一种基于搭配的中文词汇语义相似度计算方法
2013-04-23曹存根裴亚军
王 石,曹存根,裴亚军,夏 飞,2
(1. 中国科学院 计算技术研究所 智能信息处理重点实验室,北京 100190;2. 中国科学院大学,北京 100049; 3. 全国科学技术名词审定委员会,北京 100717)
1 引言
词汇间的相似度分为语义相似度和分布相似度,前者是基于认知分类学的相似度,后者是基于主题的相似度[1]。例如,“网球”与“排球”具有较高的语义相似度,因为两者具有相近的认知属性;而“网球”与“网球拍”的语义相似度较低,但具有较高的分布相似度,因为两者较多地共现在相同文档中。
本文仅专注于词汇间的语义相似度计算。词汇间的语义相似是词汇间的一种基本的语义关系,但很难明确定义。文献[2]中给出的一个典型示例是,与“方法(method)”有较高语义相似度的词包括“技术(technique, 0.169)”、“步骤(procedure, 0.095)”、“手段(means, 0.086)”、“策略(strategy, 0.074)”等(对原文示例进行了翻译,括号中的第一个值为英文原词,第二个值为相似度)。词汇间的语义相似度计算是很多应用的基础。以信息检索为例,如果一个用户通过关键字“知识获取+方法”进行检索,那么结果也应当包含“知识获取+技术”的文档,这可以通过利用语义相似的词汇实现。另外,词汇的语义相似度计算还对机器翻译[3]、本体学习[4]、浅层语义分析[5]等产生积极作用。
本文提出了一种基于二词名词短语的中文词汇语义相似度计算方法,该方法对传统分布相似度假设“相似的词汇出现在相似的上下文环境中”进行了扩展,提出利用词汇在二词名词短语中的搭配词,而非传统的句子中的邻接词作为词汇的上下文的方法。其动机在于,相较于邻接词,搭配词更能体现词汇的语义特征。方法采用了基于tf-idf的权重计算方法构建搭配词向量,然后通过计算向量间的余弦距离来获得语义相似度。由于目前汉语中没有比较词汇相似度效果的基准测试集,本文借鉴英文基准测试集[6]类似的方法,给出了基于人工评分的中文基准测试集。在该测试集中的名、动、形容词中,本文提出的方法分别达到了0.703、0.509、0.700的相关系数,且覆盖率均达1.00。
2 相关工作
目前存在两种词汇相似度计算方法,即基于语义词典的方法和基于语料库的方法。前者往往依赖于已有的语义分类词典,而后者基于分布假设“相似的词汇出现在相似的上下文环境中”。
基于语义词典的方法通常依赖语义词典。一般来说,语义词典将词汇按照语义类别组织在树状层次结构中。在英语中,许多学者基于WordNet[7]做了大量的工作,基本思想是利用树中两个词间基于上下位的路径长度作为这两者相似度的一种度量。文献[8]提出,在类似于WordNet的语义词典中,两个词汇间的语义距离正比于两者间的上下位路径长度。文献[9]在此基础上定义了一种词汇相似度计算方法。
文献[10-11]除了考虑路径长度之外,还考虑了路径上词汇的特异性,若一个词的深度越低,那么其特异性越大,权重越高。文献[12]基于相似的思想提出了新的计算方法。文献[13]除去考虑上下位关系之外,还考虑部分—整体关系和同义—反义关系。
在汉语中,文献[3]提出了基于《知网》(HowNet)的词汇相似度计算方法。与WordNet不同,知网采用了1 500多个义原,通过一种知识描述语言来对每个概念进行描述。方法将两个词汇的整体相似度分解成多个义原对相似度的组合,对于义原对的相似度计算,采用根据HowNet中上下位关系得到的语义距离的方法。
语义词典的构造耗时费力,基于语义词典的词汇相似度计算方法受限于收词规模,因此近年来研究者们关注基于语料库的方法。分布假设“相似的词汇出现在相似的上下文环境中”是该类方法的基础。词汇的上下文中并不直接包含词汇的语义信息,而是仅仅体现了词汇间的分布规律,因此该类方法面临的主要问题是如何跨越从分布相似到语义相似的差距[1-2]。文献[2]系统介绍了从利用分布相似假设计算词汇间语义相似度的理论和方法。文献[14]则采用了一种利用语义受限的上下文矩阵,计算词汇相似度的方法。
两种方法均有不足之处,基于语义词典的词汇相似度计算方法受限于词典的规模;而对于基于语料库的方法而言,一方面因上下文中含大量与词汇语义无关的噪声词汇,影响准确率;另一方面需要大规模的语料及全文匹配算法,算法效率较低。
3 方法
3.1 基本思想
本文提出了利用一种新的基于词汇在二词名词短语中的搭配词来计算词汇的语义相似度的方法,方法基于下面直观假设。
假设1(相似词汇的相似搭配假设) 语义相似的词汇在二词名词短语中有相似的搭配词。
之所以利用二词名词短语中的搭配词作为上下文,而不是用词汇在大规模语料中的邻接词,是出于以下两点考虑。
1) 词汇在二词名词短语中的搭配词能反映其某方面的语义性质。例如,“塑料/n 杯子/n”、“砖/n 房子/n”、“木头/n 桌子/n”等体现了人造物的材质信息,“沉稳/a 青年/n”、“残暴/a 杀手/n”、“聪明/a 宝宝/n”等体现了人物的性格特征,“安置/v 场所/n”、“搬运/v 系统/n”、“美容/v 中心/n”等体现了场所的功能,等等。
2) 较之基于语料库的词汇上下文,从二词名词短语集合中构造词汇上下文具有更高的抽取和计算效率。
3.2 算法描述
算法的关键在于如何量化词汇的搭配词向量,以及如何计算搭配词向量间的相似度。从构建搭配词向量的角度,算法分为利用直接搭配词和利用间接搭配词的方法。
3.2.1 基于直接搭配词的方法
基于假设1和以上定义,下面给出基于词汇在二词名词短语中的直接搭配的词汇相似度算法。算法的基本思想是首先将词汇的搭配词构造成中文实词空间中的向量,然后通过计算向量间的余弦距离来计算相似度。算法首先构造了词汇的搭配词向量(步骤1、2),该向量是一个实数向量,元素值表示搭配词的重要程度。借鉴信息检索中的思想,用tf-idf[15]值作为其量化指标。然后通过计算搭配向量的余弦距离作为词汇的相似度,并需要两个词汇的公共搭配词达到一定规模,以消除偶然性(步骤3、4)。
算法1基于二词名词短语直接搭配的词汇语义相似度度量算法
输入:S,词对
输出:x,y基于二词名词短语集中直接搭配的相似度sim1(x,y)
步骤:
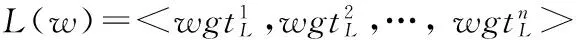
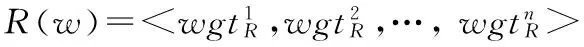
3. 记sim1L(x,y)为x,y基于左直接搭配词的相似度,若x,y共同的左搭配词数小于阈值θ,则sim1L(x,y)=-1;否则为 两者左直接搭配向量的余弦距离,即
(3)
4. 同步骤3,计算x,y基于右直接搭配词的相似度sim1R(x,y)。若x,y共同右搭配词数目小于参数θ,则sim1R(x,y)=-1;否则,
(4)
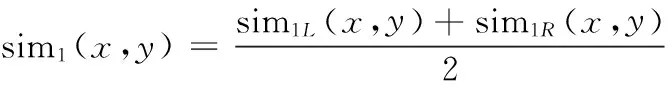
(4)
在实验中,我们取最小公共搭配词数量阈值θ=100,这可以减小因搭配词过少带来的偶然性错误,但也导致很多词对因公共搭配词较少而没有办法计算相似度。以“正午/中午”为例,其右搭配词为<正午 {快餐, 烈日, 时光, 时间, 阳光,…}>、<中午 {茶,日光,餐,时间, 班机,…}>。搭配词的交集只有“时间”,但实际上“快餐/餐/茶”,和“阳光/日光/时光”分别非常相似。现在重新审视假设1,如果首先计算得到“快餐/餐/茶”,和“阳光/日光/时光”分别是相似的,那么就可以将它们看作是相似的公共搭配词,进而得到“正午/中午”是相似的。基于这个想法,我们进一步提出了基于词汇间接搭配的词汇语义相似度算法,以解决因公共搭配词较少所带来的部分词汇无法计算的问题。
3.2.2 基于间接搭配词的方法
基于间接搭配词的相似度度量算法是基于直接搭配词方法的改进,区别在于在构造词汇的搭配词向量时,向量元素不是搭配词,而是一组彼此相似的词所组成的词簇。因此,在构造搭配词向量时,要首先计算搭配词间的相似度,这显然是一个递归的过程,需要多次的迭代。
对任意两个词wi,wj,记两者基于k次迭代搭配词的相似度为simk(wi,wj),下面给出的算法计算两者第k+1次迭代的相似度。算法2基本思路与算法1类似。
算法2基于二词名词短语间接搭配词的词汇语义相似度度量算法
输入:S,SIMk={simk(wi,wj)},词对
输出: simk+1(x,y)
步骤:
1. 记simk(x)={x′|simk(x,x′)>η}为与x基于k次迭代搭配相似的词集;
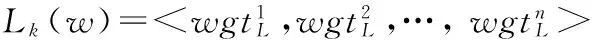
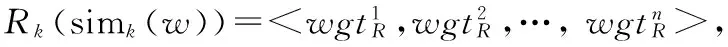
4. sim(k+1)(x,y)计算与算法1第3/4/5步相同。
算法2在一定程度上解决了算法1中因公共搭配词较少带来的问题,缺点在于迭代中出现的错误会在下一次迭代中扩散。如在前面“正午/中午”的例子中,若错误得到“快餐”和“班机”有较高相似度,那么在下一次迭代中,“正午”和“中午”的公共搭配词中将包含两者的公共搭配词簇,引起错误。一方面,随着迭代的进行,这些错误将逐步积累,影响准确率;另一方面,随着迭代的进行,越来越多的搭配词将会减少搭配词较少带来的偶然性,这将有助于提高相似度度量准确率。在下面的实验中将可以看到,当迭代次数达到一定值时,方法将在准确率上达到一个峰值,过多或过少均会导致准确率的下降。
4 试验
4.1 基于大规模生语料的二词名词短语集构建
我们利用文献[16]中的方法,从大规模生语料中抽取二词名词短语集合。文献[16]所提方法是完全自动的,首先利用词汇—句法模式(如“
4.2 基准测试集构建
英语的语义相似度度量常用的基准测试集为Miller-Charles测试集。1987年,文献[17]挑选了65对英语词汇并进行了人工打分作为相似度计算的测试集,后来文献[6]从这65对词中选出30对重新进行相似度评分,此后研究英语词汇相似度计算方法大都以这30对词语作为标准测试用例,称为Miller-Charles测试集。汉语中还没有类似的基准测试集,为了便于评价词汇相似度计算方法在中文中的效果,我们借鉴Miller-Charles测试集的构造方法,手工构建了一个基准测试集。
4.2.1 测试词对选择
我们精心地挑选名词对30对,动词、形容词各20对,在挑选的过程中考虑到两个挑选标准。
1) 分布均匀性: 挑选的词对应该尽可能地均匀的分布于多个认知领域;
2) 相似均匀性: 挑选的词对应该在相似程度上均匀分布。
以动词为例,从认知上动词可分为状态动词、变化动词、感知动词等15类[18],对每一类,我们精心挑选1~3个词,总共得到20对。这20对词语又按相似度大小分为3组,第一组相似度很大,共7对,主要是同义、近义词,例如,“抚摸”与“触摸”,“发明”与“创造”;第二组相似度一般,也有7对,由同属一类的动词构成,例如,“刮风”与“下雨”均属气象动词,“担心”与“放心”均属情感心理动词;第三组相似度较小,共6对,由分属两个不同类的动词构成,例如,“衰老”和“告诉”分属变化动词和通信动词,“鞠躬”与“听见”分属身体动作动词和感知动词。
在名词词对的挑选中,在保证上述两个标准外,我们还参考了Miller-Charles测试集的构成。
4.2.2 相似度人工评分
借鉴文献[17]的方法,我们设计了如下的人工评分方法。
1) 评分采用10分制,0分表示完全不相似,10分表示完全相似;
2) 寻找一组评分者;我们借助于中国科学院计算技术研究所大规模知识获取课题组的15个硕士研究生和10个博士研究生;
3) 评分者分两次进行评分,两次评分间隔15天;
4) 从评分者中,去掉两次评分的一致性小于0.8的评分者。文献[17]发现同一评分者在两周前后对同一组词对进行评分时,相关系数在0.85左右。因此若某评分者在两次评分中的相关系数过多地小于该值,则可认为其是无效评分者;
5) 取所有评分者两次评分的均值,作为最终人工相似度评分。
基于以上步骤得到最终的中文词汇语义相似度基准测试集,具体见表1。
4.3 试验结果
基于本文提出方法的词汇相似度实验中,|S|=2 184 635,θ=100,η=0.9,表1(a)/(b)/(c)分别给出了我们的方法在基准测试集名词、动词、形容词上的结果。评测指标包括: (1)相关系数: 算法结果与人工评测结果的相关系数;(2)覆盖率: 即能处理的词汇比例。
图1给出了基于实体搭配方法的词汇相似度计算方法结果与搭配迭代次数的关系。
从实验结果中发现,相关系数在第2次迭代时达到最高值,然后出现下降,这是因为在每次迭代中错误的相似词汇不断累加造成的。另外,名词和形容词的相关系数较高,动词较低,这是因为在名词短语中,形容词和名词的出现频率较高,且往往搭配比较固定语义的词汇;而动词一方面出现频率较低,另一方面其搭配词比较灵活, 语义更分散。覆盖率方面,名词和形容词的覆盖率较高,在第2次迭代时即可达到1;而动词由于出现频率较低的原因,覆盖率相对较低。
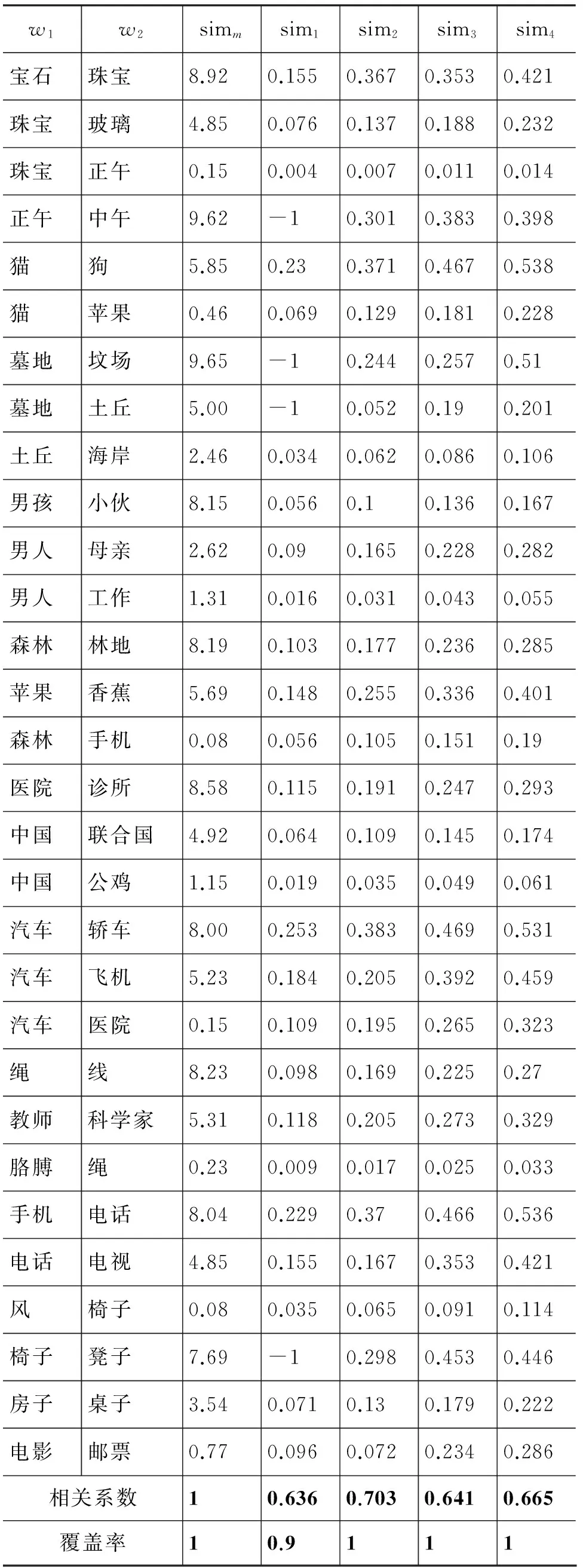
表1 基于搭配的词汇语义相似度度量实验结果(simm表示人工评分值)

(b) 动词
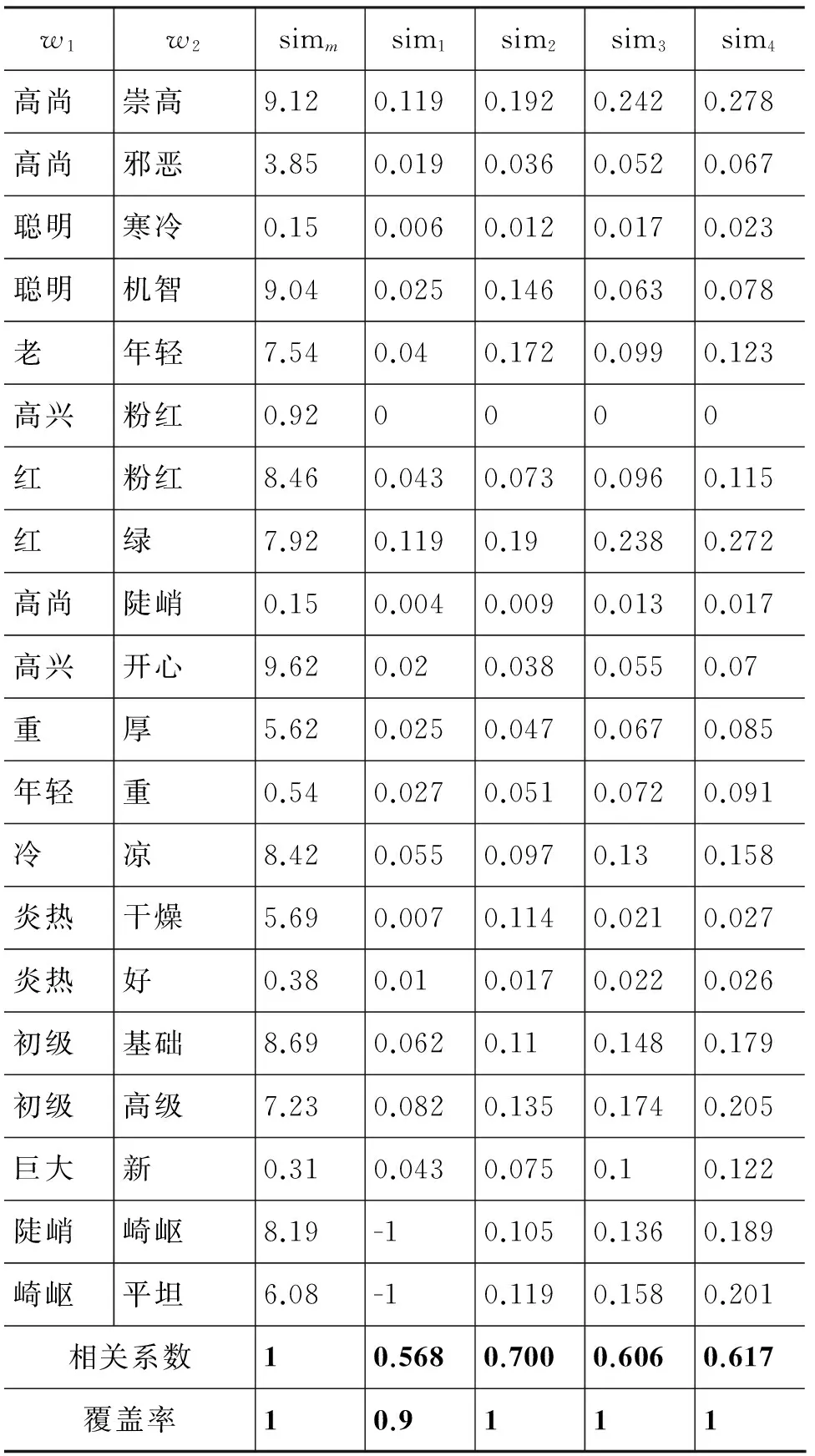
(c) 形容词
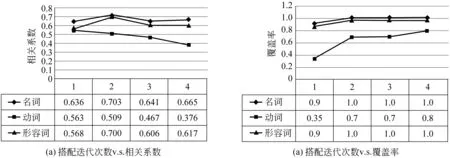
图1 基于实体搭配的词汇相似度度量方法性能与迭代次数的关系
4.4 错误分析
错误原因仍然主要集中于从分布相似性到语义相似性的差距。一方面,某些语义相似的词汇不一定具有相似的搭配词。以名词测试集中的“土丘/海岸”为例,两者都是地理实体,具有较高的语义相似度,然而两者的搭配情况却差异较大。两者tf-idf值较大的部分搭配词如下,
<{人工,人造,大,高,小} 土丘>
<土丘 {冢,一角,下面,坟,传说}>
<{大西洋,阳光, 河口,阿拉伯,太平洋} 海岸>
<海岸 {城市,地区,地形,警卫队,巡逻艇}>
两者没有一个共同的搭配词,究其原因在于相同语义分类的词汇,可能具有不同的组词用法。动词中的“通知/告诉”同样具有相同的问题。
另一方面,某些具有相似搭配词的词不一定是语义相似的。以名词测试集中的“男人/母亲”为例,两者分属不同的语义类别,语义相似度较低,然而搭配情况却比较一致。两者共同出现的左搭配词包括{白领,单身,德国,俄罗斯,非洲,健康,快乐,美国,模范,年轻,漂亮,普通,日本,上班族,上海,台湾,完美,伟大,香港,伊拉克,意大利,印第安,印度,英格兰,英雄,犹太,…},右搭配词包括{本能,房间,怀抱,灵魂,名字,年纪,年龄,情结,社会,身份,身体,声音,双手,素质,相貌,心灵,信心,形象,性格,眼睛,职业,周,…}。因为共同搭配词的很多,因此得到了较高的相似度。
基于以上分析,下一步工作将集中于进一步限制词汇的搭配词,及采用更好的重要性量化指标,减小分布相似到语义相似的差距。
4.5 与相关方法的比较
表2给出了本方法与相关方法在名词相似度度量上的比较。文献[3]是基于中文语义资源HowNet的方法;文献[8,10-13]是基于WordNet的方法,我们在中文WordNet[19]的基础上进行了实现。这些方法基于人工编撰的知识库,可以得到比较高的相关系数。但是,受限于词典规模,这些方法的覆盖率都不是很高。对于基于语料库的方法,我们与文献[14]方法在基准集上进行了比较。

表2 基于实体搭配的名词语义相似度度量方法比较
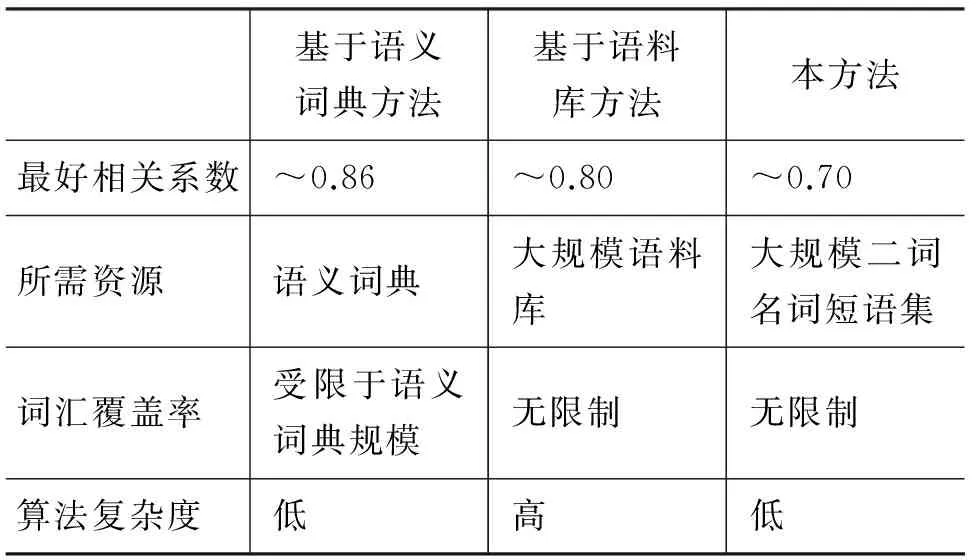
表3 与传统计算方法的特点比较
词汇相似度的人工量化本身也是一个非常困难的问题,文献[17]的实验中表明人工评测的相关系数也仅在0.85左右。从表2中发现,本方法得到的相关系数相较于基于语义词典的方法具有一定的劣势,但其优点在于其覆盖率较高,不会受限于语义词典的规模。而相较于基于语料库的方法,本方法无需从大规模的语料中获取上下文,因此具有更高的效率,且准确率也略高。在以上比较的基础上,我们总结了与传统方法相比,本方法所具有的特点,如表3所示。
5 结论和下一步工作
词汇间的语义相似度计算是许多应用的基础工作。本文提出了基于二词名词短语搭配的计算方法,具有实用的效率和可接受的准确率。方法基于直观的假设“语义相似的词汇在二词名词短语中有相似的搭配词”,提出了采用直接和间接搭配词的算法,并进行了实验。在人工构建的中文词汇相似度基准测试集的名、动、形容词中分别得到了0.703、0.509、0.700的相关系数,覆盖率达100%。
下一步的工作集中于如何进一步限制词汇的搭配词,利用更好的搭配词权重评测指标,以缩小搭配词的分布相似性与词汇间语义相似性的差距。
[1] Akira Utsumi, Daisuke Suzuki. Word vectors and two kinds of similarity[C]//Proceedings of the COLING/ACL on Main Conference Poster Sessions. 2006: 858-865.
[2] Curran J R. From Distributional to Semantic Similarity[D]. A dissertation submitted to University of Edinburgh for the Degree of Doctor of Philosophy. 2003.
[3] Qun Liu, Sujian Li. Word similarity computing based on Hownet[C]//Proceedings of Computational Linguistics and Chinese Language Processing. 2002: 59-76.
[4] P Buitelaar, P Cimiano, M Grobelnik. Ontology learning from text[C]//Proceedings of ECML/PKDD. 2005.
[5] Ting Liu, Wanxiang Che, Sheng Li. Semantic Role Labeling with Maximum Entropy Classifier [J]. Journal of Software. 2007, 18(3): 565-573.
[6] G Miller, W Charles. Contextual correlates of semantic similarity[C]//Proceedings of Language and Cognitive Processes. 1998.
[7] Richardson R, Smeaton A F, Murphy J. Using WordNet as a Knowledge Base for Measuring Semantic Similarity Between Words[C]//Proceedings of AICS Conference. 1994.
[8] R Rada, H Mili, E Bicknell, et al. Development and application of a metric on semantic nets[C]//Proceedings of IEEE Transactions on Systems Management and Cybernetics. 1989, 19: 17-30.
[9] Ted Pedersen, Siddharth Patwardhan. Wordnet: similarity-measuring the relatedness of concepts[C]//Proceedings of the 19th National Conference on Artificial Intelligence. 2004.
[10] Leacock C, Chodorow M. Combining local context and WordNet similarity for word sense identification [M]. WordNet: An electronic lexical. 1998: 265-283.
[11] Zhibiao Wu, Martha Palmer. Verbs semantics and lexical selection[C]//Proceedings of the 32nd Annual Meeting on Association for Computational Linguistics. 2003: 133-138.
[12] Yuhua Li, Zuhair A Bandar, David McLean. An approach for measuring semantic similarity between words using multiple information sources [J]. IEEE Transactions on Knowledge and Data Engineering. 2003, 15.
[13] DQ Yang, David MW Powers. Measuring semantic similarity in the taxonomy of WordNet[C]//Proceedings of the 28th Australasian Conference on Computer Science. 2005, 102: 315-322.
[14] Shi Wang, Cungen Cao, Yanan Cao, et al. Measuring Taxonomic Similarity between Words Using Restrictive Context Matrices[C]//Proceedings of 5th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD 2008). 2008: 193-197.
[15] Ricardo Baeza-Yates, Berthier Ribeiro-Neto. Modern Information Retrieval[M]. s.l. : ACM Press, 1999.
[16] Shi Wang, Yanan Cao, Xinyu Cao, et al. Learning Concepts from Text Based on the Inner-Constructive Model. Knowledge Science, Engineering and Management[C]//Proceedings of 2nd International Conference (KSEM 2007). 2007.
[17] Herbert Rubenstein, John B Goodenough. Contextual Correlates of Synonymy[C]//Proceedings of ACM. 1987, 8: 1317-1323.
[18] George A Miller. WordNet: A Lexical Database for English[C]//Proceedings of Communications of the ACM (CACM). 1995, Vol. 38: 39-41.
[19] 王石, 曹存根. WNCT:一种WordNet中概念的自动翻译方法[J]. 中文信息学报,2009,23(4):63-70.
