基于用户兴趣变化融合的个性化推荐模型
2013-09-11梁光磊谭国平
刘 春,梁光磊,谭国平
(1.中国电信股份有限公司广东研究院IT运营支撑部,广东 广州510630;2.华南理工大学计算机学院,广东 广州510006;3.河海大学 计算机与信息学院,江苏 南京210098)
0 引 言
互联网的快速发展,把人们带入了信息时代,给人们带来便利的同时也滋生了 “信息过载”,“资源迷向”等问题[1],为解决上述问题,提供个性化服务的推荐系统应运而生[2]。推荐系统从不同的角度有不同的划分方法,从算法来分,通常主要分为以下几类:基于内容、基于用户-产品二部图[3]、基于协同过滤、基于本体知识、基于机器学习和数据挖掘技术及基于多种模型融合的推荐等。其中融合的推荐是指在前述几种推荐方法基础上,对两种或多种推荐方法融合进行取利去弊的结合,从而达到提高系统性能的目的。个性化推荐的研究成果首先在电商领域获得了成功应用,有统计分析显示,亚马逊的35%的销售额是由其推荐系统拉动的[4],甚至有市场调研公司的数据显示,亚马逊网站推荐的销售转化率可以高达60%。
个性化服务在电商领域的成功应用,加速了它在其它行业的推广。目前推荐系统已被广泛应用于音乐,电影,书籍,个性化广告匹配,社交网络等领域。近年来移动互联网的发展,吸引了数以万计的独立开发者,他们开发的各类应用堆满了应用商店,人们出现了新的”应用迷航“问题,因此急需引入个性化推荐服务,来为用户推荐符合其兴趣爱好的应用软件,帮助用户更好的选择,同时也可增加开发者的收益,增加开发者的平台粘性。某电信运营商的 “爱游戏”平台是专门提供各类游戏下载的游戏应用商店,随着游戏提供商及开发者的不断加入,游戏软件数量激增,并在一定程度上导致大多数的游戏软件成为了长尾物品[5](指那些埋没在软件库里,没有机会与用户见面的物品)。然而,当前应用平台上的推荐方法很难将这些长尾物品发掘出推荐给对它可能感兴趣的用户。为了解决上述问题,本文提出了一种融合的个性化推荐模型,首先采用本体论中的概念的思想对游戏软件建模,然后通过对用户的行为日志进行分析建立用户偏好模型,最后依赖于时间因子将两种推荐模型进行有效的融合。该模型不仅能够有效准确的进行个性化推荐,提供个性化服务,同时还具有良好的扩展性和移植性,稍加改变便可将其应用到其他领域如视频的个性化推荐,图书的推荐等等。
1 游戏模型构建与用户行为分析
1.1 基于本体概念的思想构建游戏类概念-属性模型
计算机领域的本体论模型主要从概念关系角度来揭示事物的特征和本质。它通常由概念、概念所具有的特征、概念的实例及概念间的关系组成。本体学习研究通常是研究如何从结构化或者非结构化的数据源中抽取概念及发现概念间的关系[6],比较流行的词典知识库如英文的 Word-Net,中文的HowNet均是以词典知识为基础构成的概念关系网。本文的游戏软件模型构建主要参考文献 [6]所述的本体学习及概念抽取思想,按照面向对象设计思路,将游戏软件抽象成由各个类及其属性所组成的整体。我们提取游戏软件的各个类概念及其属性并根据他们之间的上下层级关系建立了如表1所示的游戏模型。
1.1.1 游戏软件的流行度估算
流行度即热门程度,一款软件在一段时期内下载的人数越多,说明该软件越受大众喜爱,可以认为其流行度高;如果一款游戏软件在相当长的一段时期内只有少数人下载则可认为其流行度很低。据此以一段时间的下载次数多少衡量一款软件的当前流行度,定义如下

式中:pop(i)——软件i的流行度,该公式是对不同下载量的软件进行权重衡量;Ci——游戏i的下载量 (用次数表示);α——权重基数,可根据系统平台的流量和下载量设定为某个默认值。
1.1.2 游戏软件的综合评分score
一款游戏的口碑如何,是否好玩,是否精致,主要由用户的评价和评分来衡量,并可从系统平台中获得用户对软件的评分,而后进行加权平均。定义游戏软件的综合评分公式如下

式中:scoreji——用户j对游戏i的评分;n——对软件i进行评分的用户总和。
1.2 用户在游戏应用平台上的行为分析
通过分析用户的操作日志可得出用户在系统平台的一般性行为见表2。
1.3 用户的长期兴趣度和随时间变化的短期兴趣度
通常用户的兴趣可分为长期兴趣和短期兴趣。在相当长一段时间内变化比较慢的兴趣可称之为长期兴趣,例如用户经常喜欢下载格斗类的游戏,说明用户喜欢格斗游戏,这个兴趣一般不会突然改变。在短时间内变化较快的兴趣称之为短期兴趣,比如用户之前一直玩格斗类游戏,近一个星期突然下了一部分音乐类的游戏,这反映了用户最近的兴趣是音乐类的。通过分析用户的显性行为和隐性行为,可得出用户的短期兴趣和长期兴趣,进而能够进行随用户兴趣变化的个性化推荐。

表2 用户的一般行为
1.3.1 用户的长期兴趣度
假设已获取用户u的所有日志信息,对该用户的整个日志信息进行统计分析。比如用户的日志记录中出现的动作类游戏比例较高,在用户的整个日志记录中持久地出现该类别的游戏,不管最近用户有没有下载动作类的游戏,都可认为用户的长期兴趣是动作类游戏。定义用户对游戏属性i的长期兴趣偏好公式如下
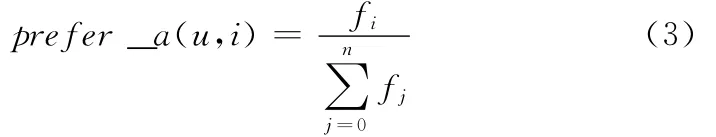
式中:prefer_a(u,i)——用户u对属性i的长期偏好值。N——某类概念中属性的个数。Fi——该类中第i个属性出现的频次。此公式表明了各个属性频次在用户日志记录中所占的比重,衡量了一个属性的对用户的相对重要程度。
1.3.2 基于时间变化的近期兴趣度
(1)非线性遗忘函数的引入
德国心理学家艾宾浩斯对遗忘现象所做的系统研究表明:人对事物的遗忘过程是非线性的,并且是先快后慢的,我们引入了双曲线函数来拟合艾宾浩斯的非线性遗忘曲线,参考文献 [17]给出调整后的遗忘函数如下
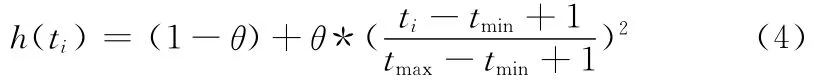
其中ti即用户对软件i的最晚一次行为的时间 (时间的单位均以天数来计),tmin表示用户行为日志的最早时间,tmax即为用户行为日志的最晚时间。θ为遗忘系数,θ的值越大遗忘的越快,表明用户的近期行为所占的比重较大,对不同的推荐系统可动态调整其值。
(2)根据用户显性和隐性行为分析用户的初始兴趣度。
用户的显性操作行为往往是用户兴趣的直接反映,而隐性行为则是用户兴趣的间接反映。本模型中所考虑了下载,收藏,评分和使用频次这些线性和隐性用户行为。它们综合反映了用户对一款软件是否感兴趣,有些行为是随时间而累积的,因此将这些分析用来衡量用户的近期兴趣变化。给出计算用户u对游戏i的初始兴趣值公式
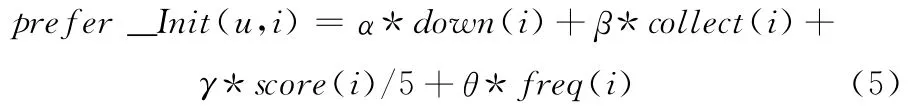
其中down即为是否需要下载,取为1或0,对于wap类网页的游戏,直接点开即可玩,用户容易丢失,相对来说需要下载客户端的游戏更能粘住用户;collect为是否收藏,值为1或者0;score即为用户u对游戏i的评分,有的有评分,有的没评分,没评分的则以该用户的普遍评分来平滑;freq(i)为用户使用游戏i的频次,计算公式如下

式中:x——使用次数,freq(i)的值与该游戏的使用频次成正比。
用户的各个行为所占的权重α+β+γ+θ=1,权重的确定一般根据用户操作需要付出的代价来定。比如 “下载”行为的权重就要低于 “收藏行为”;而要用户的 “评分行为”与 “收藏行为”需要付出的代价相似。用户 “再次使用行为”和 “下载行为”操作难度应该相似。
(3)基于时间因素的用户对软件i的兴趣度:
为了反映用户近期的兴趣偏好情况,结合遗忘函数和用户的初始兴趣值定义,给出反映用户近期兴趣偏好的兴趣计算公式
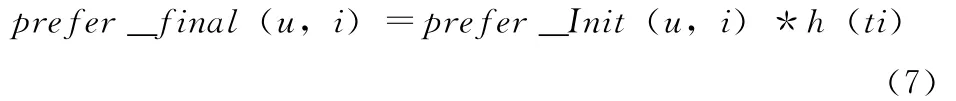
式中:pre_final(u,i)——用户u对游戏i最终兴趣偏好值。prefer_Init(u,i)——上面计算的用户对游戏i的初始兴趣值,h(ti)——该用户在时间ti的遗忘值。
2 基于用户兴趣偏好的推荐模型构建
2.1 用户对各个属性的兴趣度值
假设用户u的历史记录中有N款游戏,根据上节中计算出的用户对属性j长期兴趣偏好值和用户对游戏i基于时间变化的最终兴趣值,给出用户对各个属性的综合兴趣值。这里采用平均差分的思想将用户对整个游戏的兴趣值分化到各个属性维度上。
(1)定义用户u对属性j的近期兴趣偏好公式如下
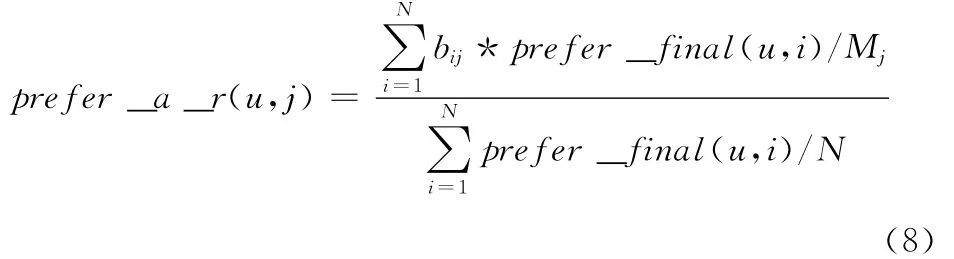
式中:Prefer_a_r(u,j)——用户u对属性j的近期兴趣偏好;bij——布尔值,游戏i包含属性j则值为1,否则为0;Mj为N个游戏中含有属性j的游戏的个数,N为用户历史记录中的游戏个数。由于采用平均差分法可能会导致用户的长期兴趣偏好值与用户的近期兴趣偏好值不在一个范围内,因此要进行归一化操作,归一化到0-1之间。(2)定义用户对各个属性的初始兴趣度的计算公式

分析上式计算结果可发现用户u的兴趣度大多集中在某些类的某些属性上。通常准确确定属性的权重还要考虑重要度和类内集中度这两个因素。重要度体现了用户对某些属性的偏好度,集中度则体现了类别内各个属性值的波动程度,反映该类概念对用户选择的影响力大小。如果一个类内的各个属性的兴趣度值波动较小,说明此类不是引起用户选择的因素,如果一个类中的各个属性的兴趣值波动较大,说明该类概念更能影响用户的选择。设游戏本体模型中第k个类概念下有nk个属性,下面给出重要度[8]和改进的文献 [9]中的类内集中度的计算公式。
(3)属性重要度参见文献 [8]中重要度的计算公式。
(4)改进的类内集中度公式如下

式中:CENk——类概念k的类内集中度,Nk——类概念k中的属性个数,——用户对属性i的初始兴趣度,如果某个类中只有一个属性的话,集中度就为1,如果各个属性的兴趣值都相等的话就会出现CENk值为0,则需要加参数进行平滑。
类内集中度概念在文本分类中是表示某些特征对该类划分的影响度,在本模型中中用来评价该类对用户选择游戏的影响力的大小。
(5)生成用户属性兴趣偏好向量
用户对第k类的第j个属性的最终兴趣偏好值计算公式参考文献 [8]修改如下:
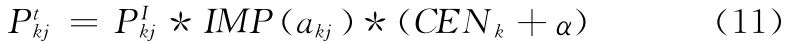
根据上述公式生成用户的属性的偏好序列,用向量模型的形式表示如下

例如a11表示第1类的第1个属性,Pt11表示用户U对第1类的第1个属性的最终属性兴趣值。上述用户偏好向量反映了用户U对各个属性的兴趣值大小,对于所有用户则可以以矩阵表的形式将各个偏好向量存储起来。我们可将计算出的属性兴趣值按从大到小排序,在进行推荐的时候,可以设一个阀值a,只考虑属性兴趣度大于a的n个属性的值,这样将大大降低系统的计算复杂度,提高系统的效率。
2.2 推荐算法描述
根据用户U的兴趣偏好向量,对U的兴趣偏好属性进行阀值筛选,然后从海量游戏软件中找出与用户U的兴趣特征相匹配的候选游戏,按照下面的公式计算各个候选游戏的得分。候选游戏g得分的计算公式如下
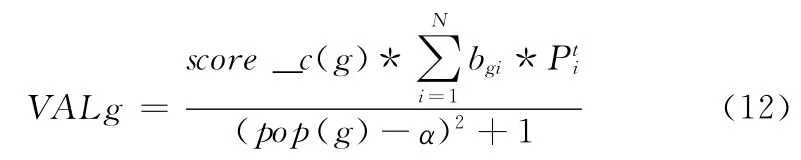
式中:Score_c(g)——章一中给出的游戏g的综合得分;N——该游戏g的属性个数;bgi——游戏g的属性i是否在筛选过的用户兴趣偏好序列里,用布尔值表示如果是则为1否则为0。Pti即为用户对属性i的最终兴趣权重。分母部分是为了要挖掘长尾物品,消除过于热门和过于冷门的游戏对结果的影响,pop(g)为游戏g的流行度;α为可调参数。据此计算所有候选软件的得分,然后降序排序,取top-N推荐给用户。
3 基于用户兴趣变化的协同过滤推荐模型
协同过滤技术是目前推荐系统中的主流技术,它基于统计学的思想,采用群体性过滤方法,通过分析与用户兴趣类似的其它用户的喜好情况来为用户进行个性化推荐,正是由于参考了其它群体的兴趣,可以发现用户的潜在兴趣爱好。协同过滤技术首先由亚马逊成功应用于电商领域,国内的豆瓣,淘宝,当当的个性化推荐系统也采用了协同过滤的思想。目前协同过滤主要分为基于用户的协同过滤(UserCF),基于物品的协同过滤 (ItemCF)及基于模型的协同过滤。ItemCF是依据群体用户的喜好来衡量物品之间的相似性,不考虑物品的具体内容特征,而UserCF是依据群体用户的喜好来衡量用户之间的相似性,不考虑用户的具体特征。UserCF主要是适用于物品种类变化较快,而用户的规模相对稳定的领域,如新闻推荐,笑话推荐,个性化阅读等领域。ItemCF主要用于物品数量相对稳定,用户量很大的情况,比如电商,电影推荐等。某电信运营商的“游戏”应用平台比较符合ItemCF的情况,其游戏数量的增长要远远小于用户数的增长。使用协同过滤技术首先要解决的是评分矩阵的稀疏性问题,下面首先讨论稀疏矩阵的填充问题。
3.1 稀疏评分矩阵的填充
由于用户—物品评分矩阵大多数情况下是稀疏的,这里给出几种常用的填充稀疏矩阵的方法:①对于用户没有评分的物品统一的按 ‘0’来填充,这是最简单但也是准确性最差的方法;②对于用户没有评分的物品按该用户对其它物品评分的 ‘平均值’来填充;③KNN的方式,取该用户的几个最近邻邻居对该物品评分的均值或差值来填充,SlopeOne算法的评分预测思想即采用的这种方式来预测;④LFM方法[10],Simon Funkt参见Netflix推荐比赛时提出了的隐语模型方法,主要过程如下:首先整理出一份用户评分矩阵作为训练集,通过隐语义分析模型迭代计算发掘用户-物品之间的隐因子;然后进行评分预测,用预测出的值来填充。经过验证,该方法可准确的预测缺失值,但是该方法基于机器学习,必须先进行训练,才能发掘出隐因子,在实时性要求比较高的推荐系统中,难以满足需求。
3.2 计算物品之间的相似度矩阵
根据游戏应用平台的特点:用户的评分极其稀疏,但又要求能够实时的把一些游戏软件推荐给适合的用户。参考项亮的著作[11]我们采用的基于条件概率的方法来计算物品共现矩阵,以此来衡量物品之间的相似度,条件概率的计算公式如下
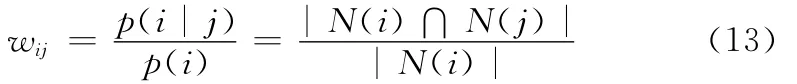
式中:N (i)——喜欢游戏i的用户数,N (j)——喜欢游戏j的用户数。
上述公式基于这样的一种假设,如果i,j同时被多个用户喜欢,那么可以认为i和j在某种程度上是相似的。通常一些热门游戏的玩的人数比较多,但是如果用上述方法会出现大多数游戏都与热门游戏相似的假象,为了防止任何游戏都与热门游戏的相似度很大,修正后的计算公式参见文献 [11]的53页。
John S.Breese在文献 [12]中提出了一个称为IUF(inverse user frequence),即用户活跃度对数的倒数,他认为不活跃用户对相似度矩阵的贡献度比不活跃用户的贡献度要大。比如系统中有些用户十分活跃,可能每天都会下载软件,该用户虽然下载次数很多,但可能并不是出于自身的兴趣,因此有必要降低这些过于活跃的用户对物品相似度的贡献度。
消除过于活跃用户影响的物品相似度计算公式修正如下

式中:Puj——用户u对候选游戏软件j的评分;i——用喜欢的游戏中与游戏j最相似K个,K值一般取10,Wij衡量i和j的相似度;N (u)——用户喜欢的游戏集合;prefer_final是以上计算出的用户对游戏i的兴趣度;分母部分主要用来消除过于热门和冷门的游戏的影响以挖掘长尾物品,其中α为调节参数。
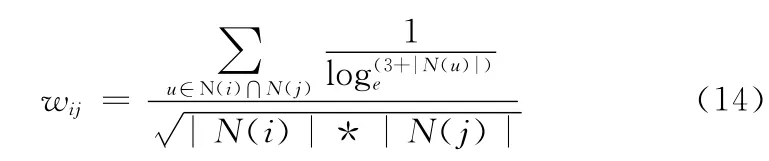
式中:N (u)——用户U所玩的游戏的数目。
John S.Breese的实验表明在准确率和召回率保持不变的情况下,通过消除过于活跃用户的影响,提高了推荐结果的覆盖率,改进了ItemCF的综合性能。
Karypis的研究[13]证明,如果将ItemCF的相似度矩阵按最大值归一化,可以提高推荐的准确率。根据上述相似度计算公式计算出物品的初始相似度矩阵M,然后使用最大值归一化公式对M进行最大值归一化,公式描述参见文献 [11]的58页。
3.3 改进的ItemCF推荐算法描述
根据以上计算得到物品相似度矩阵后,给出引入时间因素及消除热门物品影响的ItemCF推荐算法如下
4 两种推荐模型的融合
融合的推荐方法是通过把两种或多种推荐方法按照一定的规则整合,以此来弥补各自推荐方法的不足。通常情况下融合的推荐模型能够达到比较好的推荐效果,Netflix百万美元推荐系统改进大赛的冠军团队就是融合几十种推荐模型才达到了提升10%的目标[14],可见融合的推荐模型确实能提升推荐系统的性能。根据文献 [1]中提供的融合思路,推荐模型的融合主要有前融合、中融合,后融合,本模型中采用的是后融合的方式。
基于用户兴趣偏好的推荐能够发现与用户历史兴趣相符合的物品,而基于协同过滤的推荐,能够发掘用户的潜在兴趣。本模型将基于用户兴趣偏好的推荐方法和改进后的ItemCF推荐方法进行后融合,还引入了时间因子对融合模型参数进行自适应调节,融合后的推荐方法描述如下
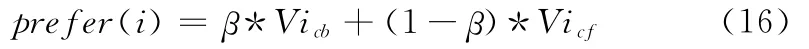
式中:Vicb——基于用户兴趣偏好的推荐算法中计算出的得分值,Vicf——游戏软件i使用改进后的ItemCF算法中计算出的得分值。Β——基于时间因素的自动调节参数,β的计算方法描述如下

式中:Tcur——当前时间 (时间单位均以天来计),Tonline——游戏的发布时间,α为调参数,这样就解决了新上线不久的软件,其用户数不是很多,使用ItemCF算法不能有效的推荐给可能对它感兴趣的用户的问题。该公式中表示如果一部游戏是新游戏,则刚上线不久时β很大,Vcb权重较大可以将其推荐给对它的感兴趣的用户,随着用户数的增多,该软件则为部分用户熟知,β逐渐降低,Vcf权重逐渐增大,可以挖掘对它感兴趣的潜在用户。
注:Vcb是基于用户兴趣偏好的推荐模型算出的游戏得分,Vcf是基于改进的ItemCF算出的游戏得分。在进行融合时,如果一部游戏在两个推荐模型中同时被推荐则可用上面的公式进行加权,如果只在一种模型里被推荐则在另外一个模型里的值就可以看作是0或者基于另外一个模型的推荐公式进行计算得出在该模型中的得分后再进行加权。在使用这个融合公式时,Vcb和Vcf值应该先归一化到同一范围内。
5 实验验证与结果分析
由于本推荐模型是用于top-N推荐,根据文献 [11]所述,我们不采用常规的评分预测评价方法MAE和RMSE方法,而采用信息检索领域的准确率来进行评测,为了评测模型发掘长尾物品的能力,把覆盖率也作为一个评测指标。实验依据某电信运营商的 “游戏”平台的实际用户数据,随机选取游戏行为相对较多的用户,实验的用户总数为7286个,用户的行为日志的时间段是8个月,游戏数为5000款。表3为用户游戏行为信息表样例。

表3 用户游戏行为信息表样例
将每个用户玩过的游戏随机按7∶3比例分为两份,记作A份和B份,将A份作为训练集,B份作为测试集。用训练集的数据训练得到相应的推荐模型,然后运用上述的推荐算法得出每个用户的top-N推荐列表 (此次实验N=10)。这里的推荐列表包括以下3份:
(1)采 用 基 于 用 户 兴 趣 偏 好 (user interest preference,UIP)的推荐方法得到的个性化推荐列表 (参考第一、二章)。
(2)采用改进后的ItemCF算法得到的个性化推荐列表(参考第三章)。
(3)采用后融合推荐方法得到的个性化推荐列表 (参考第四章)。
将这3个推荐列表与测试集的结果进行对比,得出如图1所示。
从实验结果可以看出:采用基于UIP的推荐方法在精确度和覆盖率方面稍低于改进后的ItemCF算法,但是基于UIP方法计算复杂度低,模型构建相对简单,并且能够进行实时推荐,能够为用户推荐符合其兴趣偏好的物品;改进后的ItemCF算法在由于能够根据群体兴趣发现用户的潜在兴趣,因而在精确度方面要稍高于UIP,但是在计算物品相似度矩阵方面开销较大;3种算法在覆盖率上都接近50%,融合方法的挖掘长尾物品的能力稍强,并且采用融合的推荐方法,比单独采用UIP方法和改进的ItemCF推荐方法在精确度上提升超过70%,由此可见我们采用的考虑时间因子的融合的推荐模型是较优的;④由图示可以看出,在精确度方面3种模型最高只达到10%左右,这除了与模型中参数调优有关外,还受平台测试数据特性的影响,部分用户行为数据和物品信息缺失,导致精确度的整体拉低。以上只是离线实验的结果,该结果已经验证了该融合的个性化推荐模型的优良性。对推荐系统最准确的评测则是用户满意度,我们将在系统上线后进行在线验证本个性化推荐模型的各项指标。
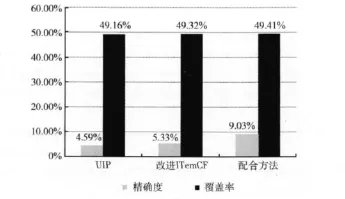
图1 3种推荐方式效果比对
6 结束语
本文讨论了将基于用户兴趣偏好 (UIP)推荐和改进的ItemCF算法进行后融合的个性化推荐模型,并将其应用于应用商店领域的软件推荐。实验表明该融合模型反映了用户兴趣漂移性,提高了个性化推荐的精度,提升了该应用平台的综合推荐性能。在取得一定成果的同时我们还遇到了个性化推荐算法都会遇到的冷启动问题[15],我们的初步解决方案是采用非个性化推荐方式,表述如下:
(1)新用户:由于无法获取其日志记录,则可进行非个性化推荐,将各个游戏的综合评分score_c(i)和流行度pop(i)进行加权,生成一个热门游戏列表,推荐给新用户。计算公式如下
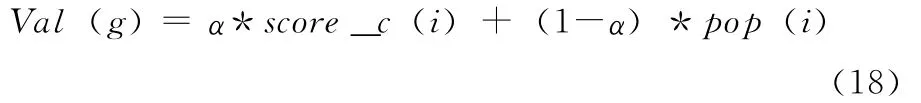
式中:ɑ——可变参数。
(2)新游戏软件:可在系统设置一个最新上线列表,可以把新上线的软件放到最新上线列表中,这样新软件就可以面向所有用户。
以上只是解决 “冷启动”问题的初步方案,推荐系统的 “冷启动”问题是为大多数研究人员所关注的问题,除此之外推荐系统中的数据稀疏性、推荐模型的扩展性问题[16]、基于潜在因子分析法的实时应用[17]和基于网络图构建高效推荐模型等问题都是推荐系统领域的热门研究问题,这些问题的解决对提高推荐系统的性能非常重要,这些将是我们今后研究的方向。
[1]XU Hailing,WU Xiao,LI Xiaodong,et al.Comparison study of Internet recommendation system [J].Journal of software,2009,20 (2):350-362 (in Chinese). [许海玲,吴潇,李晓东,等.互联网推荐系统比较研究 [J].软件学报,2009,20 (2):350-362.]
[2]Adomavicius G,Tuzhilin A.Toward the next generation of recommender systems:A survey of the state-of-the-art and possible extensions [J].IEEE Trans on Knowledge and Data Engineering,2005,17 (6):734-749.
[3]Zhou T,Ren J,Medo M,et al.Bipartite network projection and personal recommendation [J].Physical Review E,2007,76 (4):7.
[4]LIU Jianguo,ZHOU Tao,WANG Binghong.The research progress of personalized recommendation system [J].Progress in Natural Science,2009,19 (1):1-12 (in Chinese).[刘建国,周涛,汪秉宏.个性化推荐系统的研究进展 [J].自然科学进展,2009,19 (1):1-12.]
[5]Chris Anderson.Long tail theory [M].QIAO Jiangtao,transl.Beijing:China CITIC Press,2006:35-39 (in Chinese).[克里斯·安德森.长尾理论 [M].乔江涛,译.北京:中信出版社,2006:35-39.]
[6]DU Xiaoyong,LI Man,WANG Shan.A survey on ontology learning research [J].Journal of Software,2006,17 (9):1837-1847 (in Chinese).[杜小勇,李曼,王珊.本体学习研究综述 [J].软件学报,2006,17 (9):1837-1847.]
[7]ZHENG Xianrong,TANG Zeying,CAO Xianbin.Non-lineal gradual forgetting collaborative filtering algorithm capable of adapting to user’s drifting interest [J].Computer Aided Engineering,2007,16 (2):69-73 (in Chinese).[郑先荣,汤泽滢,曹先彬.适应用户兴趣变化的非线性逐步遗忘协同过滤算法 [J].计算机辅助工程,2007,16 (2):69-73.]
[8]LI Ning,WANG Zilei,WU Gang,et al.Research on user pattern in personalized film recommendation system [J].Computer Applications and Software,2010,27 (12):51-54 (in Chinese).[李宁,王子磊,吴刚,等.个性化影片推荐系统中用户模型研究 [J].计算机应用与软件,2010,27 (12):51-54.]
[9]LI Ning.The study of personalized movie recommendation technology in home network [D].Hefei:University of Science & Technology China,2009 (in Chinese).[李宁.家庭网络中个性化影片推荐技术研究 [D].合肥:中国科学技术大学,2009.]
[10]Simon Funk.Netflix update:Try this at home [EB/OL].[2006-12-11].http://sifter.org/~simon/journal/20061211.html.
[11]XIANG Liang.Recommendation system in action [M].Beijing:The People Post and Telecommunications Press,2012:51-59 (in Chinese).[项亮.推荐系统实践 [M].北京:人民邮电出版社,2012:51-59.]
[12]Breese J S,Heckerman D,Kadie C.Empirical analysis of predictive algorithms for collaborative filtering [C]//Proceedings of the 14th Conference on Uncertainty in Artificial Intelligence,1998:43-52.
[13]Mukund Deshpande, George Karypis.Item-based top-N recommendation algorithms [J].ACM Transactions on Information Systems,2004,22 (1):143-177.
[14]Netflix HQ.Grand prize awarded to team BellKor’s pragmatic chaos [EB/OL].[2006-08-29].http://www.netflixprize.com//community/viewtopic.php?id=1537.
[15]Ahn H J.A new similarity measure for colaborative filtering to alleviate the new user cold-starting problem [J].Information Sciences,2008,178 (1):37-51.
[16]Bell R,Koren Y.Scalable collaborative filtering with jointly derived neighborhood interpolation weights [C]//IEEE International Conference on Data Mining,2007.
[17]Takeshi Suzuki,Gendo Kumoi,Kenta Mikawa,et al.A study of recommender systems on a latent probabilistic space model [C]//Proceedings of 12th Asia Pacific Industrial Engineering & Management Systems Conference,2011.
