自然语言语义相关度计算模型的k枝剪求解法
2013-09-11刘运通梁燕军
刘运通,梁燕军
(安阳师范学院 计算机与信息工程学院,河南 安阳455000)
0 引 言
当前,由于自然语言处理这个难题没有得到很好的解决,越来越多的研究者在探索如何充分地利用语义信息,来取得更好的处理结果。
语义的作用越来越被重视,不少研究者使用Wordnet、Hownet、Framenet等词汇语义知识库作为语义分析的基础性资源[1];文献 [2]研究了基于依存树距离的语义角色标注方法;HPSG方法研究了基于词汇语义信息驱动的语句处理方法[3];文献 [4]研究了将语料树库与framenet相结合的介词短语消歧;文献 [5]研究了在线语义资源的词汇语义消歧;文献 [6]研究了如何利用 Woednet来提高词汇语义消歧的性能。这些研究取得不少成果,但还没有形成一套系统地利用语义信息进行自然语言处理的模型和方法。
为了能够更为合理地利用语义来进行自然语言处理,本文提出了一种自然语言语义相关度计算模型及该模型的k枝剪求解法,分析了语句的两层语义结构并给出其数学描述方法,采用自底向上的简单句归结法来进行模型求解。
1 语句的语义相关度计算模型
假设一个语句 (CS)中的任意实词 Wi(除去谓语中心词)均语义修饰于另外一个实词WGi,称WGi是Wi语义修饰目标,用函数match(Wi,WGi)来表示其语义相关度。
假设语句CS有m种不同的语法分析方案,在其中第i种语法分析方案Ai的情况下:假设V为谓语中心词,S为V的施动者,O为V的承受者,Wi是语句中的一个实词且!(Wi∈ {S,V,O}),WGi是 Wi的语义修饰目标,那么,语句的语义相关度fAi(针对语法分析方案Ai)可以用式 (1)来表示 (见图1)

S和O的语义修饰目标是V,n是实词的个数 (不包括S、V、O),KSVO为权值系数 (KSVO>1),KSVO应正比于语句的长度。

图1 语义相关度计算模型
值得注意的是:虚词不参与计算,副词、代词、数词、量词被按照实词计算。
最佳结果选择规则:假设一个语句具有m种语法分析方案,最符合语义逻辑的语法分析方案Ai满足式 (2)的条件

即语义相关度最大的语法分析方案是最佳语法分析方案。
2 语句的两层语义结构及描述方法
为了进行语句分析,根据语义结构的复杂程度,将语句划分为两个层次:简单句、复杂句。
(1)简单句:没有从句的语句CS,用文法G1来描述 (表1)。
G1的设计思路 (见图2):假设V是谓语,S是V的施动者,O是V的承受者,AB是前置定语,AA是后置定语,PD是状语或补语,相当于格语法[7]中的一组格,PC是一个的格内容。
(2)复杂句:包含从句的语句CS,在文法G1中添加规则L→CS,形成文法G2。所添加的规则L→CS说明一个简单句可以作一个复杂句中任意成分,实现了对简单句递归,因此文法G2可以描述复杂句。
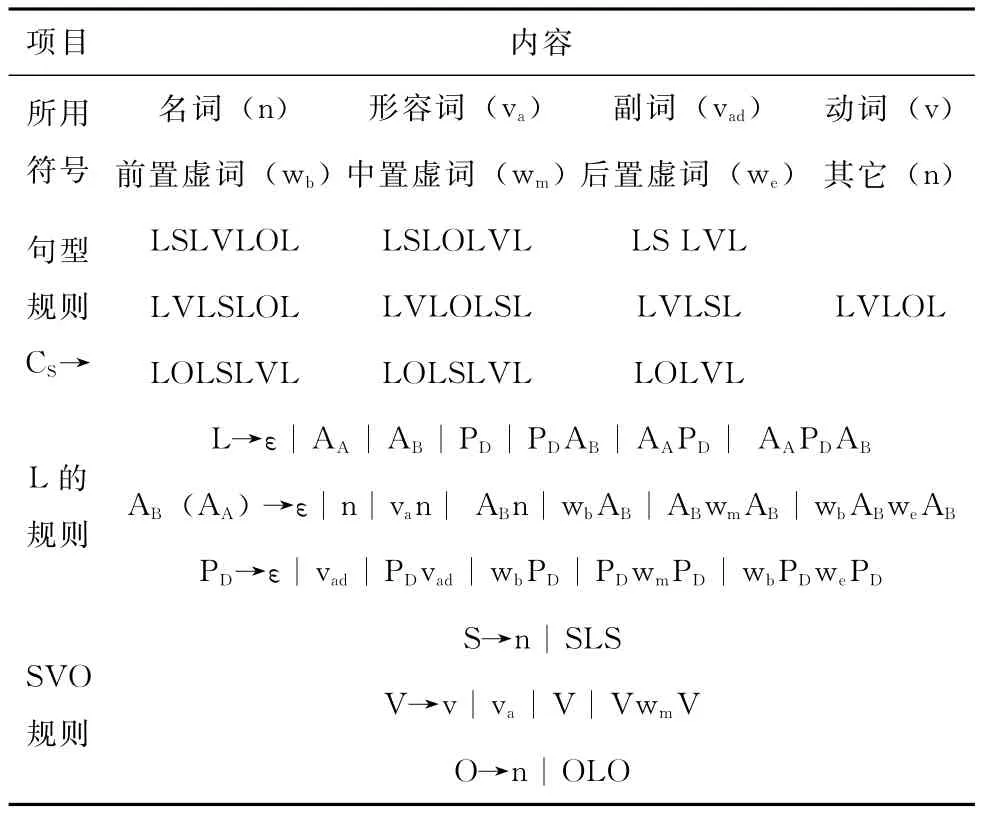
表1 文法G1的内容
3 语句分析计算过程
3.1 自底向上的简单子句归结法
在计算过程中,每次选择一个简单子句 (从句),将其归结为L,反复进行,直至整个语句成为简单句,具体方法如下:
步骤1 (数据预处理):使用ICTCLAS算法[8]进行分词,并获得其词性;
步骤2 (找到所有子句):针对语句CS,进行文法G1的CYK算法[9]的运算,可以找出满足文法G1的简单子句集合 {CS1、CS2……CSm},如图3所示;
步骤3 计算每个子句的最佳语义相关度,选择计算结果最佳的简单子句CSi,归结CSi;
步骤4 假如语句CS还不是简单句,则重复步骤2、3;否则,计算简单句CS的最佳语义相关度。

3.2 简单句的最佳语义相关度
3.2.1 词汇间的语义相关度
针对一个树状词汇语义库 (在本文的实验中,采用了hownet),两个词汇Wi与其语义修饰目标 WGi之间的语义相关度可用式3计算
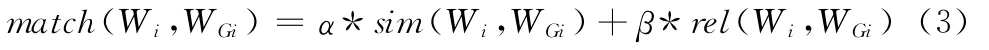
sim(Wi,WGi)表示它们之间的语义相似度,rel(Wi,WGi)表示它们之间的语义关联度,且系数α+β=1,具体细节可参考文献 [10]。
3.2.2 SVO的多个选择方案
在计算简单句的最佳语义相关度时,需要先确定SVO的位置,对于简单句,一般情况下,V的位置是确定的,而S和O的位置不易确定,在进行最佳语义相关度计算时,具有多个不同的选择方案,如图4所示。
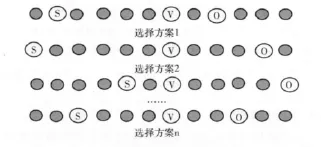
图4 SVO的多个选择方案
3.2.3 分段L的多个语义修饰方案
SVO的位置确定后,需要针对每个分段L,确定出L中的每个词汇 Wi的语义修饰目标 WGi,并计算出每一组match(Wi,WGi)的值,并求和。显然,L中具有多个不同的选择方案,如图5所示。

图5 分段L的多个语义修饰方案
3.3 k枝剪法
k枝剪法实质上是贪心法的一种变形和推广,每当面临多种选择时,贪心法仅仅选择一种当前最佳方案,进入下一阶段的搜索;在本文的k枝剪法中,每次选择k个最佳方案,进入下一阶段的搜索,舍弃了其余的可能较小的方案。
3.3.1 k枝剪法原理
从3.1和3.2的分析中,可以看出:
(1)每次子句归结时,都有多种备选方案;
(2)每次确定子句的SVO时,也有多种备选方案;
(3)针对每个分段L,也有多种备选方案。
整个求解过程,会形成了一个状态空间树。假如我们穷举计算每种备选方案,在理论上,我们可以找到最符合语义逻辑的语法分析方案。但这种方法,在计算复杂度上是很难实现的。
为了解决这个难题,我们采用了k枝剪法进行计算,可以求得一个近似解,具体方法是:
每当碰到有多种备选方案的情况,都不再进行穷举式样的搜索,而是仅仅选择k个可能性最高的方案进行计算,从而可以极大地降低计算复杂度,当然,所得到的结果是一个近似结果,其原理可以用图6表示。
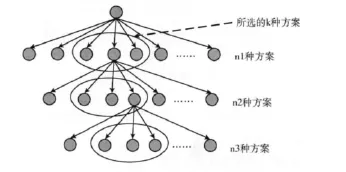
图6 k枝剪 (k=3)
3.3.2 枝剪函数
整个求解过程,形成了一个状态空间树,在对状态空间树进行搜索时,需要有一个枝剪函数,针对状态空间树中的每一层,来选定该层的k个最佳备选方案;舍弃其余的备选方案。在计算过程中,我们选用平均语义相关度来作为枝剪函数见式 (4)

在搜索状态空间树时,目标分段L(可能是一个从句)可能有多种语法分析方案 {A1,A2…,Am},n是L中词汇的个数,fAi(L)是L在语法分析方案Ai情况下的语义相关度,通过公式 (3),可以计算出m个语义相关度 {fA1(L),fA2(L)… (L)fAm(L)},选择其中最大的k个所对应的状态,进入下一步的搜索。
4 实验结果及分析
本文的实验中,以hownet作为词汇语义计算时所依据的资源。实验分为两个阶段:
(1)KSVO取值实验;
(2)枝剪过程中k取值的实验。
4.1 KSVO取值实验
首先,由于SVO的重要性要比普通的词汇大,因此需要通过实验,来确定KSVO的取值。进行7组实验,分别设定KSVO=0.9n,0.8n,0.7n,0.6n,0.5n,0.4n,0.3n (n是语句中的词汇个数),选取100个简单句 (可以降低计算复杂度,不影响计算结果),采用完全搜索法求解;实验结果见表2;根据实验结果,可以画出KSVO取值与正确率之间的关系图7。

表2 KSVO取值与正确率的实验结果
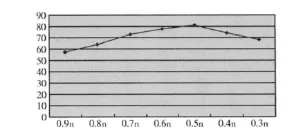
图7 KSVO取值与正确率的关系
由实验结果可知,KSVO取0.5到0.6之间的值,正确率可以到达最大。
4.2 枝剪过程中k取值的实验
显而易见,k的值越大,计算越复杂,结果越正确。因此需要通过实验,来确定k的值。进行5组实验,分别设定k=2,3,4,5,6;选取100个复杂句,采用k枝剪法搜索法求解 (设KSVO=0.55)。实验结果如下:
4.2.1 k的取值与平均所需时间之间的关系
表3中的数据是k枝剪法平均所需时间;根据实验结果,可以画出k与平均所需时间的关系图8(测试机:windows xp,Xeon E5-2403四核,主频2.2GHz,8G内存)。

表3 k枝剪法平均所需时间
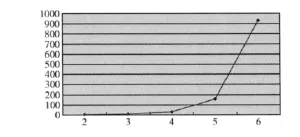
图8 k与平均所需时间之间的关系
从实验结果可以看出,所需时间T与k的阶乘成正比:T≈k!。因此,不能随意扩大k的取值,枝剪所选的分支一般应有k≤6,否则,求解计算所需的时间将以阶乘的速度增加,其时间复杂度将变得难以接受。
4.2.2 k与正确率之间的关系
表4中的数据是k枝剪法的正确率;根据实验结果,可以画出k与正确率之间的关系图9。

表4 k枝剪法的正确率
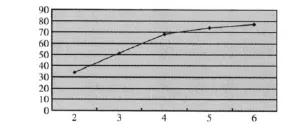
图9 k与正确率之间的关系
从实验结果可以看出,当k从1增加到4的过程中,正确率快速增加;当k>4时,正确率继续缓慢增加,增加量的绝对值越来越小,并且正确率可以取得较为满意的效果。
4.3 实验结果分析
从实验情况可以看出,使用k枝剪法进行模型求解,有以下特点:
(1)k不能过大,否则时间复杂度将会难以接受;一般情况下,应有k≤6;
(2)k不能过小,一般情况下,应有k≥4,否则,正确率会急剧下降;
(3)k=4或者5,较为合适,时间复杂度不是太高,正确率也不是太低,能够取得较为满意的效果。
5 结束语
本文提出了一个自然语言语义相关度计算模型,并研究了模型求解的k枝剪算法,可以对模型进行较为有效的近似求解;通过实验,对模型中的权重系数KSVO的最佳取值范围进行了初步研究;对k枝剪算法中k的取值范围进行了研究,得到了k与算法复杂度、正确率之间关系。但在论文的研究中,语法规则的设置较为简单,还不能覆盖一些特殊的汉语语法现象,实验数据量也较小,所依据的词汇语义库的语义信息还不能够完全满足计算需要,在下一步研究中,需要对语法规则进行完善,构建语义信息更准确、合理的词汇语义库作为语义计算的依据,并且扩大实验数据量。
[1]WEI Xue,XU Xinshun,REN Zhaochun.Word net-based lexical unit induction for FrameNet [J].Journal of Computational Information Systems 2012,8 (3):1047-1054.
[2]WANG Xin,SUI Zhifang.Semantic role labeling system based on dependency tree distance method for arguments identification[J].Journal of Chinese Information Processing,2012,26(2):40-45(in Chinese).[王鑫,穗志方.基于依存树距离识别论元的语义角色标注系统 [J].中文信息学报,2012,26(2):40-45.]
[3]Levine R,Detmar M.Head-driven phrase structure grammar:Linguistic approach,formal foundations,and computational realization [M].2nd ed.Encyclopedia of Language and Linguistics.Oxford:Elsevier,2008.
[4]Tom O,Janyce W.Exploiting semantic role resources for preposition disambiguation [J].Computational Linguistics,2008,35(2):151-184.
[5]Imdadi N,Syed A,Rizvi M.Automating reuse of online semantic resources by concept extraction using word sense disambiguation[J].Journal of Algorithms & Computational Technology,2012,6(3):435-446.
[6]Deepesh K,Choudhury J,Chakrabarty A.Improvement in word sense disambiguation by introducing enhancements in English WordNet structure [J].International Journal on Computer Science and Engineering,2012,7 (4):1366-1370.[7]LIU Yuhong.From case grammar through frame semantics to construction grammar [J].Journal of PLA University of Foreign Languages,2011,34 (1):5-9 (in Chinese).[刘宇红.从格语法到框架语义学再到构式语法 [J].解放军外国语学院学报,2011,34 (1):5-9.]
[8]ZHANG Huaping,LIU Qun.Model of Chinese words rough segmentation based on N-shortest-paths method [J].Journal of Chinese Information Processing,2002,16 (5):1-7 (in Chinese).[张华平,刘群.基于N-最短路径方法的中文词语粗分模型 [J].中文信息学报,2002,16 (5):1-7.]
[9]LI Yongliang,HUANG Shuguang,LI Yongcheng,et al.Improved CYK algorithm based on shallow parsing [J].Journal of Computer Applications,2011,31 (5):1335-1338 (in Chinese).[李永亮,黄曙光,李永成,等.基于浅层剖析的CYK改进算法 [J].计算机应用,2011,31 (5):1335-1338.]
[10]WANG Guangzheng,WANG Xifeng.Word sense disambiguating method based on HowNet semantic relevancy computation [J].Journal of Anhui University of Technology (Natural Science),2008,25 (1):71-75(in Chinese).[王广正,王喜凤.基于知网语义相关度计算的词义消歧方法 [J].安徽工业大学学报(自然科学版),2008,25 (1):71-75.]
