基于软测量技术的重石脑油芳潜含量的预测
2013-08-31程明张湜李宗雯
程明,张湜,李宗雯
(南京工业大学 自动化与电气工程学院,南京211816)
芳潜含量即芳烃的潜含量,是指石脑油中C6~C10环烷烃含量与C6~C10芳烃含量之和。由于催化重整的反应机理为碳原子数不变的反应,即C6环烷烃转化为C6芳烃(苯),C7环烷烃转化为C7芳烃(甲苯),依次类推,而C7芳烃、C9芳烃和C10芳烃经过歧化单元进行歧化反应转化为高附加值的C8芳烃(即混合二甲苯)和苯产品,故石脑油的芳潜含量的高低,直接决定着C8芳烃产量的高低,从而决定了装置的经济效益。
芳潜含量作为重石脑油重要的品质参数,在生产过程中需要检测相关成分的含量来计算得到,而各成分的检测较难实现,因此笔者基于软测量技术,结合神经网络建立芳潜含量值的预测模型,通过对重石脑油生产过程的分析,找出影响芳潜含量的间接因素,不但解决了芳潜含量的检测问题,还提供了芳潜含量预测的方法。
本文基于某石化公司的芳烃加氢裂化装置,采用联合加氢裂化法,以直馏减压柴油、轻柴油和重柴油的混合油为原料进行加氢裂化。

式中:Mi——环烷烃i的分子量;wNi——环烷烃i的质量分数;wAi——芳烃i的质量分数;wN+w2A——芳潜质量分数,wN代表环烷烃的质量分数,wA代表芳烃的质量分数。
1 软测量技术
软测量建模的实现过程包括辅助变量的选择、数据的采集及预处理、软测量模型的建立、软测量模型的在线校正。辅助变量的选择应根据较易测量且与主导变量有着密切的关系,且辅助变量的变化能够引起主导变量改变的原则进行选择。数学表达公式如下所示[1]:
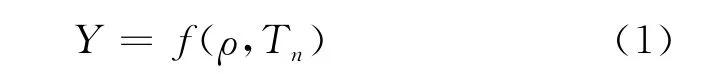
式中:Y——芳潜含量值;ρ——石油密度;Tn——重石脑油在不同的馏出体积分数下干点的馏程值。
数据的来源为某石化公司2007~2011年的记录数据,为使数据具有代表性,选择了不同季节中的130组数据,表1为在进行恩式蒸馏试验过程中,重石脑油在不同的馏出体积分数下的温度。

表1 神经网络的样本数据
数据的预处理通常包括三个方面:
1)异常数据的剔除。通常可以通过技术判别法和统计判别法来判断数据是否异常[2]。首先将采集的全体数据进行运算,得出全部数据的均值S和方差σ2,计算各点的偏离率P:
当P(i)>1.1时判断该点为异常点,需要剔除;当P(i)<1.1时说明该点是正常点。当剔除采集数据中的异常点后,即可建立样本数据。
2)数据的平滑处理。采用数字滤波的方法将样本数据中的噪声信号除去。
3)数据的归一化处理。因为原数据的幅值大小及单位不一,导致计量数据间存在较大差异性,因而要预先对数据样本进行归一化处理,归一化公式:
式中:Xmax,Xmin——该组数据中的最大值、最小值;Y(i)——对应的X(i)经归一化后的值。
在该文中,考虑到研究对象化工反应过程的复杂性和非线性,笔者将结合人工神经网络来建立相应的软测量模型。由于过程的时变性,在模型建立好之后须对模型进行在线校正。
2 神经网络建模预测
径向基函数网络RBF(Radial Basis Function)的函数逼近能力、模式识别与分类能力都优于全局逼近的网络[3]。神经网络学习训练样本的数量和质量、学习算法、网络拓扑结构和类型等的选择,对所构成的软测量模型的性能都有重大影响[4]。从径向基网络的结构上看,当隐含层和输出层神经元的权值和阈值确定后,网络的输出也就确定了,所以径向基网络的学习过程就是网络层权值的修正过程[5]。
Spread为径向基函数的扩展系数,因而合理地选择Spread是很重要的,它的值应尽可能得大,这样径向基神经元能够对输入向量所覆盖的区间都产生响应,但是,也不用使全部的径向基神经元都如此大,只要有一部分的径向基神经元能够对输入向量所覆盖的区域产生相应就可以了。在不同Spread值下的网络结构和网络预测效果见表2所列。
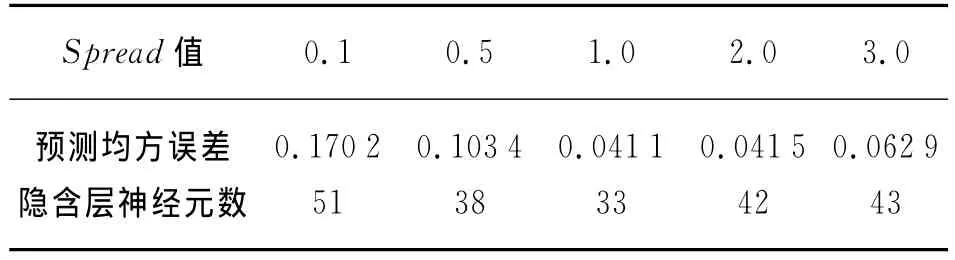
表2 不同Spread下的网络结构与预测效果
Spread的值越大,网络的输出效果越好,输出曲线越光滑,但Spread值太大会使传递函数的作用域扩大到全局,使RBF网络失去了局部收敛的优势,使传递函数对过多的输入产生响应,造成过拟合现象,这样不仅使网络的精度降低,还会较大地延长网络的学习时间。从表2中可以看出,当Spread为1.0时预测均方误差最小,此时的隐含层神经元数为33。
Spread值不同时的预测误差曲线如图1所示。当Spread为1.0时的网络预测误差最小,即网络的预测效果最好,所以,根据表2和图1的结果,在该预测模型中的Spread值取1。经仿真,网络训练结果如图2所示。

图1 Spread值不同时的预测误差

图2 训练数据仿真结果
在图2中,T为芳潜含量的实际值;RBF为神经网络模型通过训练网络输入数据得到的仿真结果;Error为芳潜含量的实际值和仿真值的差值。由图2中可以看出,T和RBF两条线重合度较大,说明网络的训练效果很好,且RBF网络的训练速度较快,模型输出和样本的输出数据差距很小,满足设定的误差要求。因此,此模型可以用来预测芳潜含量的值。利用训练好的模型对芳潜含量进行预测,预测数据仿真结果如图3所示。
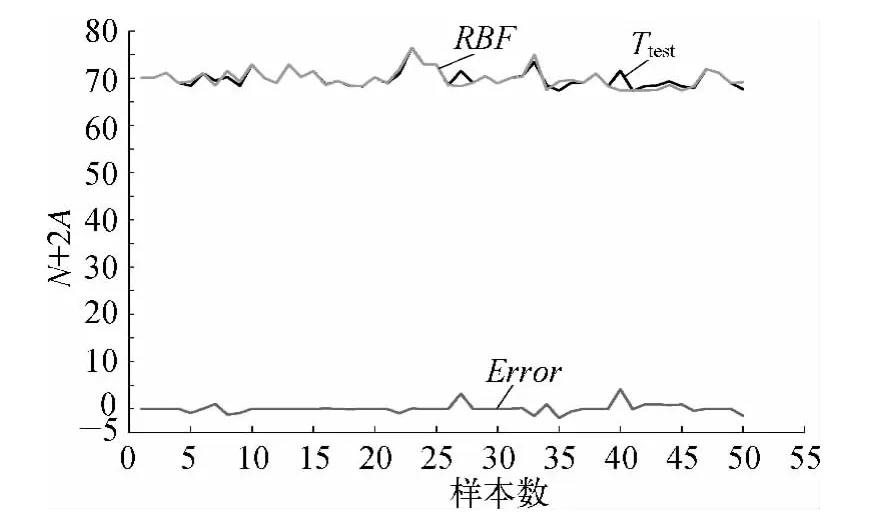
图3 预测数据仿真结果
在图3中,Ttest为芳潜含量的实际值;RBF为预测值,根据图3可以看出,模型的预测效果较好,能够在指定的误差范围内预测芳潜含量的值,达到了期望的预测结果。
笔者成功建立起来的模型要进行定时校正,即在运用一段时间后要用新的数据进行建模,以适应新模型在新环境下能准确地预测芳潜含量。对于不同化工厂的生产装置,或者同一台设备随着季节变化,或者设备折旧等因素,往往使影响产品的参数不同,不同研究人员建立的模型结构也不同,因而合理选择神经网络结构和神经网络算法是成功建模的关键。
3 线束语
运用软测量的原理结合神经网络方法,建立芳潜含量的模型,使得原本要通过复杂难以直接测量的组分参数,转为测量容易获得的辅助参数来计算芳潜含量值,并利用模型实现对重石脑油芳潜含量的预测。通过RBF的训练方法的研究可以看出,RBF网络由于在结构上具有输出-权值线性关系,训练方法快而简单,是一种性能良好的网络。
[1]马文忠,郭江艳,王艳丽,等.基于BP神经网络的联合站燃烧系统软测量模型的研究[C]//2011中国电工技术学会学术年会论文集.中国电工技术学会,2011.
[2]HE Chan, MA Changfeng.A Smoothing Self-adaptive Levenberg-marqurdt Algorithm for Solving System of Nonlinear Inequalities [J].Applied Mathematics and Computation,2010,21(06):3056-3063.
[3]许东,吴铮.基于Matlab6.x的系统分析与设计——神经网络[M].2版.西安:西安电子科技大学出版社,2002:24-25.
[4]王恩博,彭亦功.软测量建模若干方法研究[C]//中国仪器仪表学会2007学术年会智能检测控制技术及仪表装置发展研讨会论文集.中国仪器仪表学会,2007.
[5]傅荟璇,赵红.Matlab神经网络应用设计[M].北京:机械工业出版社,2010:103-104.
[6]刘文霞.石脑油品质对芳烃装置经济效益影响及对策[J].当代石油石化,2010(08):32-34.
[7]吴春辉.浮法玻璃热端生产过程控制系统设计及关键参数软测量[D].上海:华东理工大学,2010.
[8]SJOBERG J,LJUNG L.Overtraining,Regularization and Searching for a Minimum,with Application to Neural Network[J].International Journal of Control,1995,62(06):1391-1407.
[9]王恺,杨巨峰,王立,等.人工神经网络泛化问题研究综述[J].计算机应用研究,2008,25(12):3525-3533.
[10]沈雁鸣,粗汽油干点软测量研究[D].上海:华东理工大学,1998.
