汽车运行状态识别方法研究(一)——特征参数选择
2013-07-25田毅张欣张昕张良
田 毅 张 欣 张 昕 张 良
1.装甲兵工程学院,北京,100072 2.北京交通大学,北京,100044 3.酒泉卫星发射中心铁路管理处,酒泉,732750
0 引言
混合动力电动汽车(HEV)被认为是21世纪解决汽车面临的石油能源危机和环境污染问题的有效方案之一,建立先进合理的能量管理控制策略以及对现有控制策略进行优化已成为国内外各研究机构探索的核心技术之一。混合动力电动汽车的控制策略与汽车运行状态紧密相联,在对控制策略进行优化的过程中,运行工况不同,其优化结果也不同,而且车辆实际行驶过程中所经历的随机状态与已制定的典型运行工况也会有所差异。基于运行状态识别的智能控制策略是最新提出的HEV控制策略,它通过对汽车当前的运行状态进行识别来调整整车控制策略,使得HEV能够适应于不同的运行状态[1-6]。
2002年,Lin等[1]采用10个参数建立了基于Hamming神经网络的汽车运行状态识别模型,对美国和韩国的6种典型运行工况进行了识别。2005年,Langari等[2]采用Ericsson定义的26个参数,建立了基于学习向量量化(LVQ)神经网络的汽车运行状态识别模型,对美国LOS的运行工况进行识别。在我国,罗玉涛等[3]采用“工况块”的概念,用工况的平均行驶车速和行驶距离作为特征参数,通过模糊分类器对汽车运行状态进行了识别。周楠等[4]采用循环平均车速、循环行驶平均车速等10个参数,建立了基于简单神经网络的汽车运行状态识别模型,对北京、纽约、长春、上海等地的汽车运行工况进行了识别。张良等[5]采用18个参数,建立了基于支持向量机(SVM)的汽车运行状态识别模型,对我国上海和广州市的汽车运行工况进行了识别。田毅等[6]采用13个参数,建立了基于模糊神经网络的汽车运行状态识别模型,对不同敏感性参数的汽车运行工况进行了识别。
对汽车运行状态识别算法进行研究发现,想要得到一个高性能的汽车运行状态识别模型,必须首先得到一个汽车运行状态特征参数最优子集。实际上,目前在特征参数选择的算法中,不论是基于Wrapper框架的,还是基于Filter框架的,都是针对确定的特征参数全集进行选择计算的。而在对汽车运行状态特征参数进行分析后发现,其中的分段参数部分的运行状态特征参数之间的边界是不确定的,不同研究人员定义的特征参数之间的边界也是不一样的,因此特征参数全集也是不一样的,对于这种特征参数选择问题目前还鲜有人进行研究。
本文建立了一种基于混合搜索的汽车运行状态特征参数选择方法,有效地把自适应遗传算法和浮动搜索算法的优势进行结合,顺利解决了汽车运行状态特征参数选择问题。
1 汽车运行状态特征参数选择分析
1.1 汽车运行状态特征参数全集分析
汽车运行状态识别是一种在线识别,因此必须保证识别模型的准确性和实时性。本文中采用一组共22个特征参数作为汽车运行状态特征参数全集,如表1所示,可分为标准参数、波动参数、分段参数[7]三部分。表中,v1、v2、v3为有关车速的特征参数之间的边界,km/h;r1、r2为有关减速度的特征参数之间的边界,m/s2;a1、a2为有关加速度的特征参数之间的边界,m/s2。
相对加速度aRPA的计算公式为[7]
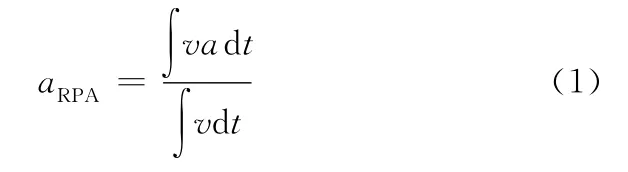
式中,v为车速,m/s;a为汽车加速度,m/s2;t为汽车运行时间,s。
汽车运行状态特征参数中分段参数部分是对汽车车速曲线变化规律的一种定性分析,研究人员可以根据自己的需要对分段参数部分的特征参数之间 的 边 界v1、v2、v3、r1、r2、a1、a2定 义 不 同 的 数值。在汽车运行状态特征参数选择时,需要对特征参数之间的边界进行优化,从而计算得到最优的特征参数全集,因此不能采用现有的特征参数选择方法进行汽车运行状态特征参数的选择计算,需要建立新的算法来解决这种特征参数选择问题。

表1 样本参数表
1.2 测试数据集建立
测试数据集是评价特征参数子集优劣的基础,其结果直接影响到识别模型的准确性及泛化能力。在建立汽车运行状态识别所需的车辆运行工况测试数据集时,需要首先对汽车运行状态进行分析,确定其分类类别。通过查阅我国《城市道路设计规范》、城市典型运行工况制定等相关文献后,发现快速路和主干道是我国大多数城市的主要交通路线。本文选用北京、上海、广州和武汉作为我国城市的代表。另外,为了增加测试数据集的覆盖面,提高汽车运行状态识别模型的识别准确性和泛化能力,本文还采用GPS车速采集仪,对汽车在主干道和快速路上的实际运行车速进行了采集,采集结果如图1所示。
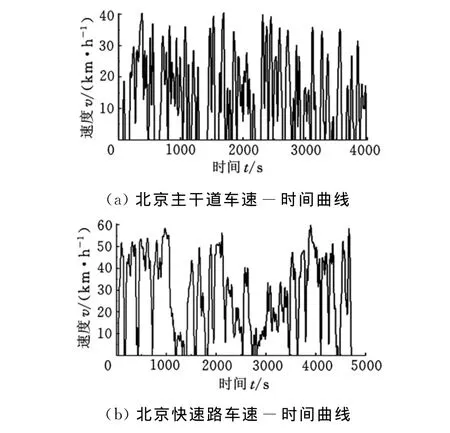
图1 车速采集
考虑到汽车在行驶过程中车速是一个时变量,汽车车速随着时间的变化而变化。为了提高识别模型的实时性,本文采用滚动时间窗的方式对速度-时间曲线进行分割[6],在此基础上建立汽车运行状态特征参数选择所需的测试数据集。通过计算这些速度小片段的汽车运行状态特征参数,可以得到汽车运行状态的测试数据集,其中包括7784组数据的主干道测试数据集和5805组数据的快速路测试数据集。然后分别从主干道和快速路测试数据集中随机选择200个样本作为运行状态分类器的训练数据集。
1.3 特征参数选择过程分析
采用计算得到的汽车运行状态特征参数全集和测试数据集,对汽车运行状态特征参数选择进行分析,发现其具有两个特点:
(1)汽车运行状态特征参数之间的边界v1、v2、v3、r1、r2、a1、a2不确定,需要对边界进行优化,才能计算得到最优的特征参数全集。因此不能采用现有的特征参数选择方法进行汽车运行状态特征参数的选择计算。
(2)如果运行状态特征之间的边界得到确定,则属于中小规模特征全集的特征参数选择问题,即全集χ中仅有22个参数,完全可以采用现有的特征参数选择方法进行求解。
因此在进行汽车运行状态特征参数选择时,采用以下步骤:确定输入参数之间的边界v1、v2、v3、r1、r2、a1、a2,计算特征参数全集;对于任意一组特征参数之间的边界,都可以得到一个特征参数全集χ。识别准确度的计算公式为
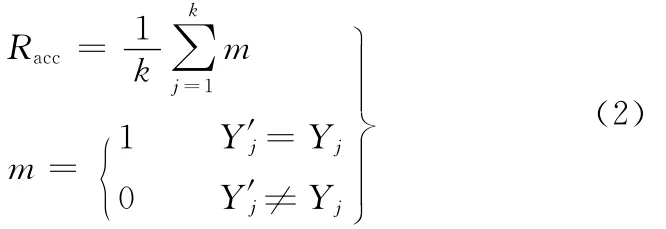
式中,Racc为识别准确度;k为测试数据集K中数据的个数;Y′=φs(Sw)为分类器的预报值;Sw为汽车运行状态特征参数子集。
当Racc最大,Sw中特征参数个数最少时,当前的Sw就是汽车运行状态特征参数的最优子集。
2 混合搜索算法总体结构设计
2.1 结构框架设计
通过对汽车运行状态特征参数选择对象进行研究,发现主要有两种搜索对象,一种为对特征参数边界进行搜索,另外一种为对特征参数子集进行搜索。因此本文针对这两种搜索对象,采用内外两层循环的方式,对汽车运行状态特征参数进行选择。
(1)外层循环的主要任务是寻找最优的汽车运行状态特征参数之间的边界,以便生成特征参数全集,也可以认为是特征参数选择问题的全局搜索操作。对汽车运行状态特征参数之间的边界进行搜索寻优是一个多参数多目标优化问题,因此需要选择智能搜索算法。常用的智能搜索算法为遗传算法、蚁群算法、模拟退火算法等。本文中选用自适应遗传算法[8-9]作为外层循环的搜索方式。
(2)内层循环的主要任务是对外层循环得到的汽车运行状态特征参数全集进行特征参数选择计算,也可以认为是汽车运行状态特征参数选择问题的局部搜索操作。
在汽车运行状态特征参数选择过程中,如果内层循环也采用遗传算法进行特征参数选择,则计算时间过长,也容易产生局部最优解,而且遗传算法对于中小规模数据集的特征参数选择来说并不具有优势。为了尽量缩短特征参数选择的搜索时间,本文选用了对中小规模数据集搜索能力强的浮动搜索算法作为内层循环的搜索算法。
2.2 自适应遗传算法
汽车运行状态特征参数边界的优化模型主要包括:优化参数、约束条件和目标函数。
(1)优化参数。根据1.1中的分析得到,运行状态特征参数之间的边界v1、v2、v3、r1、r2、a1、a2是不确定的,因此本文将这些参数作为自适应遗传算法的优化参数。
(2)约束条件。本文对运行状态特征参数边界,即优化变量v1、v2、v3、r1、r2、a1、a2的约束区间上下限根据经验确定,如表2所示。
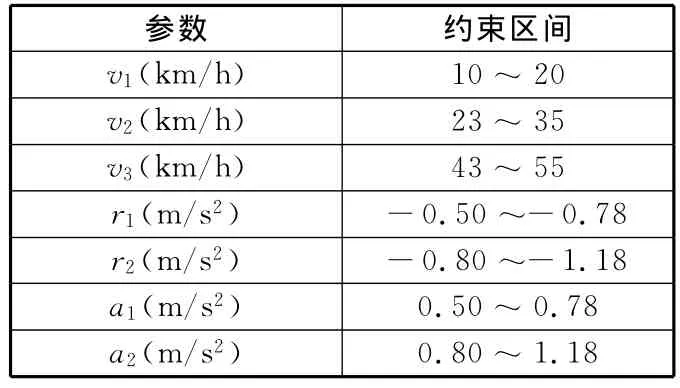
表2 优化变量的约束区间
(3)目标函数。本文采用加权法建立遗传算法中的目标函数,从而将多目标优化问题转化为单目标优化问题。在汽车运行状态特征选择问题中,遗传算法的目标函数为
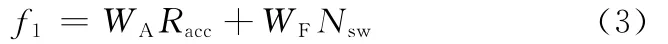
式中,f1为遗传算法的目标函数值;WA为分类器识别准确度的权重;Nsw为特征参数子集中参数个数;WF为特征参数子集中参数个数的权重。
考虑到Racc和Nsw数量级的不同,本文中定义WA=0.99,WF=0.01。
在遗传算法计算过程中,通过选择、杂交和变异三种基本形式,模拟自然选择以及遗传过程中的繁殖、杂交和突变现象。然而如果对于无论适应度高的个体还是适应度低的个体都以同样的概率进行交叉和变异操作,显然是不合理的。本文采用自适应的遗传算法进行计算,该算法对适应度高的个体采用较小的概率进行交叉和变异操作,对适应度低的个体采用固定的概率进行交叉和变异操作[9]。
(1)选择操作。本文中采用轮盘赌模型,按各染色体适应度大小比例来决定其被选择数目的多少。
(2)交叉操作。交叉概率公式为
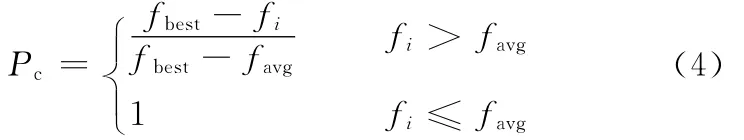
式中,fi为待交叉的两个个体中适应度较高者的适应度;favg为当前种群中所有个体的平均适应度;fbest为当前种群中适应度最高的个体适应度。
(3)变异操作。交异概率公式为
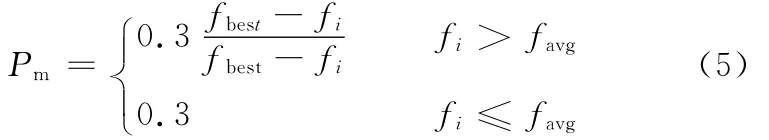
2.3 浮动搜索算法
传统浮动搜索算法的起始点往往采用随机生成的方式[10-11]。因此如果采用传统的浮动搜索算法,混合搜索算法中每次进行浮动搜索计算所选的起始点之间没有任何关系,是相互独立的。通过对采用遗传算法得出的汽车运行工况特征参数全集进行分析后发现,这些特征参数全集之间具有一定的类似性,因此本文提出了起始点种群间遗传和个体间遗传两种选择浮动搜索算法起始点的方法。
(1)基于起始点种群间遗传的混合搜索算法。在遗传算法每个种群中所有个体计算完以后,对计算得到候选特征参数子集进行评价,得到相对最优的子集并遗传给下一代。当新的种群生成后进行浮动搜索时,选用的起始点就是上一个种群计算得到的最优子集。
(2)基于起始点个体间遗传的混合搜索算法。在遗传算法每个个体计算完后,就进行一次最优子集评价,如果比原先的最优子集好,则替代,并遗传给下次搜索;如果不好,则放弃。当新的个体进行计算时,起始点就选从当前的最优子集开始搜索。采用起始点个体间遗传的混合搜索算法对汽车运行状态特征参数进行选择的流程如图2所示。
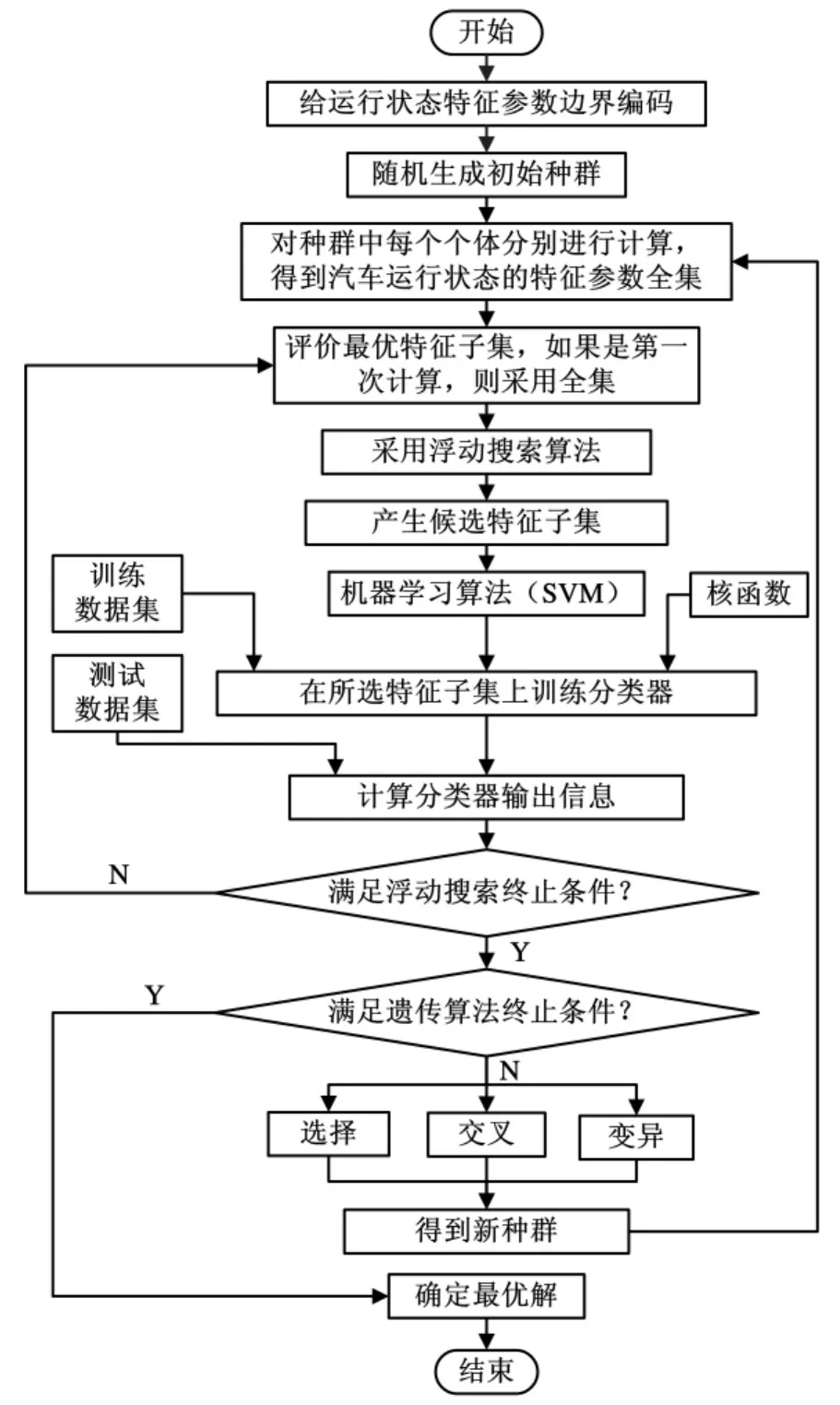
图2 采用起始点个体间遗传的混合搜索算法流程图
3 汽车运行状态特征参数选择计算结果及分析
3.1 特征参数最优子集
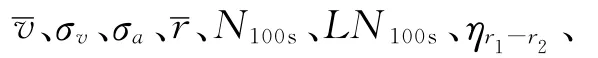
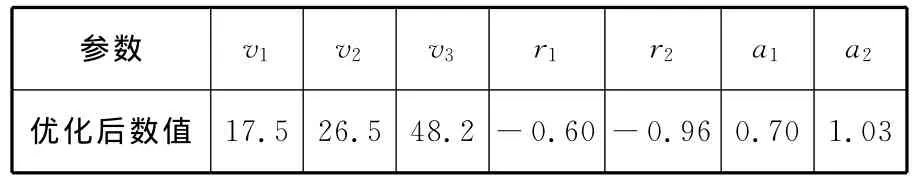
表3 遗传算法优化后的特征参数之间的边界
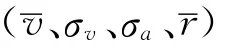
3.2 特征参数最优子集的参数个数对分类器准确度的影响
采用基于向后搜索的特征参数选择方法,对优化后的汽车运行特征参数全集进行搜索,分类器的识别准确度随特征参数个数的变化如图3所示。从图中可以得到,特征参数最优子集中参数数目在8~12时,分类器的识别准确度相差很小。而且,分类器的识别准确度随着最优子集中特征参数个数的减少,先增加后减少。主要是因为:特征参数过多时,不重要的特征参数会对分类器造成干扰,影响分类器的识别准确度;当特征参数减少到一定程度时,分类器的识别准确度保持不变;随着特征参数进一步减少,当其不能完全反映汽车运行状态的特征时,减少特征参数个数会造成特征的缺失,从而导致分类器的识别准确度大幅度降低。
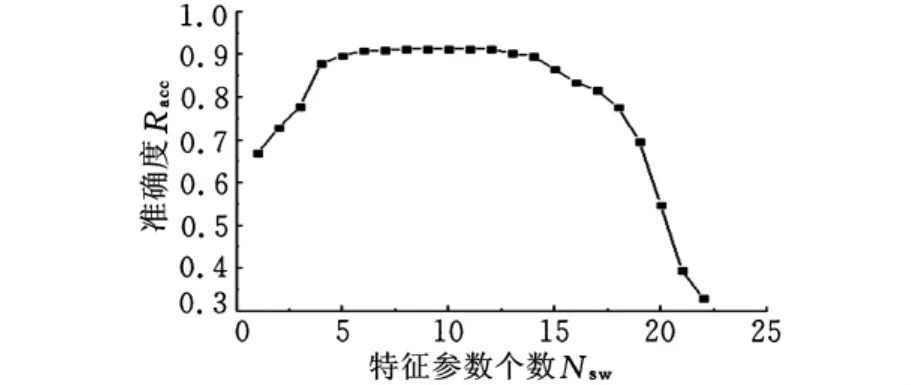
图3 特征参数子集个数与分类器识别准确度的关系
3.3 采用不同起始点位置的浮动搜索算法的计算结果及分析
对浮动搜索算法的起始点,分别采用起始点独立、起始点种群间遗传和起始点个体间遗传三种方式对汽车运行状态特征参数进行选择,计算结果如表4所示。
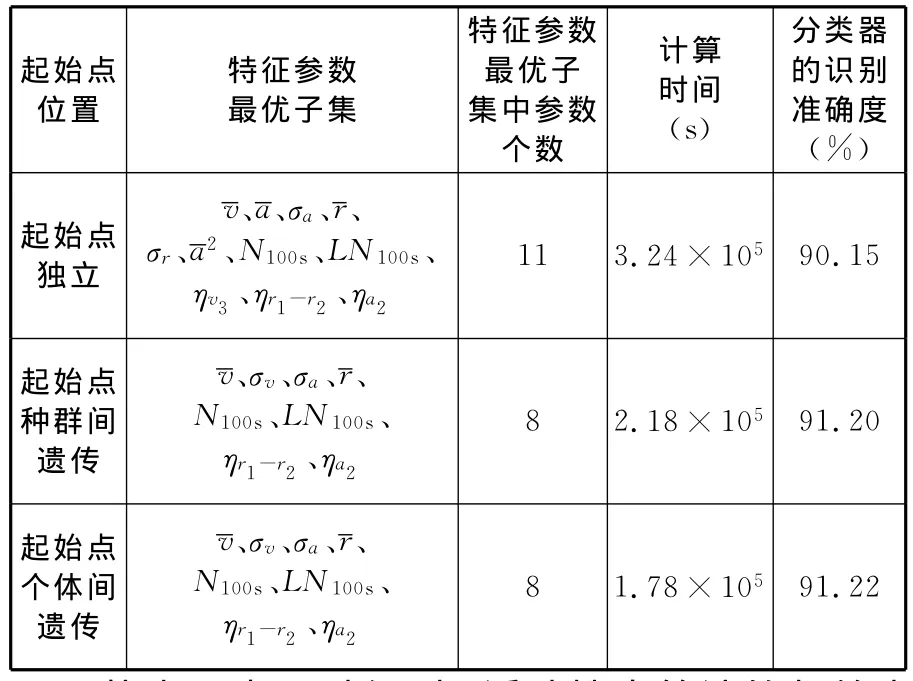
表4 采用不同起始点位置的浮动搜索算法的计算结果
从表4中可以得到,浮动搜索算法的起始点采用种群间遗传或个体间遗传的方式得到了相同的特征参数最优子集,而且比采用起始点独立方式计算得到的结果更好。分析原因主要是因为混合搜索算法中浮动搜索采用起始点独立的方式,没有充分利用到每次搜索得到的特征参数最优子集的优势,起始点不是最优点,使得计算结果容易陷入局部最优。相对于采用起始点独立的方式,采用个体间遗传的方式,可以使得搜索时间缩短45%,汽车运行状态特征参数最优子集个数从11个降低到8个,采用特征参数最优子集训练得到的分类器识别准确度也有所提高。在汽车运行状态特征参数选择计算过程中,起始点采用个体间遗传的方式比采用种群间遗传的方式的计算时间更短,原因是采用个体间遗传的方式虽然增加了评价特征参数子集优劣的时间,但是浮动搜索的起始点更加优秀,最大程度地避免了无效搜索,缩短了搜索的时间。
不同起始点位置的浮动搜索算法计算得到的最优子集中特征参数个数随进化代数的变化曲线如图4所示,由图4a可以得到,特征参数个数虽然总体上随着进化代数的增加而减少,但是由于没有充分利用每次搜索得到的特征参数最优子集的优势,使得计算结果很容易脱离最优区域,搜索初期会出现特征参数偶尔增加的情况,而且最终的结果也不是最优解,只能得到11个参数的特征参数最优子集。起始点个体间遗传的搜索效率最高,当进化代数达到31代时就得到了最优解,比起始点种群间遗传要快6代,而且得到了8个参数的特征参数最优子集。
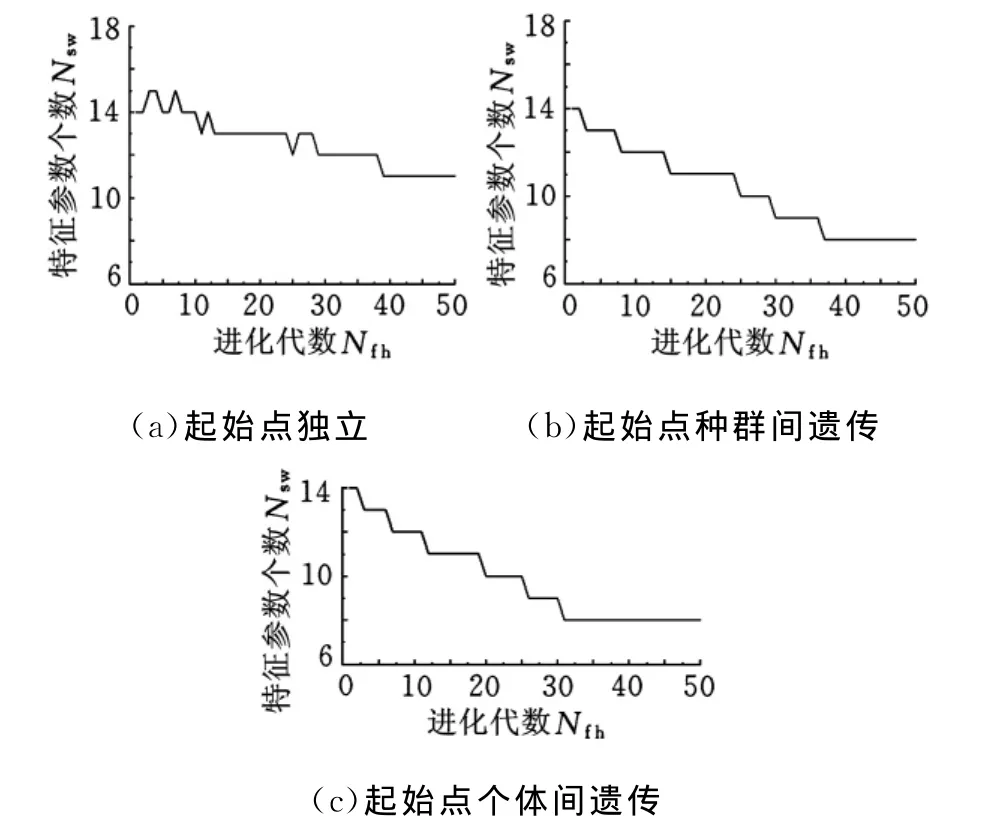
图4 特征参数个数随进化代数的变化曲线
4 结论
为了解决汽车运行状态特征参数选择问题,本文提出了一种混合搜索算法。该算法将自适应遗传算法和浮动搜索算法相结合,通过自适应遗传算法对汽车运行状态特征参数之间的边界进行搜索,依据获得的边界得出汽车运行状态特征参数全集特征;在此基础上,以浮动搜索算法对全集参数进行搜索,进而选择出汽车运行状态特征参数最优子集。
本文中还对最优子集中参数数量进行了分析,得到最优子集的识别准确度会随着参数个数的减少先增大后减小的结论。另外,通过计算说明浮动搜索算法的起始点采用个体间遗传的方式,相对于采用传统的起始点独立的方式,可以使得汽车运行状态特征参数最优子集中参数个数从11个减少到8个,并可提高搜索效率和最优子集的识别准确度。
[1]Lin C,Jeon S,Peng H,et al.Driving Pattern Recognition for Control of Hybrid Electric Trucks[J].Vehicle System Dynamics,2004,42(1/2):41-57.
[2]Langari R,Won J S.Intelligent Energy Management Agent for a Parallel Hybrid Vehicle—Part I:System Architecture and Design of the Driving Situation Identification Process[C]//IEEE Transaxtions on Vehicular Technology.USA:IEEE,2005:925-935.
[3]罗玉涛,胡红斐,沈继军.混合动力电动汽车行驶工况分析与识别[J].华南理工大学学报(自然科学版),2007,35(6):8-13.Luo Yutao,Hu Hongfei,Shen Jijun.Analysis and Recognition of Running Cycles of Hybrid Electric Vehicle[J].Journal of South China University of Technology(Natural Science Edition),2007,35(6):8-13.
[4]周楠,王庆年,曾小华.基于工况识别的HEV自适应能量管理算法[J].湖南大学学报(自然科学版),2009,36(9):37-41.
Zhou Nan,Wang Qingnian,Zeng Xiaohua.Adaptive HEV Energy Managemen Algorithms Based on Drive-cycle Recognition[J].Journal of Hunan University(Natural Sciences),2009,36(9):37-41.
[5]Zhang Liang,Zhang Xin,Tian Yi,et al.Intelligent Energy Management for Parallel HEV Based on Driving Cycle Identification using SVM[C]//The Institution of Engineering and Technology,Proceedings of the 2009 International Workshop on Information Security and Application.Oulu:IWISA,2009:457-460.
[6]田毅,张欣,张昕,等.基于神经网络工况识别的HEV模糊控制策略[J].控制理论与应用,2011,28(3):363-369.
Tian Yi,Zhang Xin,Zhang Xin,et al.HEV Fuzzy Control Strategy Based on the Neural Network Identification of Driving Cycle[J].Control Theory& Applications,2011,28(3):363-369.
[7]Ericsson E.Independent Driving Pattern Factors and Their Influence on Fuel-use and Exhaust Emission Factors[J].Transportation Research Part D,2001,6(4):325-345.
[8]魏志成.基于遗传算法的鲁棒数字图像水印研究[D].天津:天津大学,2007.
[9]曾喻江.基于遗传算法的卫星星座设计[D].武汉:华中科技大学,2007.
[10]Somol P,Pudil P,Novovicova J,et al.Adaptive Floating Search Methods in Feature Selection[J].Pattern Recognition Letters,1999,20(3):1157-1163.
[11]Songyot N,David P C.An Improvement on Floating Search Algorithms for Feature Subset Selection[J].Pattern Recognition,2009,42(4):1932-1940.
