优先级资源共享在RTL综合中的实现*
2013-08-19刘贵宅于芳刘忠立刁岚松
刘贵宅 于芳 刘忠立 刁岚松
(1.中国科学院 微电子研究所,北京100029;2.北京飘石科技有限公司,北京 100029)
电子设计自动化(EDA)工具是现场可编程门阵列(FPGA)领域的一个重要组成部分.随着FPGA以其特有的优势逐步扩大应用领域,人们越来越意识到FPGA 的EDA 工具的重要性.FPGA 配套的EDA工具流程包括综合、映射[1]、布局、布线[2]、码流生成、码流下载等,如图1 所示.
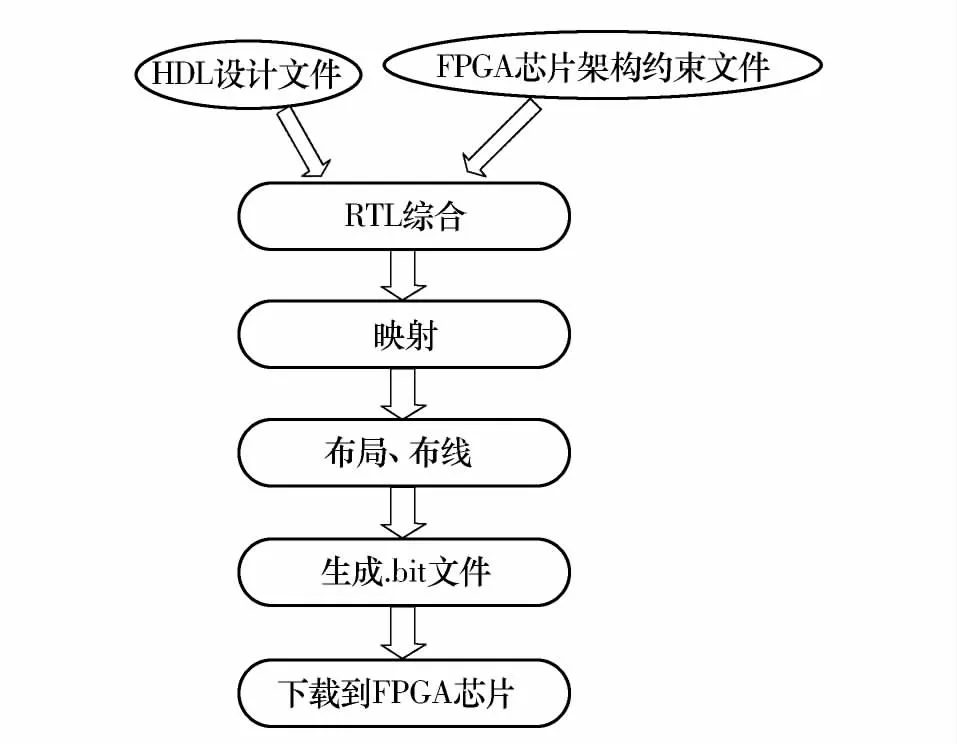
图1 FPGA EDA 流程图Fig.1 Flowchart of FPGA EDA
寄存器传输级(RTL)综合[3]处于FPGA 的EDA工具流程的最前端,将行为级的描述文件转换为门级的网表,承担了绝大部分的优化任务,包括针对面积、时序和功耗的优化,是FPGA 的EDA 工具重要的部分[4],综合结果直接影响整个设计的好坏.
RTL 综合涉及到多个知识领域,包含优化算法、计算机编译[5]、硬件描述语言(HDL)[6]、软件工程等,也是FPGA 的EDA 工具流程中难度最大的部分.对FPGA 综合优化技术的深入研究十分有意义.
RTL 综合就是将HDL 描述的设计文件转化为门级网表并优化的过程,这个过程包括解析[7]、确立、逻辑优化、工艺映射[8].RTL 综合过程中的优化包括对时序[9]、面积[10]和功耗的优化[11],而优先级的资源共享就是针对面积进行的优化.
资源共享是时序互斥的两个或多个相同算术逻辑单元(ALU)用同一资源实现的方法,是FPGA 综合中的关键技术之一[12],成熟的综合工具Synplify(Synopsis 公司)、XST(Xilinx 公司)、Leonardo spectrum(Mentor 公司)均采用资源共享方案,但具体实现方案没有公开.而开源的综合工具(如伯克利大学的ABC[13]和Stephen Williams 团队的Icarus[14])均未采用资源共享方案.
文中基于中国科学院微电子研究所与北京飘石科技公司联合开发的Verilog RTL 综合工具HqFpga,提出了一种优先级资源共享方法,通过改进普通的资源共享方法,将可共享的资源按照相同输出、相同输入、无共同端口的优先顺序依次进行共享,以减少ALU 个数,使有限的资源得到充分利用,用较小的芯片实现更大的设计,进而实现面积优化.
1 优先级资源共享方法
文中的资源共享是将设计描述中不同时进行的相同算符(算术操作符)按照规定的顺序依次进行共享,以达到优化的效果,属于RTL 综合中针对面积进行的优化.
1.1 优先级资源共享的约束
RTL 综合中的优先级资源共享方法有一些约束,主要包括以下两部分:
(1)资源共享主要针对比较复杂的算符,如* 、+、-、/等.资源共享在减少ALU 的同时,会增加多路选择器(MUX),但总体资源减少,达到面积优化的作用.对于普通的逻辑操作(如与、或操作等),在减少逻辑操作的同时会引入MUX,总体结果面积未必减少.
(2)只有功能相同且不同时执行的算术操作才可以进行共享,而且只有互斥分支之间功能相同的算术操作才可以用同一ALU 共享实现.如if、else 或case语句的不同互斥分支,在某一时刻只有一个分支执行.
1.2 优先级资源共享的流程
优先级资源共享就是不同分支的时序互斥的相同复杂操作按照规定的优先级次序依次进行共享.
优先级资源共享的实现伪代码如下:


优先级资源共享的步骤如下:
(1)收集所有if、else、case 互斥分支,这些互斥分支在某一时刻只有一个分支工作,满足优先级资源共享的约束.
(2)收集互斥分支之间相同的算术操作符.该步骤仅检测收集相同的算术操作符,不考虑普通的逻辑操作符.
(3)对于检测到的可以共享的算术操作符,优先对输出端口相同的算术逻辑单元进行资源共享.具有相同输出端口的模块,输出端口一定会连接到同一个或同一组MUX 来选择驱动信号,如图2(a)所示.资源共享要先检测输入端是否有公用端口,若没有公共输入端口,则将相同的操作合并,将输出端的MUX 分别平移到两个输入端口,以选择信号驱动,如图2(b)所示;若含有公共输入端口,则将公共端口固定在一个输入端口上,另一端口将输出的MUX 平移过来,共享之后可减少ALU 的数量,如图2(c)所示.
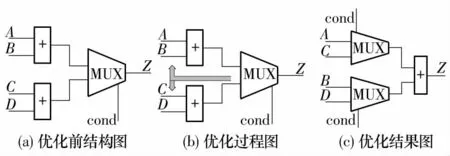
图2 资源共享分解示意图Fig.2 Schematic diagram of resource sharing decomposition
(4)对有相同输入端口的模块进行资源共享,其过程和步骤(3)类似,将相同的操作合并为一个操作,公共端口作为一个输入端口,另一个输入端口添加一个MUX 选择输入信号,输出端口直接驱动两个信号.
(5)对其他可共享的模块进行资源共享,其过程和步骤(4)类似,分别在两个输入端口插入MUX来选择驱动信号,输出端口直接驱动两个信号.
1.3 优先级资源共享的优点
改进的优先级资源共享的优点叙述如下.
(1)增加的MUX 数量减少
以EP1 为实例,其代码如下:

实例EP1 不采用资源共享的综合结果如图3所示,包含3 个加法器和1 个MUX.
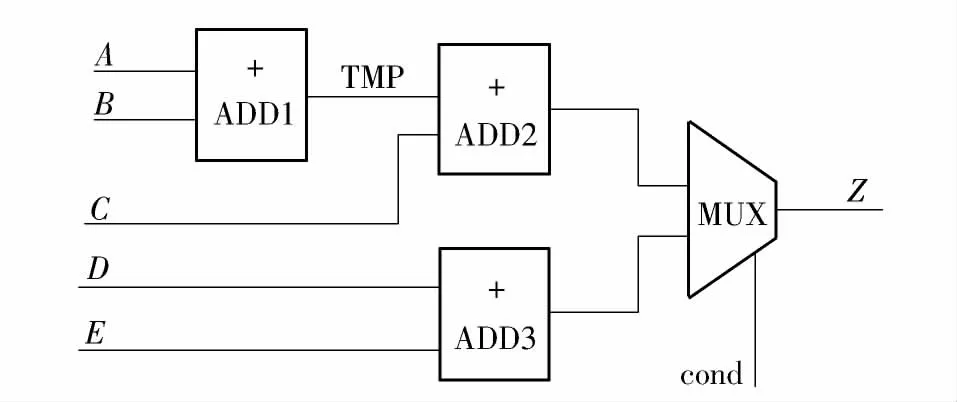
图3 EP1 不采用资源共享的综合结果Fig.3 Synthesis result of EP1 without resource sharing
EP1 采用非优先级的普通资源共享方法的综合结果如图4 所示,ADD1 和ADD3 共享,包含2 个加法器和3 个MUX,输入到输出的信号延时为2 级MUX 延时+2 级加法器延时.
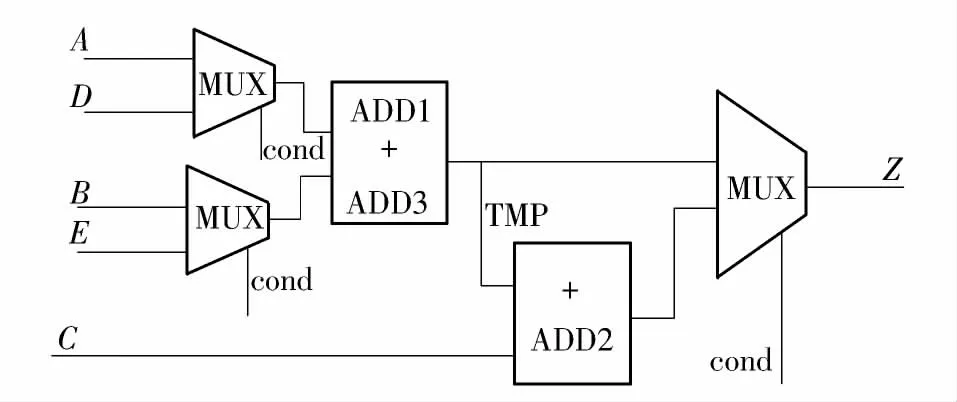
图4 EP1 采用普通资源共享方法的综合结果Fig.4 Synthesis result of EP1 using normal resource sharing method
EP1 采用优先级资源共享方法的综合结果如图5所示,ADD2 和ADD3 共享,只包含2 个加法器和2 个MUX,与不采用资源共享方法相比减少了1个加法器,而与采用普通资源共享方法相比减少了1 个MUX,输入到输出的信号延时为1 级MUX 延时+2 级加法器延时.
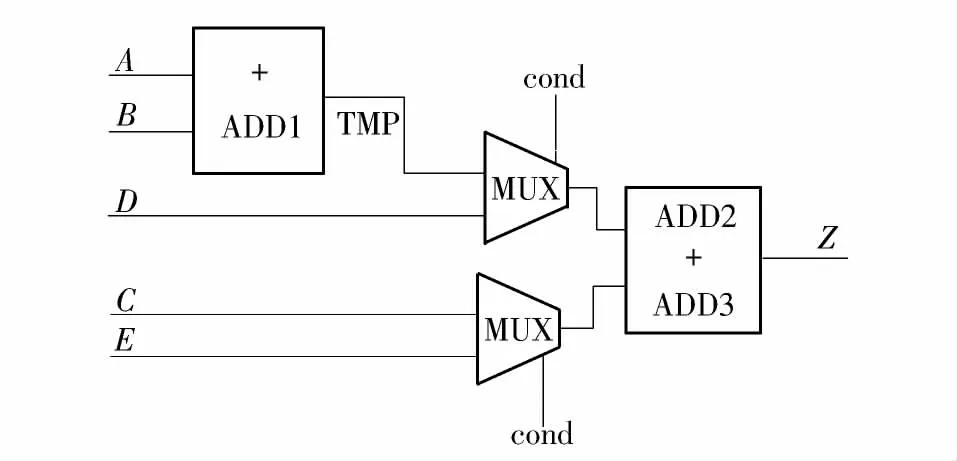
图5 EP1 采用优先级资源共享方法的综合结果Fig.5 Synthesis result of EP1 using priority resource sharing method
(2)避免数据流冲突错误
以EP2 为实例,其代码如下:

EP2 不采用资源共享的综合结果如图6 所示,该网表包含4 个加法器和1 个MUX.
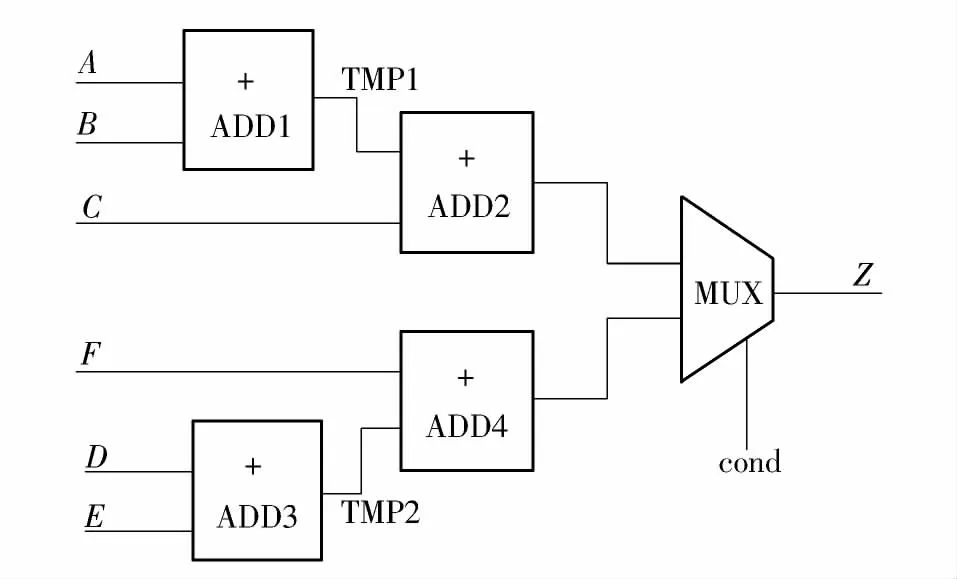
图6 EP2 不采用资源共享的综合结果Fig.6 Synthesis result of EP2 without resource sharing
EP2 采用非优先级的普通资源共享方法的综合结果如图7 所示,ADD1 和ADD4 共享,ADD2 和ADD3 共享,与不采用资源共享方法相比减少了2 个加法器,增加了4 个MUX,还产生了组合回路和数据流冲突[15]的错误.
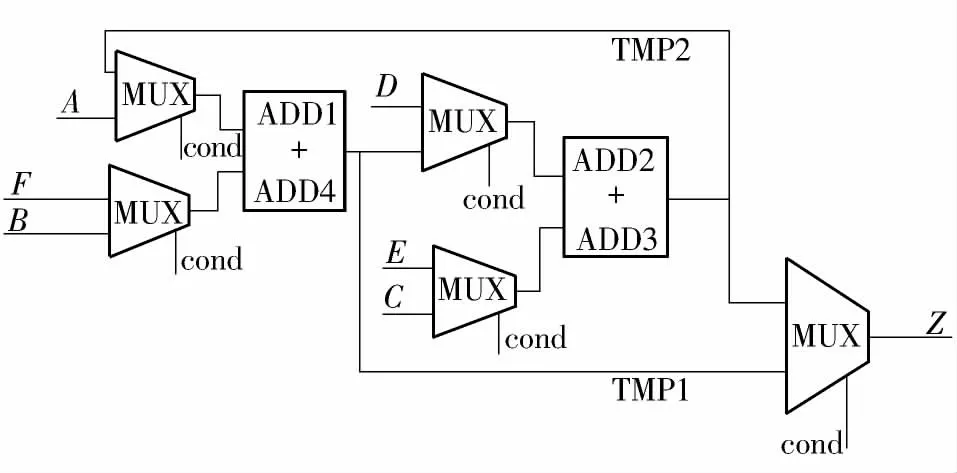
图7 EP2 采用普通资源共享方法的综合结果Fig.7 Synthesis result of EP2 using normal resource sharing method
EP2 采用优先级资源共享方法的综合结果如图8所示,ADD2 和ADD4 共享,ADD1 和ADD3 共享,包含2 个加法器和3 个MUX,与不采用资源共享方法相比减少了2 个加法器且不会出现组合回路,与采用普通资源共享方法相比减少了2 个MUX和2 级MUX 延时.
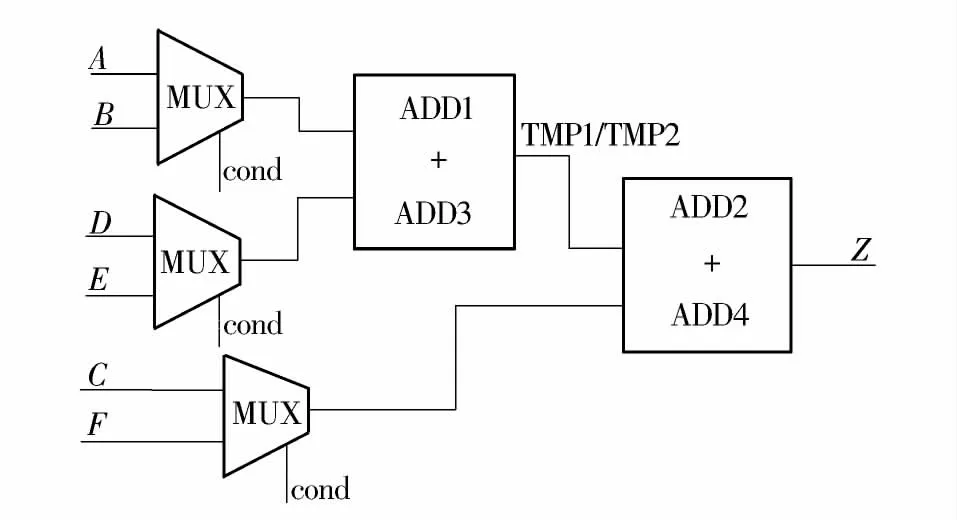
图8 EP2 采用优先级资源共享方法的综合结果Fig.8 Synthesis result of EP2 using priority resource sharing method
2 实验结果与分析
为验证文中优先级资源共享方法的优化效果,从工业界实际电路中随机选取了8 个不同种类的电路进行测试.测试环境如下:CPU 为Intel core i7 CPU 870 2.93 GHz,内存为4 GB,操作系统为Windows XP,编译环境为Visual C ++2008.运行结果网表均通过ABC[13]中的验证工具证明其与原始电路等价.
优先级资源共享后的综合结果和未进行资源共享的结果比较如表1 所示,主要以加法为例,比较ALU 的个数.表1 表明,优先级资源共享方法可以减少所需的ALU 个数,达到资源优化的目的.
优先级资源共享方法和普通资源共享方法所需的ALU 个数相同,主要是减少了MUX 的个数,进一步实现面积优化,具体结果如表2 所示.
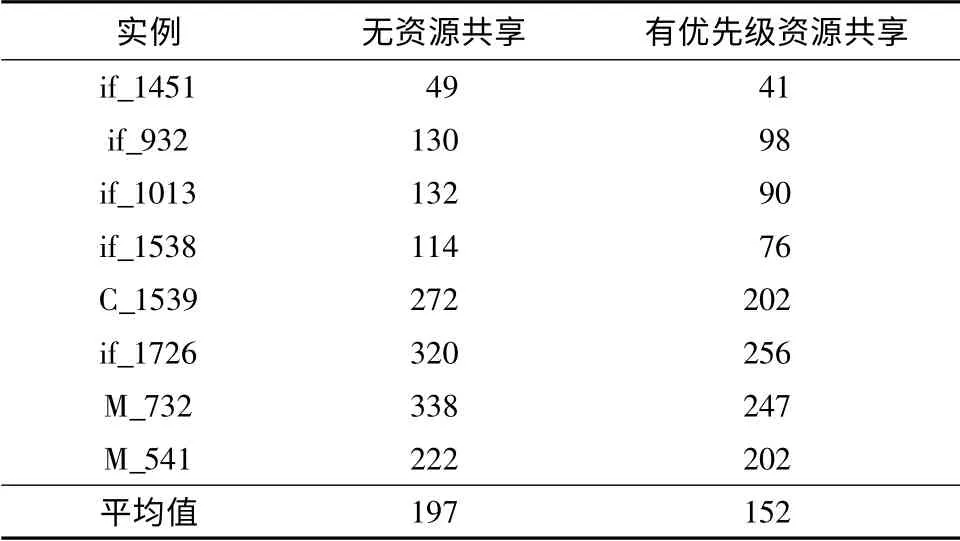
表1 优先级资源共享前后的ALU 个数对比Table1 Comparison of ALU numbers before and after using priority resource sharing method
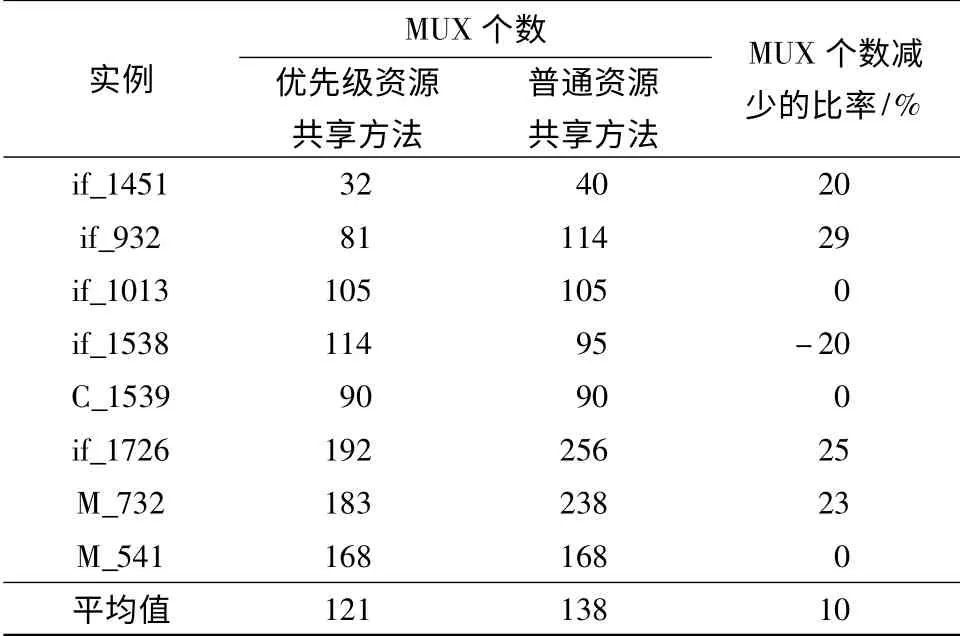
表2 优先级资源共享和普通资源共享方法的MUX 个数对比Table 2 Comparison of MUX numbers between priority resource sharing method and normal resource sharing method
表2 表明,采用优先级资源共享方法后,MUX的个数比普通资源共享方法减少了10%左右,优化效果更好.
3 结语
针对FPGA 中算术操作资源较为复杂、占用面积大且算术单元数量有限的问题,文中通过改进普通资源共享方法,提出了资源共享的优先级顺序.该优先级资源共享方法不仅减少了复杂ALU 的个数,而且所需的MUX 个数也比普通资源共享方法减少了10%左右,达到了面积优化的效果.文中提出的资源共享方法仅针对ALU 进行优化,今后将进一步研究可以同时优化时序互斥的普通逻辑单元和共享时序互斥的实例的方法.
[1]Zhang Qianli,Chen Stanley L,Li Yan,et al.Mapper design for an SOI-based FPGA[C]∥Proceedings of the 10th IEEE International Conference on Solid-State and Integrated Circuit Technology.Shanghai:IEEE,2010:821-823.
[2]陈亮,李艳,李明,等.基于SRAM 的FPGA 导航布局布线方法实现与应用[J].深圳大学学报理工版,2012,29(3):217-223.Chen Liang,Li Yan,Li Ming,et al.Implementation and application of navigated place and route for an SRAMbased FPGA[J].Journal of Shenzhen University Science and Engineering,2012,29(3):217-223.
[3]Deniziak S.A symbolic RTL synthesis for LUT-based FPGAs[C]∥Proceedings of the 12th International Symposium on Design and Diagnostics of Electronic Circuits &Systems.Liberec:IEEE,2009:102-107.
[4]Piga L,Rigo S.Comparing RTL and high-level synthesis methodologies in the design of a theora video decoder IP core[C]∥Proceedings of the 5th Southern Conference on Programmable Logic.Sao Paulo:IEEE,2009:135-140.
[5]Sussman A,Lo N,Anderson T.Automatic computer system characterization for a parallelizing compiler [C]∥Proceedings of 2011 IEEE International Conference on Cluster Computing.Austin:IEEE,2011:216-224.
[6]Chinedu O K,Genevera E C,Akinyele O O.Hardware description language (HDL):an efficient approach to device independent designs for VLSI market segments [C]∥Proceedings of the 3rd IEEE International Conference on Adaptive Science and Technology.Abuja:IEEE,2011:262-267.
[7]Pakray P,Bandyopadhyay S,Gelbukh A.Dependency parser based textual entailment system[C]∥Proceedings of 2010 International Conference on Artificial Intelligence and Computational Intelligence.Sanya:IEEE,2010:393-397.
[8]Jeong C,Nowick S M.Technology mapping and cell merger for asynchronous threshold networks[J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2008,27(4):659-672.
[9]Awan M,Harris F,Koch P.Time and power optimizations in FPGA-based architectures for polyphase channelizers[C]∥Proceedings of the Forty-Fifth Asilomar Conference on Signals,Systems and Computers.Pacific Grove:IEEE,2011:914-918.
[10]Cong J,Minkovich K.Optimality study of logic synthesis for LUT-based FPGAs[J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2007,26(2):230-239.
[11]Aksoy L,Costa E,Flores P,et al.Optimization of area and delay at gate-level in multiple constant multiplications[C]∥Proceedings of the 13th Euromicro Conference on Digital System Design:Architectures,Methods and Tools.Lille:IEEE,2010:3-10.
[12]Mondal S,Memik S O.Resource sharing in pipelined CDFG synthesis [C]∥Proceedings of the IEEE/ACM Asia and South Pacific Design Automation Conference.Shanghai:IEEE,2005:795-798.
[13]Berkeley Logic Synthesis and Verification Group.ABC:a system for sequential synthesis and verification,release 70319[EB/OL].(2007-10-01)[2012-10-15].http:∥www.eecs.berkeley.edu/~alanmi/abc/.
[14]Stephen W.Icarus:a Verilog simulation and synthesis tool[EB/OL].(2006-12-26)[2012-10-15].http:∥iverilog.icarus.com/.
[15]Synopsis.VHDL compiler reference manual[R].Mountain View:Synopsis,2004.
