中文博客多方面话题情感分析研究
2013-04-23傅向华郭岩岩郭武彪
傅向华, 刘 国, 郭岩岩, 郭武彪
(深圳大学 计算机与软件学院,广东 深圳 518060)
1 引言
互联网的发展,新兴媒体的涌现,推动大众传播向分众化、个人化方向发展,使得普通民众在Web上表达个人的主观性观点越来越便捷。博客作为Web上一种新的信息传播和交互方式,正变得日益流行和普及,影响力不断扩大,引起了不同领域的研究人员的关注[1-2]。博客博文(Blog document)一般由个人用户撰写,多数博文表达着个人对经济、政治等社会事件的观点态度和情感倾向。因此博客为网络舆论提供了得天独厚的条件,蕴含丰富的舆情信息。对博客进行情感分析,有助于把握大众舆论的态度,对商业智能、信息预测、舆情分析均具有重要研究价值[3-5]。
虽然情感分析研究领域已取得许多成果[4, 6],但国内外有关情感分析的研究多数集中于产品评论方面,例如,早期主要关注电影、旅游等评论的整体情感倾向分析[7-8],近期提出的基于特征的观点挖掘[9-10]以及多方面观点挖掘[11-13]则主要研究产品属性的情感倾向。针对政治、经济等社会事件的用户产生内容进行情感分析的研究还很少: Mullen等[14]分析了非正式的在线政治评论的特点并进行了初步的统计测试,认为传统基于词的分类方法不适用于对其进行情感分析;Malouf等[15]利用话语(discourse)中的协同引用关系,研究Web上的非正式政治文本的倾向分类问题; Melive等[16]提出利用情感词典和文本分类方法进行博客情感分析;而在国内,陶富民等[17]提出一种用于篇章级新闻评论情感分析的特征提取方法;杨超等[18]采用Hownet和NTU SD构建情感词词典,以进行网络舆情的倾向性分析;林琛等综合新闻口语评论中人物对象的特点,提取一种自动识别人物对象的方法[19]。但这些有关政治、经济等社会事件的情感分析研究,一般仅限于新闻、博客等用户产生内容文本的篇章级情感倾向判别,而实际的博客文本中,通常会同时涉及多方面的话题,因此需要更深入地判别评论者对不同话题的情感倾向,进行多方面话题的情感分析。
为从用户产生内容的文本中抽取潜在话题,研究人员提出话题情感分析模型的方法,如Qiaozhu Mei等[20]提出话题情感混合模型(Topic-Sentiment Mixture, TSM),用于发现博客中的潜在话题以及相应的情感倾向;Chenghua Lin等[21]提出用于情感分析的话题情感联合模型(Joint Sentiment Topic, JST),以同时从文本中检测话题与情感倾向;而Ivan Titov等[22]针对多方面的观点挖掘,提出多粒度的话题模型,同时考虑全局话题与局部话题两级话题的情感标签;国内清华大学的Fangtao Li等[23]进一步在话题情感模型中,将文档中情感词看作一个马尔可夫链,考虑局部上下文中情感词之间的相互依赖关系;北京大学的Wayne Xin Zhao等[24]基于最大熵模型和LDA模型,提出能同时从用户产生内容中发现多方面话题以及方面观点词的方法。虽然这些方法在小规模数据上获得较好的效果,但也存在缺陷,一方面,这类方法模型复杂,求解比较困难;另一方面,多数方法仅在产品评论上进行验证。而与产品评论相比,博客文本一般涉及话题宽泛,且缺乏显式的情感标记(如评分、星级等),因此,对博客文本进行多方面话题的情感分析更具挑战性。
根据已有文献,目前尚未有对中文博客等有关社会事件的用户产生内容进行多方面话题情感分析的研究。本文提出一种基于LDA模型与HowNet词典的两阶段多方面博客情感分析方法。该方法首先利用LDA模型对博客文本进行话题划分,然后再对划分后的话题窗口进行情感分析。实验结果表明,该方法能够较好地同时识别博客文本所涉及的多方面子话题及每个子话题上的情感倾向。
2 基于LDA话题模型与滑动窗口的多方面情感分析
一篇博客文本一般涉及多个子话题,发表有关多方面子话题的观点意见。因此,博客情感分析中,仅进行篇章级别或句子级别的情感分析还不够,还需要进一步从话题层面对博客文本进行划分,然后在此基础上分析博客文本在不同子话题上的情感倾向。
2.1 LDA话题模型
LDA是有关文档集合的产生式概率模型。假设博客文档集合为={d1,d2…,d},对应的词典包含||个词,任意文档d表示为包含dN个词的词序列d={wd1,wd2,…,wdN},wdn表示文档d的第n个词,wdn∈。则LDA模型将每篇文档视为由话题集合随机混合产生(假设||已知),而每个话题φk∈为关于中词的多项式分布。LDA话题模型的图模型表示如图1所示。
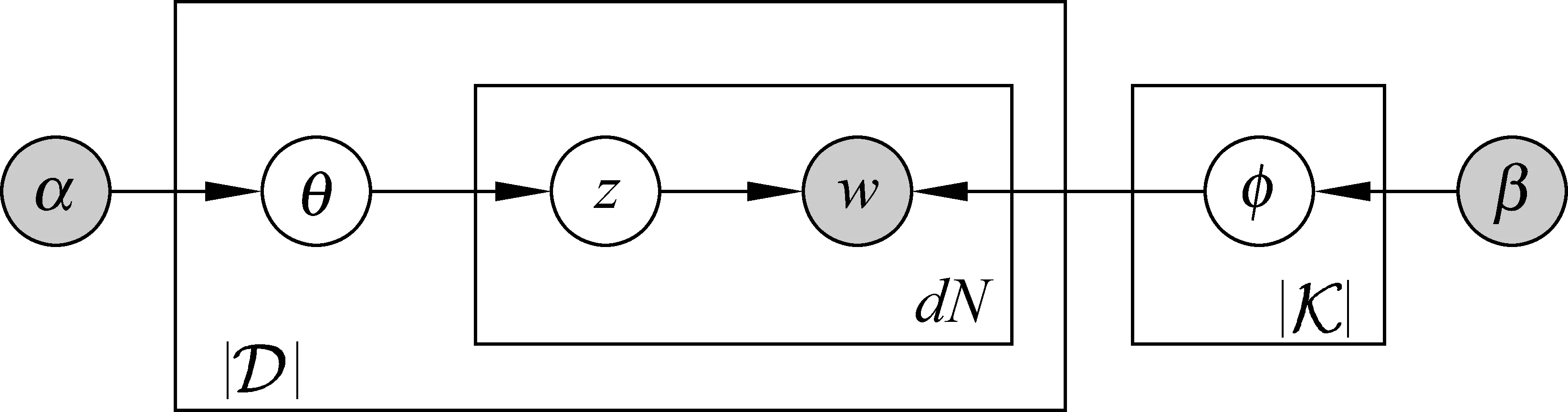
图1 LDA话题模型的图模型表示
LDA模型具有清晰的层次结构,依次为文档集合层、文档层和词层。LDA模型由文档集合层的参数(α,β)确定,α为博客文档集的话题先验分布超参数,反映了文档集合中潜在话题间的相对强弱;β刻画所有潜在话题自身的概率分布,φ表示||个话题在词上的分布,由||×||的矩阵β参数化,其中βij=p(wj=1|zi=1)。在文档层,θd表征文档d在话题集合上的分布,θd服从Dir(θd|α);在词层,zdn为产生wdn的话题,表示文档d分配在每个词上的潜在话题分量,zdn~Multinomial(θd)。给定参数α及φ,文档d的产生过程为:
① 从Dir(θ|α)中随机选择一个||维向量θd,产生文档d的话题分布;
② 根据概率p(wdn|θd,φ)产生文档d的每个词wdn。
构建并使用LDA模型的核心问题是隐含变量的推断,即确定模型参数θ和φ。在已知文档集的词w的条件下,反向推出其对应隐含变量z从而得到φ,θ和α。由于同时存在多个未知变量,难以精确推断,多数采用近似推理方法,如变分近似Bayesian法,Gibbs采样等[25-26]。如采用Gibbs采样方法估计当前采样词wdn的话题zdn的后验分布,然后得到模型参数φ和θ。确定模型参数后,给定文档d,可计算该文档关于潜在话题θ的后验分布为式(1):
其中:
本文采用Mark Steyvers等的Matlab Topic Modeling Toolbox*http://psiexp.ss.uci.edu/research/programs_data/toolbox.htm对博客文本集合进行话题识别。首先对中文博客文本进行分词、词性标注等预处理,然后将博客文本中不同词的出现次数作为LDA,模型的输入,具体数据格式为三元组(DID,WID,WCOUNT)集合,其中DID为文档的ID号,WID为词的ID号,WCOUNT为词WID在文档DID中出现的次数。识别所得的任一话题φk输出为不同词在该话题上的分布概率,即:Pk=(p1k,p2k,…,p),其中pik为第i个词属于第k个话题上的概率。
2.2 基于滑动窗口的多方面博客情感分析
定义1多方面博客情感分析: 设对博客文档集合涉及的话题集合,用户表达的情感倾向标签集合为={l1,l2,…,l},多方面博客情感分析的任务是确定任意博客文档d所涉及的子话题d及对应的情感标签。
情感表达一般以句子为单位,包括评价对象与情感表达词两个组成元素,两者紧密相关。已有研究表明,评价对象主要为名词、代词,而情感表达词主要为形容词、副词、动词等,而话题识别中起主要作用的是名词。虽然利用LDA模型可识别文本集合所涉及的多方面话题的词分布概率,但由于LDA模型将文本视为词袋(bag of words),丢弃了评价对象与情感表达词之间的关联关系,因此不能直接根据所识别的某个话题分布中的情感词判断该话题的情感倾向。本文提出基于滑动窗口的分阶段处理方式: 对于某个博客文本的词序列,选择一个滑动窗口,首先判断滑动窗口内文本的子话题,然后计算该滑动窗口所表达的情感倾向,最后再聚合相同话题的情感倾向。
定义2滑动窗口: 对某个博客文本d的词序列d={wd1,wd2,…,wdN},滑动窗口={w1,w2,…,w}为d的一个子序列,即,且对于任意两个滑动窗口i和j,满足i∩j=∅,所有的滑动窗口i=d。
在LDA模型中,由于某个话题φk视为关于词典的多项式分布,将其表示为Pk(wi)。当LDA模型训练好之后,||个话题的分布φ确定。而对于某个滑动窗口,亦可视为关于词典的多项式分布,将其表示为Q(wi),则可以基于KL散度计算两个概率分布之间的差异。则滑动窗话题φk之间的KL散度值为:
由于KL散度不具备对称性,本文采用下式计算KL散度值:
KL(Q,Pk)=(KL(Q‖Pk)+KL(Pk‖Q))/2
(3)
滑动窗口中某个词wi的概率采用滑动窗口内词频进行计算,则: Q(wi)=count(wi)/||,其中count(wi)为词wi在滑动窗口内的出现次数。
定义3滑动窗口话题划分: 给定滑动窗口={w1,w2,…,w|w|}和训练好的LDA模型,若滑动窗口对应的分布为Q(wi),话题φk对应的分布Pk(wi),则可计算滑动窗口与各话题模型之间的差异度,滑动窗口话题划分则为选择arg min KL(Q‖Pk)对应的话题模型φk作为滑动窗口的话题。
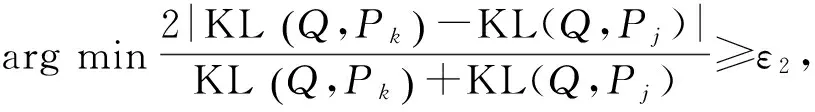
定义4子话题情感倾向分析: 给定滑动窗口={w1,w2,…,w|w|},根据某个分类函数f,确定该滑动窗口内文本的情感倾向的过程,即f:→。
综上所述,基于LDA话题模型与滑动窗口的多方面情感分析过程概述如下:
输出: 多方面的子话题及其情感倾向。
Step2: 输入数据集,训练LDA模型;
Step3: 利用训练好的LDA模型进行话题识别,得到||个话题的词分布P。
Step4: 对于每篇博客文本,根据滑动窗口进行子话题识别与情感倾向分析,步骤如下:
Step 4.3: 以二元组(话题号,情感倾向值)形式记录该滑动窗口的子话题及对应的情感倾向;
Step 4.3: 若未到达文本末尾,选择下一个滑动窗口,跳转到Step4.1;否则执行Step4。
Step5: 对记录的所有滑动窗口话题及其情感倾向,根据话题号,对不同话题的情感倾向值进行累加,即得到每个话题的情感倾向值。
3 基于Hownet的情感倾向度计算
3.1 HowNet词典
HowNet*http://www.keenage.com/以汉语和英语中词语所代表的概念为描述对象,以揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库。HowNet中有两个主要的概念: “概念”和“义原”。 “概念”是对词汇语义的一种描述,每个词可以表达为几个概念。“义原”是用于描述一个“概念”最小意义的单位。HowNet中的每个概念用一系列的义原来描述,义原之间通过上下关系组织成树状结构。
HowNet中词汇语义相似度的计算式通过计算词汇之间各自概念之间的相似度来实现的,而概念之间的相似度又是通过概念的义原之间的相似度来实现的。义原之间的相似度是通过计算义原树中两个义原的距离来实现。
对两个词语wi和wj,若wi有N个概念:Si1,Si2,…,SiN,wj有M个概念:Sj1,Sj2,…,SjM,则wi和wj的相似度等于各概念的相似度的最大值,即:
而义原之间的相似度可通过义原树中两个义原的路径距离来计算,两个义原pi和pj之间的语义距离为[27]:
其中dij>0为pi和pj在义原树中的路径长度,α是可调参数。
3.2 情感词的情感倾向度计算
计算情感词的情感倾向度时,首先选取m对具有强烈褒贬倾向的词作为基准词,将其情感倾向值标为+1和-1,然后根据Hownet词语的相似度计算方法,计算被测情感词与每个基准词之间的相似度,根据相似度的值得到该情感词的情感倾向值。对于某个词w,其情感倾向值如式(6)所示:
其中,kpi表示情感倾向为+1的基准词,kqi表示情感倾向为-1的基准词。若O(w)>0,则w的情感倾向度为正,若O(w)<0,则w的情感倾向度为负,若O(w)=0,则为中性。
式(6)中,对参与计算的m个相似度最大的褒义基准词与贬义基准词,权值相同。考虑到相似度越大的基准词,应该占更大的权重。因此,本文考虑加权的情感倾向度计算,如式(7)所示。
其中wpi=Simw(kpi,w)/∑Simw(kpi,w),wqi=Simw(kqi,w)/∑Simw(kqi,w)通过对不同的情感基准词采用加权,情感倾向度的计算准确率有一定的提高。对于某个滑动窗口,其情感倾向值为所有词的情感倾向值的和平均,则:
O()=|。
Step 2.1: 利用HowNet词典,根据式(4)分别计算该词与褒义基准词、贬义基准词的相似度;
Step 2.2: 根据式(7)计算该词的情感倾向值;
Step 2.3: 若滑动窗口中的尚有未处理完的情感词,选择下一个情感词,跳转到Step2.1;否则执行Step3。
Step 3: 计算滑动窗口中所有情感词的情感倾向值求平均值,得到该滑动窗口的情感倾向值。
4 实验与分析
4.1 实验设置
从新浪博客抓取有关“火车票实名制”的博客文本集合,主要抽取博客文本的标题、正文和评论,过滤掉没有意义的、字数过短的评论。剩余的每个评论作为博客文本的一个段落。首先由人工对抓取的博客文本进行情感倾向的标记,每篇博客文本由3人分别标记,再综合3人的标记结果。由于人工标记无法确定具体的情感值,因此采用正、负和中性3种情感标记。选取3人标记结果一致的博客文本,结果不一致的继续讨论,若讨论后仍无法取得一致,则将该博客文本去掉。最后得到人工标注的博客文本2 000篇作为实验数据语料。
实验过程中,首先对博客文本进行中文分词,建立向量空间模型。在情感倾向计算时,按词性过滤掉人名、地名、机构团体名、时间词、数词、量词、代词、标点符号和字符串等没有情感倾向的词汇。
情感基准词的选择是按照Google搜索返回Hits数从高到低排序,然后去掉语义重复的词,将其替换为排序靠前的情感极性词。本实验选取40对情感基准词如表1所示。
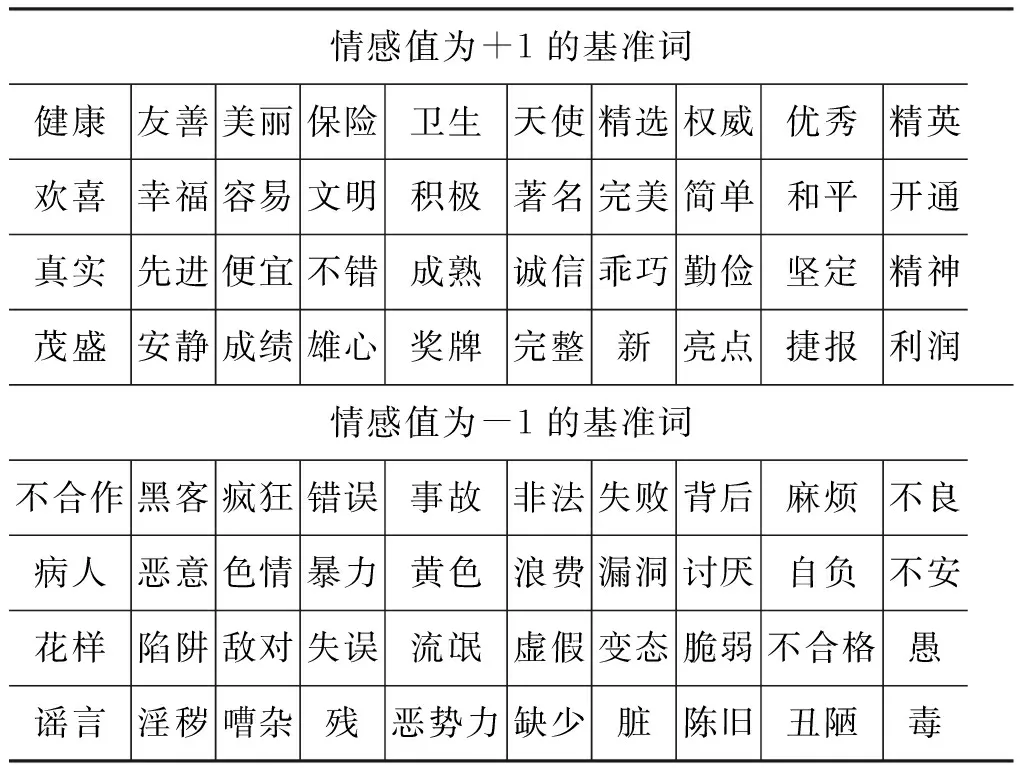
表1 40对极性褒贬基准词
4.2 情感词的情感倾向度计算实验
为比较式(6)和本文所提的改进的式(7)在情感词情感倾向度计算中的效果,本实验选取2 000组Hownet中文词表中标注为“良”和“莠”属性的词汇作为测试词汇,对式(6)和式(7)进行实验,实验结果如表2所示。由表2可以看出, 改进后的计算方法在褒义词判断方面明显优于原始算法,在贬义词判断方面略低于原始算法,但平均准确率明显要高于原计算方法。
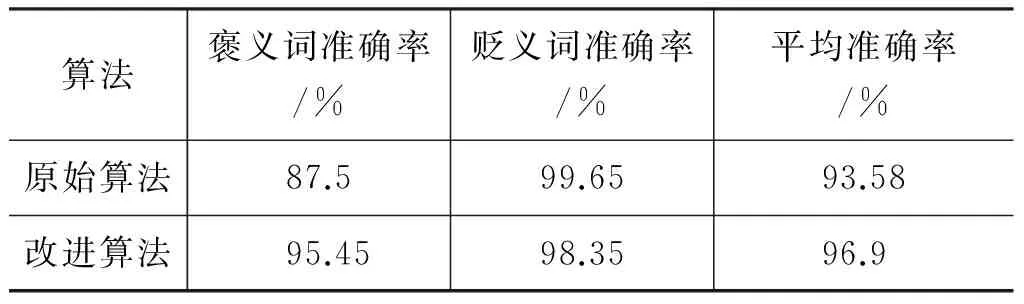
表2 不同算法下情感词情感倾向判断的准确率
4.3 篇章级博客情感分析实验结果
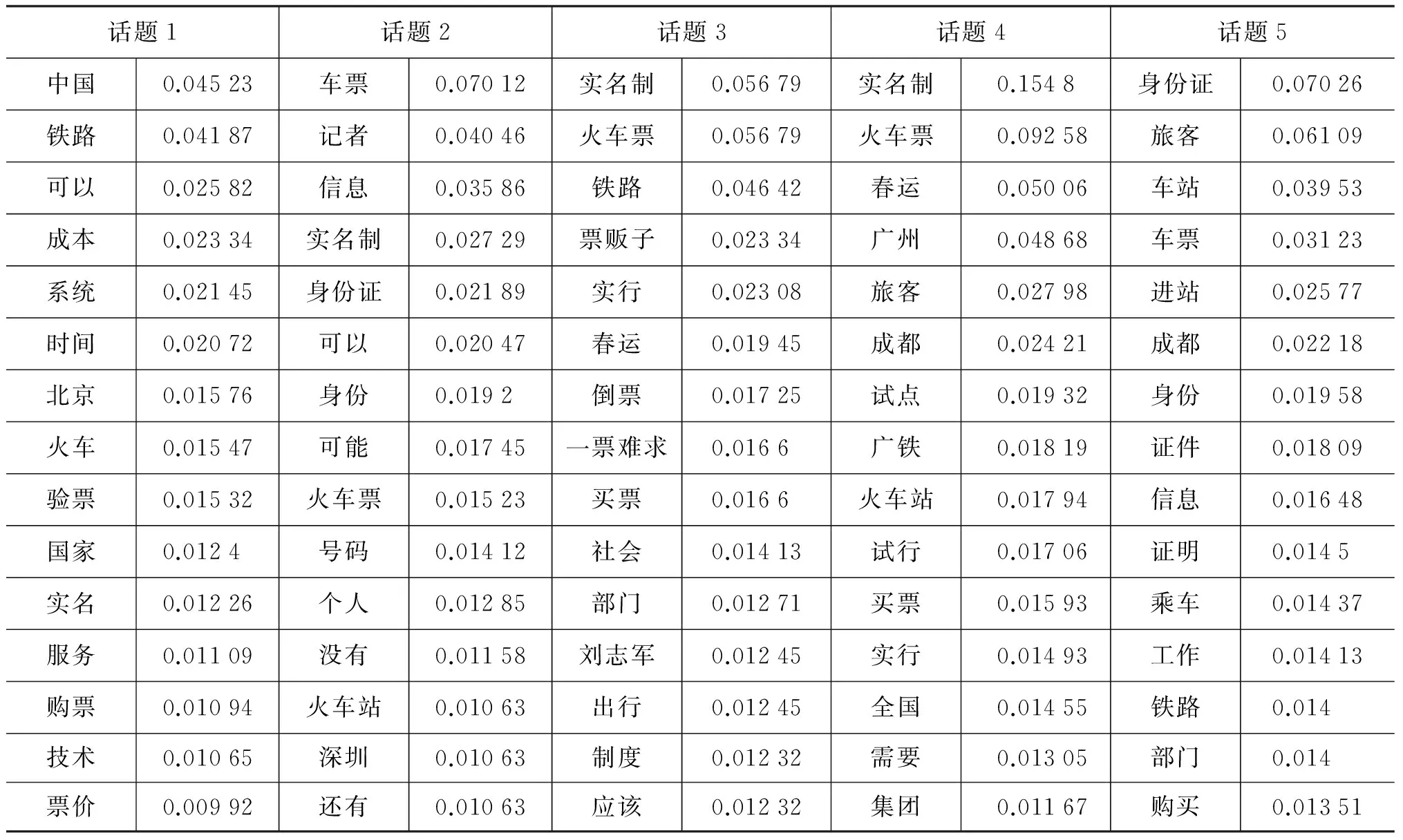
对于每篇博客文档d,设滑动窗口=d,则可对整个文档进行情感分析。由于整个文档不涉及话题的划分,因此可以直接根据3.2节方法计算其情感倾向。实验中设定阈值参数u,若-1≤O(d)<-u,则d的情感倾向为负,若-u≤O(d)≤u则为中性,若u 表3 不同阈值u下的篇章级情感倾向准确率 由表3可知,当阈值u取0.015时,达到最大的准确率73.28%,显然得到的情感分类准确率不够高。可见基于篇章级别的粗粒度情感分析,不能够很准确地表达该话题的情感倾向,主要原因在于篇章级别的话题所表示的内容“太大”。 1) 话题划分实验设置 多方面博客话题情感分析中,首先需要训练LDA话题模型。由于多方面话题的人工标记非常耗费时间,且不容易把握话题。因此本实验从2 000篇博客文本中选择300篇,由人工对其中的句子进行分析,标注每篇博客文本的每个句子所属于的子话题及对应的情感标签,情感标签包括正、负和中性3种。 在标注之前,首先利用LDA话题模型对300篇博客文本进行话题识别。选择不同的参数||进行实验,并人工分析各话题的词分布情感。根据曹娟等人的研究结果,当主题结构的平均相似度最小时,可得到最优的LDA模型[28],因此本文选取使话题结构平均KL散度距离较大的LDA模型。 通过设定不同的话题数目,使用式(3)计算不同话题下各个话题之间KL距离的平均值,实验结果如表4所示。由表4可知,发现当||=5时,各个话题之间的距离最大,获得最好的效果,对应可解释的5个话题。表5列出每个话题分布中的概率值最大的前15个词。 表4 不同话题数目下各个话题之间的距离 表5 5个子话题的部分特征词及权重 对于每篇博客文本,在话题划分时,滑动窗口大小分别以句子、段落和动态大小3种方式进行选取。句子、段落的划分根据相应的标点符号和段落标记完成。其中动态滑动窗口以句子为基本单位,通过比较窗口变化前后窗口中文本与各个话题距离的变化,来进行话题划分。实验中,分别按上述3种划分方法由人工对300篇博客文本进行话题划分标记。然后分别采用3种方法进行话题划分实验,实验结果表明第1种和第3种方法的准确率均低于50%,使用段落的方法准确率为72.97%。分析实验数据发现,第1种方法准确率低的原因,是因为单个句子所包含的词太少,在计算KL散度时,区分度很小。而第3种方法准确率低的原因,是测试文本的标记非常困难,不同标记人员在判断某个句子是属于前一个话题还是后一个话题时经常不一致,导致标记的数据差别很大。因此,后续话题情感分析实验以段落为基本单位进行话题划分。 2) 话题划分实验结果 对300篇博客文本进行话题划分,每个评论作为一个段落,共得到1 842个博客正文段落,767个评论段落,总共2 608个博客文本段落,话题段落分布如表6所示。话题划分的准确率计算公式为式(8)。 其中,tnk表示正确划分为话题k的段落数,TN表示总的测试段落数,tnother为其他话题类的段落数。利用LDA进行话题划分,调整参数ε1和ε2,结果如表7所示,可见当ε1=0.05,ε2=0.2时,话题划分的准确率最高。 表6 LDA模型中话题识别结果 表7 不同阈值下话题划分结果 得到各个话题下的识别结果如表6所示,其中第一行为采用LDA识别的话题段落数,第二行为与人工标记相符的段落数,前5个话题共正确识别1 809个段落。 3) 多方面情感分析实验结果 在话题划分的基础上,进一步基于Hownet词典计算每个段落的情感倾向度。对5个话题下识别正确的1 809个段落文本进行情感倾向度计算,其中标记为正向情感倾向的段落数为593,中立情感倾向的为427,负面情感倾向的为789。实验结果显示共有1 613篇段落的情感倾向判断正确,情感倾向分析的准确率为89.165%,具体每个话题的情感识别准确率结果如表8所示。由表8可知,针对博客段落的话题情感倾向分析的准确率比较高,博客的情感倾向可以从多方面通过博客话题的情感倾向来表示。 表8 不同话题下情感分析结果 本文提出一种基于LDA话题模型与Hownet词典的多方面博客话题情感分析方法。首先利用数据语料训练话题模型,然后以滑动窗口为单位,利用训练好的LDA模型对博客文本进行话题识别与划分;在此基础上,基于Hownet词典对划分后的话题段落进行情感分析。实验结果表明,该方法不仅能获得较好的话题划分效果,最好达到91.225 4%,也有助于改善情感分析的结果,对于每个话题段落的情感倾向分析准确率达到89.165%。通过本文方法,可以识别博客文本所涉及的多方面子话题及每个子话题上的情感倾向,能够更准确、深入地分析博客文本的情感倾向。不过,实验过程中发现,对于某个文本语料,预先确定子话题的数目||的难度很大。在后续的研究中,将考虑在LDA模型中引入Dirichlet过程,以便自动确定某个文本语料中的子话题数目。 [1] 杨宇航,赵铁军,于浩,等. Blog研究[J]. 软件学报, 2008, 19(4): 912-924. [2] Agarwal Nitin, Huan Liu. Blogosphere: research issues, tools, and applications[J]. SIGKDD Explor. Newsl., 2008, 10(1): 18-31. [3] 顾明毅,周忍伟. 网络舆情及社会性网络信息传播模式[J]. 新闻与传播研究, 2009(5): 67-73,109. [4] 赵妍妍,秦兵,刘挺. 文本情感分析[J]. 软件学报, 2010, 21(8): 1834-1848. [5] Pang Bo, Lillian Lee. Opinion Mining and Sentiment Analysis[J]. Found. Trends Inf. Retr., 2008, 2(1-2): 1-135. [6] 黄萱菁, 张奇, 吴苑斌. 文本情感倾向分析[J]. 中文信息学报, 2011, 26(6): 118-126. [7] Turney, Peter D. Thumbs up or thumbs down?: semantic orientation applied to unsupervised classification of reviews[C]//Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. 2002:417-424. [8] Min, Hye-Jin, Jong C Park. Toward finer-grained sentiment identification in product reviews through linguistic and ontological analyses[C]//Proceedings of the ACL-IJCNLP 2009 Conference Short Papers. 2009:169-172. [9] Ding Xiaowen, Bing Liu, Lei Zhang. Entity discovery and assignment for opinion mining applications[C]//Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining. 2009:1125-1134. [10] Su Qi, Xinying Xu, Honglei Guo, et al. Hidden sentiment association in chinese web opinion mining[C]//Proceeding of the 17th international conference on World Wide Web. 2008:959-968. [11] Zhu Jingbo, Huizhen Wang, Benjamin K. Tsou, et al. Multi-aspect opinion polling from textual reviews[C]//Proceeding of the 18th ACM conference on Information and knowledge management. 2009: 1799-1802. [12] Wang Hongning, Yue Lu, Chengxiang Zhai. Latent aspect rating analysis on review text data: a rating regression approach[C]//Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2010: 783-792. [13] 杨源, 林鸿飞. 基于产品属性的条件句倾向性分析[J]. 中文信息学报, 2011, 25(3): 86-92. [14] Mullen, Tony, Robert Malouf. A preliminary investigation into sentiment analysis of informal political discourse[R]. AAAI Symposium on Computational Approaches to Analysing Weblogs(AAAI-CAAW). 2006. [15] Malouf Robert, Tony Mullen. Taking sides: user classification for informal online political discourse[J]. Internet Research, 2008, 18(2): 177-190. [16] Melville Prem, Wojciech Gryc, Richard D. Lawrence. Sentiment analysis of blogs by combining lexical knowledge with text classification[C]//Proceedings of the 15th ACM SIGKDD international conference on Knowledge Discovery and Data Mining. 2009:1275-1284. [17] 陶富民,高军,王腾蛟,等. 面向话题的新闻评论的情感特征选取[J]. 中文信息学报, 2010, 24(3): 37-43. [18] 杨超, 冯时, 王大玲,等. 基于情感词典扩展技术的网络舆情倾向性分析[J]. 小型微型计算机系统, 2010, 31(4): 691-695. [19] 林琛, 李弼程, 周杰. 网络新闻口语评论文本中人物对象识别方法[J]. 中文信息学报, 2010, 24(4): 26-31. [20] Mei Qiaozhu, Xu Ling, Matthew Wondra, et al. Topic sentiment mixture: modeling facets and opinions in weblogs[C]//Proceedings of the 16th International Conference on World Wide Web. 2007: 171-180. [21] Lin Chenghua, Yulan He. Joint sentiment/topic model for sentiment analysis[C]//Proceeding of the 18th ACM Conference on Information and Knowledge Management. 2009:375-384. [22] Titov Ivan, Ryan McDonald. Modeling online reviews with multi-grain topic models[C]//Proceeding of the 17th International Conference on World Wide Web. 2008: 111-120. [23] Li Fangtao, Minlie Huang, Xiaoyan Zhu. Sentiment Analysis with Global Topics and Local Dependency[C]//Proceedings of the 24 AAAI Conference on Artificial Intelligence (AAAI-10). 2010. Atlanta, Georgia, USA: AAAI. [24] Zhao Wayne Xin, Jing Jiang, Hongfei Yan, et al. Jointly modeling aspects and opinions with a MaxEnt-LDA hybrid[C]//Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing. 2010, Association for Computational Linguistics: Cambridge, Massachusetts. 56-65. [25] Blei David M, Andrew Y Ng, Michael I Jordan. Latent dirichlet allocation[J]. J. Mach. Learn. Res., 2003, 3: 993-1022. [26] Griffiths Thomas L, Steyvers Mark. Finding scientific topics[C]//Proceeding of the National Academy of Sciences of the United States of America. 2004. [27] 朱嫣岚,闵锦,周雅倩,等. 基于HowNet的词汇语义倾向计算[J]. 中文信息学报, 2006, 20(1): 14-20. [28] 曹娟, 张勇东, 李锦涛,等. 一种基于密度的自适应最优LDA模型选择方法[J]. 计算机学报, 2008, 31(10): 1780-1787.
4.4 多方面博客话题情感分析实验结果




5 结论
