海洋物质输运模拟中并行计算的应用比较研究
2013-09-11黄伟建蔡忠亚
黄伟建,周 伟,蔡忠亚
(1.河北工程大学 信息与电气工程学院,河北 邯郸056038;2.中国海洋大学 海洋环境与生态教育部重点实验室,山东 青岛266100)
0 引 言
为了提高运算速度,并行计算技术已应用到海洋数值模拟领域;MPI[1]和 OpenMP[2]是目前此领域相关研究中最常用的两种并行计算方法。近几年,随着处理器技术的发展,采用多核心处理器的集群计算机得到了普及,由于多核心集群计算机具有节点间分布式和节点内共享式两种存储结构,因此多核心集群计算机用户在进行海洋数值模拟研究时,不仅可以采用MPI这种适合分布式存储结构的并行计算方法[3],而且也可以采用以OpenMP为代表的适合共享存储结构的并行计算方法[4]。通过将 MPI和OpenMP两种并行计算技术应用于同一问题并在多核集群平台上进行对比研究,能够找到一种更合适的方法,以求更有效的在多核集群平台上解决这种问题。
对物质输运方程[5]进行求解以模拟物质输运过程是各类海洋数值模拟相关研究的重要组成部分之一,为了找到一种更适合在多核集群计算机平台上对物质输运方程进行求解的并行计算方法,本文以普林斯顿海洋模型 (princeton ocean model,POM)[6]为例,分别使用 MPI和 OpenMP两种不同类型的并行计算技术对其物质输运方程的串行算法进行并行化改造,并在多核心集群计算机平台上进行了对比实验。
1 并行程序设计
1.1 物质输运方程
本论文使用的物质输运方程为C(x,y,z,t):
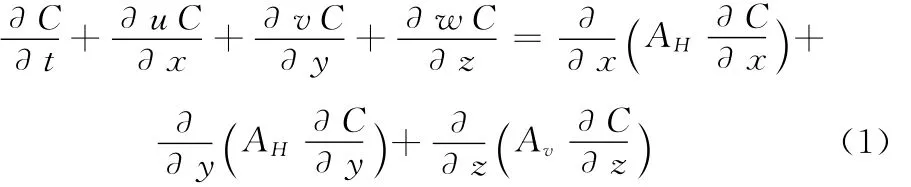
1.2 串行模拟方法
本论文使用的物质输运方程求解的串行方法[7]在POM模式基础上使用Fortran语言进行开发,POM是一种三维斜压原始海洋模式,由美国普林斯顿大学研制。该算法首先计算由平流和水平扩散引起的浓度变化,这一部分为显示格式计算。之后对由垂向扩散引起的浓度变化进行计算,这一部分为隐式格式。以下为串行模拟方法流程描述,设t为时间变量,T为模拟时间长度:
(1)初始化模拟参数,如模拟时长、计算区域等。
(2)时间循环for(t=0;t<T;t++)。
(3)调用POM模式水动力过程。
(4)调用物质输运模块对模拟区域t时刻的每一网格点求解物质输运方程C(x,y,z,t)(式 (1)),该模块依次计算平流项、扩散项以及开边界条件。
(5)输出物质输运方程的计算结果,即时刻t的示踪物质浓度数据。
(6)执行步骤 (2)至步骤 (6)到t循环结束为止。
(7)模拟结束。
1.3 并行模拟方法
串行的物质输运模拟方法在对每一个网格点求解物质输运方程时,各网格点的计算相对独立,因此可以将模拟区域适当划分成多个子区域,将各个子区域的计算放在不同的处理器核心上进行,以此实现计算的并行化处理。图1为按照横向划分子区域的并行模拟方法流程图。
并行的物质输运模拟方法在串行方法的基础上,将物质输运的模拟区域划分为多个子区域,从而将方程C(x,y,z,t)的求解划分为多个子求解 (式 (2)),并分别放置在多个不同的处理器上进行运算。在并行求解过程中,相邻子求解之间需要交换后续求解需要的分区边界数据


图1 物质输运模拟并行方法流程
根据物质输运模拟的计算区域可以分块进行求解的特点,本文采用单指令流多数据流 (single instruction streammultiple data stream,SIMD)方 式并 分 别 使用 MPI和OpenMP两种并行计算技术对物质输运方程求解的串行方法进行并行化改造。由于MPI和OpenMP具有不同的特点,下面对这两种技术应用于物质输运方程求解的方法进行对比说明。
1.3.1 MPI并行方式
消息传递是在分布式存储系统上进行并行计算的有效方法,MPI作为一种基于消息传递模型的程序库,提供了在多个进程之间发送接收消息以及同步等功能。由于MPI易用性强且性能稳定,因此其被广泛应用于集群系统当中[8]。消息传递要经过数据打包、传送、消息拆包3个过程,时间开销较大,所以在使用MPI设计并行程序时,避免大量的消息传递是一个普遍原则[9]。使用MPI对物质输运模块进行并行,关键在于如何有效的传递分区边界处的数据。对计算区域进行分块后,各分区可以互相独立的进行计算,但分区边界处数据的计算需要用到相邻分区的计算结果,因此相邻进程需要通过消息对分区边界处的数据进行交换。假设有以下代码:

按照i对计算区域进行分块后,多个进程针对各自分块的数据执行以上代码进行并行计算。非边界处的计算各进程可以独立完成,但在边界处,由于计算array2(i)需要使用array1(i-1)的值,而array1 (i-1)的值位于上一个分区,因此各进程在计算完成array1数组以后需要将边界处的数值通过MPI消息发送给相邻的进程。如图2(a)所示,MPI版本的物质输运模块由多个位于不同节点计算机上的MPI进程运行,各进程根据分配的子区域进行求解。在计算的某些时刻,进程i需要使用前面进程i-1的边界数据,由于两个进程无法共享内存空间,此时进程i-1与进程i需要分别使用MPI的消息发送和消息接收方法完成分区边界数据的传递工作。
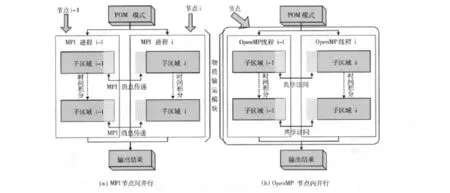
图2 MPI(a)和OpenMP(b)并行方式对比
1.3.2 OpenMP并行方式
OpenMP是一种被广泛使用的在共享存储系统上进行并行编程的标准,它能够通过在代码中加入指令来控制程序在特定的位置进行多线程的并行执行。由于共享存储体系结构所具有的存储共享这一特点,使用OpenMP进行并行程序设计时需要利用同步和锁操作来保证内存访问的正确性[10]。同时,避免开销较大的同步和锁操作的大量使用能够提高系统的效率[11]。与MPI采用多进程并行的方式不同,OpenMP采用多线程并行,各并行线程共享相同的一块内存,每个线程均可以对内存中的每一个位置进行读写操作,因此使用这种方法对物质输运模块进行并行化时,线程之间不需要对分区边界数据进行交换。物质输运模块内部由多个循环构成,OpenMP提供了相应并行指令用于这种情景。假设有以下OpenMP并行代码:

如以上代码所示, “!$omp parallel do”指令告知编译器此处代码需要多线程并行工作完成,当主线程执行代码到此处时,会自动生成多个并行的子线程,每个子线程执行循环区间的一部分。由于多个并行线程共享相同的内存空间,在分区边界处计算array2(i)时,线程可以直接访问位于相邻分区的array1(i-1),而不需要进行边界数据的交换。每个循环结束处的 “!$omp end parallel do”命令会进行一次同步操作,因此会带来一些时间开销。如图2(b)所示,OpenMP版本的物质输运模块与MPI版本相似,多个位于同一节点计算机上的OpenMP线程对不同分区的数据进行处理。因为多个并行线程共享相同的内存空间,线程i可以直接访问前面线程i-1的边界数据,而不需要如MPI那样通过消息传递进行数据交换。
1.4 实验方法
本论文分别将MPI版本并行程序和OpenMP版本并行程序放置于中国海洋大学环境科学与工程学院的多核集群计算机上运行,并对实验结果进行对比分析。该集群计算机由20台IBM HS21计算机组成,节点之间使用高速千兆网络连接,集群具体配置信息见表1。为了便于更好的对实验结果进行分析,只选取应用了并行计算的物质输运模块进行研究,每种测试情景运行5次,将最短的时间 (不计文件读写所用时间)作为最终结果。在对计算时间进行分析的基础上,同时对并行程序的加速比和效率进行分析。并行程序的加速比由串行程序的计算时间与并行程序的计算时间这两者的比值求得;在串行时间一定的情况下,加速比与并行时间成反比。并行效率等于加速比与核心数的比值,能够反映核心的运算能力是否被充分使用。本实验采用的计算区域为适用于胶州湾模拟的312×213×5规模的网格,为了进行并行计算,我们将计算区域均匀划分成1-8个子区,每个区域分块对应一个计算核心,时间积分60000步。
2 结果与讨论

表1 并行计算机配置概要
实验结果表明,本论文采用的物质输运并行模拟方法产生的物质浓度数据结果与串行方法的结果一致,据此可以证明并行方法的可靠性,图3为以浓度图形式对胶州湾物质输运模拟结果进行的对比。
图4为MPI与OpenMP所用的计算时间对比图,横轴为使用的CPU核心个数,纵轴为计算时间。从该图中可以观察到,随着核心数目增加,MPI与OpenMP的计算速度逐渐加快,运算时间逐渐减少。在使用8个核心进行计算时,MPI和OpenMP均达到计算速度的最高值,相对于串行分别减少83%和76%的计算时间。通过观察MPI和OpenMP时间折线的后段,可以发现二者的计算速度增幅明显放缓,对于MPI来说,这主要是由于增加的MPI进程带来的通信开销造成的[12,13];对于OpenMP,主要原因是增加的线程数量带来的同步开销较大[14],对运算效率造成了负面影响。
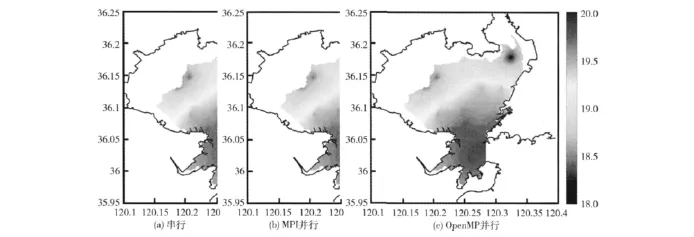
图3 胶州湾物质输运模拟结果浓度图对比

图4 MPI和OpenMP计算时间对比

图5 MPI和OpenMP加速比对比
图5、图6反映的是MPI和OpenMP的并行加速比以及并行效率的情况。从图5中可以观察到,MPI和OpenMP在使用12个核心时加速比达到最高值5.95和4.19。随着核心数目增加,MPI通信开销和OpenMP线程间同步开销使二者的加速比增长幅度呈现明显下降趋势。从图6中可以观察到,MPI和OpenMP在使用2个核心时的并行效率达到最高值,分别为0.95和0.87。之后随着核心数目的增加,二者的并行效率呈现明显下降趋势。虽然MPI和OpenMP在使用8个核心时的计算速度最高,计算用时最短,但此时的并行效率却处于最底值位置,这说明MPI和OpenMP在使用更多的核心进行计算时,计算之外的开销比重也随之增加,从而导致了核心利用效率的降低[15]。
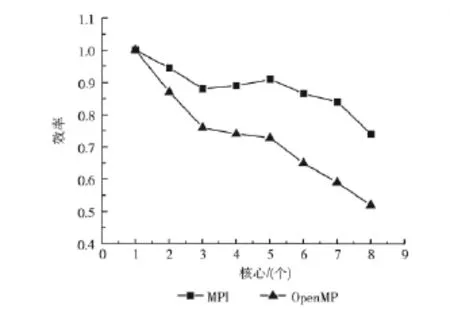
图6 MPI和OpenMP并行效率对比
通过以上分析可以得出,在计算区域为312×213×5这种规模的实验条件下,MPI的加速效果明显优于OpenMP,当MPI使用8个核心时运算速度达到最高值,相较于串行速度提高6倍。
3 结束语
本论文分别将MPI和OpenMP两种类型的并行计算方法应用于模拟海洋物质输运的过程,并在多核心集群计算机系统上进行了对比实验。实验结果表明,MPI的加速效果明显优于OpenMP,且最高运算速度接近串行的6倍。由此看来,在这种计算规模下MPI更适合用来在多核心集群平台上对海洋物质输运的模拟过程进行并行化。根据本研究的成果,今后将把MPI并行的物质输运模拟方法应用到有关海洋研究当中,使其发挥更大的作用。
[1]LI Dong,LIU Jing,HAN Guijun,et al.Parallel algorithms for princeton ocean model[J].Marine Science Bulletin,2010,29 (3):229-333(in Chinese). [李冬,刘璟,韩桂军,等.POM海洋模式的并行算法 [J].海洋通报,2010,29 (3):229-333.]
[2]Gonzalez M,Ayguade E,Martorell X,et al.Dual-level parallelism exploitation with OpenMP in coastal ocean circulation modeling [G].Lecture Notes in Computer Science 2327:Proceedings of the 4th International Symposium on High Performance Computing.Berlin:Springer,2006:469-478.
[3]MPI:A message-passing interface standard [EB/OL].[2012-07-11].https://computing.llnl.gov/tutorials/mpi/.
[4]OpenMP:An application program interface [EB/OL].[2012-07-18].https://computing.llnl.gov/tutorials/openMP/.
[5]SHEN Xia,HONG Dalin,WANG Peng.Study on numerical scheme of mass transport equation based on POM [J].Advances in Marine Science,2009,27 (4):452-459 (in Chinese).[申霞,洪大林,王鹏.基于POM的物质输运方程数值格式研究 [J].海洋科学进展,2009,27 (4):452-459.]
[6]Zhang W G,Wilkin J L,Schofield O M E.Simulation of water age and residence time in New York Bight [J].Journal of Physical Oceanography,2010 (40):965-982.
[7]CHEN Bingrui,ZHU Jianrong,QI Dingman.Improvement in numerical scheme on the advection term of mass transport equation using particle-tracing method [J].Oceanologia Et Limnologia Sinica,2008,39 (5):439-445 (in Chinese).[陈昞睿,朱建荣,戚定满.采用质点跟踪方法对物质输运方程平流项数值格式的改进 [J].海洋与湖沼,2008,39 (5):439-445.]
[8]Lusk E,Chan A.Early experiments with the OpenMP/MPI hybrid programming model [C]//West Lafayette:Proceedings of the Fourth International Workshop on OpenMP,2008:36-47.
[9]WANG Zhiyuan,YANG Xuejun,ZHOU Yun.Scalable triple modular redundancy fault tolerance mechanism for MPI-oriented large scale parallel computing [J].Journal of Software,2012(4):1022-1035 (in Chinese).[王之元,杨学军,周云.大规模MPI并行计算的可扩展冗余容错机制 [J].软件学报,2012 (4):1022-1035.]
[10]PAN Wei,LI Zhanhuai,WU Sai,et al.Evaluating large graph processing in MapReduce based on message passing [J].Chinese Journal of Computers,2011 (10):1768-1784 (in Chinese).[潘巍,李战怀,伍赛,等.基于消息传递机制的MapReduce图算法研究 [J].计算机学报,2011 (10):1768-1784.]
[11]WU Huabei,SUN Jizhou,WANG Wenyi.Research and implementation of parallel programming environment for hybrid parallel computing system [J].Computer Science,2010,37(4):143-178 (in Chinese). [武华北,孙继洲,王文义.面向混合并行计算系统编程环境的研究与实现 [J].计算机科学,2010,37 (4):143-178.]
[12]Rabenseifner R,Hager G,Jost G.Hybrid MPI/OpenMP parallel programming on clusters of multi-core smp nodes[C]//Proceedings of the 17th Euromicro International Conference on Parallel,Distributed,and Network-Based Processing,2009:427-236.
[13]Thakur R,Gropp W.Test suite for evaluating performance of multi-threaded MPI communication [J].Parallel Computing,2009,35 (12):608-617.
[14]Rabenseifner R,Hager G,Jost G.Tutorial on hybrid MPI and OpenMP parallel programing [C]//Portland,OR:Supercomputing Conference,2009.
[15]Martin J Chorley,David W Walker.Performance analysis of a Hybrid MPI/OpenMP application on muti-core clusters [J].Journal of Computational Science,2010,1 (3):168-174.
