基于PSO-DNN 神经网络的煤制甲醇合成过程建模
2013-07-31张文兴甘子桥王建国
张文兴,甘子桥,王建国
(内蒙古科技大学机械工程学院,内蒙古 包头 014010)
甲醇合成工序在煤制甲醇生产中处于一个核心地位,是复杂流程的化工过程,其特点是流程长、反应机理复杂、强耦合性、高度非线性、时变性。由于甲醇合成塔运行过程往往具有动态特性,难以用数学模型来描述。人工神经网络方法是非线性过程建模的一种有效的方法,众多领域中应用最广、最有成效的是多层前向网络,但它是一个静态神经网络,实现的是系统输入与输出之间的静态匹配,无法准确地反映甲醇合成过程的动态特性。动态神经网络具有延迟或反馈环节,能够更直接生动地反应系统动态特性,Elman 网络作为一种动态递归神经网络,对历史数据具有敏感性,具有处理动态信息的能力[1],然而 Pham[2]等指出,采用标准 BP算法训练的Elman 网络,只能逼近一阶动态系统,要更高阶动态系统建模,必须采用动态算法或采用Elman 网络的改进型。因此,本文引入一种基于结构改进的Elman 网络,即在标准Elman 网络的反馈节点引入自反馈,针对改进Elman 网络采用BP 算法进行训练导致的的收敛速度慢、稳定性差和泛化能力弱的问题,引入粒子群优化算法对动态神经网络的权值和阈值进行优化。实验结果表明,使用动态神经网络建立的粗甲醇转化率预测模型具有预测精度高、动态适应性强、结构简单等特点;引入粒子群算法对动态神经网络进行优化后,模型的实时性、稳定性和泛化能力都得到明显的增强。
1 动态神经网络
1.1 改进Elman 网络的结构
图1 为改进Elman 网络结构,即在标准Elman网络的反馈节点上加自反馈,系数为α,如图1中虚线所示。
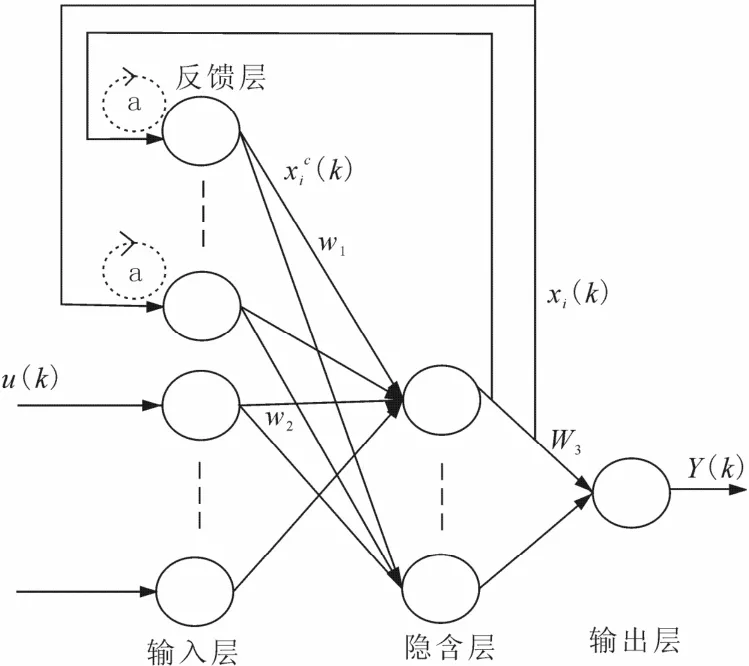
图1 改进Elman 神经网络结构图Fig.1 The block diagram of modifield Elman neural network
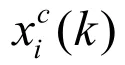

因此可得:

改进 Elman 神经网络的非线性空间的表达式为:

式中:y—输出节点向量;
x—n 维中间层节点单元向量;
u—r 维输入向量;
xc(k)—n 维反馈状态向量;
ω3—隐含层到输出层连接权值;
ω2—输入层到隐含层连接权值;
ω1—承接层到隐含层的连接权值;
g(*)—输出神经元的传递函数,是隐含层输出的线性组合;
f(*)—隐含层神经元的传递函数,多取为sigmoid 函数,即

α在k 时刻的修正量可写为:

式中:η —学习率。

1.2 改进Elman 网络的学习算法
改进的Elman 神经网络学习算法仍然采用的是梯度下降算法,即利用反向传播算法(BP)[4],根据网络的实际输出值与输出样本值的差值来修改权值和阈值,使得网络输出层的误差平方和最小。设第k 步系统的实际输出为 yd( k ),则改进反馈网络的目标函数即误差函数可表示为:

将E 对连接权 wI3,wI2,wI1分别求偏导,由梯度下降法可得网络的学习算法:
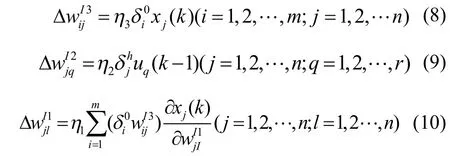
1.3 基于DNN 神经网络的粗甲醇转化率预测模型
甲醇合成过程的影响因素众多,且各影响因素之间呈现高度非线性及强耦合性,因此本文采用核主元分析法(KPCA)来解决模型输入变量特征提取问题。KPCA 方法的基本思想是通过某种隐式方式将输入空间映射到某个高维空间(常称为特征空间),并且在特征空间中实现主元分析(PCA)[5]。由于KPCA 通过核函数的引入实现了输入样本变量到非线性主元的映射,使数据变量与非线性主元间的距离和达到最小,弥补了PCA 在非线性特征提取问题上的局限性。结合上文介绍的改进Elman 网络可以建立一种DNN 模型,其原理如图2 所示,先根据先验知识确定初始输入变量,然后采用核主元分析法(KPCA)对输入数据进行非线性映射处理,消除数据变量之间的耦合相关性,降低数据维数,提取主元,再利用改进Elman 神经网络对提取的主元进行训练学习,最后完成预测模型的建立。

图2 基于DNN 神经网络的粗甲醇转化率预测模型Fig.2 Crude methanol conversion rate prediction model based on DNN neural network
2 基于PSO 算法的DNN 预测模型
2.1 PSO 算法基本理论
PSO[6]算法最早由 Kennedy 和 Eberhart 在 1995年提出。PSO 算法是从鸟类捕食行为中得到启发并用于求解优化问题的,算法中每个粒子都代表问题的一个潜在解,每个粒子对应一个由适应度函数决定的适应度值。粒子的速度决定了粒子移动的方向和距离,速度随自身及其他粒子的移动经验进行动态调整,从而实现个体在可解空间中的寻优。粒子群算法收敛速度快,具有很强的通用性,并已在化工过程建模中获得了广泛的应用[7,8]。
2.2 PSO 算法优化DNN 网络的基本思想
DNN 神经网络采用BP 算法基于梯度信息来调整连接权值,因而极易陷入局部极值点且收敛速度较慢,权值和阈值选取的随机性会导致网络稳定性差。为了克服上述缺点,引入收敛速度快、鲁棒性高、全局搜索能力强的PSO 算法来优化DNN 网络的连接权值和阈值,建立一种新的 PSO-DNN 网络模型。PSO 优化DNN 网络的具体实现步骤如下:
(1) 将DNN 网络结构中所有神经元间的连接权值和各个神经元阈值编码成实数码串表示的个体,即M 个优化权值(包括阈值在内)可用由M 个权值参数组成的一个M 维向量来表示,作为PSO 算法要寻优的位置向量。
(2)在编码的解空间中,随机产生一定数目的个体(微粒)组成种群,其中不同的个体代表神经网络的一组不同权值,同时初始化Gbest、Pbest。
(3)DNN 网络训练及个体的适应度评价。将微粒群中每一个个体的分量映射为网络中的权值和阈值,从而构成个体对应的神经网络。首先划分训练样本和测试样本;其次输入训练样本进行网络训练,通过反复迭代来优化网络权值,并计算每一个网络在训练集上产生的均方误差,以此作为目标函数;最后对每个个体进行适应度评价,从中找到最佳个体用来判断是否需要更新微粒的 Gbest 与Pbest,构造如下的适应度函数:

式中:n—训练样本个数;
c—输出端个数;
tk,p—训练样本P 在k 输出端的给定输出;
Yk,p(Xp)—训练样本P 在k 端的实测值,他们两个值的误差平方和越小,表示实际值和预测值越接近,网络的性能越好。
(4)更新每个粒子的速度和位置,产生下一代的粒子群。更新公式如下:


(5)当目标函数值小于给定的误差或达到最大迭代次数时,算法结束。将PSO 算法训练出来的最佳神经网络的权值和阈值作为DNN 网络的初始值。
3 仿真实验
以某厂 ICI 型甲醇塔为对象,该装置采用铜基催化剂低压法合成甲醇,上游净化工段产生的有效气体(CO、CO2和 H2)在合成塔内发生一连串反应,得到粗甲醇。通过分析甲醇合成机理及其反应特点,选取合成塔温度(T)、合成系统压力(P)、驰放气流量(Sc)、氢碳比(ρ)、入塔气流量(Sr)、新鲜气流量(Sn)、循环气流量(Sx)共7 个可操作变量,作为预测模型的初始输入变量。选取甲醇合成塔出口的单程粗甲醇质量转化率为质量指标。选择选择 2011年9月至12月合成塔刚进入稳定期时采集到的原始数据,经过异常数据剔除处理,得到建模数据。经过平滑滤波处理去除数据集中的随机噪声,通过归一化处理将所有数据归一化到[0,1]之间,消除数量级上的差异。
经过预处理后的数据共249 组,考虑到样本时间跨度较大,为了能使训练样本集和测试样本集都能够涵盖全部周期内的信息,将样本按时间序列排序,从中抽提出第4、8、12、16…248 组共62 组数据作为测试数据样本集,剩余187 组数据作为训练集用来训练样本。评价指标选择均方误差。
BP 网络和Elman 网络参数:根据人工经验,从7 个初始输入变量中选取5 个影响最大的变量(T、P、Sc、ρ、Sx)作为模型的最终输入,隐含层节点数通过穷举试验确定为12 个时网络性能最佳,输出层节点数为1 个,即粗甲醇转化率,则BP 网络和Elman 网络均采用5-12-1 的结构。
DNN 网络参数:7 个初始输入变量(T、P、Sc、ρ、Sr、Sn、Sx)经过 KPCA 特征变量提取后,选取累积贡献率大于85%的前3 个变量作为最终输入,隐含层节点个数通过穷举法试验确定为8 个时,平均误差最小,反馈层节点个数与隐含层相同,均为 8个,则DNN 网络采用3-8-1 的结构。
以上3 种网络的训练算法均采用BP 算法,初始权值设为[-0.1,0.1]之间的随机值。DNN 网络的自反馈增益 为0.6。训练次数设定为1 000 次,目标设定为0.001。
下面,设计PSO-DNN 网络模型,结构为3-8-1,粒子维数为:3×8+8×1+1+8=41 个个,适应度函数选择均方误差,取 c1=c2=2,惯性权重选择ωmax=0.9,ωmin=0.4,选择粒子个数为 30,最大迭代次数设为1000。按照PSO 优化DNN 网络模型的步骤,进行粗甲醇转化率预测仿真实验,训练样本预测结果如图3 所示,测试样本预测结果如图4 所示。采用相同的实验数据,基于上述4 种网络,分别建立粗甲醇转化率的预测模型,误差性能综合分析比较见表1 所示。

图3 PSO-DNN 网络训练样本预测结果Fig.3 The predicted results of the training sample of PSO-DNN network
从图3 可以看出,PSO-DNN 网络模型的训练效果良好,预测值与实际值的拟合程度较好。从图 4可以看出PSO-DNN 模型较为精确的预测了粗甲醇的转化率,具有较强的泛化能力。
从表1 可知,四种网络的训练误差都比较小,证实了神经网络非线性映射能力较强。Elman 网络和DNN 网络的测试误差都小于BP 网络,说明反馈动态网络的逼近能力要强于前馈静态网络。DNN 网络的训练误差及测试误差较 Elman 网络均有所提高。但BP、Elman、DNN 三种网络的测试误差要远远高于训练误差,说明采用 BP 算法的神经网络泛化能力较差。使用PSO 优化DNN 网络后,模型的跟踪性能有所改善,测试误差为 0.0057,说明PSO-DNN 网络的泛化能力和稳定性明显提高,且全局收敛性增强。

图4 PSO-DNN 网络测试样本预测结果Fig.4 The predicted results of the test sample of PSO-DNN network

表1 四种网络模型的性能比较Table 1 Comparison of capability of four network models
4 结 论
本文针对甲醇合成过程的特点,融合Elman 神经网络、核主元分析法、粒子群优化算法的优势,提出了基于 PSO-DNN 神经网络的粗甲醇转化率预测模型。以合成塔实际运行数据为样本,通过仿真实验,结果表明:首先,引入改进的Elman 网络增强了模型的动态适应性;其次,采用核主元分析法对预测模型输入特征进行提取和对输入数据进行预处理,可一定程度降低模型的复杂度和提高预测效果;使用粒子群算法后,预测模型的实时跟踪精度、稳定性及泛化能力都得到了明显的改善。本文建立的基于PSO-DNN 神经网络的预测模型实现了粗甲醇转化率的实时测量,并为工艺参数优化控制奠定了基础。
[1] Cong Qiumei,Chai Tianyou,Yu Wen.Modeling wastewater treatment plant via hierarchical neural networks[J] . Control Theory &Applications,2009,26(1):8-14.
[2] Pham D T,et al.Dynamic system identification using Elman and Jordan Networks [A].Neural Networks for Chemical Engineers[C].Elsevier Sciense Publishers,1995:573-592.
[3]Qi Hongji,Liu Mandan,Wang Honggang.Proceess modeling method based on an improved Elman neural network//Proceedings of the 7th World Congress on Intelligent Control and Automation[C].2008,26(7):8188-8192.
[4] Rumelhart D,Williams R.Learning representations by back propagating errors[J].Nature,1986,323(9):533-536.
[5] B.Scholkopf,A.Smola,K-P Muller.Nonlinear component analysis as a kernel eigenvalue problem[J].Neural Computation,1998,10(6):1299-1319.
[6] Kennedy J,Eberhart R.Partical swarm optimization[C].Proc IEEE Int Conf on Nerural Networks,Perth,USA.USA:IEEE,1995,1942-1948.
[7] 冯冬青,杨书显. 氧乐果合成过程的PSO-回归BP 网络建模方法[J]. 郑州大学学报,2011,43(3):113-117.
[8] 徐进荣,潘丰. 基于PSO 和SVM 的发酵过程建模与优化控制[J]. 微计算机信息,2008,24(7):31-33.
