Scanning of Embedded QuadTrees[C]//Proceedings of Data Compression Conference.[S.l.]: IEEE Press, 2011.
[8]朱志良, 赵德平, 朱伟勇.“Julia曲线”与分形图像压缩编码[J].中国科学院研究生院学报, 2002, 19(2): 177-181.
[9]赵德平, 彭 鹏, 张东伟.基于Mandelbrot集和Logistic映射的分形图像压缩编码[J].计算机工程与设计, 2008,29(11): 2851- 2856.
[10]郑 莹, 李光耀, 孙燮华.一种新的非线性分形压缩方法[J].计算机工程, 2008, 34(11): 21-22, 25.
